
常用的几个数据代表
2024-05-24 17:37田载今
中学生数理化·八年级数学人教版 2024年6期
田载今
研究问题时需要关注各种相关信息,这些信息通常以数字形式呈现,即统计中所称的数据,数据不仅能简洁地表达信息,而且能定量地刻画信息,便于我们科学地分析信息,因而数据是研究问题的重要依据,随着计算机和云计算的迅速发展,大数据时代已经到来,海量数据的处理得到越来越广泛的应用.
统计学是研究数据处理的学科,统计的全过程包括:收集数据、整理数据、分析数据(发现并研究数据的分布特征),并依此推断、评判已发生的事或预测将发生的事,在统计过程中,已收集到而未进一步处理的数据叫作原始数据.一般情况下,直接面对一组未经整理的原始数据,难以发现其分布特征.因此,通常需要对原始数据进一步加工整理,使其分布状况变得清晰.从中得出相应的特征值作为数据代表,再从研究数据代表人手,深入研究相关问题.
一组数据的分布特征可以从不同方面进行分析,下面从数据分布的集中趋势和离散程度两方面,讨论统计中常用的平均数、中位数、众数和方差等数据代表.
一、描述集中趋势的数据代表
“一组数据围绕哪个中心数值分布?”这是分析数据时通常关注的一个问题.它关系到一组数据的平均水平或一般情况,对统计推断有重要参考价值.在统计学中,把一组数据向某一中心数值靠拢的情形,称为这组数据的集中趋势.在描述数据的集中趋势时,常从平均数、中位数和众数中选择合适的数据代表.
如果以一组数据大小的平均水平描述集中趋势,则可用平均数作为数据代表.平均数由全部原始数据计算得出.如果以一组数据大小的中间水平描述集中趋势,则可用中位数作为数据代表.一组数据按大小排列时,中位数在居中位置.如果以一组数据中出现次数最多的数据描述集中趋势,则可用众数作为数据代表,众数是一组原始数据中出现次数最多的数据.一组数据的众数可能有一个,也可能有多个,还可能一个也没有,平均数、中位数和众数各有各的作用,分别适合从不同角度分析数据的集中趋势.
平均数是最常用的一个数据代表,它反映了一组数据大小的平均水平.需要注意的是,如果一组数据中有极端数据,即与多数数据相比过大或过小的个别数据,则它会使平均数的值与多数数据存在较大差距.如仍以平均数代表该组数据的中心数值,则不能恰如其分地反映这组数据的分布状态.这种情形下,选择中位数或众数作为数据代表,能更好地反映一组数据的集中趋势.
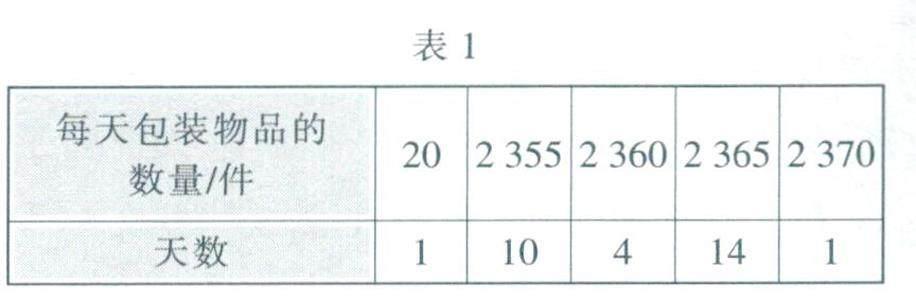
例1 表1为一条自动包装线某月每天包装物品的数量及相应的天数.
(l)分别求出表中数据的平均数、中位数和众数.
(2)用平均数作为数据代表,能客观反映这个月每天包装物品数量的一般情况吗?
解:(1)通过计算加权平均数,得表中数据的平均数为
(20+2355×10+2360×4+2365×14+2370)÷30=2283.
表中共有30天的数据,这30个数据从小到大排列时,处于正中间位置的第15和第16两个数据的平均数为(2360+2365)÷2=2362.5.因此2362.5是该组数据的中位数.
30个数据中,2365出现14次,出现次数最多,因此2365是该组数据的众数.
(2)观察表中数据不难发现,30天中有29天的数据都不小于2355,它们都大于平均数,且与平均数的差都不小于72.这30天中有1天的数据20远小于平均数2283,这可能是某一天自动包装线有突发故障造成的反常结果,显然,20这个极端数据,使得正常情况下应有的平均数的值变小.如果仍以平均数2283作为数据代表,则与自动包装线每天工作的一般状况差距较大.而以中位数2362.5或众数2365作为数据代表,则能较客观地反映一般情形下包装物品数量的实际情况.因此,此问题不宜用平均数作为数据代表描述数据的集中趋势.
二、描述离散程度的数据代表
“一组数据中,各个数据与这组数据的中心数值(例如平均数)的偏离程度有多大?”这是分析数据时通常关注的另一个问题,在统计学中,把这种偏离程度称为这组数据的离散程度(或离中程度),它反映了一组数据大小的波动状态.我們结合下面的问题对数据离散程度予以说明.
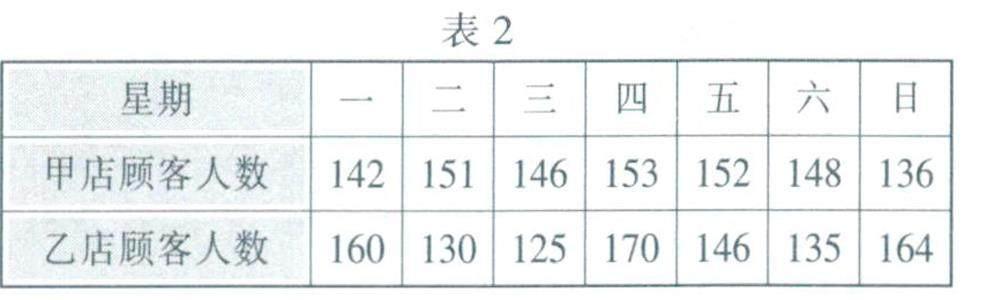
表2是某一周内甲、乙两个书店接待顾客人数的记录.
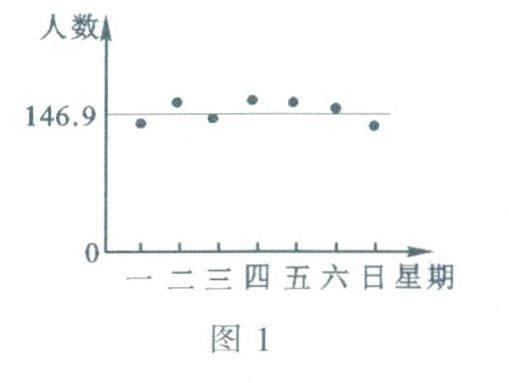
计算可知,甲、乙两个书店该周内平均每天接待顾客人数分别约为146.9和147.1.两者非常接近,我们再考虑两组数据的波动状态.先观察数据散点图,图1和图2中的点分别表示甲、乙两个书店的顾客数量,各点的横坐标为时间(星期一到星期日),纵坐标为顾客人数.图中的水平线与纵轴交点的纵坐标是7个数据的平均数.
比较两图,直观上可以发现:图1中各数据点分布较紧密,波动较小,即总体上看各点与平均值对应的水平线的偏离度较小:图2中各数据点分布较松散,波动较大,即总体上看各点与平均值对应的水平线的偏离度较大.这里的偏离度是对7个点偏离度的平均水平而言,是根据各数据点与平均数直线的距离大小而得出的.尽管与平均数直线相比,有些数据点高,有些数据点低,但各点与直线的距离都是非负的值.即高度差的绝对值,两组数据相比,甲店数据的离散程度较小,乙店数据的离散程度较大.
统计学中常用方差对一组数据的波动情况(即各数据与平均数的偏离状态)作定量的刻画,描述数据的离散程度.计算方差的方法为:(1)计算一组数据的平均数;(2)计算各数据与平均数之差的平方和;(3)用所得平方和除以这组数据的个数.设一组数据为x1,x2,…,xn(共n个),记其平均数为x,方差为s2.则
例2 分别计算上面问题中甲、乙两个书店某一周接待顾客人数的方差.南所得方差你能看出哪种可能性?
解:由以上所述可知,甲、乙两个书店某一周平均每天接待顾客人数分别为146.9和147.1(保留到0.1).计算两组数据的方差,得甲店数据的方差s2甲=32.1,乙店数据的方差sz=272.1.比较两个方差,得S2甲.
为什么计算方差要用各数据与平均数之差的平方和,而不直接把各数据与平均数之差相加呢?一般情形下,一组数据中可能有些数据比平均数大,有些数据比平均数小.它们与平均数之差会有正有负,如果直接把这些差相加,就会出现正负相抵.例如,一组数据为1,2,3,4,5,平均数为3,各数据与平均数之差分别为-2,一1,0,1,2.这些差之和为0,但这并不意味着这组数据都是紧靠着平均数的,用各数据与平均数之差的平方和,则利用了平方的非负性,防止出现做加法时正负相抵而隐藏了相关数据对平均数的偏离,方差名称中的“方”正是“平方”的简称.
对方差的算式进行恒等变形:
这给出了方差的另一种算法:各数据平方的平均数减各数据平均数的平方.
从上面几例可以看出,得出平均数、中位数、众数和方差这四种常用数据代表的方法不同,这些数据代表所表示的意义也不同,在反映一组数据的分布特征时,它们有各自的侧重点.根据实际问题的需要,选取合适的数据代表来认识一组数据的集中趋势与离散程度,是分析数据的常用做法.
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-09-06
China Report Asean(2022年8期)2022-09-02
物联网技术(2020年12期)2021-01-27
中等数学(2019年1期)2019-05-20
中等数学(2018年7期)2018-11-10
汽车零部件(2017年4期)2017-07-12
中学数学研究(广东)(2017年2期)2017-03-28
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
