
基于强化学习的室内温湿度联合控制方法研究
2024-05-23 14:09:20陈长成安晶晶王闯段晓绒
科学技术与工程 2024年12期
陈长成, 安晶晶, 王闯, 段晓绒
(北京建筑大学环境与能源工程学院, 北京 100044)
随着经济的快速发展,人类的活动地点逐渐由室外转向室内,人类平均有80%~90%的时间在室内度过,这使得人们对室内空气环境有着更高的要求[1]。室内空气环境的营造主要依赖于各种空气调节设备,风机盘管作为一种空调设备,由于其机型体积小、操作安装方便和易于独立控制等优点,已经被广泛应用于办公楼、酒店宾馆和科研楼等建筑场所。然而,现有的针对风机盘管控制的研究主要集中于降低室内温度的波动和超调量来获得更佳的室内热舒适性,这种仅以温度作为单一控制对象的方式,忽略了室内湿度对人体健康方面的影响以及不同人群出于热舒适考虑的室内湿度差异化需求。
室内环境湿度主要通过影响人体的热代谢和水盐代谢来影响人体热舒适性[2],不同人群对室内湿度的敏感程度不同。对于普通人群而言,在同一室温下,室内湿度在一定范围内的波动不会显著地影响其对室内环境的热舒适性评价,而对于患有呼吸道疾病的人群,室内湿度的波动则会显著地增加其不适感并影响其对室内环境热舒适的真实评价[3-4]。因此,将室内温度和湿度联合控制在合适的范围内对于改善室内人员的健康状态和提高室内人员的热舒适评价具有十分重要的意义。
目前,风机盘管常用的控制方法通常仅以室内温度作为控制对象,如通断控制、基于规则的控制(rule based control, RBC)和比例积分微分(proportional integral derivative,PID)控制等,这些控制方法因具有部署简单的特点被广泛应用于实际的项目中。然而,暖通空调系统作为一种高度非线性的时变系统,传统的控制方法往往难以取得理想的控制效果[5-7]。近年来,模型预测控制(model predictive control, MPC)在暖通空调系统中的应用受到广泛关注。MPC作为一种监督控制,具有稳定性较好、多目标滚动优化的特点,但MPC的控制效果不仅依赖于精准的数学模型,还需要能够准确反映建筑室内外参数变化规律的数据信息[8]。随着大数据技术和人工智能的发展,强化学习(reinforcement learning, RL)作为近几年兴起的一种机器学习方法,具有免模型、自学习的优点[9-10],一些学者已经对强化学习算法在暖通空调系统中的优化控制展开了研究。Fang等[11]将DQN(deep Q network)算法应用于变风量空调系统,以节约系统总能耗和满足室内温度要求为总目标,通过控制送风温度的设定值和冷机供水温度的设定值,验证了大多数情况下DQN算法的控制效果优于基于规则的控制。闫军威等[12]将Double DQN算法应用于广州市某办公建筑的中央空调系统节能优化运行中,在满足室内温度要求的前提下,相较于PID控制,降低了5.36%的系统总能耗。丁瑞华等[13]提出一种基于专家知识的深度强化学习优化控制方法,以某数据中心的水冷式空调系统为研究对象,将该方法与传统的RBC和PID控制相对比,证明了该方法可以实现在机柜出口温度处于安全范围内的前提下降低系统总能耗。Yuan等[14]以某办公楼变风量空调系统为例,验证了强化学习控制器在满足室内温度要求方面比RBC和PID控制器更节能。Biemann等[15]在模拟的数据中心环境中对4种Actor-critic算法进行了评估,结果表明:与基于模型的控制器相比,这4种算法都可以实现区域温度保持在理想范围内而同时减少10%的能源消耗。目前,强化学习算法在暖通空调系统中的应用研究主要以满足室内温度要求的前提下降低系统总能耗为优化目标,这忽略了室内湿度的影响,有可能造成室内湿度满足率降低的情况。
综上所述,在风机盘管的控制研究方面,目前常用的控制方法仅以室内温度作为单一控制对象,忽略了湿度对不同人群舒适性的影响。由于风机盘管采用冷凝除湿的方法,室内温度和湿度之间存在耦合关系,通过调控风机盘管以实现室内温湿度均控制在合适范围内具有较大难度,且目前相关的研究还比较少。此外,强化学习算法作为近几年兴起的一种机器学习控制方法,已经有学者对其在暖通空调系统中的应用进行了初步的研究,但大多数研究集中于满足室内温度要求的前提下降低系统能耗,利用强化学习算法对使用风机盘管的建筑进行室内温湿度联合控制的研究目前还比较少。为解决上述问题,以采用风机盘管加新风系统的北京某办公建筑为研究对象,搭建TRNSYS-Python联合仿真平台,提出一种基于动作干预的强化学习算法对风机盘管的送风量进行调控,以实现室内温度和相对湿度联合控制满足率的提升。本研究可为将强化学习算法应用于室内环境控制提供新的研究思路。
1 技术路线
面向目前中国建筑广泛使用的风机盘管末端设备,提出一种基于动作干预的强化学习算法对风机盘管的送风量进行调控,以期实现室内温度和相对湿度联合控制满足率的提升。技术路线如图1所示,具体如下。
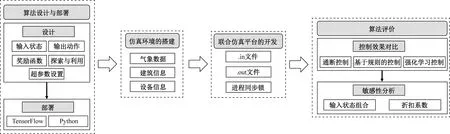
图1 技术路线图Fig.1 Schematic diagram of the overall technical approach
(1) 强化学习算法的设计与部署。设计一种适用性更好的强化学习算法用于风机盘管送风量的调控,并借助深度学习库TensorFlow部署该算法。
(2) 建筑仿真环境的搭建。在TRNSYS软件中对建筑及其能源系统进行建模,为后续智能体的训练提供交互环境。
(3) TRNSYS-Python联合仿真平台的开发。基于文件的数据传递方式实现TRNSYS与Python的实时交互,开发联合仿真平台用于算法的测试与评价。
(4) 算法评价。将所提的强化学习控制算法与传统控制方法进行室内温度和相对湿度联合控制效果的对比,然后探究不同输入状态组合下强化学习算法的敏感性。
2 强化学习算法
2.1 算法的基本原理
强化学习(reinforcement learning, RL)是机器学习领域中除了监督学习和非监督学习以外的第三种基本的学习方法,其灵感来源于心理学中的行为主义理论,即有机体不断地与环境进行交互,获得由环境给出的奖励或者惩罚,然后逐步形成对奖惩的预期,产生能够获得最大收益的动作行为[16]。图2为强化学习算法的示意图。

图2 强化学习算法原理示意图Fig.2 Schematic diagram of reinforcement learning algorithm
图2中,智能体可以接收来自环境的状态和奖赏信息,智能体输出的动作可以在环境中被执行。t时刻的状态用st表示,动作用at表示,奖赏用r(st,at)表示。具体的交互过程为:在每个决策时刻t,智能体执行动作at,经过一个时间步长Δt后,环境进入t+1时刻,状态由st变为st+1,智能体观察到st+1并知晓由环境反馈回来的此时间步长内的奖赏r(st,at)。
强化学习算法的迭代计算对象为状态和动作所对应的最大期望奖励值函数,用Q(st,at)表示,其含义为在状态st下执行动作at,系统将获得的累计奖励值[17]。通过智能体与环境之间的不断交互,利用式(1)对Q(st,at)进行更新。
Qnew(st,at)←(1-α)Qold(st,at)+α[r(st,at)+
γmaxQ(st+1,at)]
(1)
式(1)中:Qnew(st,at)为更新后的最大期望奖励值函数;Qold(st,at)为更新前的最大期望奖励值函数;α为学习速率,α∈(0,1],当学习速率较大时,算法的收敛速度较快,但振荡的风险较高,当学习速率较小时,算法的收敛速度较慢,但振荡的风险较低;γ为折扣系数,γ∈[0,1],其含义为当前动作对未来长期奖励的影响程度,γ越大,智能体便更加重视未来获得的长期奖励,反之,γ越小,智能体则短视近利,更在乎即时奖励。
在实际的暖通空调系统中,设备和传感器比较多,状态的维度空间很大,且许多状态为连续而非离散的,若计算出每一个Q(st,at),将是一项十分繁琐复杂且低效的任务。为了解决这一问题,利用人工神经网络对Q值函数进行估计的方法被提出[18-20]。人工神经网络的输入为状态,输出为各个动作的Q值。此类采用人工神经网络的强化学习算法被称为深度强化学习算法。DQN算法是一种深度强化学习算法,其搭载了两个人工神经网络(Q网络和目标Q网络)和一个经验池。Q网络需要被训练以输出最优的Q值。目标Q网络无需被训练,仅作为Q网络被训练时的标签,其参数的更新来自固定时间步长内Q网络参数的复制。经验池存放了智能体与环境交互产生的经验,在Q网络被训练时,这些经验被抽取,送入Q网络作为训练数据。DQN算法的具体流程如图3所示。

图3 DQN算法流程图Fig.3 Flowchart of DQN algorithm
考虑到空调系统运行产生的数据十分庞大复杂,室内空气状态为连续变量而非离散的,所以本文采用了DQN算法解决风机盘管送风量优化控制问题。
2.2 DQN算法的设计
2.2.1 输入状态
在基于强化学习的优化控制策略中,状态的选取至关重要。状态包含的影响因素越多,智能体接收到关于环境的信息就越全面,最终学习到的策略也越接近最优控制策略。但是,状态维度的增加会导致训练时间的加长以及智能体探索空间的扩大,存在智能体学习失败的风险[10]。因此,在确定输入状态之前,需对潜在的输入状态及其不同的组合进行多次的实验。
经过反复实验之后,选取同一时刻的室内温度和室内相对湿度经过转换后作为DQN算法的输入状态,转换公式为
(2)
(3)
式中:tem、RH分别为转换前的温度和相对湿度;t′em、R′H分别为为转换后的温度和相对湿度;式(2)的作用是当室内温度tem处于设定上限值Tup,bo和设定下限值Tlow,bo之间时,将t′em分布于-1~1;当tem大于设定上限值Tup,bo或者小于设定下限值Tlow,bo时,将t′em线性地增加或者减少;式(3)的作用是当室内相对湿度RH处于设定上限值RHup,bo和设定下限值RHlow,bo之间时,将R′H分布于-1~1,当RH大于设定上限值RHup,bo或者小于设定下限值RHlow,bo时,RH每增加或者减少10,R′H则增加或者减少1。这样的转化可以使得t′em和R′H的量级相近。
2.2.2 输出动作
DQN算法的输出动作可以视为暖通空调系统中的可控制变量。选取风机盘管的送风量作为输出动作。采用的风机盘管的送风量共有4个挡位,分别是关闭、低挡位、中挡位和高挡位,分别对应额定风量的0、50%、75%和100%,得到动作空间为
A=[a0,a1,a2,a3]=[0,50%,75%,100%]。
2.2.3 奖励函数
理论上,智能体总是向着累计奖励值最大化的方向训练,奖励函数充当了智能体牵引者的角色。所以,奖励函数的设计决定了智能体训练过程的长短以及训练效果的优劣。针对研究目的,定义奖励函数由温度惩罚项和相对湿度惩罚项的负数形式表示,如式(4)~式(6)所示。
Reward=-k1ptem-k2pRH
(4)
(5)
(6)
式中:Reward为奖励;ptem为温度惩罚项;pRH为相对湿度惩罚项;k1为温度惩罚项系数;k2为相对湿度惩罚项系数。
2.2.4 探索与利用机制及超参数设置
选择ε-贪婪探索策略对更多的状态-动作对进行探索,其中ε为随机数。具体的流程为在训练阶段,每一个时间步产生一个随机数,若该随机数小于此时的εi,则智能体随机选择一个动作,否则智能体根据Q网络的预测结果选择动作。εi的计算公式为
εi=ε0-εdecaystepi
(7)
式(7)中:εi为第i代的随机数;εdecay为衰减系数;stepi为第i个时间步;ε0为初始随机数。
为避免无意义的探索和增强控制器的实用性,对智能体进行动作干预。在训练阶段,当室内温度超出设定上限值2 ℃时,风机盘管采取高挡位送风量,当室内温度低于设定下限值2 ℃时,风机盘管关闭。在测试阶段,当室内温度高于设定上限值时,风机盘管开高挡位,当室内温度低于设定下限值时,风机盘管关闭。这样的动作干预不仅可以避免智能体为了获得更加合适的室内相对湿度而忽略室内温度,还可以避免暖通空调设备的损坏。所用DQN算法的超参数设置如表1所示。

表1 超参数设置Table 1 Hyperparameter settings
2.3 算法的评价
2.3.1 训练收敛判据
智能体的训练需要在合适的时候退出。训练时间过短,有可能造成智能体的学习过程未完成,学习到的经验可靠性不足。训练时间过长,则有可能陷入人工神经网络过拟合的困境。因此,需要设定一个合适的收敛判据用于判断智能体的训练是否应该终止。选择逐步平均奖励值SAR作为收敛判据,其计算公式为
(8)
式(8)中:ri为第i个时间步长内的奖励值;N为已经进行的时间步长的个数。
2.3.2 控制效果评价
为了验证所提出的强化学习控制方法的室内温度和相对湿度联合控制效果,选取在工程中常用的通断控制和基于规则的控制进行仿真对比。通断控制的设置为当室内温度高于或等于控制目标上限(27 ℃)时,开启风机盘管对室内进行降温,当室内温度低于或等于控制目标下限(25 ℃)时,关闭风机盘管,其余情况保持送风量不变以减少风机盘管的挡位变化。基于规则的控制对室内温度的控制预留了安全范围[17],当室内温度距离控制目标上限0.3 ℃时,风机盘管开启最大风量对室内空气进行降温,避免室温进一步升高,反之,当室内温度距离控制目标下限0.3 ℃时,关闭风机盘管,避免室温进一步降低,其余情况风机盘管开启中挡位送风量维持室内温度。上述控制方法的具体设置如表2所示。
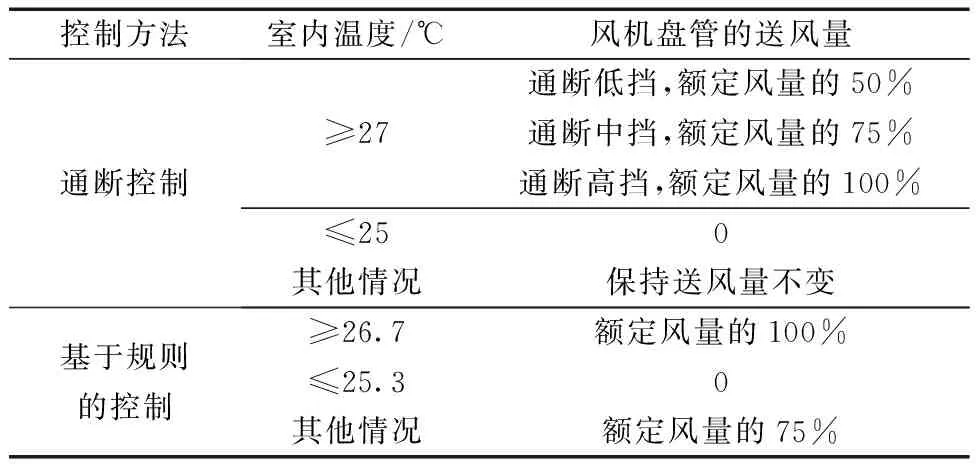
表2 通断控制和基于规则的控制的具体设置Table 2 Specific settings for on-off control and rule-based control
选取温度满足率φtem、相对湿度满足率φRH、温度和相对湿度联合控制满足率φtem&RH作为评价指标,其计算公式分别为
(9)
(10)
(11)
式中:ntem为室内温度在上下限范围内的工况点数;nRH为室内相对湿度在上下限范围内的工况点数;ntem&RH为室内温湿度均在上下限范围内的工况点数;N为总工况点数。
2.3.3 敏感性分析
为了分析DQN算法的敏感性,测试不同输入状态组合在不同的折扣系数下对控制效果的影响。各个组合的设置如表3所示。

表3 各个组合的输入状态选择Table 3 Input state selection for each combination
3 联合仿真平台
3.1 仿真环境的搭建
智能体需要经过训练才能学习到行之有效的控制策略,训练过程中智能体需要不断地接收环境信息并给出执行动作。若将未训练完成的强化学习算法部署于实际的建筑暖通空调系统,将有设备损坏、室内空气状态严重偏离舒适区间的风险。因此,在TRNSYS软件中搭建仿真环境,用于智能体的训练、算法的测试与评估。
研究对象为北京市海淀区某办公建筑内的工会活动室,面积为116 m2,空调系统形式为风机盘管加新风系统。该办公楼由老旧库房改建而成,围护结构的传热系数:外墙为2.266 W/(m2·K),屋顶为0.804 W/(m2·K),外窗为1.46 W/(m2·K)。内扰设置:人体发热量为66 W/人,人员密度为0.1 人/m2,人员产湿量为0.109 kg/(h·人),人员在室率08:00—20:00为1,其余时间为0。空调系统的设置:新风量为系统总风量的10%,采用新风处理到室内空气焓,不承担室内负荷;室内温度控制目标为25~27 ℃,室内相对湿度控制目标为40%~60%;空调设置在07:00—20:00开启,其余时间关闭,空调启动时间比人员进入室内的时间提前了1 h是为了确保当人员进入房间时,室内温度处于合适的范围内,提高人员的热舒适性。仿真时间步长设置为12 min。在SketchUp软件中建立建筑的几何结构,如图4所示。
图4 建筑的几何结构Fig.4 The geometry of the building
3.2 TRNSYS-Python联合仿真平台的开发
提出的DQN控制算法由Python语言实现,借助免费开源的深度学习库TensorFlow完成人工神经网络的搭建和训练。
为了实现TRNSYS与控制器之间的实时交互,采用基于文件的数据传递方式。控制器将控制动作写入.in文件,然后TRNSYS借助本研究自定义模块读取该.in文件并执行对应的动作,到达下一个仿真时间步后,TRNSYS将环境的状态写入.out文件,由控制器读取该文件。为保证TRNSYS软件与基于Python的控制器这两个进程的时间同步问题,本研究在Python环境中自定义文件锁用于控制Python代码和TRNSYS模拟计算的先后次序,实现跨进程计算和数据同步。结合上述DQN算法的设计和TRNSYS软件与强化学习控制器之间的实时交互,提出的TRNSYS-Python联合仿真平台的整体架构如图5所示。

s为当前状态;a为采取的动作;s′为下一时刻的状态;rv为奖励值
4 仿真结果对比与分析
4.1 DQN算法仿真结果分析
选取7月1日00:00—7月15日00:00作为训练时间段,训练过程的逐步平均奖励值曲线如图6所示。
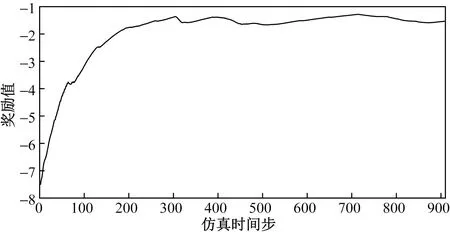
图6 训练过程逐步平均奖励值曲线Fig.6 Stepwise average reward curve during training
由图6可知,在约前300步内,智能体不断与环境交互并学习产生的经验,这段时间内逐步平均奖励值迅速爬升。300步之后,智能体已经初步完成学习,继续与环境交互,学习更多的经验,逐步平均奖励曲线在小范围内上下波动。
将训练好的模型在8月1日00:00—8月31日00:00进行测试,对测试时间段内的仿真结果进行统计,结果如表4所示。

表4 强化学习控制器控制效果Table 4 The control effect of reinforcement learning controller
选取典型日(8月2—5日)的室内空气状态进行绘制,结果如图7所示。
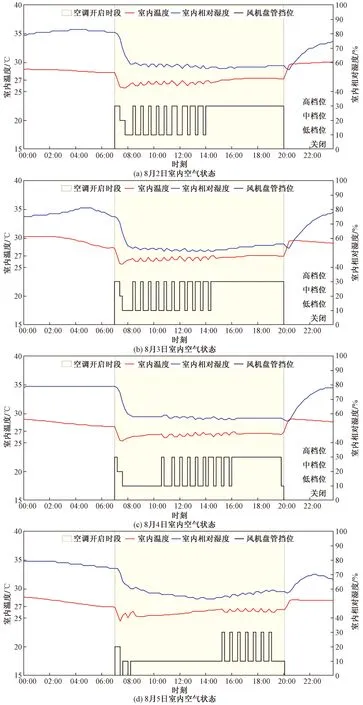
图7 室内空气状态Fig.7 Indoor air status
由图7可知,强化学习控制器对室内温度进行动作干预,使得室内温度处于舒适范围附近,保证了空调设备的正常运行,避免了设备的损坏。当室内温度处于舒适范围内时,智能体可以自行选择风机盘管的挡位进行送风,以达到更佳的温度和相对湿度联合控制满足率。
4.2 不同控制方法仿真结果对比与分析
为了进一步验证强化学习控制器的温度和相对湿度联合控制效果,选取通断控制和基于规则控制进行仿真对比。不同控制方法下,室内温度和相对湿度的仿真结果如图8~图10所示。

图8 不同控制方法下室内温度分布的平均值和方差Fig.8 Mean and variance of indoor temperature distribution under different control methods
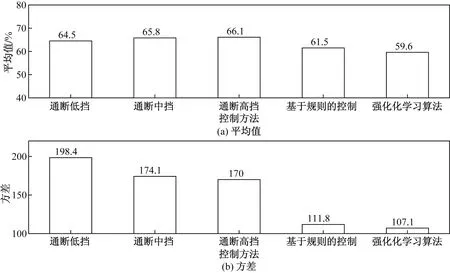
图9 不同控制方法下室内相对湿度分布的平均值和方差Fig.9 Mean and variance of indoor relative humidity distribution under different control methods
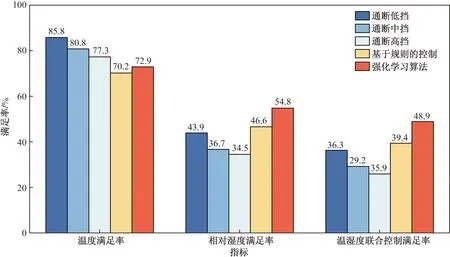
图10 不同控制方法效果对比Fig.10 Effect comparison of different control methods
由图8~图10可知,在室内温度控制方面,3种通断控制方法下,室内温度分布的平均值更偏向于控制目标的平均值,为26 ℃,而基于规则的控制和强化学习算法控制这两种方法下,室内温度分布的平均值更偏向于2 5 ℃,低于控制目标的平均值,但仍在控制目标范围之内。在室内相对湿度控制方面,五种控制方法下,室内相对湿度分布的平均值均大于控制目标的平均值,即50%,强化学习算法控制的偏高程度最小,其室内相对湿度分布的平均值为59.6%。对测试时间段内的典型年气象文件进行数据分析,可以发现在该时段内出现了较多阴雨天,阴雨天的室外大气相对湿度较高,从而使得室内相对湿度也随之升高。由方差统计结果可知,在强化学习算法控制方法下,室内温度和相对湿度分布的方差最小,即该控制方法下的室内温度和相对湿度分布相较于其他控制方法更加集中。综合来看,提出的强化学习算法可以实现在略微损失室内温度舒适性的情况下,较大幅度地提高室内相对湿度舒适性,从而使得总的室内温度和相对湿度联合控制效果提升。
由图10可知,对于室内温度满足率,通断低挡方法的控制效果最佳,为85.8%,基于规则的控制方法的效果最差,为70.2%。对于室内相对湿度满足率,强化学习方法的控制效果最佳,为54.8%,通断高挡控制方法的效果最差,为34.5%。而对于室内温度和相对湿度联合控制满足率,强化学习方法的控制效果最佳,为48.9%,比基于规则的方法的控制效果提升了9.5%,比通断低挡方法的控制效果提升了12.6%,比通断中挡方法的控制效果提升了19.7%,比通断高挡方法的控制效果提升了23.0%。
5 讨论
为了探究所提控制算法的敏感性,对表3中的输入状态组合进行仿真测试。测试结果如图11所示。

图11 各组合测试结果Fig.11 Test results of each combination
由图11可知,对于组合1和组合2,γ=0.1时联合控制效果最佳,对于组合3,γ=0.5时联合控制效果最佳,对于组合4,γ=0.7时联合控制效果最佳。随着输入状态数的增加,最佳联合控制效果对应的折扣系数γ也随之增大。这与折扣系数γ的含义相符,即当输入状态越多,则需要智能体越重视长期奖励,当输入状态越少,则需要智能体更加短视。组合1、组合2和组合3在不同折扣系数γ下的联合控制效果比较稳定,波动较小,而组合4在不同折扣系数γ下的联合控制效果稳定性较差,控制效果出现了振荡。由此可见,虽然输入状态的增加可以使智能体更全面地接收到系统的信息,但这也增加了智能体的学习成本以及学习效果不收敛的风险。因此,输入状态的选择对于智能体的学习至关重要,这也决定了最终的控制策略是否有效。
6 结论
提出一种基于动作干预的强化学习控制方法,并设计了其输入状态、奖励函数、智能体探索与利用机制。然后,以采用风机盘管加新风系统的北京某办公建筑为研究对象,开发TRNSYS-Python联合仿真平台,对所提方法的控制效果进行了验证,得到以下结论。
(1)利用基于文件的数据传递方式,开发TRNSYS-Python联合仿真平台,其可以在仿真环境中更加方便地训练智能体、测试和评估复杂的强化学习算法的性能。
(2)基于动作干预的DQN算法不仅在训练阶段可以减少训练时间、节约计算成本,还能够在测试阶段增加算法部署的安全性。从本文仿真结果来看,该算法可以实现更佳的建筑室内温度和相对湿度联合控制效果,与传统的基于规则的控制、通断低挡控制、通断中挡控制和通断高挡控制相比,可以将温度和相对湿度联合控制满足率分别提升9.5%、12.6%、19.7%和23.0%。
(3)输入状态的选择和超参数的设置至关重要。输入状态数越多,智能体接收到关于环境的信息就越全面,最终学习到的策略也越接近最优控制策略。但是,输入状态数的增加有可能导致智能体学习失败、学习效果不收敛。在同一输入状态下,不同的超参数设置也影响着智能体的学习效果。当超参数处于合适的范围时,算法的鲁棒性较好,当超参数超出合适的范围时,算法的性能将受到影响。
因此,所提的控制方法可以在损失较少室内温度舒适性的情况下,较大幅度地提高室内相对湿度舒适性,能够较好地实现室内温度和相对湿度的联合控制,可以为建筑热舒适研究提供新方法。对于室内温度和相对湿度均有特定要求的建筑类型和场景,本文方法具有工程应用价值。
利用强化学习算法对暖通空调系统进行优化控制是十分复杂的问题,因此本次研究存在一定的局限性,未来的研究可以以此开展。所涉及的建筑和暖通空调系统相对简单,没有涉及多区域之间的热湿传递,强化学习算法在高度耦合、非线性的系统中将展现更佳的算法性能,因此,未来将强化学习算法应用于复杂的暖通空调系统是一项具有挑战性的工作。出于设备安全的考虑,所提的控制算法暂未部署于实际的暖通空调系统,未来将强化学习算法部署于真实的系统中并对其进行评估是一项意义重大的工作。
猜你喜欢
建筑热能通风空调(2022年6期)2022-07-30 14:01:32
中国特种设备安全(2021年3期)2021-07-28 06:54:18
化工管理(2020年17期)2020-07-17 12:10:50
建材发展导向(2019年10期)2019-08-24 06:25:20
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
能源(2018年5期)2018-06-15 08:56:02
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
能源(2017年9期)2017-10-18 00:48:27
现代工业经济和信息化(2016年12期)2016-05-17 05:37:47
家庭百事通(2016年3期)2016-03-14 08:07:17
