
高效联邦学习:范数加权聚合算法
2024-05-24 17:07陈攀张恒汝闵帆
计算机应用研究 2024年3期
关键词:隐私保护
陈攀 张恒汝 闵帆

摘 要:在联邦学习中,跨客户端的非独立同分布(non-IID)数据导致全局模型收敛较慢,通信成本显著增加。现有方法通过收集客户端的标签分布信息来确定本地模型的聚合权重,以加快收敛速度,但这可能会泄露客户端的隐私。为了在不泄露客户端隐私的前提下解决non-IID数据导致的收敛速度降低的问题,提出FedNA聚合算法。该算法通过两种方法来实现这一目标。第一,FedNA根据本地模型类权重更新的L1范数来分配聚合权重,以保留本地模型的贡献。第二,FedNA将客户端的缺失类对应的类权重更新置为0,以缓解缺失类对聚合的影响。在两个数据集上模拟了四种不同的数据分布进行实验。结果表明,与FedAvg相比,FedNA算法达到稳定状态所需的迭代次数最多可减少890次,降低44.5%的通信开销。FedNA在保护客户端隐私的同时加速了全局模型的收敛速度,降低了通信成本,可用于需要保护用户隐私且对通信效率敏感的场景。
关键词:联邦学习;通信成本;隐私保护;非独立同分布;聚合;权重更新
中图分类号:TP181 文献标志码:A
文章编号:1001-3695(2024)03-008-0694-06
doi:10.19734/j.issn.1001-3695.2023.07.0327
Efficient federated learning:norm-weighted aggregation algorithm
Chen Pana,b,Zhang Hengrua,b,Min Fana,b
(a.School of Computer Science,b.Laboratory of Machine Learning,Southwest Petroleum University,Chengdu 610500,China)
Abstract:In federated learning,the non-independent and identically distributed(non-IID) data across clients leads to slower convergence of the global model and significantly increases communication costs.Existing methods collect information about the label distribution of clients to determine aggregation weights for local models,accelerating convergence,but this may leak clients privacy.To address the slower convergence caused by non-IID data without leaking clients privacy,this paper proposed the FedNA aggregation algorithm.FedNA achieved this goal in two ways.Firstly,it assigned aggregation weights based on the L1 norm of the class weight updates of local models to retain their contributions.Secondly,it set the class weight updates corresponding to missing classes at the clients to 0 to mitigate their impact on aggregation.Experiments were conducted under four different data distributions on two datasets.The results show that compared to FedAvg,the FedNA algorithm can reduce the number of iterations required to reach steady state by 890 at best,lowering communication costs by 44.5%.FedNA maintains clients privacy while accelerating the convergence of the global model and decreasing communication costs.It is suitable for situations that need to protect clients privacy and are sensitive to communication efficiency.
Key words:federated learning;communication cost;privacy protection;non-IID;aggregation;weight updates
0 引言
聯邦学习(federated learning,FL)[1~5]是一种分布式机器学习范式,旨在解决隐私保护和数据孤岛问题[6]。FL结合本地计算和模型传输的思想解决中心化机器学习方法的隐私风险[7]。在训练过程中,客户端将数据保存在本地,仅将本地模型训练得到的权重更新上传到服务器。服务器将客户端上传的本地模型的权重更新进行聚合以更新全局模型,然后将更新后的全局模型发送回客户端作为新的本地模型。通过重复的本地训练和服务器聚合,最终得到一个最优的全局模型。
FL系统中客户端之间的数据通常是非独立同分布(non-IID)[7]的。例如,客户端A可能是一家小型医院,主要收治年轻人,而客户端B可能是一家大型综合医院,收治各个年龄段的患者。这两个医院的患者数据在年龄分布上存在明显的差异。数据的non-IID会使FL的收敛速度受到很大影响,导致通信成本显著增加。聚合方法在FL中起着重要作用,它对全局模型的收敛速度有着显著的影响。FedAvg[2]是FL中常用的聚合算法,其核心思想是客户端拥有的数据量越大,在模型聚合时赋予其本地模型的权重就越高。由于它没有考虑在non-IID数据下不同本地模型的贡献差异,所以具有较高的通信成本。FedCA-TDD[1]保留了不同本地模型的贡献,提高了FL的收敛速度,但其需要收集客户端样本的标签分布信息。出于隐私原因,服务器不应从客户端收集任何有关其本地训练样本的信息。
实验发现,客户端上传的本地模型权重更新的分类器部分能反映本地模型对全局模型的贡献。基于此,本文提出了联邦范数加权聚合(federated norm weighted aggregation,FedNA),它在不收集任何客户端隐私数据的前提下,能够降低FL的通信成本。FedNA根据每个本地模型对全局模型的贡献大小,动态确定其在联邦聚合时的权重系数。具体来说,对于模型的特征提取器部分,贡献被定义为客户端训练数据的数据量。对于模型的分类器部分,贡献被定义为模型类权重更新的L1范数。此外,如果客户端的数据集缺失某些类别,则将对应类别的权重更新置零,以减少其所带来的负面影响。实验结果表明,FedNA与其他先进方法相比,显著降低了通信成本。
1 相关工作
1.1 联邦学习
传统的FL系统由K个客户端和一个服务器组成,客户端由[K]进行索引。客户端k拥有本地数据集Dk,整个FL系统中的数据表示为D=∪k∈[K]Dk,其包含了C个类别的数据。FL系统的每一次迭代过程包含了客户端选择、本地模型训练、模型权重更新传输和服务器端聚合。在第t次迭代中,服务器将最新的全局模型ωtglobal分发给随机选择的U个由[U]t索引的客户端。随后,客户端k∈[U]t使用本地数据对模型进行优化,目标函数为
ωt+1global=ωtglobal+∑k∈[U]t|Dk|∑k′∈[U]t|Dk′|Δωtk(2)
1.2 联邦学习的非独立同分布
现有的一些研究[2,9,10]表明,non-IID数据是FL的一个重大挑战。由于用户行为的多样性,来自不同客户端的训练数据存在显著差异。例如,不同地区的植被数据由于维度、气候等因素的影响,往往服从不同的分布。non-IID的数据会导致FL模型的准确率降低,同时也会增加通信成本。
关于FL在non-IID数据上的模型准确率的研究有很多。Zhao等人[11]提出在客户端之间共享一个小的公共数据集,以缓解客户端之间数据的non-IID,这与FL的初衷相悖[12~14]。与训练单个全局模型的方法不同,Arivazhagan等人[15]提出在每个客户端上设计训练个性化模型,以缓解non-IID带来的准确率下降问题。Li等人[9]提出为客户端的局部目标函数添加一个近端项,以提高整体收敛的稳定性。Wang等人[16]设计了一种FL客户端选择机制,以获得均匀的数据分布,提高模型的准确率。
1.3 联邦学习的通信成本
在FL中,客戶端和服务器之间需要不断进行数据传输,因此通信成本是一个挑战。一些学者提出应用模型压缩技术来减少传输的信息量,从而降低通信成本。Shi等人[17]提出将训练算法与局部计算、梯度稀疏Flexible Sparsification相结合,从而减少迭代的总数。Sattler等人[18]扩展了现有的top-k梯度稀疏化,提出了Sparse Ternary Compression压缩框架。Han等人[19]通过修剪、训练量化和霍夫曼编码对DNN模型进行深度压缩。还有一些研究考虑发送不频繁的权重更新。Gao等人[20]提出一种错误补偿双压缩机制的通信高效分布式SGD方法得到更低的通信复杂度。Nishio等人[21]提出选择尽可能多的设备参与每次训练迭代,从而减少通信迭代的总数。此外,郑赛等人[22]基于生成模型生成模拟数据实现一轮通信完成模型训练,减少了通信数量。Ma等人[1]提出了FedCA-TDD,基于类加权聚合策略提高了FL系统的收敛速度,降低了通信成本。
2 联邦范数加权聚合
2.1 问题设置
考虑一个传统的FL系统,其中一个服务器和多个客户端协作训练一个分类模型。从功能来看,分类模型可以看作是由特征提取θ和分类器w={wc}Cc=1组成,其中{wc}Cc=1称为类权重(class weight)。整个分类模型的参数表示为ω={θ,w}。FL的一个主要特点是分布式环境下的频繁通信。每轮训练迭代需要将模型权重更新从各客户端发送到服务器,然后再将全局模型参数分发给各客户端。客户端数据间的non-IID导致通信成本的显著增加。本文目标是在维持模型性能的前提下减少模型参数传输来减轻通信开销。最近的一项研究[23]表明,FL中的non-IID场景可以细分为特征分布偏斜、标签分布偏斜、不同特征下的概念转移、不同标签下的概念转移和数量偏斜五个类别。标签分布偏斜和数量偏斜是本文的主要关注点。
2.2 核心思想
在联邦学习中,non-IID数据导致各客户端对不同类别样本的贡献存在差异。具体而言,某一类样本较丰富的客户端对该类别的参数拟合贡献更大。如何在不收集客户端隐私数据的前提下在聚合时对客户端的贡献进行保留是一个挑战。为了探究类别权重更新在反映客户端贡献方面的潜力,本文进行了实验研究。为简化问题,在有10个客户端的FL系统中使用MNIST数据集进行实验。可视化本地模型训练过程中的类权重更新{Δwc}Cc=1的L1范数,如图1所示。结果显示,{Δwc}Cc=1的L1范数的模式与客户端训练样本标签分布的模式呈现出相似性。
基于此,从本地模型的类权重更新中提取本地模型对全局模型的贡献。此外,先前的一些研究表明[24~26],客户端训练样本的标签分布或数量分布偏移的影响更多体现在模型中的分类器上,分类器对偏移更敏感。由此,本文对客户端上传的模型权重更新的特征提取器和分类器两个部分,分别采用不同的方法确定权重进行加权平均。在特征提取器部分,客户端本地训练数据的数量定义为权重,这与FedAvg相似。在分类器部分,客户端本地模型的类权重更新的L1范数定义为权重。通过类权重更新L1范数对分类器权重更新进行加权平均,能够保留本地模型对不同类别的贡献。
此外,softmax函数在分类任务中发挥着重要作用。在训练过程中,当输入样本标签为1时,softmax将对应类别的类权重推向该类别的特征中心,同时将其他类别的类权重拉离该类别特征中心。最终,各类别的类权重接近各自的特征中心,如图2(a)所示。然而,在FL中,客户端可能仅包含部分类别的训练样本,将不存在的类别称为客户端的缺失类。因此,在客户端的本地训练期间,对应于缺失类的类权重可能出现偏移,如图2(b)和(c)所示。图中,不同颜色的小圆代表不同类别样本的特征。图(a)客户端有所有类别的样本,类权重接近特征中心;图(b)和(c)客户端缺少某些类别的样本,类权重远离特征中心。缺失类的类权重更新会在聚合期间对模型收敛产生负面影响。因此,如果客户端没有某个类别的训练样本,本文考虑将该类别对应的类权重更新置0。
图3显示了FedNA和FedAvg在non-IID情况下的分类器部分的聚合结果。可以看出,FedNA能够保留本地模型对每个类别的贡献,其聚合后的L1范数接近于本地模型类别权重更新的L1范数。同时,FedNA仅依赖于客户端上传的模型参数,不收集任何额外隐私数据,避免了FedCA-TDD算法需要收集类别分布信息的隐私风险,对用户隐私提供了保护。虽然FedNA所使用的分类器的L1范数可以在一定程度上反映客户端的标签分布,但这种反映具有很大的误差,图1也印证了这一点。
2.3 FedNA算法
FedNA算法对分类模型的两个部分使用不同的加权策略。对于特征提取器部分,客户端本地训练样本的数量决定权重;对于分类器部分,类权重更新的L1范数决定了其权重。客户端k类权重的聚合权重定义如下:
3 实验
3.1 实验设置
1)数据集
在MNIST[27]和EMNIST Balanced[28]数据集上评估了本文方法和基准方法,数据集的统计信息如表1所示。为了模拟真实世界的FL系统,需要将数据集的训练数据按照一定策略分配给每个客户端,每个客户端都有自己的本地训练集。为了模拟FL中客户端之间数据的non-IID场景,本文采用了如下两种方案:
a)按照文獻[29,30]的方法对pc~Dirk(α)进行采样,并按照pc,k的比例随机分配c类训练数据给客户端k。non-iid(α)用于表示这种模拟方法,其中α用于控制non-IID的程度,较小的α值对应更不平衡的数据分布。
b)首先将数据集中的数据按类别进行排序,然后将这些数据分成100×s个分片。每个客户端从这些分片中随机选择s个分片作为本地训练集。由于所有分片都具有相同的大小,所以客户端具有相同数量的训练样本。non-iid-bs(s)用于表示这种模拟方法,其中s用于控制客户端拥有的分片数量,较小的s值对应于更不平衡的数据分布。
2)FL系统设置
实验中,FL系统的默认设置如表2所示。客户端本地训练使用随机梯度下降优化器进行优化,动量参数设为0.5,损失函数为交叉熵。客户端本地训练中使用了两个自定义的CNN模型。第一个模型用于MNIST数据集的训练,其网络结构如表3所示,第二个更复杂的模型则用于EMNIST Balanced数据集的训练,其网络架构如表4所示。
3)评价指标
本文采用了以下三个指标评价本文方法与基准方法。
a)全局模型的测试准确性。即最后30次迭代的全局模型在测试数据集上的测试准确率的均值和标准差,用于评估模型的全局表现。
b)首次到达预期准确率所需的迭代次数。用于比较不同算法的收敛速度。
c)稳定在预期准确率所需的迭代次数。在数据为non-IID的情况下,FL训练过程中的测试准确率会出现波动,所以需要考虑到达稳定状态所需的迭代次数。如果连续10次记录的测试准确率都超过了预期准确率,则认为模型稳定在预期准确率,到达稳定状态。
预期准确率的设置遵循实验结果。不同数据集在不同分布下,本文取各方法最后30次迭代的平均测试准确率的最小值,然后保留两位有效数字作为预期准确率。表5展示了不同数据集在不同分布下的预期准确率。
3.2 实验结果
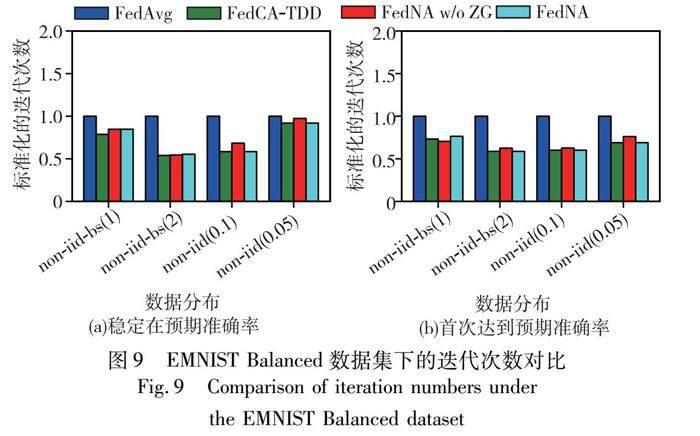
本文在两个数据集上的四种数据分布下对FedNA和基线方法进行了评估,测试准确率曲线如图4~7所示。其中,FedNA w/o ZG表示未使用权重更新置零(ZG)的FedNA。从图4~7可知,在收敛速度方面,FedNA表现明显优于FedAvg,与FedCA-TDD几乎相同。值得注意的是,FedNA无须收集客户端本地数据的标签分布。FedNA w/o ZG的收敛速度也优于FedAvg,这对于那些对隐私要求较高的场景非常有帮助。此外,随着non-IID程度的增加,FedNA在收敛速度上的优势变得更加明显。
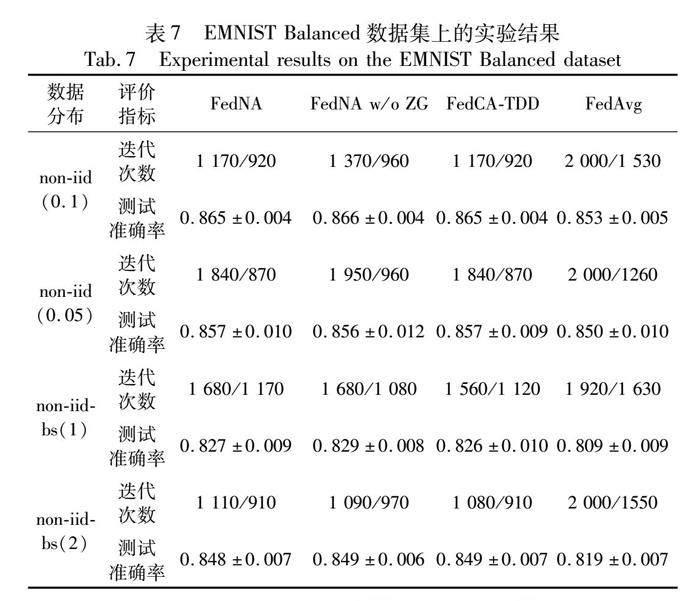
本文方法和基线方法的评价指标结果如表6、7所示。迭代次数这一行“/”左右的两个数字分别为稳定在预期准确率和首次达到预期准确率的迭代次数。此外,本文将所有方法的迭代次数以FedAvg为基准进行标准化和可视化,结果如图8、9所示。通过观察表6、7和图8、9可以得出结论,在大多数情况下,FedNA需要的迭代次数明显少于FedAvg,与FedCA-TDD几乎相同。例如,在non-iid-bs(2)分布下的EMNIST Balanced数据集中,FedNA和FedCA-TDD稳定在预期准确率和首次达到预期准确率的迭代次数分别为1 110/910和1 080/910,而FedAvg为2 000/1 550。FedNA w/o ZG与FedAvg相比也表现出明显的优势。例如,在non-iid-bs(1)分布下的EMNIT Balanced数据集中,FedNA w/o ZG稳定在预期准确率和首次达到预期准确率的迭代次数分别为1 680/1 080,而FedAvg为1 920/1 630。FL训练的总通信成本是通过计算每轮通信成本乘以达到目标准确率所需的训练迭代次数得到的[1]。FedNA每次迭代的传输数据量与FedAvg相同,但达到目标准确率所需的迭代次数更少,降低了总通信成本。值得注意的是,在non-iid-bs(2)分布下的EMNIST Balanced数据集中,FedNA达到稳定状态所需的迭代次数比FedAvg少890次,可降低44.5%的通信成本。
本文測试了FedCA-TDD、FedNA、FedNA w/o ZG和FedAvg算法最终的测试准确率。结果显示,FedNA、FedNA w/o ZG、FedCA-TDD的平均测试准确率分别为0.917、0.916和0.916,而FedAvg为0.905。FedAvg准确率略低于本文方法。例如,在EMNIST Balanced数据集上的non-iid-bs(1)和non-iid-bs(2)分布下,FedNA分别为0.827和0.848,而FedAvg分别为0.809和0.819。这表明,在提高收敛速度、减低通信成本的同时,本文方法并未对模型性能产生不利影响。
3.3 消融实验
本文对没有NA或ZG的FedNA在不同分布下的EMNIST Balanced数据集上进行消融实验,结果如表8所示。对比FedNA w/o NA和FedAvg可以发现,NA可以提高FedNA的收敛速度。例如,在数据分布为non-iid(0.1)时,FedNA w/o NA稳定在预期准确率和首次达到预期准确率的迭代次数分别为1 130/890,而FedAvg为2 000/1 530。此外,对比FedNA w/o ZG和FedNA的迭代次数可以发现,ZG也可以提高FedNA的收敛速度。例如,在数据分布为non-iid(0.05)时,FedNA w/o NA稳定在预期准确率和首次达到预期准确率的迭代次数分别为1 950/960,而FedAvg为2 000/1 260。综上,ZG和NA对最终收敛速度的提升都有不同程度的贡献。
4 结束语
本文提出了一种新的联邦学习聚合方法FedNA,旨在降低在non-IID数据下的联邦学习的通信成本。FedNA根据客户端的类权重更新的L1范数为客户端分配权重,保留了本地模型的贡献。此外,FedNA将客户端缺失类的类权重更新设置为零,消除了其在聚合时对模型的负面影响。本文在两个数据集上模拟了四种数据分布来进行实验。结果表明,与FedAvg相比,FedNA算法最多可以减少44.5%的通信开销。与现有方法相比,FedNA既有效地保护了客户端的隐私,又加速了全局模型的收敛速度,降低了通信成本。
在未来的工作中,笔者将探索在不同的训练阶段如何自适应地调整类加权策略,从而实现更加高效的聚合策略。
参考文献:
[1]Ma Zezhong,Zhao Mengying,Cai Xiaojun,et al.Fast-convergent federated learning with class-weighted aggregation[J].Journal of Systems Architecture,2021,117:102125.
[2]McMahan H B,Moore E,Ramage D,et al.Communication-efficient learning of deep networks from decentralized data[C]//Proc of International Conference on Artificial Intelligence and Statistics.[S.l.]:PMLR,2017:1273-1282.
[3]Konecˇny J,McMahan H B,Yu F X,et al.Federated learning:strategies for improving communication efficiency[EB/OL].(2017-10-30).https://arxiv.org/abs/1610.05492.
[4]McMahan H B,Moore E,Ramage D,et al.Federated learning of deep networks using model averaging[EB/OL].(2016-02-17).https://arxiv.org/abs/1602.05629v1.
[5]Konecˇny J,McMahan H B,Ramage D,et al.Federated optimization:distributed machine learning for on-device intelligence[EB/OL].(2016-10-08).https://arxiv.org/abs/1610.02527.
[6]Zhai Kun,Ren Qiang,Wang Junli,et al.Byzantine-robust federated learning via credibility assessment on non-IID data[J].Mathematical Biosciences and Engineering,2022,19(2):1659-1676.
[7]Zhang Chen,Xie Yu,Bai Hang,et al.A survey on federated learning[J].Knowledge-Based Systems,2021,216:106775.
[8]Cao Xiaoyu,Fang Minghong,Liu Jia,et al.FLTrust:Byzantine-robust federated learning via trust bootstrapping[EB/OL].(2022-04-12).https://arxiv.org/abs/2012.13995.
[9]Li Tian,Sahu A K,Zaheer M,et al.Federated optimization in heterogeneous networks[EB/OL].(2020-04-21).https://arxiv.org/abs/1812.06127.
[10]Li Qinbin,Diao Yiqun,Chen Quan,et al.Federated learning on non-IID data silos:an experimental study[C]//Proc of the 38th IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2022:965-978.
[11]Zhao Yue,Li Meng,Lai Liangzhen,et al.Federated learning with non-IID data[EB/OL].(2018-06-02).https://arxiv.org/abs/1806.00582.
[12]Jeong E,Oh S,Kim H,et al.Communication-efficient on-device machine learning:federated distillation and augmentation under non-IID private data[EB/OL].(2023-10-19).https://arxiv.org/abs/1811.11479.
[13]Wu Xizhu,Liu Song,Zhou Zhihua.Heterogeneous model reuse via optimizing multiparty multiclass margin[C]//Proc of the 36th International Conference on Machine Learning.[S.l.]:PMLR,2019:6840-6849.
[14]Yao Xin,Huang Tianchi,Zhang Ruixiao,et al.Federated learning with unbiased gradient aggregation and controllable meta updating[EB/OL].(2020-12-16).https://arxiv.org/abs/1910.08234.
[15]Arivazhagan M G,Aggarwal V,Singh A K,et al.Federated learning with personalization layers[EB/OL].(2019-12-02).https://arxiv.org/abs/1912.00818.
[16]Wang Hao,Kaplan Z,Niu D,et al.Optimizing federated learning on non-IID data with reinforcement learning[C]//Proc of IEEE Confe-rence on Computer Communications.Piscataway,NJ:IEEE Press,2020:1698-1707.
[17]Shi Dian,Li Liang,Chen Rui,et al.Toward energy-efficient federated learning over 5G+mobile devices[J].IEEE Wireless Communications,2021,29(5):44-51.
[18]Sattler F,Wiedemann S,Myuller K R,et al.Robust and communication efficient federated learning from non-IID data[J].IEEE Trans on Neural Networks and Learning Systems,2019,31(9):3400-3413.
[19]Han Song,Mao Huizi,Dally W J.Deep compression:compressing deep neural network with pruning,trained quantization and Huffman coding[C]//Proc of International Conference on Learning Representations.2016.
[20]Gao Hongchang,Xu An,Huang Heng.On the convergence of communication efficient local SGD for federated learning[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2021:7510-7518.
[21]Nishio T,Yonetani R.Client selection for federated learning with hete-rogeneous resources in mobile edge[C]//Proc of IEEE International Conference on Communications.Piscataway,NJ:IEEE Press,2019:1-7.
[22]鄭赛,李天瑞,黄维.面向通信成本优化的联邦学习算法[J].计算机应用,2023,43(1):1-7.(Zheng Sai,Li Tianrui,Huang Wei.Federated learning algorithm for communication cost optimization[J].Journal of Computer Applications,2023,43(1):1-7.)
[23]Kairouz P,McMahan H B,Avent B,et al.Advances and open pro-blems in federated learning[J].Foundations and Trends in Machine Learning,2021,14(1-2):1-210.
[24]Li Xinchun,Zhan Dechuan.FedRS:federated learning with restricted softmax for label distribution non-IID data[C]//Proc of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.New York :ACM Press,2021:995-1005.
[25]Luo Mi,Chen Fei,Hu Dapeng,et al.No fear of heterogeneity:classifier calibration for federated learning with non-IID data[J].Advances in Neural Information Processing Systems,2021,34:5972-5984.
[26]Kang Bingyi,Xie Saining,Rohrbach M,et al.Decoupling representation and classifier for long-tailed recognition[C]//Proc of the 8th International Conference on Learning Representations.2020.
[27]LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of IEEE,1998,86(11):2278-2324.
[28]Cohen G,Afshar S,Tapson J,et al.EMNIST:extending MNIST to handwritten letters[C]//Proc of International Joint Conference on Neural Networks.Piscataway,NJ:IEEE Press,2017:2921-2926.
[29]Yurochkin M,Agarwal M,Ghosh S,et al.Bayesian nonparametric fe-derated learning of neural networks[C]//Proc of International Confe-rence on Machine Learning.[S.l.]:PMLR,2019:7252-7261.
[30]Wang Hongyi,Yurochkin M,Sun Yuekai,et al.Federated learning with matched averaging[C]//Proc of International Conference on Learning Representations.2020.
猜你喜欢
现代营销·学苑版(2016年12期)2017-01-23
计算机应用(2016年12期)2017-01-13
无线互联科技(2016年13期)2017-01-10
软件导刊(2016年11期)2016-12-22
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
新闻界(2016年15期)2016-12-20
企业导报(2016年20期)2016-11-05
电脑知识与技术(2016年21期)2016-10-18
