
基于注意力门UNet网络的CT金属伪影去除方法
2024-05-17 11:56:56师晓宇
计算机测量与控制 2024年4期
师晓宇,王 斌
(中北大学 信息与通信工程学院,太原 030051)
0 引言
金属伪影是计算机断层扫描(CT,computed tomography)中常见的问题之一。当患者携带金属植入物(例如牙科填充物和髋关节假体)时就会出现这种情况。与身体组织相比,金属材料在光谱上会造成显著的X射线衰减,导致X射线投影不一致。不匹配的投影将会在重建得到的CT图像中引入十分明显的条纹和阴影伪影,这会显著降低图像质量并影响医学图像分析工作以及随后的医疗服务。这些金属伪影会掩盖植入物周围组织的重要诊断信息,严重影响医疗效果,比如导致医生难以对靶区进行精准勾画,进而对临床治疗效果产生诸多负面影响[1]。因此,金属伪影去除(MAR,metal artifact reduction)对提高临床诊断的准确性有着重要意义。
近年来,许多传统方法提出了MAR任务,主要可分为三类,即迭代重建、正弦图域MAR和图像域MAR。迭代算法旨在设计一些手工制作的正则化器,例如总变分[1]和小波域[2]中的稀疏约束,并将它们表示为算法优化以约束解空间。由于主观的先验假设,这些方法无法精细地表示临床应用中复杂多样的金属制品。基于正弦图域的方法将受金属影响的区域(即正弦图中的金属迹线)视为缺失数据,并通过线性插值[3]或先前图像的正向投影[4]来填充这些区域。然而,金属痕迹中的这些替代数据通常不能正确满足CT成像几何约束,这会导致重建CT图像中出现由于金属植入物影响的二次伪影。齐宏亮等人[5]提出了一种基于先验图像的CT插值校正算法,其中对原始投影数据进行插值后使用滤波反投影算法进行图像域重建后得到去伪影后的图像,为了避免初步校正产生的次级伪影,又提出了一种全新的滤波算法。这种算法能够得到较好的重建图像,但是由于先验图像的质量限制以及滤波算法无法进行自适应迭代,相对于深度学习去伪影模型鲁棒性并不突出。
随着近年深度学习(DL,deep learning)在医学图像处理领域的快速发展,基于深度学习的金属伪影校正方法也相继提出并取得了良好的临床效果。卷积神经网络(CNN,convolutional neural networks)在公开数据集的图像分析性能表现优于传统方法[4-7],同时比图形切割和多图集分割技术[8]快一个数量级。U-Net[9],DeepMedic[10]和整体嵌套网络[11-12]等全卷积网络(FCN,fully convolutional networks)[13]已被证明可以在包括心脏磁共振在内的各种任务中实现稳健和准确的性能。UNet是使用最广泛的深度CNN之一,特别是在医学影像方面体现除了良好的效果[14]。Xu等人[15-16]使用VGG(visual geometry group)网络,Wang等人[17]用条件生成对抗网络(cGAN,conditional generative adversarial network),Ding等人[18]使用FCN[13]分别进行了图像域的MAR方法研究?这类方法在对射线状伪影及椒盐噪声时展现了出色的效果,但对于带状伪影性能表现较差。史再峰等人[19]提出了多任务学习的生成对抗网络,利用连续伪影图像的空间相关性和解剖组织相似性并行处理学习,训练共享编码器和多个解码器重建出高质量的CT图像。Liao等人[20]提出无监督的伪影解纠缠网络(ADN,artifact disentanglement network),对图像域中正常组织与金属伪影进行分离以达到去除伪影的效果?但是由于金属伪影构成的复杂性,该方法在分离组织与金属伪影的过程中性能不稳定,加之在该方法中存在网络结构繁纷复杂,后续优化难度较大,提升效果有限。由于深度学习到的鲁棒特征表示,基于DL的MAR技术通常优于基于手工特征的传统方法。然而,现有的基于DL的MAR方法仍然存在着一定的局限性。他们中的大多数将MAR视作一般的图像恢复问题,较少强调在整个学习过程中嵌入的物理几何约束。大多数现有方法依赖于现成的DL工具包来构建不同的网络架构,对于特定的MAR任务缺乏足够的主要信息关注度,在恢复图像细节过程中造成混入背景信息以及组织保留程度不足的问题。
为了解决网络去金属伪影中图像恢复信息不足,背景信息与主要信息混杂导致组织信息保留不足的问题。本文提出了一种注意力门的UNet网络的医学CT图像金属伪影去除模型,能够在去除复杂CT图像金属伪影的同时有效保留金属植入物周围的解剖组织结构。
1 网络框架
基于UNet的CT图像金属伪影去除网络总体框架如图1所示,网络整体分为两个模块,分别为特征提取模块和强化特征解码模块。输入图像为大小256×256的CT灰度图像。在特征编码模块设置为4层,每一层分别有两组卷积层,每层卷积层由大小3×3的卷积核和线性整流函数(ReLU,rectified linear unit)激活函数构成。在经过每一层后都由大小2×2的上采样进行特征扩充后进入下一层重复操作到最深层。强化特征解码模块与特征提取模块相似,在接受深层提取信息的过程前会经过相同层级特征提取模块的注意力信息进行叠操作以强化信息提取编码的准确度,实现更有效的特征提取。
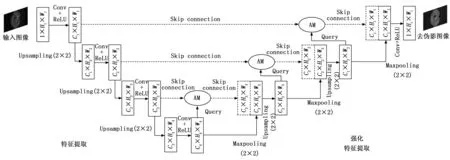
图1 网络整体框架
UNet网络结构作为经典的编解码器结构,编解码信息利用跳跃连接进行沟通从而避免大量空间的精准信息丢失的问题,直接将编码器中提取的特征合并至解码器相对应的层中。但是其中存在着初始编码器低阶层中由于提取的特征不精确,从而导致相应叠加的解码器层中存在很多的冗余信息,降低了网络的效果。为了避免这样的情况出现,在UNet的基础上加入了软注意力结构[21]的注意力门模块。意在通过注意力门模块抑制无关区域像素的干扰,突出特定局部区域的显著特征。使用软注意力结构代替硬注意力通过神经网络可以计算梯度并且前向传播和后向反馈来学习得到注意力的权重。软注意力结构的另一个好处在于其集成到标准UNet网络结构中时要简单方便、计算开销小,更加可贵的是可以提高模型的灵敏度和预测的精度。解码器经过上采样恢复出位置细节,但是上采样同样会导致边缘细节过平滑和位置关系不准确的问题。现有的一些工作[9]使用跳跃连接机制将底层特征与高层特征连接以补充位置信息。由于低层特征提取包含了无用的背景信息,此信息反而会导致目标对象的提取精度受到影响。为了加强模型对目标的提取效果,设计了一种为捕获高级语义信息并强调目标特征的注意力门模块。
注意力门控机制是一种通过动态调整模型对输入信息的关注度来提升模型性能和效率的方法。在深度学习中,注意力门控机制常用于处理序列数据或图像数据,帮助模型在处理和理解数据时,更加关注输入的重要部分,并忽略不重要的部分。注意力门控机制的核心思想是通过一个称为“门控”的机制来控制信息的流动。在最常见的形式中,门控机制采用自注意力机制,通过计算输入信息中每个位置的表示,并将这些表示应用于输入信息中的每个位置,以获得新的、经过注意力处理的信息。具体来说,自注意力机制首先对输入信息进行线性变换,得到一个表示输入信息的矩阵。接着,这个矩阵被分成多个独立的头,每个头都会独立地计算输入信息的注意力表示。最后,这些注意力表示被加权求和,得到最终的注意力表示。这个表示被应用于输入图像的每个像素,以产生新的、经过注意力的信息。
2 注意力门
2.1 参数更新
为了捕获足够大的感受野并因此提取附近组织信息,在UNet架构中逐渐对特征映射网格进行下采样。这样,粗空间网格级模型的特征就可以定位与背景与组织的关系。通过将注意力门(AG,attention gate)加入UNet模型中同样可以实现定位组织与背景,并且可以加强分割效果,其中注意力门避免了训练多种模型以及由此带来的参数量膨胀的问题。AG能够在训练中降低对图像中不相关的背景的响应,而避免了手动裁剪感兴趣区域(ROI,region of interest)。
从粗尺度提取的信息用于AG,以消除跳跃连接中不相关和嘈杂的区域,在跳跃连接操作之前执行仅合并相关的注意力区域,并且在前向传播和后向反馈来学习得到注意力的权重,这使得较低层中的模型参数能够基于ROI进行学习更新。
第l-1层中参数的更新由式(1)所示:
(1)

每个通道对应于特定的语义响应。金属伪影和人体组织通常涉及不同的通道。AG模块因此对语义依赖关系进行特征提取以强调目标通道。AG利用深层中的抽象特征和浅层中的全局特征以编码依赖关系。深层特征映射含有丰富的语义信息,可用于指导浅层特征映射以选择重要的位置详细信息。此外,浅层映射利用整体图像信息对不同通道的语义关系编码,可以实现过滤干扰信息。通过使用语义关系信息,AG模块可以强调目标区域并改进特征表示。AG模块如图2所示。
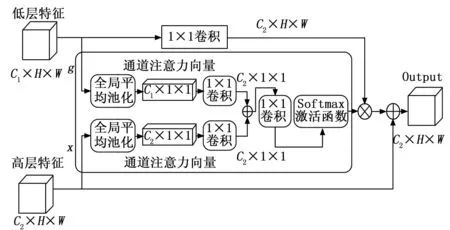
图2 注意力门模块
2.2 池化操作
高级特征映射和低级特征映射执行全局平均池化。其将整体信息压缩成一个具有信息权重的注意力向量以强调关键特征并过滤干扰背景。生成注意力矢量如下:
Fa(x,y)=δ1[Wαg(x)+bα]+δ1[Wβg(y)+bβ]
(2)
Ac=δ2[WφFa(h,l)+bφ]
(3)
其中:h和l分别为深层和浅层映射。g为全局平均池化。δ1为线性整流(ReLU,rectified linear unit)激活函数,δ2为softmax函数。Wα、Wβ、Wφ是指1×1卷积的参数。bα、bβ、bφ为偏差。
(4)
其中:n=1,2,...,c和x=[x1,x2,...,xc],W,H为图像宽和高。
我们对矢量进行1 × 1卷积,以实现对特征依赖关系的进一步确定。具体而言,1 × 1卷积核可以在空间维度上将输入特征映射的尺寸减小,同时保持深度维度不变。这有助于在不改变特征通道数的情况下,对特征图的感受野进行调整和改变。接着使用softmax函数对矢量进行归一化激活。softmax函数可以将输入值映射为概率分布,使得输出值的和为1。这使得模型能够将输入特征映射为相对权重的表示,进而实现特征的合理融合。然后将浅层特征映射与注意力向量相乘以生成注意特征映射。具体而言,我们将注意力向量视为权重系数,对浅层特征映射进行加权求和。这种操作可以使得模型能够根据浅层特征映射中的不同特征,自主地选择关注哪些特征并抑制其他不重要的特征。最后通过添加深层特征映射来校准所关注的关键特征。这一步骤有助于将浅层特征映射中未考虑到的信息,如空间信息等,融入深层特征映射中。同时,也有助于提高模型的表达能力和泛化性能。此外还使用了全局平均池化和1×1卷积来实现该模块。全局平均池化可以将输入特征图的尺寸减小至1×1,并将每个像素点的值压缩为一个标量。这种操作可以有效地降低计算复杂度,并且能够避免过拟合现象的产生。而1×1卷积则可以在不改变特征通道数的情况下,实现特征的重新组合和利用。相较于其他模块,该模块并没有添加大量额外参数,因此不会导致模型复杂度的显著增加。同时,由于全局平均池化的使用,该模块的计算成本也得到了大大降低。此外,该模块还具有较好的泛化性能和表达能力,能够有效地提升模型的性能和效果。
3 训练过程与损失函数
网络训练过程采用 Pytorch 框架,迭代epoch为500次,每次epoch迭代300轮。批处理尺寸为4,使用Adam优化网络,β1=0.6,β2=0.999,初始学习率为0.000 01,每训练20个epoch学习率下降为原来的1/2。实验环境:操作系统为Ubuntu20.04,Python版本3.7,使用Pytorch框架,硬件采用GPU:NVIDIA GeForce RTX2070 8 GB。
为了得到更加贴近主观视觉的MAR图像,设计了基于图像主观视觉的损失函数,在保证图像还原质量情况下充分保留原本的组织细节。该损失函数由灰度损失和总变分损失。
灰度损失LMSE,为生成样本与真实样本之间的均方误差,可以使生成样本图像尽可能贴近真实样本,如式(5)所示:
(5)
其中:N为训练集中样本图像对数;Xfree为生成的无伪影图像,Y为真实无伪影图像。
总变分损失LTV,由式(6)表示:
(6)
式中,H、W分别为图像的高度和宽度;▽x、▽y分别为图像在横纵坐标上的变分和。
总损失函数Ltotal由式(9)表示:
Ltotal=LMSE+αLTV
(7)
其中:α为权重用于调节效果,初始取值为0.2。
4 实验结果与分析
本文采用DeepLesion数据集[22]生成的图像验证所提方法的正确性和有效性,将所提方法与CGANMAR[23],CycleGAN[24],CNNMAR[2],UNet[9],ADN[20]进行对比实验。
4.1 数据集准备
利用文献[2]的方法,基于DeepLesion医学公开数据集[25]选取生成了3 040对金属伪影对照图像用于网络训练和测试,选取300对进行测试,图像为大小256×256的灰度图像。在对比实验中对选取的300对待测试灰度图像进行统一测试,得到结果图像进行标准客观标准定量对比,结果图像统一窗宽在-800~1 000 HU间,以方便观察比较。
4.2 评价指标
数据集中包含配对数据,可进行定量和定性评估。为了定量分析CT图像的金属伪影校正指标,采用峰值信噪比(PSNR,peak signal to noise ratio)、结构相似性指数(SSIM,structural similarity index measurement)、空域视觉信息保真度(VIFs,spatial domain visual information fidelity)、特征相似度(FSIM,feature similarity index measurement)作为定量评估指标。
PSNR是衡量图像失真程度或噪声水平的定量指标,使用PSNR对网络去除CT金属伪影效果进行评估,数值越高说明效果越好。MSE是待测图像x与标签图像y的均方误差,分别为:
(8)
(9)
式中,i,j为像素值,W,H为图像的宽和高;n为图像比特数。
SSIM是用来衡量两幅图像的结构相似程度,越接近1说明结构相似度越高,计算方式如式(10):
(10)
式中,μx、μy为图像亮度均值,σx、σy为μx、μy的标准差,C1、C2为对比度。
FSIM是用来衡量两幅图像特征相似度,其更加关注图片中界定物体的结构的边缘像素而降低了背景区域的像素的影响,更有助于反映主体的图像质量,其指标越接近1表明两幅图像的特征相似度越高,其计算方式如式(11):
(11)
其中:SL(x)为相位一致性特征相似度与梯度一致性特征相似度融合的相似度,PC(x,y)为相位两张图像的相位一致性特征相似度,I为完整图像像素域。
VIFs数值越高,结果图像和目标图像之间相关性就越强,指标越接近1效果越好,具体公式参考Bovik的计算方法[26]。
4.3 实验结果分析
4.3.1 定性分析
为了展示本文方法处理伪影图像、去除图像金属伪影恢复图像细节的性能,随机从测试集中选取了3组测试对比结果图。能够从图3中观察到,CycleGAN[24]作为一种无监督方法在无监督领域表现突出,但是这种模型还要求伪影校正输出能够转换回原始伪影影响图像,这虽然有助于保留内容信息但是同样鼓励了模型保留图像中的金属伪影结构,影响了模型最终的重建图像质量。ADN作为一种比CycleGAN先进的无监督学习方法,其生成的图像质量高于CycleGAN但是相比有监督方法仍然在伪影的去除方面存在着去除条纹不均匀,细节保留不充分的不足,如图4、5所示,伪影没有被有效地去除或减少。CNNMAR是基于投影插值的方法。CNNMAR能够较好地保留条纹但是结构性信息恢复严重不足。我们还发现,UNet的效果接近于cGANMAR的效果,cGANMAR在其后端使用类似UNet的体系结构。由于使用GAN结构网络,cGANMAR产生了比UNet更锐利的输出图像。UNet和cGANMAR在图像中都显示出了良好的效果,UNet产生的图像伪影去除效果较好但是结构信息保留细节不够;cGANMAR在感官上生成图像比较锐利并较好地去除了伪影亮条纹,但是在处理暗条纹情况仍然有所欠缺。作为改进的UNet模型,在单独UNet的基础上加入了注意力门模块,从表中可以观察到在结构指标以及峰值信噪比等均优于UNet。相比于UNet输出图像的整体清晰度下降的结果得到较高的PSNR,在图3在注意力门模块的加入后,本文方法得到了相比UNet更加清晰且对比度更高的去金属伪影图像。从图4、5中可以观察到,在有复杂金属植入物的情况下,上述几种方法的性能有了比较明显的下降,两种无监督方法CycleGAN和ADN去除条纹伪影的效果较差,CycleGAN还产生了新的暗条纹伪影,CNNMAR由于受到先验图像训练效果的制约,恢复了一定的组织结构但伪影没有能够很好地去除且过平滑问题较为严重,影响了图像质量。CGANMAR得到了对比度较高的图像,但是同样没有很好地去除金条纹伪影。UNet去除伪影的效果较为明显但组织结构的信息保留并不充分,在图像的部分区域出现了过平滑的问题。由于注意力门模块的加入,增强了UNet网络提取主干信息的能力,通过较粗粒度的特征图,获得语义上下文信息,进而对来自同层的encoder的特征图中不相关的特征进行抑制,提高了模型对目标区域的灵敏度和准确性本文方法在所示图像中均显示了优于上述方法图像的性能,能够在较好去除金属伪影的同时保留组织细节结构。在图4所示的金属伪影原始图像中可以看出,本图像中的金属植入物严重影响了CT扫描获得的图像质量,对于细节恢复工作提出了很大的挑战,CycleGAN恢复出的图像带有明显的金属条纹伪影,CNNMAR恢复出的图像出现了严重的过平滑问题,导致结构细节损失严重,严重影响了重建图像的可用性,cGANMAR在图像对比度方面取得了较好的视觉效果,但是在图4所示的ROI区域内,出现了结构丢失的问题,影响了图像的质量,UNet在HU值较低的区域丢失了较多的细节,导致重建图像的质量下降,这可能与UNet在设计损失函数中只使用了均方差损失有关,均方差损失在最小化误差的训练过程中会忽略标签与输入较小误差的像素,从而鼓励平滑输出结果;在ADN取得的结果图中可以观察到其结果相对于CycleGAN的结果有一定的提高,但是由于无监督学习的不确定性,产生的图像质量仍然存在着不足。在图5所示的模型结果对比图中可以看到,由于金属植入物的位置CT细节受到严重干扰,产生了亮度值过大的区域,对于该区域的细节恢复同样是一大挑战。与上图类似,CycleGAN保留了细节的重建图像对比度较高但是存在比较明显的金属伪影,CNNMAR在恢复复杂图像的问题上平滑效果明显影响了图像可用度,cGANMAR在HU值较低的位置去伪影效果较好,捕捉了图像细节,但是在组织结构明显的区域内没有取得理想的效果,UNet仍然存在组织细节丢失与组织平滑的问题,此图中,ADN在较低HU值时取得了较好的质量,同样留存了明显的条纹伪影,本文提出的方法在视觉效果上均超越了前述方法,取得了较为可用的重建图像。
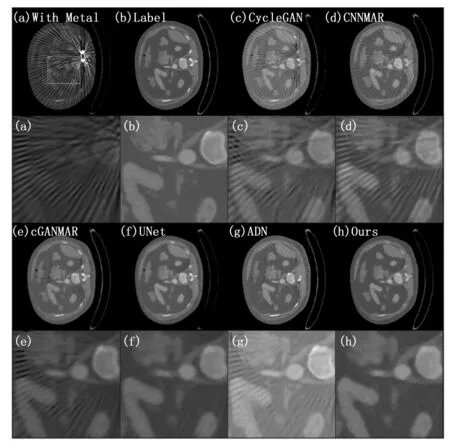
图3 腹部CT图像ROI区域金属伪影去除结果

图4 腹部CT图像金属伪影去除结果
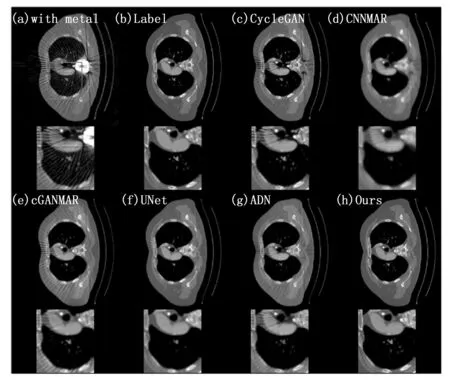
图5 胸部CT图像金属伪影去除结果
4.3.2 定量分析
表1展示了前述方法在选取的图像评价指标中所取得的结果。所示指标中UNet由于监督学习的学习方式,在优良先验图像和选取的合适的目标函数共同校正模型训练情况下,取得了一定的成绩,基于UNet模型和注意力门控模块的本模型同样取得了优良的成绩,在PSNR上取得了高于UNet的35.591 3的成绩,在PSNR的评价标准下已经达到了人眼分辨困难的程度。在SSIM和FSIM两种结构相似性评价指标中分别取得了0.928 8和0.961 3的成绩,在总体结构性和主要结构部分相似性得到了很好的效果。而其余方法在评价指标中并不理想,与前述定性分析结论相一致。

表1 测试集金属伪影去除结果平均指标对比
5 结束语
本文提出一种基于UNet的带有注意力门架构的MAR的模型。模型充分利用注意力门结构强大的细节提取能力进行CT图像的组织结构细节提取和恢复。在验证实验过程中,定性评估结果与定量结果指标均表明基于此监督数据集训练出的注意力UNet模型可以成功抑制金属伪影,并在重建图像中能够有效保留金属周围的组织结构和细节,与同类方法相比有着更好的性能。
猜你喜欢
睿士(2023年10期)2023-11-06 14:12:16
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学科学(学生版)(2021年3期)2021-04-13 08:26:18
小哥白尼(趣味科学)(2020年9期)2021-01-18 06:12:42
中国医疗器械信息(2019年3期)2019-03-09 02:51:58
中国医学影像学杂志(2018年9期)2018-10-17 01:27:18
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
Coco薇(2015年5期)2016-03-29 23:14:09
中国卫生标准管理(2015年4期)2016-01-14 05:16:44
