
基于胶囊网络的跨语言方面级情感分析
2024-06-01 19:03:40梁慧杰朱晓娟任萍
现代信息科技 2024年4期
梁慧杰 朱晓娟 任萍

收稿日期:2023-06-09
基金项目:2022年度安徽省高校重点项目(2022AH050821)
DOI:10.19850/j.cnki.2096-4706.2024.04.012
摘 要:跨语言情感分析的目的是利用数据资源丰富的源语言帮助资源较少的目标语言进行情感分析。针对中文文本标注语料较少和不同方面项的不同情感极性特征重叠影响文本情感分析准确率的问题,提出一种基于胶囊网络的跨语言方面级情感分类方法BBCapNet,该方法利用BERT模型学习源语言的语义特征训练词向量作为嵌入层,然后利用BiLSTM学习上下文信息,利用胶囊网络(Capsule Network)获取文本中局部信息和整体情感极性间的关系,从而提取不同方面项的情感特征,最后使用归一化指数函数(Softmax)进行分类。通过与其他主流方法进行对比论证,论证结果表明,该方法在跨语言方面级情感分类效果上有显著提升。
关键词:胶囊网络;情感分类;BERT;跨语言
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)04-0056-05
Cross-language Aspect Level Sentiment Analysis Based on Capsule Network
LIANG Huijie, ZHU Xiaojuan, REN Ping
(School of Computer Science and Engineering, Anhui University of Science & Technology, Huainan 232001, China)
Abstract: The purpose of cross-language sentiment analysis is to use source languages with abundant data resources to assist target languages with limited resources in sentiment analysis. A cross-language aspect level sentiment classification method BBCapNet based on Capsule Networks is proposed to address the issue of limited corpus for Chinese text annotation and overlapping sentiment polarity features of different aspects, which affects the accuracy of text sentiment analysis. This method uses the BERT model to learn semantic features of the source language and train word vectors as embedding layers, and then uses BiLSTM to learn contextual information, The Capsule Network is used to obtain the relationship between the local information and the overall sentiment polarity in the text, so as to extract the sentiment characteristics of different aspects. Finally, the normalized exponential function (softmax) is used for classification. By comparing with other mainstream methods, the results show that this method has a significant improvement in cross-language aspect level sentiment classification.
Keywords: Capsule Network; sentiment classification; BERT; cross-language
0 引 言
电商的蓬勃发展,使人们的购物方式产生了变革,随之产生了海量的商品评论数据。商品评论中蕴含着已购买用户对产品及其服务的情绪信息。这些商品评论数据既可以帮助消费者快速了解产品的真实信息又有助于商家判断用户喜好,快速地做出市场决策。
方面级情感分类任务的目标是判断文本中特定方面项对应的情感极性。方面級情感分类能够判断评论中不同方面的情感极性。比如,当输入语句“这家餐厅的服务很好”和方面项“服务”,可以提取出由方面项对应的情感极性“正向”。实现文本的细粒度情感分类,在社交媒体级商品评论等领域中有着较强的应用需求。目前方面级情感分类研究集中在使用深度神经网络。近年来,预训练语言模型[1-3]已成功地应用在自然语言处理的各个任务中。预训练语言模型也已经成为方面级情感分类任务模型的主流构建模块[4-8]。预训练语言模型的引入取得了不错的效果,但依然存在着忽视不同方面项的不同情感极性特征重叠影响文本情感分析准确率的问题。而且训练一个好的情感分类模型,需要大量的标注语料[9],而方面级情感分类任务不仅需要像传统情感分类任务一样标注文本的情感极性还需要标注对应的方面项。标注任务目前主要依靠人工标注,需要耗费大量的时间和人工成本。方面级情感分类标注语料资源有限且主要是英文数据集[10]。中文公开的标注语料匮乏,因此我们引入跨语言情感分类,将英文作为源语言利用其较为丰富的标注语料来提取语义信息,帮助中文数据做情感分类以弥补中文语料不足的缺陷,提高中文情感分类准确率。
针对中文语料匮乏和情感特征重叠的问题,提出了一种基于胶囊网络的跨语言方面级情感分类模型BBCapNet。首先,利用Bert预训练语言模型将文本转化为词向量;其次,采用双向长短期记忆网络学习上下文文本信息;然后利用胶囊网络的动态路由区分重叠特征;最后,利用归一化指数函数进行情感分类。
1 相关工作
1.1 方面级情感分析
与粗粒度情感分类相比细粒度情感分类通常被用于研究精度较高的大型数据集[11]。在大多数情况下,句子可能包含多个具有不同情绪的方面。因此,为了提高的准确性,有必要从不同的方面对情感进行分类。现有的方面级情感分类方法可分为三类:1)基于情感词典的方法,可以根据其相关的情感属性对这些方面进行分类和分类。但是基于情感词典的方法的效率取决于情感词典的质量。2)基于传统机器学习的情感分类方法主要在于情感特征的提取以及分类器的组合选择,不同分类器的组合选择对情感分析的结果有存在一定的影响,这类方法在对文本内容进行情感分析时常常不能充分利用上下文文本的语境信息,存在忽略上下文语义的问题。3)基于深度学习的方法是使用各种神经网络来进行的,典型的神经网络学习方法有:卷积神经网络、递归神经网络、长短时记忆网络等。现阶段的研究更多的是通过对预训练模型的微调和改进,从而更有效地提升实验的效果。
递归神经网络(RNN)是文本分类中应用最广泛的深度神经网络。LSTM是RNN的一种变体,可以学习长期的依赖关系。BiLSTM由两个方向相反的长短期记忆网络组成,每个长短期记忆网络都可以学习到一个时间步骤的隐藏状态,然后将两个方向的隐藏状态拼接起来作为输出。因此BiLSTM可以同时利用文本的正向和反向信息,捕捉文本中的上下文信息。为了模拟方面和句子上下文之间的交互作用,Tang等[12]提出的TC-LSTM模型通过连接方面项与句子,构建目标词和上下文词之间的联系。考虑到句子的不同部分在情感分类过程中的重要程度不同,Wang等[13]提出了基于注意力的LSTM方面嵌入模型ATAE-LSTM,揭示了句子的情感极性不仅由内容决定,而且与所关注的方面高度相关。
1.2 胶囊网络
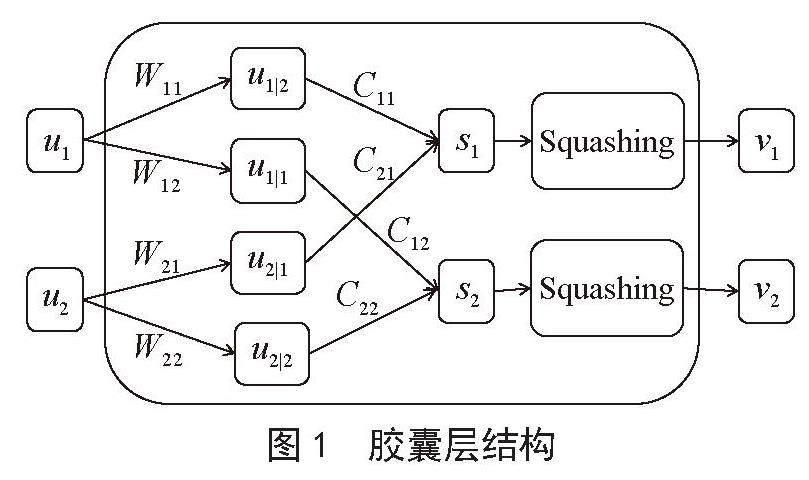
胶囊网络的核心思想是用胶囊层取代传统的卷积神经元。在利用卷积神经网络(CNN)提取特征的过程中,卷积核的大小决定了CNN可以检测到的特征大小,这使得该模型在文本领域发展受限。在文本领域,卷积核太大会使模型难以学习单词之间的关系,而卷积核太小会使模型无法处理倒置、代词等复杂的句子结构。池化操作则会导致文本中大量空间信息丢失。相比之下,胶囊网络不会受到检测单元的结构和大小的限制,可以自动更新接受域,从而学习文本复杂的内部关系[14]。胶囊层是由神经元组成的,不同的是普通神经元接受标量输入再输出标量,而胶囊网络接受向量输入并输出向量。如图1所示的胶囊结构。
图1 胶囊层结构
胶囊网络被提出后,Kim等[15]对于胶囊网络在文本分类领域的发展进行了论证。Zhao等[16,17]最先在文本分类领域使用胶囊网络,并针对文本分类任务提出了三个策略减少背景或者噪音胶囊对网络的影响。此后又提出可扩展的胶囊网络并将其应用于多标签分类和问答领域。为解决一词多义问题,Du等[18,19]将胶囊网络用于方面级情感分类任务中,使用胶囊网络来构建语义的矢量化表示。张[20]在胶囊网络模型上增加了一个嵌入增强模块,使其可以提取长文本上下文语义同时有针对性的重视文本中的关键内容。程等[21]将卷积神经网络与双向GRU网络融合应用于文本情感分析,从而更为全面地提取文本情感特征。以上研究表明,胶囊网络适用于在文本领域。因此,本文将采用胶囊网络来区分重叠特征。
2 BBCapNet模型
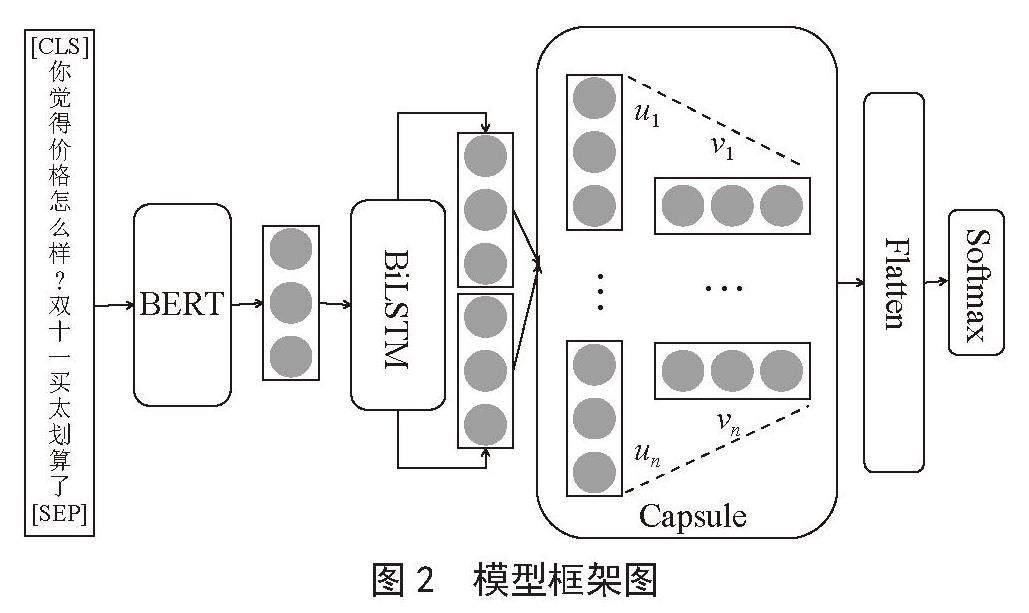
基于胶囊网络的跨语言方面级情感分类模型BBCapNet采用Bert-base(Chinese)模型得到词向量表示,将Bert-base(Chinese)模型的输出作为BiLSTM的输入,再将BiLSTM的输出作为胶囊网络层的输入,最后经过全连接层和Softmax得到最终的情感分类结果。模型如图2所示。
图2 模型框架图
2.1 词嵌入层
将源语言数据集Laptop作为训练集。目标语言中文京东电商评论数据集作为测试集。首先利用谷歌翻译将源语言数据集翻译为目标语言,然后通过Bert-base(Chinese)模型对翻译为中文的训练集和测试集进行编码。Sun等人[4]提出了为方面级情感分析的模型输入构建辅助句的方法。我们将这一方法用于构建带有方面类别的句子表示。将句子和带有方面类别的构造句连成一对。即[CLS]构造句(ai)[SEP]s[SEP],其中s是给定的句子,ai是s对应的某一方面类别,构造句(ai)是为方面类别ai构造的问句。例如,给定句子“双十一买太划算了”,其對应的方面项为“价格”,生成句子对“你觉得价格怎么样?双十一买太划算了”。将句子对输入到Bert-base(Chinese)后,得到有方面项信息的句子s的向量表示v。句子对式的输入,使得方面项与句子的相对位置固定,有益于胶囊网络获取方面项信息和句子整体情感信息的关系。
2.2 语义提取层
将得到的向量v输入到BiLSTM层。BiLSTM包括正向LSTM和反向LSTM,通过正向LSTM和反向LSTM分别获取正向读取文本信息和反向读取文本信息时的特征,再将正向和反向得到的特征进行整合,如式(1)至式(3)所示:
(1)
(2)
(3)
其中,hf表示正向LSTM得到的特征向量,hb表示反向LSTM得到的特征向量,·表示向量拼接。在BiLSTM层每一次训练时,模型以30%的概率使一些节点失效,每一次失效的节点不完全相同,从而使得模型在每次训练过程中都是在训练一个独一无二的模型,最终集成在同一个模型中。从而达到预防过拟合的作用。
得到向量h后,我们将其输入到胶囊网络层,初级胶囊层通过简单的通道切割将特征向量划分为多个初级胶囊h = {u1,u2,…,ui,…,un}然后将位置信息通过仿射变换得到高层胶囊,如式(4)所示:
(4)
其中,ui表示第i个初级胶囊, 其表示经仿射变换得到的高层胶囊,Wij表示其仿射权重。然后,胶囊网络将根据式(5)动态路由高层胶囊。动态路由是一个基于权重Cij的加权和。权重Cij的计算方法如式(6)所示:
(5)
(6)
胶囊层使用协议路由,以类似于聚类的方式给予向量权重。这个过程是通过对低层胶囊i到高层胶囊j的先验概率bij进行Softmax操作来完成的。在投影后的每个空间中,越接近簇中心权重越大。胶囊网络使用路由机制来生成高级特征,根据不同词汇被考虑的程度分配不同的耦合系数,以解决特征重叠的问题[22]。最后为保证输出概率vj的大小保持在0和1之间使用了Squashing函數来进行归一化,如式(7)所示:
(7)
2.3 情感分类层
Softmax层的作用是:将向量映射为(0,1)之间的值,所有值之和为1,即将向量映射为概率,并给出分类结果。将胶囊网络层的输出经过flatten层之后经过Softmax函数得到最终的情感分类极性。
3 实验
3.1 实验设置
实验采用SemEval-2016 Task5中的Laptop评论数据集作为训练集,实验所用的测试集并从京东电商平台爬取关于华为MateBook 16的用户评论。为了统一数据集中的方面类别,将所有评论的方面类别分为质量、性能、硬件、价格、电池、设计、总体。每条评论包含一个或多个方面。将评论的情感分类为对商品有明显好感的正面,对商品有明显反感的负面,以及对商品没有明显情感倾向或前后有矛盾的中性。Laptop评论数据训练集共包含2 082条数据,其中正面评论1 208条,中性评论164条,负面评论710条。京东电商评论数据集共601条,其中正面评论486条,中性评论49条,负面评论66条。由于中文电商评论存在默认好评的现象,在爬取的京东评论数据中去除了系统默认好评。具体实验环境如表1所示。
表1 环境配置
实验环境 具体配置
操作系统 Windows 10
CPU Intel core i5
GPU Tesla P100-PCIE-16 GB
编程语言 Python 3.9
深度学习框架 Keras
在深度学习模型训练的过程中,实验参数的设置不同会产生不同的结果,经过多次实验对比,最终将参数设置如下:BERT编码器生成的表示向量为768维,BiLSTM生成128维的向量,胶囊网络生成5个5维的表示向量,dropout设置为0.3,SGD优化器的学习率设置为0.000 1。使用正确率(Accuracy, Acc)和综合评价指标F1值作为衡量模型性能的指标。
3.2 对比实验
将BBcapNet与其他深度学习模型在相同数据集上进行二分类和三分类的对比实验,其中二分类实验为去除中性评论,只对正面和负面评论做分类。实验对比如下深度学习模型。
W2V_LSTM:使用Word2Vec训练词向量,由LSTM进行特征提取再分类。
Bert_LSTM:使用Bert训练词向量,由LSTM进行特征提取再分类。
Bert_BiLSTM:使用Bert训练词向量,由BiLSTM进行特征提取再分类。
Multi_Bert:陈等[23]提出的一个基于多通道Bert的跨语言属性级情感分类方法。
noQA_BBcapNet:代表本文提出的模型但不使用构造句输入,输入只有句子信息没有方面项信息。QA指第三节中提到的Question+Answer类型的输入构造句。
BBcapNet:指本文提出的模型。
3.3 实验结果与分析
本文在3.1节提出的数据集上进行了多组对比实验,在实验过程中记录了本文所提出的模型与其他模型的对比实验数据。实验结果如表2所示。图3为各模型在三分类时的分类正确率对比图。
从图3的可视化结果可以看出,BBcapNet的分类准确率高于其他模型。从表2可以看出,BBcapNet比文献[23]中提出的Multi_Bert在二分类问题上的准确率和F1值分别提高3.5%和2.8%,三分类问题上的准确率和F1值分别提高了3.5%和10.7%,说明胶囊网络比Multi_Bert使用的金字塔层提取文本特征的效果更好。通过对比Bert_LSTM和W2V_LSTM的实验结果可以发现,使用预训练语言模型Bert作为编码器无论是二分类任务还是三分类任务上的准确率均有提高,这说明Bert相对于Word2Vec可以获取更高效的文本向量表示。Bert_BiLSTM比Bert_LSTM的二分类准确率提高了3.8%,三分类准确率和F1值分别提高了3.0%和2.3%,说明BiLSTM双向提取文本信息的方法比LSTM单向提取文本信息的方法效果更好。BBcapNe比noQA_BBcapNe在二分类和三分类上的准确率都有提升,说明方面项信息的加入有利于模型学习特定方面项与情感极性的关系。BBcapNet比Bert_BiLSTM在三分类问题上的准确率和F1值分别提高了5.6%、2.3%,说明胶囊网络的加入使模型学习到了部分Bert_BiLSTM未能学习到的细节信息。
表2 实验结果
模型 二分类 三分类
Acc F1 Acc F1
Bert_LSTM 88.0 89.1 76.7 78.1
W2V_LSTM 71.5 75.9 58.7 62.2
Bert_BiLSTM 91.8 90.6 79.7 80.4
Multi_Bert 90.5 91.1 80.6 72.0
noQA_BBcapNet 93.4 93.6 79.5 80.5
BBcapNet 94.0 93.9 84.1 82.7
图3 各模型准确率对比图
3.4 性能分析
将BBcapNet与其他5组模型在三分类数据集上花费的时间进行对比分析,T表示一轮迭代训练花费的时间,单位为秒,实验结果如表3所示。从表中可以看出,模型越复杂训练时间越长,Bert模型训练时间远多于Word2Vec模型的训练时间。
表3 模型训练时间
模型 T / s
QA_BBcapNet 63
BBcapNet 63
Multi_Bert 92
Bert_BiLSTM 62
Bert_LSTM 61
W2V_LSTM 16
4 結 论
提出了一种基于胶囊网络的跨语言方面级情感分类方法BBCapNet,该方法将源语料训练集翻译为目标语料后利用BERT模型训练词向量作为嵌入层解决中文文本标准语料不足的问题,然后利用BiLSTM学习上下文信息,利用胶囊网络获取文本中局部信息和整体情感倾向的关系,缓解了不同方面项的不同情感倾向重叠导致的文本分类准确率较低的问题。最后使用归一化指数函数进行分类,通过与多种方法进行对比表明,此方法在跨语言方面级情感分类效果上有显著提升。由于负面评论样本较少,负面评论的分类准确率和F1值都低于正面评论。后续的研究将重点关注如何提升少样本和样本不均衡时模型的分类准确率。
参考文献:
[1] BROWN T B,MANN B,RYDER N,et al. Language Models are Few-Shot Learners [J/OL].(2020-07-22).https://arxiv.org/abs/2005.14165.
[2] YANG Z,DAI Z,YANG Y,et al. XLNet: generalized autoregressive pretraining for language understanding [C]//NIPS'19: Proceedings of the 33rd International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc.,2019:5753-5763.
[3] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2023-05-06].https://arxiv.org/abs/1810.04805v2.
[4] SUN C,HUANG L Y,QIU X P. Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence [J/OL].arXiv:1903.09588 [cs.CL].[2023-054-06].https://arxiv.org/abs/1903.09588v1.
[5] XU H,LIU B,SHU L,et al. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis [J/OL].arXiv:1904.02232 [cs.CL].[2023-05-06].https://arxiv.org/abs/1904.02232.
[6] LI Y C,YIN C X,ZHONG S H,et al. Multi-Instance Multi-Label Learning Networks for Aspect-Category Sentiment Analysis [J/OL].[2023-05-06].https://arxiv.org/abs/2010.02656v1.
[7] KE Z X,XU H,LIU B. Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks [J/OL].arXiv:2112.03271 [cs.CL].[2023-05-06].https://arxiv.org/abs/2112.03271.
[8] RIETZLER A,STABINGER S,OPITZ P,et al. Adapt or Get Left Behind:Domain Adaptation through BERT Language Model Finetuning for Aspect-Target Sentiment Classification [C]//Proceedings of the 12th Language Resources and Evaluation Conference.2020:4933-4941.
[9] BEN DAVID S,BLITZER J,CRAMMER K,et al. A theory of learning from different domains [J].Machine learning,2010,79:151-175.
[10] 趙传君,王素格,李德玉.跨领域文本情感分类研究进展 [J].软件学报,2020,31(6):1723-1746.
[11] MEYER B,BIKDASH M,DAI X F. Fine-grained financial news sentiment analysis [C]//SoutheastCon 2017.Concord:IEEE,2017:1-8.
[12] TANG D,QIN B,FENG X,et al. Effective LSTMs for Target-Dependent Sentiment Classification [J/OL].arXiv:1512.01100 [cs.CL].[2023-05-06].http://arxiv.org/abs/1512.01100.
[13] WANG Y Q,HUANG M L,ZHU X Y,et al. Attention-based LSTM for Aspect-level Sentiment Classification [C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.Austin:Association for Computational Linguistics,2016:606-615.
[14] WANG J,DU J P,SHAO Y X,et al. Sentiment Analysis of Online Travel Reviews Based on Capsule Network and Sentiment Lexicon [J/OL].arXiv:2206.02160 [cs.CL].[2023-05-07].https://arxiv.org/abs/2206.02160.
[15] KIM J,JANG S,CHOI S. Text Classification using Capsules [J].Neurocomputing,2020,376:214-221.
[16] ZHAO W,YE J B,YANG M,et al. Investigating Capsule Networks with Dynamic Routing for Text Classification [C]//Conference on Empirical Methods in Natural Language Processing.Brussels:ACL,2018:3110-3119.
[17] ZHAO W,PENG H Y,EGER S,et al. Towards Scalable and Reliable Capsule Networks for Challenging NLP Applications [J/OL].arXiv:1906.02829 [cs.CL].[2023-05-06].https://arxiv.org/abs/1906.02829.
[18] DU C,SUN H,WANG J,et al. Investigating Capsule Network and Semantic Feature on Hyperplanes for Text Classification [C]//Empirical Methods in Natural Language Processing.Hong Kong:Association for Computational Linguistics,2019:456-465.
[19] DU C,SUN H,WANG J,et al. Capsule Network with Interactive Attention for Aspect-Level Sentiment Classification [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).Hong Kong:Association for Computational Linguistics,2019:5489-5498.
[20] 张旭东.基于深度学习的情感分析技术研究与应用 [D].成都:电子科技大学,2021.
[21] 程艳,孙欢,陈豪迈,等.融合卷积神经网络与双向GRU的文本情感分析胶囊模型 [J].中文信息学报,2021,35(5):118-129.
[22] 徐志栋,陈炳阳,王晓,等.基于胶囊网络的方面级情感分类研究 [J].智能科学与技术学报,2020,2(3):284-292.
[23] 陈潇,王晶晶,李寿山,等.基于多通道 BERT的跨语言属性级情感分类方法 [J].中文信息学报,2022,36(2):121-128.
作者简介:梁慧杰(1999—),女,汉族,安徽阜阳人,硕士研究生在读,研究方向:自然语言处理;通讯作者:任萍(1982—),女,汉族,安徽泗县人,讲师,博士,研究方向:自然语言处理。
