
基于模糊集合改进的TDOA声源定位方法
2024-05-17 11:57王晨光
计算机测量与控制 2024年4期
苏 石,申 冲,王晨光
(1.中北大学 信息与通信工程学院,太原 030051;2.中北大学 仪器与电子学院,太原 030051)
0 引言
在复杂环境下,空气中可能存在各种类型的音频信号,在这个混乱的环境中,如何不受干扰地准确定位自身想追踪的声源位置,是研究者们一直以来研究的热点领域。利用麦克风阵列技术进行声源定位作为一种关键的情报收集手段,在各种复杂场景中发挥着不可或缺的作用。它通过多个传感器组成的阵列获取信息,精确地计算出声音的来源位置,进而为人们提供实时可靠的信息和情报。当前基于麦克风阵列的声源定位主要通过三类算法模型实现,分别是高分辨率谱估计方法,可控波束形成方法和基于到达时间差(TDOA)的时延估计方法。
其中高分辨率谱估计方法通过计算各个阵元的相关矩阵,获取不同参数下的子空间,进而求取声源的方位信息;可控波束形成方法通过对采集的信号计算加权和得到波束,然后改变麦克风阵列接收信号的方向并计算信号的功率,不断搜索得到输出功率最大的波束方向,该方向即为所求的声源方位;基于到达时间差的时延估计方法(TDOA)主要分为两步实现,首先是估算同一声源到达阵列中不同 麦克风之间的时间差,其次再根据该差值求解声源 到达各个麦克风之间的距离,最后再利用求解几何的方法确定声源的方位[1-3]。
相较于前两种方法,TDOA方法计算量较小,实时性较高,在麦克风阵列声源定位系统中被人们广泛地使用[4],并不断做出改进。例如,文献[5]在研究表面冲击定位时,以水平分量精度因子(HDOP,horizontal dilution of precision)值作为判断依据调整传感器布置方式,配合通道时差补偿的TDOA算法精确定位冲击位置。文献[6]设计了一种基于TDOA高精度短波定位系统,采用软件无线电设计架构,射频前端采用直接带通采样,采用GPS和锁相环(PLL,phase-locked loops)相结合时钟方案对已知的短波信号进行定位。文献[7]针对室内定位系统中标签节点续航时间短、便携性低和标签容量小的问题,设计了一种嵌入式微控制系统,在分析系统主要功耗来源基础上,选取尺寸较小的超宽带(UWB,ultra wide band)模块完成收发功能。文献[8]提出一种改进的传感器位置不准确的最小二乘法。用TDOA与基于到达频率差定位法(FDOA,frequency difference of arrival)联合的方式确定声源的精确位置。文献[9]提出了一种基于多层感知机的水下声源被动定位方案,将多通道波形数据直接作为输入对多层感知机网络进行训练,从而获取高精度的定位神经网络。文献[10]研究了抑制非视距误差的定位算法,对非视距环境下的TDOA定位模型中的参数进行重构,作为中间参考变量,辅助其他算法得到更精确的结果。文献[11]旨在通过引入约束总最小二乘框架来提高三维TDOA_AOA(angle of arrival)定位算法的性能,将伪线性方程的固有特征作为附加约束,建立三维TDOA_AOA定位模型,再求解该模型中的多约束优化问题。文献[12]考虑到TDOA定位系统的性能受到时间同步误差的严重影响,针对TDOA估计的性能主要由频率信息决定的问题,提出一种基于互相关相位差补偿的目标信号和参考信号相干积分TDOA估计方法,同时实现目标TDOA和参考TDOA的估计。文献[13]为了提高定位特定区域辐射源的多个复杂目标时的实时性,将时延估计值数据输入神经网络获得模型,利用该网络定位未知目标。文献[14]利用IMMKF(Interacting Multiple Model Kalman Filter)算法与传统TDOA的Chan-Taylor算法协同工作,克服了传统卡尔曼滤波器在目标忽然改变运动状态时不能及时跟踪从而产生较大误差的问题。
除了上述的文献外,还有许多研究人员对TDOA算法做出改进,但在实际应用时仍需要采集到良好的信号数据作为基础,为了保证采集到良好的声源信号数据,往往需要设计滤波器及相关调理电路,使得整个采集系统的复杂性增加。因此本文旨在利用模糊集合对采集到的数据进行处理,之后再将这些数据带入TDOA算法内以提高该算法在面对复杂环境时的抗干扰性,这样便可以降低设计外部调理电路的复杂程度,降低硬件方面的压力。为了验证该想法的可行性,本文搭建了以6个麦克风形成的阵列作为声源信号采集模块的声源定位系统,测试本文采用的方法相比于传统TDOA是否有所提升。本文主要分为3个部分,分别为系统设计部分、算法研究部分和实验测试部分。
1 麦克风阵列定位系统设计
1.1 数据采集系统设计
本文的硬件设计方案采用了STM32F103CBT6型号单片机作为核心CPU,该型号单片机具有高性能、低功耗、体积小等优点,并且具有广泛的应用领域,间断性的操作节省了许多功率,非常适合于嵌入式应用系统的开发。麦克风阵列中的麦克风选用的是16 mm全指向咪头传声器,结合其相关外围电路作为本系统的采集声源模块,可以高效地采集空气中传播的声音信号。信号处理芯片及其相关外围电路则对采集到的信号进行放大和模数转换,增强了信号质量,便于后续处理。系统电源及相关电路提供了系统所需的电源支持,保证系统的可靠性和稳定性。
系统采集工作的主要流程为:系统运行开始后,麦克风阵列开始工作,采集空气中传播的声音信号,并通过信号处理模块进行处理。处理后的信号数字化后送入声源定位算法进行计算。声源定位算法对数字信号进行滤波抑噪,并利用获得的声音时延信息进行声源定位计算,最终得到声源位置信息。声源位置信息将通过显示器模块进行显示。整个系统的设计如图1所示。
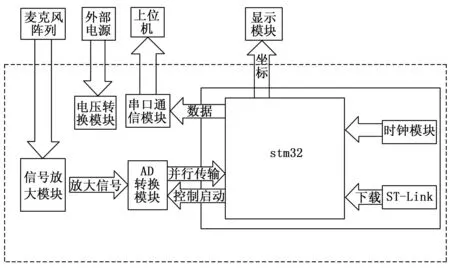
图1 系统硬件模块设计图
1.2 信号处理电路设计
本实验的信号处理过程包括运放和模式转换两个主要步骤。选择MAX9814信号放大器芯片实现幅值放大功能,放大挡位为20~40 dB。这种选择可以获得较高的信噪比,得到较为理想的数据。由于CPU芯片无法处理模拟信号,必须将其转换成数字信号。为此选择了AD7819芯片实现模数转换功能。AD7819仅使用地址解码逻辑,因此很容易实现到微处理器地址空间的映射,实现了信号的有效处理。信号处理相关原理如图2所示。
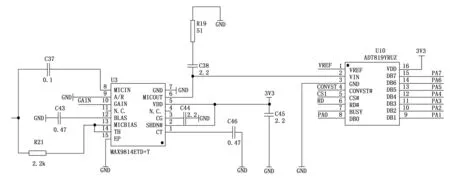
图2 数据处理相关电路原理图
图2为一路麦克风采集到信号的处理过程,本文采用的是正六边形麦克风阵列,所以整个系统有六路完全相同的上述所示电路共同接入STM32F103处理器,图3为处理器模块电路原理图。

图3 处理器相关电路原理图
2 声源定位模型的建立
2.1 麦克风阵列设计
麦克风阵列的设计对声源信号的成功定位起着关键作用。因此,本文综合考虑各方面因素,采用二维6元正六边形麦克风阵列作为整个系统的采集模块。以正六边形分布,将正六边形的几何中心作为声源检索范围的笛卡尔坐标系原点,相邻两个麦克风的间距为15 cm。如图4所示。
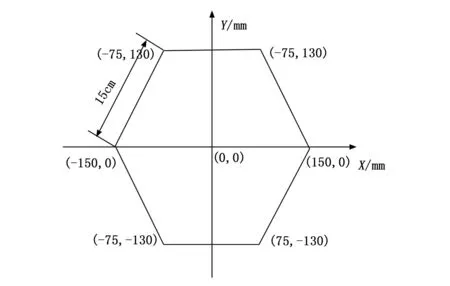
图4 麦克风阵列构型
利用麦克风阵列确定声源的方法主要分为两类:解析类和估算类。相比于解析类算法对数据高精度的要求,估算类算法通过不断比较估值、优化定位结果,从而逐渐逼近声源真实的位置[15],这种算法降低了对数据精确性的需求,如Taylor算法、网格搜索法[16]等。网格搜索是一种常用的超参数调优方法。在网格搜索时,需要对每个超参数指定一组可能的取值,然后对这些取值进行排列组合,形成一个超参数组合的网格。接着,对每个超参数组合进行模型训练和评估,最终选择在验证集上表现最好的超参数组合作为模型的最终超参数。通过网格搜索法进行声源定位时,即通过对声源必然存在的某一区域以一定的步长进行网格划分,利用音频信号特征计算指标,择优选取相应的网格坐标作为声源的估测点。
例如在图5中,点Si(i=1,2,3,4)为网格中点,点Mj(j=1,2,3,4,5,6)为麦克风所在位置,则网格中点到麦克风的距离为Dij,设声音信号从声源传递到麦克风的距离为Tj。在声源定位模型中,声音传播速度设为定值340 m/s,假设声源刚好位于点Si上,则根据速度公式可知:
(1)
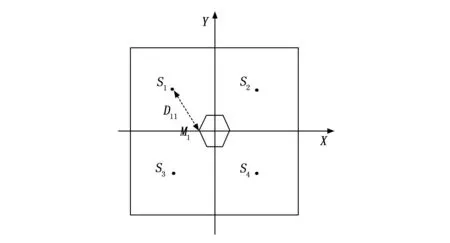
图5 网格搜索法示意图
若声源不在点Si上,则存在于点Sm(m=1,2,3,4)所在的网格内,其中:
(2)
此时点Sm所在的网格即为最优网格,Sm点的坐标即为最优估计点。
在网格搜索时,步长的划分会影响到搜索的效率和准确性。如果步长划分过大,可能会导致搜索结果不够精确,错过最优解;如果步长划分过小,可能会导致相邻的网格数据混淆,产生无效计算,从而浪费计算资源。
为了解决这个问题,可以采用多次迭代的方式,即先进行粗搜索再进行细搜索。具体来说,可以先以较大的步长进行网格划分,选出最优网格,然后在最优网格的基础上,以较小的步长对其进行细分,继续进行搜索。这样可以减少误差带来的计算量浪费,同时又能保证搜索结果的准确性。
需要注意的是,多次迭代的方式虽然可以提高搜索效率和准确性,但也会增加计算量和时间成本。因此,在实际应用中,需要根据具体情况权衡利弊,选择合适的搜索策略。
当选出最优网格后,便可进行下一次迭代,如图6所示。
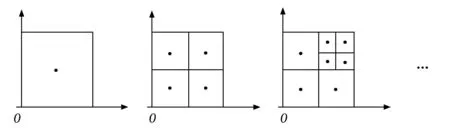
图6 网格迭代示意图
2.2 广义互相关TDOA算法
TDOA算法一般分为两步,首先是利用麦克风阵列采集的声源信号进行时延估计,第二步是根据时延值判断声源位置。时延估计具体而言是指利用麦克风阵列采集声源信号,利用麦克风阵列中不同麦克风接收到信号的微小差异从而求出信号到不用麦克风之间的时延值。这一过程,通常应用广义互相关算法。互相关函数是信号分析里的概念,表示的是两个时间序列之间的相关程度,即描述信号x1(t),x2(t)在任意两个不同时刻t1,t2的取值之间的相关程度。
下列公式中的X(t)表示为麦克风阵列每个阵元接收到的声音信号:
xi(t)=ais(t+τi)+ni(t)
(3)
式中,s(t)是以时间为变量的声源信号、a是阵元i接收信号的衰减因子、τ是阵元i接收信号相对参考麦克风接收信号的时延、n是阵元i接收到的加性噪声。
根据定义,两个信号的互相关为两个信号在不同时刻的期望:
Rx1,x2(τ)=E[x1(t)x2(t+τ)]
(4)
对于连续函数,有定义:
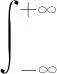
(5)
对于离散函数,有定义:
(6)
根据维纳—辛钦定理,互相关函数与其互功率谱密度互为傅里叶变换对,所以互相关函数也可表示为互功率谱密度的傅里叶变换形式:
(7)
Rx1,x2函数峰值对应的横坐标所代表的时间,即为两个信号的时延值。
在麦克风阵列对实际信号进行处理时,由于存在混响和噪音的原因,计算出的互相关函数的峰值往往不明显,降低时延估计的精度。所以在实际运算时,通常将互相关函数转换到频域进行处理[17],通过使用加权函数的方式抑制噪声带来的影响,再将该信号通过傅里叶逆变换转换回时域观察互相关函数的峰值。其主要过程如图7所示。
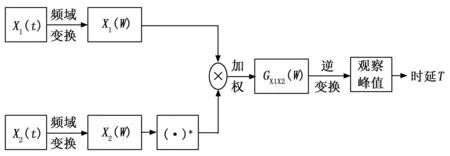
图7 广义互相关流程图
其中:(·)*代表共轭运算。一个共轭对相乘表示为Gx1x2(w),基于加权函数ψ(w)的广义互相关函数表达式为:
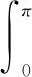
(8)
如此便可比较准确地估算出输入信号间的时延。
2.3 基于模糊集合改进TDOA算法
尽管估算类算法通常不需要进行复杂的计算,而且还可以稳定地获得声源坐标的估计值,但仍存在一些局限性。首先,进行比较的次数过多会增加计算和时间上的负担。而且,估算类算法的结果只是对真实值的逼近,而非真实值本身。如果时延数据存在误差,结果的精度将进一步降低。通常情况下,噪声、与实际不符的线性程度假设以及多径效应等因素都会对TDOA算法的结果产生影响。
首先,传感器需要具有较高的灵敏度才能够采集远处的声音信号。然而,具有较高灵敏度的传感器也会同时采集到环境中的微小噪声。远处的声源信号与近处的噪声混合在一起,会严重影响通信系统的精度和可靠性。
其次,在声音远场模型中,声音的传播路径被假设为线性[18]。然而,在实际的复杂环境中,由于存在复杂的传播路径和非线性效应,声音信号的传播路径并非完全是线性的。这导致计算结果产生误差,误差的大小取决于环境的复杂性。
区内葛仙山序列岩体与变质岩侵入关系清楚,接触面多外倾,呈舒缓波状,倾角40°~70°。外接触带均发育有宽窄不等的烘烤边,接触面多切割围岩片理。围岩接触变质较明显,形成绿泥石、绢云母等变质矿物。
此外,当存在许多遮蔽物时,如在地面上,声音信号会发生多种散射、反射和衍射现象,形成多径效应[19]。与单路径传播的信号相比,采集到的信号会有许多微小相位差的衍生信号。在时域空间中,相位差等同于时间差,因此多径效应会对TDOA算法中的时延估计部分产生较大的影响。
为了得到较为理想的声源信号数据,可以采用模糊集合来筛选特定的音频。假设正弦信号为y,则该信号可表示为:
y(t)=Asin(wt+φ)+e(t)
(9)
其中:A为衰减因子,e(t)为噪声。将该信号进行采集,设采集到的数据集为y:
y={y1,y2,y3,…,yn}
(10)
将采集到的数据进行模糊化处理,选择与采集信号对应的隶属度函数,计算实际采集到的信号对于目标信号的隶属度,并组成相应集合,这样采集到的原始信号就被映射到了一个模糊集合中:
y∈Y={y1/uy1,y2/uy2,…,yn/uyn}
(11)
其中:uyi是描述yi隶属于模糊集合Y中的程度。最后,我们需要将模糊集合中的元素进行反模糊化处理,得到实际的数值结果和f(x*)*。这一过程需根据原始数据不同的隶属度,对模糊集合中的元素做出不同的加权,从而得到更理想的数据:
f(xn*)*=uyn·gn
(12)
其中:uyn表示隶属度,gn代表加权系数,通过在不同信噪比条件下多次实验估计出最优值,根据经验选择合适的加权系数。
较为常见的隶属度分布函数有矩形分布、梯形分布、三角分布以及与噪声有关的高斯分布等。而根据数据发展的规律,又可将上述分布具体设定为偏小型、偏大型、居中型3种。对于特定声源的定位方法实验来说,无论数据的值偏大或偏小都会导致结果不准确,系统的性能下降,所以适合本实验的隶属度函数为居中型,当被测声源的频率为具体某一值时,可选择具有唯一最高点且便于计算的三角隶属度分布函数。三角分布的隶属度函数[20]分别如式(13)和图8所示:
(13)
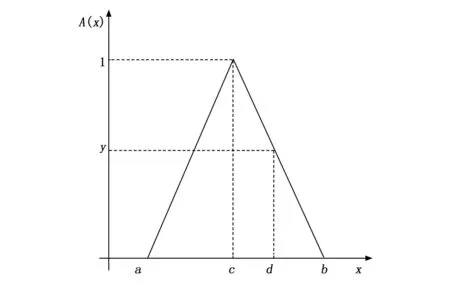
图8 三角隶属度分布函数示意图
其中:c的值已知,且为ab的中点。根据图片可知,当x=c时,隶属度函数的值可确定为1。当需要使用该隶属度函数时,就需要采用指派法明确分布图像上其余的任意一点(d,y),即可确定该隶属度函数的具体公式。再通过最大隶属度法将数据反模糊化带入后续计算。整个过程的实现流程如图9所示。
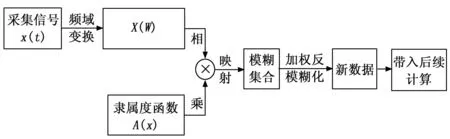
图9 模糊集合优化数据流程图
3 实验验证及结果
3.1 实验场景及过程


图10 实验场景图
3.2 算法性能测试
为了对模糊集合算法性能进行测试,利用麦克风阵列中的单个麦克风在距离3、9、20 m处,对相同的声源信号进行采集。为了便于观察对比,声源信号采用标准正弦信号。根据奈奎斯特采样定理,系统设备的采样率应为待测信号的2倍以上,结合本实验的硬件采集能力,待测声源频率定为2 kHz。对频域信号数据采用更便于计算的三角分布隶属度函数进行处理,指派其中一点的隶属度为(2 100,0.9),之后再还原成时域正弦信号,用原始采集信号作为对照,采集点数统一设定为128。采集到的原始信号数据分布如图11~13所示。
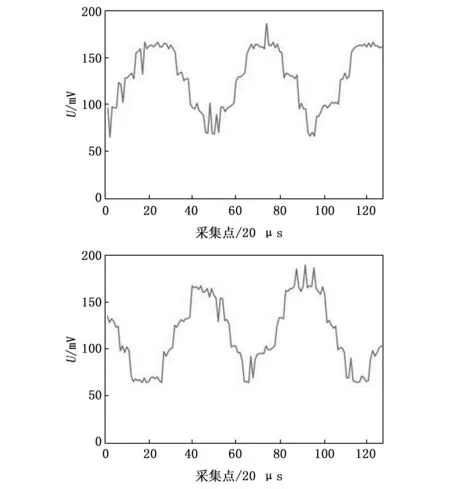
图11 传统算法(上)、本文算法(下)距离3 m时采集到的数据
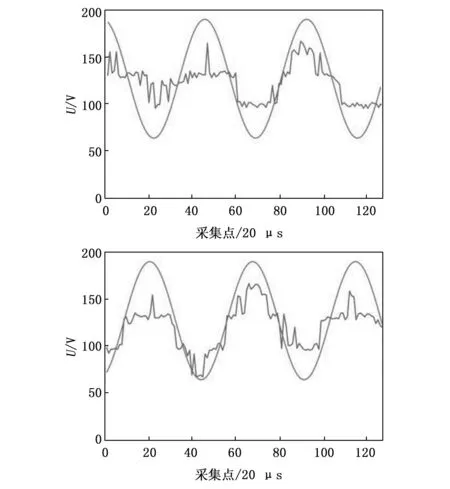
图12 传统算法(上)、本文算法(下)距离9 m时采集到的信号对比原正弦信号
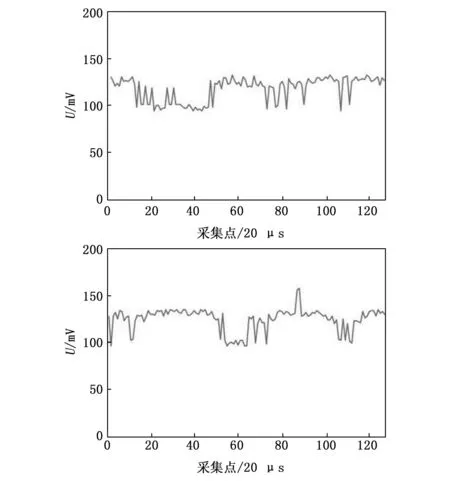
图13 传统算法(上)、本文算法(下)距离20 m时采集到的数据
根据对比图可以明显观察到,不论是对于原始数据还是经过模糊集合处理的数据,在采集距离逐渐增加的过程中,信号受到的干扰程度和失真程度也逐渐加大。然而,值得注意的是,在距离声源最远(20 m)和最近(3 m)处采集到的信号中,模糊集合处理效果并不显著。相反,在距离声源适中的位置(9 m)采集到的信号经过模糊集合处理后,其抗干扰性能更加显著。与标准正弦信号进行对比后发现,采用本文算法采集到的正弦信号更接近原始正弦信号。通过具体计算可知,在距离为9 m的位置采集到的数据中,原始数据的误差标准差为26.34,而经过模糊集合处理后的数据误差标准差为22.79,因此减小了3.55。由此可见,通过数据对比可以得出,在距离声源一定距离时,经过模糊集合处理后的数据相较于原始数据更加接近正弦信号,同时具备更强的抗干扰性能。
3.3 定位结果测试
为了观察应用本文算法进行声源定位的结果,本次实验与验证算法过程的声源音频信号保持一致,定位声源实验采用的声源音频仍然选择2 kHz的标准正弦信号。图14展示了实验过程的流程。
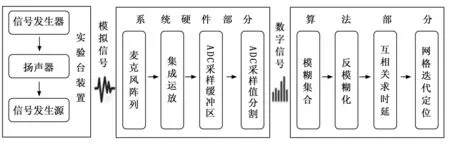
图14 实验流程图
对相同的声源信号进行定位实验,采用广义互相关TDOA和本文算法,与麦克风的距离从近到远选择三点S1(2,2),S2(4,8)和S3(6,12)(单位:m)作为声源位置,每个点分别进行10组测试,用来验证本文算法对广义互相关TDOA算法的提升效果。每组定位误差结果如图15~17所示。
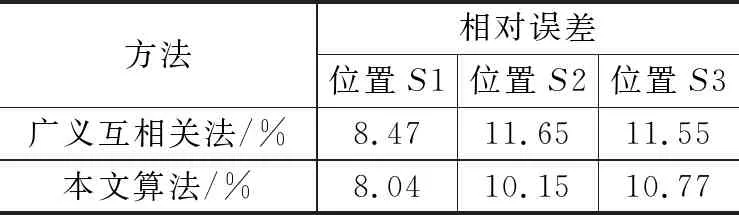
表1 两种方式进行声源定位的平均误差结果
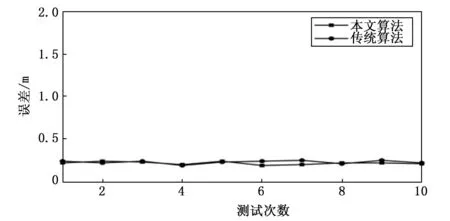
图15 点S1定位误差对比
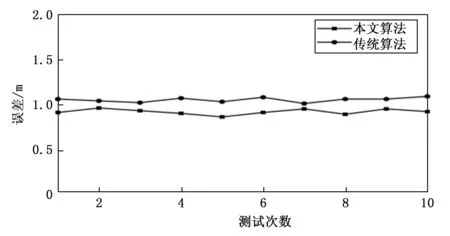
图16 点S2定位误差对比
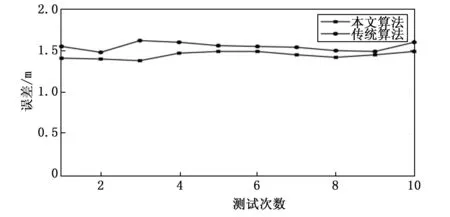
图17 点S3定位误差对比
3.4 定位实验结果分析
观察上文中给出的误差对比图和表格数据,当声源距离麦克风阵列变远时,两种方法定位的误差均增大。当对距离麦克风较近的点S1进行测试时,由于信号本身并未产生较大的干扰,所以采用本文算法的提升效果有限;当对点S2进行测试时,声源到麦克风阵列的距离相比之前有所增加,信号的干扰逐渐增加,本文算法的效果逐渐明显;当对点S3进行测试时本文算法效果略有优势。
分析产生上述结果的原因,主要是由于随着定位距离增大,干扰信号的数据分布超过隶属度函数的分布范围,超过的部分数据没有得到筛选处理,和麦克风阵列采集到的原始数据相同,所以效果略有减弱。如果想在后续实验中确定好隶属度函数的分布范围,把分布范围选定成最适合本实验的值。这可以通过以下几点:1)采用高精度的硬件采集设备保证采集到数据的准确性;2)选择最为合适隶属度函数分布,上文提到的高斯分布和三角形分布都较为合适,但二者的实际效果并没有进行比较,甚至是否有更适合本次实验环境的隶属度函数分布,在相关论文里也并没有前人进行总结,所以需要自行通过大量实验来选定;3)通过对已知的相同信号的多次测试,不断调整隶属度函数覆盖的范围,对比结果选择最理想的值。同时也可以选择增加迭代次数来获取更准确的位置坐标,但相应地也会增加系统计算的时长。
4 结束语
本文的目标是通过算法的改进,增强声源定位系统的抗干扰性,减少硬件采集设备的压力。而体现本文目标是否达成的方式,是通过观察在带有混响、多径效应以及噪声直接干扰的环境里,应用本文算法的结果精度是否优于直接采集后的计算结果精度。针对TDOA算法在复杂环境下的抗干扰性仍有较大的改进空间,本文采用模糊集合对采集到的数据进行筛选处理,并搭建简易硬件平台进行实验验证。尽管定位相对误差较大,但仍可以通过对比实验证明该方法相对于常用的TDOA算法,能有效改善信号数据失真的问题,进而提高系统整体性能。在未来的应用实践过程中,可以搭建更加精密的硬件实验装置,并且可以将该种算法与高性能滤波器相结合,进一步提高采集数据的准确性。同时也应该注意两点:1)对特定声源须选择适合的隶属度函数才能有效发挥其作用,这需要一定的先验知识和主观判断;2)本文试验为了验证算法的可行性,所以采用的声源为单一频率,属于理想情况,在实际应用时,面对某类声源频率大多是分布在某一段区间之内的。所以在未来对于声学信号与数据处理相关的研究工作中,应当积累和掌握好各类音频信号的指标与特征。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
复旦学报(自然科学版)(2019年3期)2019-07-19
电子制作(2019年23期)2019-02-23
电子测试(2018年23期)2018-12-29
测控技术(2018年6期)2018-11-25
小学科学(2016年12期)2017-01-06
噪声与振动控制(2016年5期)2016-11-09
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
做人与处世(2015年19期)2015-09-10
