
基于姿态估计和Transformer模型的遮挡行人重识别
2024-05-23 14:08陈禹刘慧梁东升张雷
科学技术与工程 2024年12期
陈禹, 刘慧, 梁东升, 张雷
(1.东软汉枫医疗科技有限公司, 沈阳 110034; 2.北京建筑大学电气与信息工程学院, 北京 100044)
行人重识别(re-identification, ReID)技术具有从跨设备采集的图像中识别同一行人的能力[1-2]。该技术利用人工智能方法,能够解决边防检查、人员追踪等公共安全应用问题,在视频监控、智能安防、应急疏散、城市管理等多个领域被广泛应用。行人重识别算法根据应用场景状况的不同可分为两个重点领域:一个是标准行人重识别,另一个则是遮挡行人重识别。前者是后者的基础,后者是通过研究因行人遮挡而导致的识别困难所进行的延伸。目前,多种行人重识别方法[3-4]已经被提出。但是这些方法主要用于处理全貌图像,对于更为实际和具有挑战性的遮挡图像鲜少研究。因为行人处在复杂的正常社会秩序环境中,可能会刻意遮挡,或利用复杂环境的掩体进行遮挡,或被其他行人遮挡,或者走出监控设备的视野,特别是在剧场、医院、景区、闹市等人员密集场所。因此遮挡的行人重识别技术更为实际且更具挑战性。首先,遮挡引起关键信息的缺失,大大增加错误匹配的概率。其次,通过对行人部位进行匹配虽然已被证明是有效的方法[3],但前提是需要先对行人进行严格对齐,因此,当遮挡严重时系统可能无法工作。
针对遮挡的行人重识别问题,近年来也得到了许多科研工作者的青睐,提出了许多新的方法[4-6]。这些方法主要针对特征学习和对齐问题,以求提高遮挡的行人重识别能力。现有方法可以大致分为三类,分别为基于手工分割的方法、使用附加线索的方法和基于Transformer的方法。
基于手工分割的方法利用对齐补丁之间的相似关系解决遮挡问题。Sun等[3]于2018年、2019年分别提出了一种基于部件的卷积基准网络(part-based convolutional baseline,PCB)以及一种基于区域的可视感知部分(visibility-aware part model,VPM)模型,PCB网络均匀分割特征图并直接学习局部特征,VPM通过自我监督学习区域的可见性[7]。Jia等[8]使用相应模式集合之间的Jaccard相似性系数,将遮挡的行人重识别作为集合匹配问题来公式化。
利用外部线索来定位人体部位的方法如:图像分割、姿态估计或人体解析等。Song等[9]提出了一种基于掩码引导的对比度关注模型,可以单独从身体中学习特征。Miao等[10]提出了一种姿态引导的特征对齐方法,基于人体语义关键点匹配待查询图像以及图库中图像的局部特征,结合预定义的关键点置信度阈值来判断是否被遮挡。Gao等[11]通过姿势引导注意力学习区分性部分特征,提出一种姿势引导可见部分匹配(pose-guided visible part matching,PVPM)模型。Wang等[12]基于高阶关系和人体拓扑信息来学习稳健特征,提出了高阶行人重识别(high-order ReID,HOREID)模型。
最近,基于Transformer的方法开始引起人们的关注。Transformer具有强大的特征提取能力和学习解耦特征的能力。He等[13]研究的纯Transformer框架TransReID,利用Transformer强大的特征提取能力,在行人重识别和车辆重识别方面都取得了良好的表现。Li等[14]利用Transformer学习解耦特征的能力,提出部件感知Transformer(part-aware Transformer),可以解耦出鲁棒的人体部位特征,适用于遮挡行人身份重识别。
与上述方法不同,结合姿态信息和Transformer架构,提出一种姿态Transformer网络(pose Transformer net,PT-Net)模型。该模型利用Transformer的学习解耦特征的能力,解耦相似姿态特征,提高姿态特征的区分度和清晰度,并有效地缓解了遮挡对特征学习的影响。通过融合全局外貌、局部部位和姿态信息等,生成更加鲁棒和准确的特征表示,同时采用自注意力机制自适应学习重要信息,抑制噪声和无关信息的影响。首先通过将关键点信息与行人特征图像相结合,在行人特征表示中保留更多的身体结构信息,从而更好地抵御遮挡带来的干扰。其次利用Transformer模型对基于姿态的行人特征表示进行编码,实现特征对齐和特征融合,从而提升遮挡行人重识别的准确性和稳定性。该方法在解决边防检查、人员追踪等公共安全应用问题领域具有重要的意义。
1 相关工作
1.1 ResNet50模块
残差神经网络(residual neural network, ResNet)由He等[15]于2015年提出。ResNet50网络是一种具有深度残差连接的卷积神经网络,可以有效提取行人图像的特征。传统的神经网络通过堆叠多个隐藏层来提高模型拟合能力,同时也增加了网络的复杂度。且当隐藏层数增多时,容易引起梯度消失(vanishing gradient problem,VGP)和梯度爆炸(exploding gradients problem,EGP)问题,导致模型的性能反而会下降。梯度消失和梯度爆炸是在训练过程中经常遇到的问题。梯度爆炸可以通过梯度裁剪来解决,而梯度消失需要对模型本身进行改进。ResNet网络,将输入特征与输出特征之间建立一条直接连接的捷径,使得模型能够更好地优化深层网络,有效地解决了梯度消失的问题。如图1所示,ResNet采用残差块(residual block)的结构,直接将低层的特征传递到更深层次的特征中,从而避免了信息的丢失和梯度消失的问题。

图1 残差网络模块Fig.1 Residual network module
1.2 Transformer模块
Transformer[16]模型是主要用于处理自然语言的模型。受自注意力机制的启发,许多科研人员开始将Transformer应用于计算机视觉领域。文献[17]提到DETR模型通过执行交叉注意力,将目标查询和特征图进行匹配,将检测问题转化为一对一匹配问题,从而消除了手工制作组件的需要。Han等[18]和Khan等[19]研究了Transformer在计算机视觉领域的其他应用。其他如图像处理Transformer(image processing transformer,IPT)[20]利用Transformer的优势通过大规模预训练,在超分辨率、去噪等任务中实现了最先进的性能。最近提出的视觉Transformer (vision transformer,ViT)[21]模型直接将纯Transformer应用于图像块序列,如图2所示,但是ViT需要大规模的数据集进行预训练。为了克服这个问题,Touvron等[22]提出数据高效图像(data-efficient image Transformer,DeiT)框架,引入特殊的教师-学生策略,以加速ViT的训练,因而无需大规模的预训练数据。
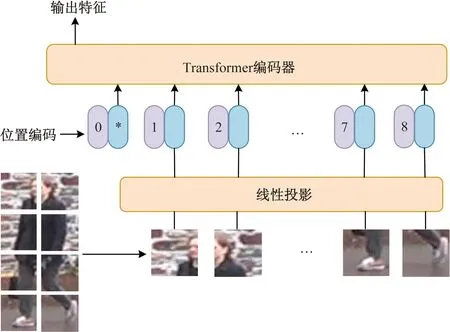
图2 Transformer框架Fig.2 Vision Transformer framework
1.2.1 图像分块嵌入

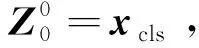
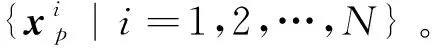
(1)
Z′l=MSA[LN(Zl-1)]+Zl-1,l=1,2,…,L
(2)
Zl=MLP[LN(Z′l)]+Z′l,l=1,2,…,L
(3)
(4)
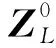
采用Transformer编码器层来学习特征表示。由于所有的Transformer层都具有全局感受野,因此基于卷积神经网络的方法存在有限的感受野的问题得到了解决。此外,没有下采样操作,因此详细信息得以保留。
1.2.2 Transformer编码器
图3展示了Transformer编码器[16]的结构,它由多个交替的多头自注意力(multi-head self-attention,MSA)和多层感知器MLP组成。编码器完成的计算过程可通过式(2)和式(3)描述。在每个块之前应用层归一LN(layer norm),在每个块之后使用残差连接[25]来防止信息的丢失。多头自注意力机制可以更好地捕捉序列中的依赖关系和全局信息,MLP块可以对序列特征进行非线性变换和提取。同时,由于层归一化和残差连接的使用,Transformer编码器能够更好地避免梯度消失和信息瓶颈的问题。

L×为编码器的层数
在ViT中,输入图像被划分成多个图像块,每个图像块被展平成一个二维矩阵,作为Transformer编码器的输入。在每个Transformer块中,输入首先通过多头自注意力层进行编码,该层计算每个位置对于整个序列的重要性并加权,以便更好地捕捉图像中的关键特征。随后,这些加权的位置向量被传递到多层感知器MLP中,以进行一些非线性变换和特征提取。在每个Transformer块中,还使用残差连接和层归一化来提高模型的性能。这些操作使得ViT能够更好地处理高分辨率图像,并且能够从中学习到更准确的特征表示。
1.3 BNNeck模块
将ID loss和triplet loss结合在一起训练网络模型,由于这两种损失的目标在嵌入空间中是不一致的,设计了一个名为BNNeck的结构,如图4所示。BNNeck在特征之间(分类器full connetction层之前)添加了一个批量归一化BN(batch norm)层。BN层之前的特征表示为ft。让ft通过BN层得到归一化特征fi。在训练阶段,ft和fi分别用于计算三元组损失和ID损失。归一化层平衡了fi的每个维度。特征在超球面表面附近呈高斯分布,这种分布使得ID损失更容易收敛。此外,BNNeck降低了ID损失对ft的约束。来自ID损失的较少约束使得三元组损失更容易同时收敛。而且,归一化层保证了属于同一行人的特征的紧凑分布。在推理阶段,选择fi来进行行人ReID任务。余弦距离度量可以比欧几里德距离度量获得更好的性能。

图4 BNNeck网络结构Fig.4 Structure of BNNeck network
2 PT-Net网络架构
PT-Net网络结构如图5所示,主要由特征提取和特征对齐两个关键阶段组成。在特征提取阶段,利用ResNet50作为基础模型提取全局特征,并结合姿态估计模型提取局部特征,以获取更全面、更丰富的行人特征表示。在特征对齐阶段,采用Transformer模型对局部特征和全局特征进行特征融合和对齐,进一步提升了模型对行人特征的精准表示。为了提升模型性能,在该研究中引入BNNeck模块[23]。为了更好地训练模型,在不同阶段加入多种损失函数进行监督,以使模型不仅能够准确地预测样本标签,而且能够在特征空间上实现更好的聚类效果,即相同样本距离更近,不同样本距离更远。这些损失函数包括交叉熵损失、三元组损失以及圆损失。通过这些监督机制,可以进一步提高模型的性能,让其在行人重识别任务中取得更加准确和鲁棒的结果。

*标记的输出表示特征融合后的结果
2.1 特征提取阶段
研究表明,基于部件的特征是有效的行人重识别特征[3]。在遮挡或部分遮挡的情况下,局部特征的精确对齐是必要的[7]。遵循上述思路,并受最近在行人重识别[3,23,26]和人体关键点预测方面的发展启发,利用ResNet50主干提取不同关键点的局部特征。尽管人体关键点预测已经取得了较高的准确度,但在遮挡或部分图像下,它仍然表现得不尽如人意。这些因素导致关键点位置及其置信度的不准确性。因此,提出一个改进方法,通过结合Transformer模块,增强了局部特征的表达和整合能力。同时,还通过引入深度监督机制来减轻梯度消失问题,从而提高了模型的稳定性和鲁棒性。通过大量的实验证明,上述方法在行人重识别任务中取得了优异的性能。
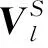
(5)
(6)
式中:K为关键点数;vk∈Rc,其中c为通道数;mkp为通过对原始关键点热力图进行softmax函数归一化获得的,以防止噪声和离群值。
使用分类损失Lcls和三元组损失Ltri联合构成目标损失LS,如式(7)所示。

(7)

2.2 特征对齐阶段
在特征提取阶段,借助行人姿态估计技术获得行人的关键点信息,这些关键点包括头部、肩部、膝盖等关键部位的位置信息。这些关键点信息可以辅助特征对齐,提高模型在行人重识别任务中的表现。同时,利用关键点信息还可以更好地捕捉行人的姿态信息和身体结构信息。
在模型的编码器阶段,使用Transformer编码器中的注意力机制来实现特征对齐,这使得每个位置的特征表示可以同时考虑输入序列中的所有位置。通过对每个位置进行加权求和的方式,将注意力机制计算得到的各个位置的特征表示进行聚合,可以得到更加准确和全局的特征表示。这种特征对齐和聚合的方式,极大地增强了模型的表达能力和泛化能力,从而在行人重识别任务中取得更好的效果。
Transformer中的自注意力机制(self-attention)将输入序列中的每个位置的特征表示视为一个向量,它们同时作为查询(query)、键(key)和值(value)来计算注意力分布。这种注意力分布表示了每个位置与其他位置的相对重要性,并通过加权求和的方式将输入序列中所有位置的表示进行聚合,得到更准确的表示。在多头注意力机制中,模型使用多组不同的查询、键和值向量来计算不同的注意力分布,每个注意力头可以关注不同的特征子空间,从而进一步增强模型的表达能力。最终,将多个注意力头的输出拼接起来,得到更全面的表示。总的来说,这种注意力机制的实现方式可以捕捉输入序列中的长程依赖关系,并且不受输入序列长度的限制,从而实现了特征对齐,提高了模型的表达能力。
3 实验设置与结果分析
3.1 实验环境及实现细节
本实验环境为:显卡GeForce RTX3090,显存大小24 GB。采用随机擦除和自动增强策略将输入图像的尺寸调整为256×128。模型训练epoch为60,batchsize为64,随机选择4个行人进行采样,每个行人取16张图片作为训练数据。使用Adam优化器,将初始学习率设置为3.5×10-4。
实验与文献[26]的研究相同,采用ResNet50[15]作为骨干网络。在ResNet50中,丢掉全局平均池化GAP(global average pooling)层和全连接层,并将最后一次残差模块卷积运算的步幅设为1,得到16次下采样的特征图。对于分类器,按照文献[23]的方法使用了一个批量归一化层[27]和一个全连接层[28],接着是一个softmax函数。对于人体关键点模型,使用在COCO数据集上预训练的HR-Net[29]关键点模型。该模型预测17个关键点,将所有头部区域的关键点融合起来,最终得到K=14个关键点,包括头部、肩部、肘部、腕部、臀部、膝盖和脚踝。
采用均值平均精度(mean average precision, mAP)和首位准确率(Rank-1)来评价算法的性能。mAP为平均精度(average precision, AP)的平均值,即各类别AP的平均值。mAP的计算步骤如下。
步骤1假设待检索图片为qj,前n个检索结果中正确的正样本个数为c′(n,qj),则精度的表达式为
(8)
步骤2假设检索结果中共有M个正样本,正样本的集合为{i1,i2,…,iM},平均精度公式为
(9)
步骤3假设共有Nq张待检索图片,则均值平均精度的表达式为
(10)
图6展示了mAP指标计算示例,假设共有2个待检索的Probe图片。

图6 行人重识别mAP指标计算示例Fig.6 Example of mAP metric calculation for ReID
另一个评价指标Rank-n表示按照相似度排序后的前n个查询结果中,存在与查询目标属于同一类别的概率。实验选取Rank-1作为评价指标,即第一个查询结果与查询目标属于同一个类别的概率。在图7中,展示了Rank-n指标的计算示例,假设共有5个待检索的Probe图片。
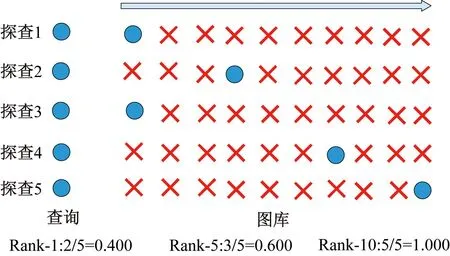
图7 行人重识别Rank-n指标计算示例Fig.7 Example of Rank-n metric calculation for ReID
3.2 算法改进的有效性
Occluded-Duke数据集是从DukeMTMC-reID中选择的,包含较多的遮挡行人图像,训练集中有702个行人的15 618张图像,测试集种有1 110个行人的17 661张和519个行人的22 10张图像用于图库和查询。
选择添加Circle Loss的BOT算法为基线模型,PT-Net算法在基线模型的基础上添加了姿态估计模块和Transformer模块。在Occluded-Duke数据集上的实验结果如表1所示,与基线模型相比,PT-Net算法在mAP Rank-1指标上分别提高了1.3、1.5个百分点。该结果表明,增加姿态估计和Transformer模块可以显著提高模型的性能。其中,姿态估计模块有助于更好地利用关键点信息进行特征对齐,而Transformer模块则能更好地捕捉输入序列中的长程依赖关系,从而提升模型的表达能力。

表1 Occluded-Duke数据集上的实验结果Table 1 Experimental results on Occluded-Dukedataset
3.3 对比实验
将PT-Net与3种不同的方法进行了比较,分别是传统的整体行人重识别方法[3]、带有关键点信息的整体行人重识别方法[29-30]以及被遮挡的行人重识别方法[10]。实验结果如表2所示。可以看出,普通的整体行人重识别方法和带有关键点信息的整体方法之间表现没有明显的差异。如基于部分的卷积网络(part-based convonlutional baseline,PCB)[3]和特征蒸馏生成对抗网络(feature distilling generative adversarial network,FD-GAN)[30]在Occluded-Duke数据集上的Rank-1分数均为40%,表明仅使用关键点信息并不能明显提高遮挡的行人重识别任务的效果。相比之下,针对被遮挡的行人重识别方法,在遮挡数据集上都取得了明显的改进。如姿态引导特征对齐(pose-guided feature alignment,PGFA)[10]在Occluded-Duke数据集上获得51.4%的Rank-1分数,HOReID[12]在该数据集上获得55.1%的Rank-1分数,这表明被遮挡行人重识别任务具有一定的难度,需要学习具有辨别性的特征和实现特征对齐。最后,提出的框架PT-Net在Occluded-Duke数据集上获得了最佳性能,其Rank-1分数和mAP分数分别为58.9%和49.5%,证明了其有效性。

表2 对比试验结果Table 2 Results of the comparative experiment
4 结论
针对行人重识别遮挡问题,基于姿态估计和Transformer技术,提出一种新的行人重识别方法PT-Net。本文方法对输入图像进行关键点检测,并将关键点信息与行人特征图像结合,产生基于姿态的行人特征表示,能够更好地解决行人遮挡问题。在Occluded-Duke数据集上的实验结果表明,与其他基于深度学习的行人重识别方法相比,该算法在mAP和Rank-1上分别提高了1.3、1.5个百分点,对于解决行人重识别中的遮挡问题具有一定的实际应用价值。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
意林(2021年5期)2021-04-18
学生天地(2020年3期)2020-08-25
扬子江(2019年1期)2019-03-08
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
小天使·一年级语数英综合(2017年6期)2017-06-07
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
