
基于BERT与细粒度特征提取的数据法学问答系统
2024-05-30 19:13宋文豪汪洋朱苏磊张倩吴晓燕
上海师范大学学报·自然科学版 2024年2期
宋文豪 汪洋 朱苏磊 张倩 吴晓燕

摘 要: 首先利用bidirectional encoder representations from transformers(BERT)模型的強大的语境理解能力来提取数据法律文本的深层语义特征,然后引入细粒度特征提取层,依照注意力机制,重点关注文本中与数据法律问答相关的关键部分,最后对所采集的法律问答数据集进行训练和评估. 结果显示:与传统的多个单一模型相比,所提出的模型在准确度、精确度、召回率、F1分数等关键性能指标上均有提升,表明该系统能够更有效地理解和回应复杂的数据法学问题,为研究数据法学的专业人士和公众用户提供更高质量的问答服务.
关键词: bidirectional encoder representations from transformers(BERT)模型; 细粒度特征提取; 注意力机制; 自然语言处理(NLP)
中图分类号: TP 3911 文献标志码: A 文章编号: 1000-5137(2024)02-0211-06
Data law Q&A system based on BERT and fine-grained feature extraction
SONG Wenhao1, WANG Yang1*, ZHU Sulei1, ZHANG Qian1, WU Xiaoyan2*
(1.College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 201418, China; 2.School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract: A data legal question and answer system was proposed based on bidirectional encoder representations from transformers(BERT) model and fine-grained feature extraction to provide accurate professional legal consulting services. Firstly, the powerful contextual understanding ability of the BERT model was leveraged to extract deep semantic features from data legal texts. Subsequently, a fine-grained feature extraction layer was introduced which mainly focused on key components related to data legal Q&A within the text using an attention mechanism. Finally, the collected legal Q&A dataset was trained and evaluated. The results indicated that compared to traditional multiple single models, the proposed model showed improvements in key performance indicators such as accuracy, precision, recall, and F1 score, which suggested that the system could more effectively comprehend and address complex issues in data law, providing higher quality Q&A services for both research data law professionals and the general public.
Key words: bidirectional encoder representations from transformers(BERT) model; fine-grained feature extraction; attention mechanism; natural language processing (NLP)
0 引言
在众多深度学习模型中,bidirectional encoder representations from transformers(BERT)模型[1]因在各类自然语言处理(NLP)任务上表现卓越而备受关注. 通过预训练的语言表示,BERT模型能够捕捉到文本中丰富的语义信息. 然而,法学文本的专业性和复杂性要求问答系统不仅要理解自然语言,还需要对法律术语和概念有深入的理解[2].
数据法学[3]是一门新兴学科,主要研究与数据相关的法律问题[4]. 数据法学融合了法学、计算机科学、信息技术及隐私保护等多个学科的知识和方法,具有多学科交叉的特点,因此,该领域的研究人员不仅需要具备扎实的法律基础,还需要掌握数据管理、数据保护及数据安全等相关科技术语.
细粒度语义[5]是一种深度理解文本的能力,涉及对语句中每个单词、短语以及其上下文的逐层分析和理解. 在基于BERT模型的数据法学问答系统中,因为法律问题往往具有复杂的语境和严密的逻辑结构,对于细粒度语义的应用至关重要. 在构建基于BERT的数据法学问答系统时,细粒度语义分析是确保系统能够准确理解和回答复杂法律问题的核心组成部分. 传统的问答系统通常通过浅层次的语法和词法规则来理解问题,然而,法律问题往往涉及深层次的法律概念和逻辑关系,需要更高层次的语义理解. 细粒度语义分析通过深度学习模型,能够捕捉语句中每个单词和短语的丰富语义信息,同时考虑其上下文的关系. 这种深度的语义理解使得系统能够更好地理解法律问题的隐含意思、逻辑关系,从而提高了问答系统对复杂法律场景的适应能力.
本文作者提出了一种识别并关注法律文本中关键信息的细粒度特征提取方法,通过结合BERT模型的深层语义理解能力和注意力机制[6]的细粒度分析,系统能够在处理复杂法律问题时,提供更准确、更具解释性的答案,为相关专业人士和公众用户提供了一个高效的法律咨询工具,有助于降低法律服务的门槛,促进法律资源的公平和高效分配.
1 数据处理与系统开发
1.1 数据采集与处理
针对各种数据法学相关的书籍资料文本,生成可以捕获文本资料核心内容的不同难度和不同形式的问答数据. 将文本内容转换成json格式文件,将其分割成数千篇章,并从中预生成一系列答案. 答案主要包括两种类型:文本中句子片段和文本中抽取的命名实体(NER)[7]. 在完成句子划分时,先将句子中可能出现的英文符号,替换为对应的中文字符,随后按照句号、逗号、分号等进行短句划分. 利用NER技术抽取文本中的实体,包括数字、日期、专用名等. 此外,针对于数据法学在各种现实生活所会出现的案例,采用爬虫技术,在网络上获取了数千条有关数据法相关的法律咨询问答. 为了去除噪声,对数据进行了人工标注,然后将爬取的数据和阅读理解数据集SQuAD与中文法律阅读理解数据集CJRC[8]融合训练,CJRC数据集包含约10 000篇文档,来源于裁判文书网. 通过抽取裁判文书的事实描述内容(“经审理查明”或者“原告诉称”部分),针对事实描述内容标注问题,最终形成约50 000个面向数据法学的问答内容.
将各数据集整理、融合为相同的格式,并乱序处理,剔除空白字符、带括号的英文,截取文本,限制其长度,删除不需要的信息.
1.2 系统构建
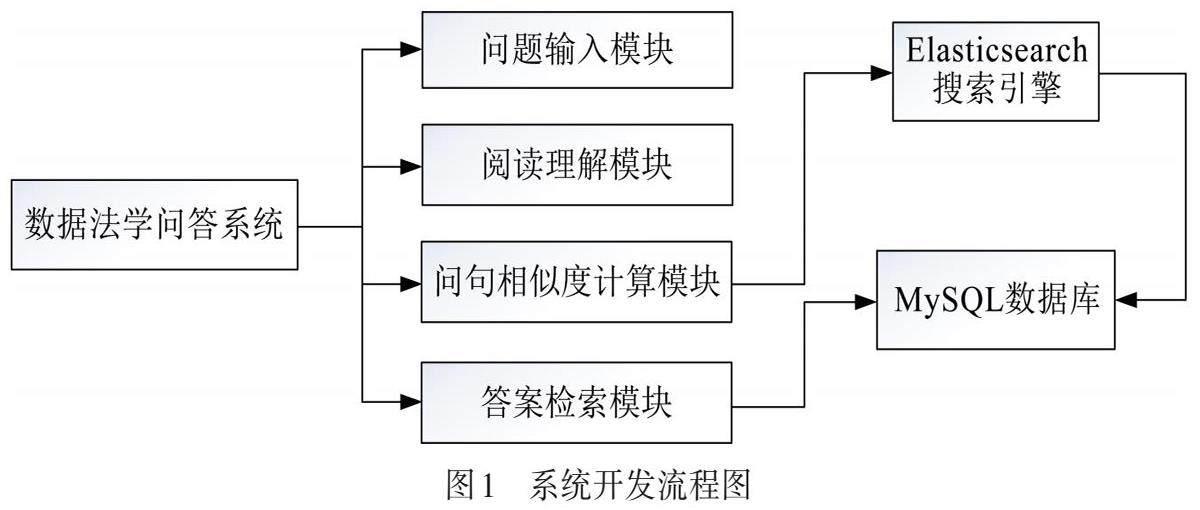
系统由问题输入模块、阅读理解模块、问句相似度计算模块及答案检索模块组成,如图1所示. 用户通过问题输入模块,可注册、登录系统,提出自然语言问题.通过阅读理解模块将用户输入的问题进行向量转化,通过问句相似度计算模块将问句向量与向量库进行相似度计算. 本系统使用MySQL数据库对问答数据进行储存,通过高度可扩展且开源的分布式全文检索引擎Elasticsearch从数据库MySQL中检索并输出答案.
2 模型及算法
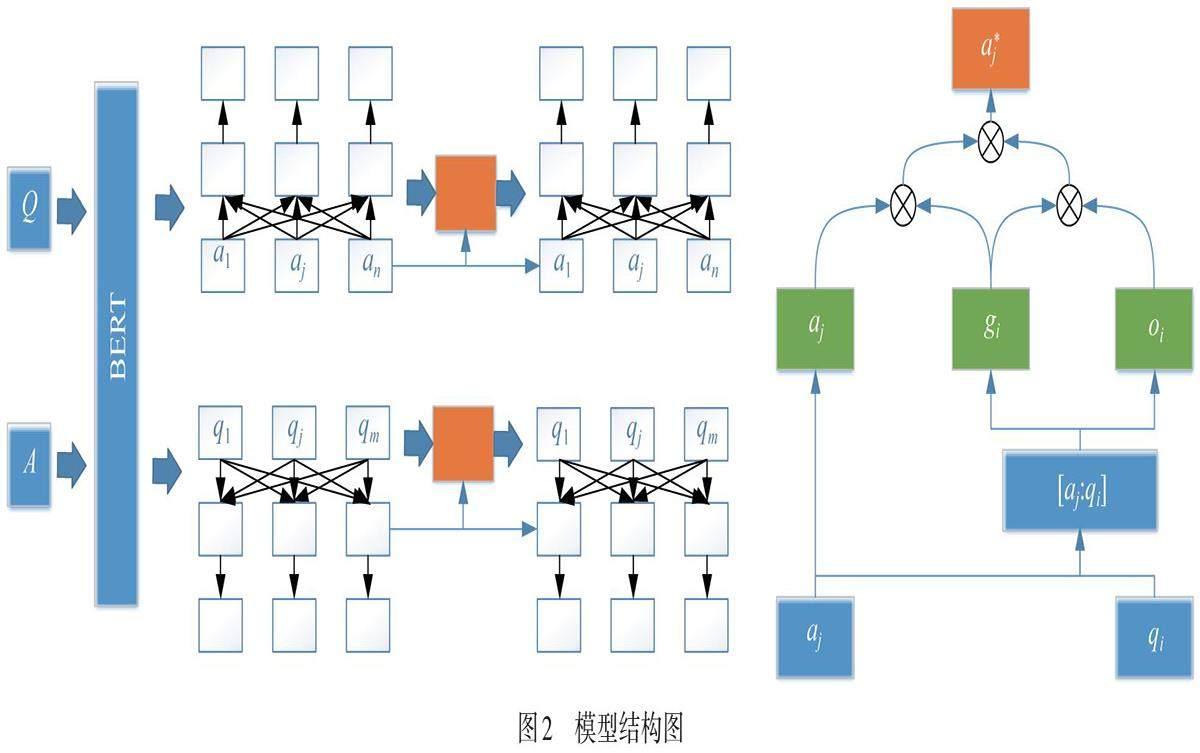
由于法律语言通常比较复杂、正式且常常存在歧义,采用细粒度特征提取方法[9-10],识别并关注法律文本中的关键信息. 通过结合BERT模型的深层语义理解能力和注意力机制的细粒度分析,系统能够在处理复杂法律问题时提供更准确、更具解释性的答案,模型结构图如图2所示.
对候选答案集合根据语义匹配度进行排序,将排名第一的答案作为正确答案. 模型主要分为输入层、语义匹配层、特征提取层、输出层四个部分.
输出层:对于一个问答对Q和A,Q=![]() ,A=
,A=![]() ,n和m為问题和答案的长度. 用 BERT 模型对输入的问题和答案进行编码,得到问题和答案的句子特征,
,n和m為问题和答案的长度. 用 BERT 模型对输入的问题和答案进行编码,得到问题和答案的句子特征,
Q=BERT(Q) , (1)
A=BERT(A) . (2)
需要对Q和A中每个词进行细粒度语义对齐,将两者间的语义匹配结果输入特征提取层. 首先,计算问答对之间的余弦相似度
![]() . (3)
. (3)
对![]() 通过公式进行归一化处理,
通过公式进行归一化处理,
![]() , (4)
, (4)
其中,![]()
![]()
根据注意力分数对![]() 作进一步表示:
作进一步表示:
![]() , (5)
, (5)
![]() , (6)
, (6)
其中,α为注意力分数;c*为注意力分数的加权求和.
为了实现细粒度语义对齐,保留重要信息作为下一步匹配层的输入,对答案进行细粒度特征提取,保留重要信息. 通过门控机制,可以共享问题和答案的公共语义信息. 门控
![]() , (7)
, (7)
其中,![]() 为门控函数;
为门控函数;![]() 和
和![]() 为2个门控参数.
为2个门控参数.![]() 的作用是过滤无用、琐碎的信息,保留
的作用是过滤无用、琐碎的信息,保留![]() 中可以与A共享的语义信息. 激活函数
中可以与A共享的语义信息. 激活函数
![]() , (8)
, (8)
其中,![]() 和
和![]() 为2个激活参数.
为2个激活参数.![]() 的作用是使模型能夠学习更加复杂的关系和模式. 更新
的作用是使模型能夠学习更加复杂的关系和模式. 更新![]() ,
,
![]() . (9)
. (9)
计算问题![]() 与答案A的匹配分数
与答案A的匹配分数![]() ,
,
![]() (10)
(10)
其中,![]() 是模拟函数;
是模拟函数;![]() 是经过k-1步特征提取后问题的特征,然后将匹配分数相加,
是经过k-1步特征提取后问题的特征,然后将匹配分数相加,
![]() . (11)
. (11)
同样地,
![]() . (12)
. (12)
损失函数
![]() , (13)
, (13)
其中,![]() 分别表示正确答案间的匹配分数和其他候选答案间的匹配分数.
分别表示正确答案间的匹配分数和其他候选答案间的匹配分数.
3 实验及结果
为了验证本方法的有效性和准确性,在AMD Ryzen 7 5800H处理器、8 GB内存、RTX3060显卡、Windows11(64-bit)操作系统、Pycharm 2022.1、Python3.9.8开发环境下进行实验. 本实验采用BERT模型(Base版本),该模型包含12头注意力机制,隐藏层的维度为768维,参数为1.1×108个,句子最长序列为64,每个批次的数据量为64,学习率为1.0×10-5,迭代次数为3,丢失率为0.3.
表1是与BERT,RoBERTa,ALBERT和GPT-3的模型性能对比.
从表1中可以看出,本模型在准确度、精确度、召回率和F1分数上均表现优异.
本系统基于Django Web框架开发,使用过程中,先向系统询问一个自然语言问题,系统根据提问从Elasticsearch中检索出相匹配的内容,作为召回候选集,通过本研究的模型对答案进行预测,输出匹配度最高的答案. 系统的运行界面及示意图如图3所示.
4 结论
本文作者基于BERT模型开发了数據法学问答系统,通过细粒度特征提取,提高问答系统在数据法学场景下的理解和应用能力.通过实验证明了系统在解决真实法律问题时表现出色,为法学研究者和从业者提供了一个智能的信息获取工具.
参考文献:
[1] DEVLIN J, CHANG M W, LEEK, et al. Bert: pre-training of deep bidirectional transformers for language understanding [J]. arXiv: 1810.04805, 2018.https:// arxiv.org/abs/1810.04805v2.
[2] 丁红卫. 人工智能透过言语语言识别精神障碍 [J]. 上海师范大学学报(哲学社会科学版), 2023,52(4):24-34.
DING H W. Artificial intelligence identifies mental disorders through speech and language [J]. Journal of Shanghai Normal University ( Philosophy & Social Sciences Edition), 2023,52(4):24-34.
[3] 王齐齐. 全球大数据法学研究现状、热点与前沿 [J]. 江汉学术, 2023,42(5):24-32.
[4] 莫骅. 大数据时代背景下的法学研究新趋势 [J]. 法制博览, 2021(22):185- 186.
[5] 范东旭, 过弋. 基于可信细粒度对齐的多模态方面级情感分析[J]. 计算机科学, 2023,50(12):246-254.
FAN D X, GUO Y. Aspect-based multimodal sentiment analysis based on trusted fine-grained alignment [J]. Computer Science, 2023,50(12):246-254.
[6] CUI Y M, CHE W X, LIU T, et al. Pre-training with whole word masking for Chinese BERT [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021,29:3504-3514.
[7] ZHANG N X, LI F, XU G L, et al. Chinese NER using dynamic meta-embeddings [J]. IEEE Access, 2019,7:64450-64459.
[8] LEE C H, LEE H Y, WU S L, et al. Machine comprehension of spoken content: TOEFL listening test and spoken SQuAD [J] IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019,27(9): 1469-1480.
[9] XIANG Y, CHEN Q C, WANG X L, et al. Answer selection in community question answering via attentive neural networks [J].IEEE Signal Processing Letters, 2017,24(4):505-509.
[10] 荣光辉, 黄震华. 基于深度学习的问答匹配方法 [J]. 计算机应用, 2017,37(10):2861-2865.
RONG G H, HUANG Z H.Question answer matching method based on deep learning[J].Journal of Computer Applications,2017,37(10):2861-2865.
(责任编辑:包震宇,郁慧)
DOI: 10.3969/J.ISSN.1000-5137.2024.02.010
收稿日期: 2023-12-23
基金项目: 上海市科学仪器领域项目(22142201900); 教育部重大项目(20JZD020); 国家自然科学基金(62301320)
作者简介: 宋文豪(1999—), 男, 硕士研究生, 主要从事自然语言处理方面的研究. E-mail:1245355011@qq.com
* 通信作者: 汪洋(1986—), 男, 副教授, 主要從事人工智能应用技术方面的研究. E-mail:wyang@shnu.edu.cn;吴晓燕(1990—), 女, 副研究员, 主要从事人工智能在计算成像方面的研究. E-mail:wuxiaoyan151@126.com
引用格式: 宋文豪, 汪洋, 朱苏磊, 等. 基于BERT与细粒度特征提取的数据法学问答系统 [J]. 上海师范大学学报 (自然科学版中英文), 2024,53(2):211?216.
Citation format: SONG W H, WANG Y, ZHU S L, et al. SONG Wenhao, WANG Yang, ZHU Sulei, et al. Data law Q&A system based on BERT and fine-grained feature extraction [J]. Journal of Shanghai Normal University (Natural Sciences), 2024,53(2):211?216.
猜你喜欢
红外技术(2022年11期)2022-11-25
南大法学(2021年3期)2021-08-13
南大法学(2021年6期)2021-04-19
高技术通讯(2021年1期)2021-03-29
南大法学(2021年4期)2021-03-23
电子制作(2018年19期)2018-11-14
电脑与电信(2018年11期)2018-02-16
自动化学报(2017年11期)2017-04-04
信息安全研究(2016年3期)2016-12-01
新校长(2016年5期)2016-02-26
