
基于样本扩充网络的水声目标分类模型优化算法
2024-05-17 11:56:44张博轩赵天白常振兴蒋翔宇王少博
计算机测量与控制 2024年4期
张博轩,赵天白,常振兴,蒋翔宇,王少博
(1.中国电子科技集团公司 第54研究所,石家庄 050081;2.国网电力空间技术有限公司,北京 102213;3.电子科技大学 信息与通信工程学院,成都 610731)
0 引言
水声目标识别技术是当今世界各国研究的热点和难点,随着新型低噪声推进器的研发和应用,如何在复杂的海洋环境中精确发现、定位和识别水声目标是各国海军部门都高度重视的问题。传统的水声目标识别方法主要利用经典信号处理方法提取目标特征并进行匹配,以此为依据对目标身份进行分类[1]。这类方法受人为经验影响较大,自适应能力差,在复杂多变的海洋环境中识别准确率较低。因此,针对水中舰船目标机械辐射噪声信号的人不在回路的识别成为水声信号处理发展的热点,尤其是如何将基于人工智能方法研发的目标识别算法模型从实验室扩展至实际环境中并依旧取得良好、稳定的性能,是此类方法研究过程中的重中之重。
将人工智能技术引入水声目标识别系统这一思路尚未取得突破性进展,无法在海洋实战中实现应用赋能,其根本原因是深度神经网络模型若想达到对数据的高效、准确的智能化处理,绝离不开用大量的数据来训练模型参数。但是,由于绝大部分高价值水声目标现存数据稀少,敏感目标难以采集,导致可供训练的声学数据样本数据严重不足,从而影响了该方法的识别效率。传统的水声目标识别方法不需要大量的声呐信号数据,如线谱分析法、匹配滤波法等。虽然这些方法在仿真中都取得了较好的识别效果,但它们对声呐的信噪比或先验因素要求较高,对不同类型的声信号的辨析能力相差较大且检测速度较慢,难以应用于实时且噪声较复杂的场景。
在有限样本闭集的前提下,文献[2]等采用支持向量机(SVM,support vector machine)对鲸鱼声数据集进行处理,达到了94.5%的多类识别准确率;文献[3]基于SVM提出差分进化粒子群混合算法,调优了核函数和惩罚项参数,以识别不同水下目标的辐射噪声;文献[4]团队提出梯度提升机(AdaBoost)和SVM混合模型,对水面舰船辐射噪声目标信号进行识别,在样本和特征数量减少50%的情况下,取得相同的识别准确率;然而,这些方法在面对样本分布不均衡或总体样本较少的情况时,性能下降严重,而这两点是在真实的海洋舰船机械辐射噪声信号侦收过程中普遍存在的问题。因此,在有效信号采集较少的情况下,如何让水声目标探测与识别装备保持较高的分类准确率仍是一个极具挑战性的问题。
针对这一问题,在深度学习领域已有相关思路,系主要通过对数据进行变换、生成等操作来解决样本缺失问题。文献[5]提出了生成对抗网络(GAN,generative adversarial network),将源域映射到目标域;文献[6]将特征提取器和分类器分别作为标准GAN(standard generative adversarial network)[7]、最小二乘GAN[8](least-squares generative adversarial network)和相对GAN[9](relativistic generative adversarial networks)中的生成器和判别器,并用GAN的基本训练方式引导其交替更新参数,从而使各个GAN变体模型学习到源域目标域指定特征;文献[10]设计了部分共享参数的特征提取器,以获得声纹特性的更好表征。文献[11]则采用循环一致对抗生成对抗网络(CycleGAN,cycle generative adversarial networks)学习源域与目标域无标签数据特征之间的映射,将源域带标签数据转化至目标域进行模型训练,从而保证目标域声纹数据能够被准确识别[12]。
基于上述分析,在目标的数据样本集总量不足或分布不均时,如何利用先验信息或现有的少量样本生成大量的、有效的充足样本集以辅助模型训练,从而提升识别模型的稳定和泛化性能,是制约深度学习赋能于水声目标识别系统的瓶颈问题,也是深度神经网络模型在水声目标识别问题中迈向实际应用的必经之路。
为解决该问题,本文提出一种基于样本扩充网络的水声目标分类模型优化算法。该方法首先对实际侦收的水声信号进行预处理,提取其梅尔倒谱系数和时频谱图后,利用基于CycleGAN的样本扩充网络和少量的真实数据实现样本生成,加入后续的深度神经网络训练中,从而降低后续训练的迭代次数和收敛难度,并提升模型分类识别的准确率、稳定性与泛化能力。实验表明该方法在声呐信号样本较少的情况下,通过网络进行样本扩充,有效提高了神经网络模型的识别准确度,收敛速度和稳定性[13]。
1 CycleGAN网络原理
CycleGAN是GAN网络的一个重要分支,通过在源域目标域互相映射,生成更符合需求的样本。CycleGAN的原理从本质上分析是利用两个相互镜像对称的环形生成对抗网络结构,通过在源域、目标域的4个判别器和两个生成器中建立映射,以实现样本的传递和循环。并对判别器进行针对性设计,以适应环形结构带来的改变。
具体地,该网络由两个生成器和4个判别器组成,多个模块需要不同的约束条件来训练参数。其损失函数如下:
(1)
其中:前两项是不同的对抗损失,第三项为身份映射损失,而第四项为循环一致损失。对抗损失是基础的GAN损失,在对损失值进行极大极小化的博弈过程中提升生成器的生成能力,以得到符合需要的生成样本。循环一致性损失使网络循环生成样本与原始输入样本的特征保持一致,从而保证在两个生成器的计算过程中保留全部海况信息以及船只信息。身份保持损失与循环一致性损失相似,均用以训练生成器。在训练过程中,需将这四类损失按权重相结合作为最终优化函数,确保模型向目标方向学习并逐步收敛。
为保证生成样本的多样性和更好的训练网络,本文通过加入掩码来训练CycleGAN。在加入掩码后,CycleGAN的损失函数需要更新为:
(2)
(3)
(4)
(5)
以上损失函数均为原样本与掩码m点乘得到。
2 基于样本扩充网络的识别模型优化方法
本文基于CycleGAN搭建了如图1所示的样本扩充网络,其主要包括预处理、扩充网络和分类器3个部分。接下来将对模型的每一部分进行详尽的阐述。
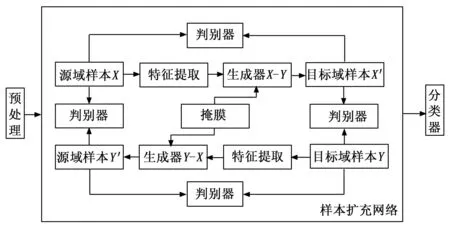
图1 样本扩充网络框架
2.1 预处理
声信号识别中,音频信号中的频率成分是随着时间推移而变化的,无法直接对整段音频提取特征。因此,本文需要首先对长时间的音频信号进行分帧处理,利用短时傅里叶变换(STFT,short-time Fourier transform)等分析手段对信号进行解析,以兼顾在不同维度下短帧信号的时频分辨率。
将长时间信号进行分帧,本文利用滑动窗加权的方式实现。常用的窗口包括Kaiser窗、Blackman窗、Hanning窗、Hamming窗、矩形窗等,本文采用的窗函数是Hamming窗。
窗函数的数学表达式为:
(6)
针对时域信号,进行了加窗之后的信号输出为:
Oi=xi(n)*w(n)
(7)
考虑到水声信号为单通道音频,可以通过谐波分量和冲激分量分解(HPSS,Harmonic and percussive source separation),将单通道音频转换为双通道立体声,其中两个通道分别为谐波分量与冲激分量,作为新的音频输入供后续特征提取使用。HPSS的具体步骤如图2所示。
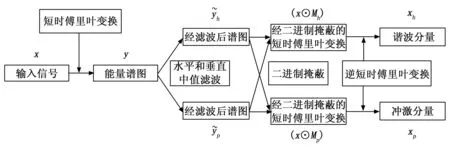
图2 HPSS提取步骤
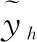
(8)
而在使用中值滤波时,我们使用了01掩蔽矩阵(binary masking)的方式,对谱图进行处理,掩蔽矩阵Mh和Mp的构建方式如下:
(9)
使用掩蔽矩阵Mh和Mp将STFT中所有的时域-频域容器划分到为谐波分量或冲激分量中,进而从原始的STFT结果划分出谐波分量Xh和冲激分量Xp:
χh=(χ⊙Mh)
χp=(χ⊙Mp)
(10)
最后,通过逆快速傅里叶变换(iSTFT)将修改后的频谱图Xhχh和χp反变换回时域,产生分离的谐波和冲激信号。
利用深度学习进行信号处理时,直接对经过预处理之后的水声信号进行采样,再将数据合成一维向量作为深度学习模型的输入的方法不但难以深度挖掘频域信息,而且采样数据往往受水下噪声的影响较大,不利于分类器对水中目标的精确分类和识别。
而时频图像包含了水中目标的时域、频域、幅度的三维信息,更能从多个维度表示出水中目标的特征,包含的信息量更加丰富,同时,作为二维图像,适合利用卷积神经网络(CNN,convolutional neural network)进行特征的提取和分类,故本文将时频图像和梅尔频率域的倒谱系数谱图作为表征水中目标的数据作为深度学习网络的输入。
对初步处理后的一维时域音频信号求取其梅尔倒谱系数(MFCC,mel-scale frequency cepstral coefficients)。MFCC参数是参照人体听觉的临界带效应设计而成,目前在语音领域被广泛应用,具有良好实践效果[14]。
MFCC谱图的提取流程图如下,首先对信号进行分帧加窗,从而使信号局部平稳,而后通过离散傅里叶变换获得能量谱。在获得音频的能量谱的同时,还需要构造一个梅尔滤波器组,并与能量谱进行点积运算得到梅尔频谱图。梅尔滤波器组的作用是将能量谱转换为更接近人耳机理的梅尔频率,本文中设置梅尔滤波器的个数为128。滤波过程的公式如下:
(11)
其中:N表示每一帧的总点数,Hm(f)为梅尔滤波器组系数。
MFCC与时频图类似,区别在于时频图为线性谱图,而MFCC的频域轴为非等间距划分,达到了展现更多低频细节的目的。同时MFCC的滤波器组构建也不同于时频图的正弦波,而是三角滤波器。MFCC的计算公式如下:
E′(m)=lgE(m)
(12)
为了适配模型的图像处理性能并提升对比模型的易适配度,本文选取了包含大量目标时频域信息的LOFAR谱作为模型的输入样本[15]。信号的预处理和特征提取流程如下:首先对水听器阵列采集的多阵元时域信号进行空域[16]、频域滤波,随后对得到的一维声波序列信号进行滤波得到一组帧序列{L1(n),L2(n) ,…,Lk(n)},对每一帧Lk(n)进行标准化和中心化处理:
(13)
(14)
其中:yk(n)代表标准化后的信号,N代表帧长度,xk(n)代表中心化后的信号。将信号的采样序列分为连续的若干帧,每帧N个采样点。接着对每帧信号做归一化和中心化处理,最后对处理后的每帧信号加窗做短时傅里叶变换得到时频谱图。
2.2 扩充网络
扩充网络由2个生成器、4个判别器组成。生成器可分为3个模块:下采样模块、残差提取模块和上采样模块,如图3所示。
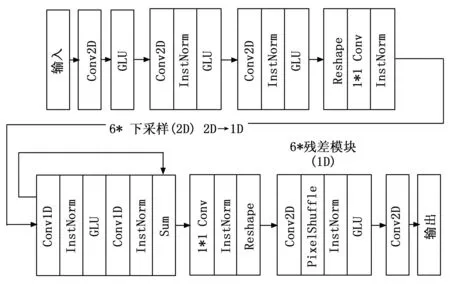
图3 生成器结构示意图
在上采样模块中,经过掩码处理的特征向量通过两层卷积层进行特征提取。模块再经过一层1*1的卷积层将二维特征转化为一维特征。在残差提取模块中,网络利用六个相同的残差模块对源域的一维特征进行转化,保留源域海况信息的同时将源域特征转化为目标域特征。下采样模块通过一层1*1的卷积层和三层二维卷积层将一维特征转化为二维的具有目标域特征的特征向量,其二维尺寸大小与输入的源域合成特征向量一致。具体网络参数见表1,其中n代表每个批次的样本数量。
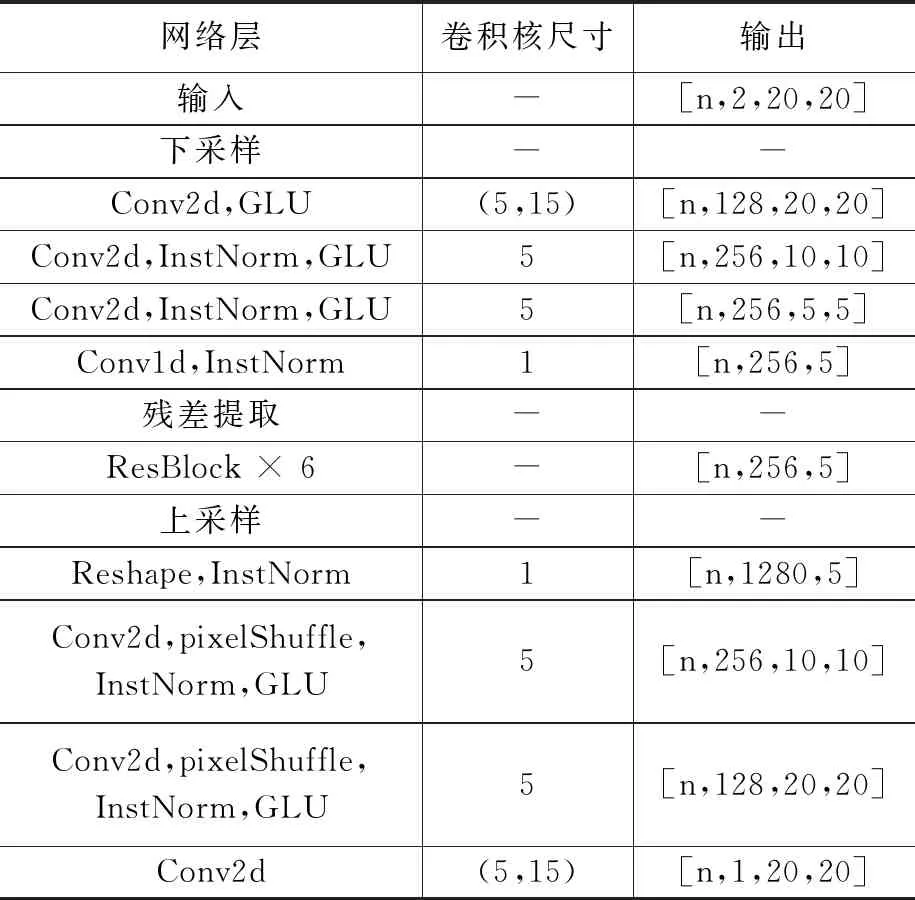
表1 生成器网络结构参数
4个判别器结构如图4所示。通过一层卷积以及4个卷积下采样模块对其进行特征提取,最后送入一个大小为1的输出卷积层,进行判别。判别器的具体参数见表2。
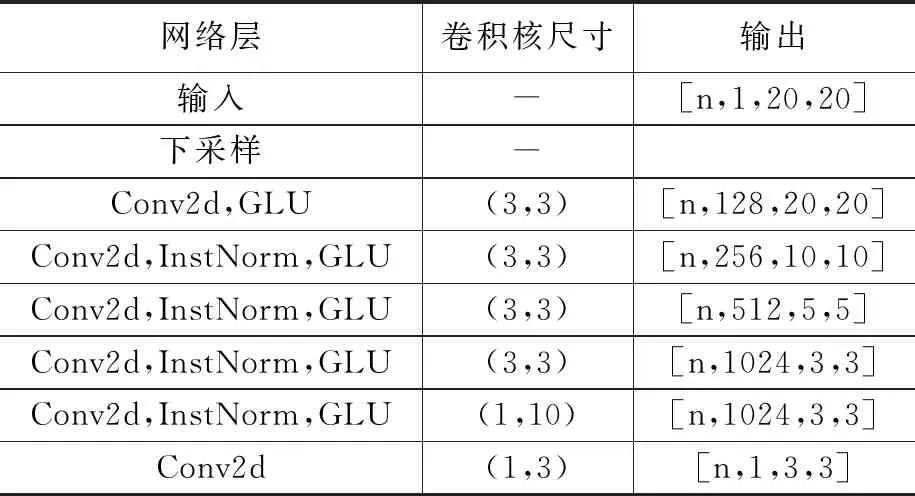
表2 判别器网络结构参数
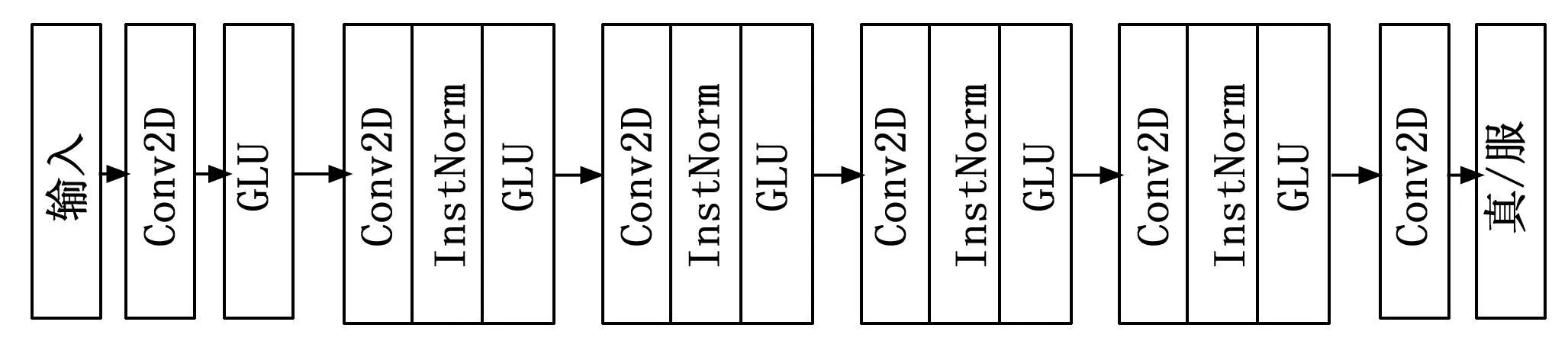
图4 判别器结构示意图
2.3 分类器
2.3.1 分类器模型
本文使用KNN[15]、CNN[16]和残差网络[17](ResNet,resident network)3种基础网络搭建不同分类器。其中KNN超参数n_neighbors为9,p为1;CNN共4层卷积层,kernel_size为3;ResNet18由4个block和一个前置卷积层组成,kernel_size为5。
在选取模型配置时,综合了水声目标分类领域的数据集规模和样本特征等因素,从而选择ResNet框架来搭建模型。
与其他卷积神经网络不同,ResNet的提出是为了解决梯度爆炸和消失问题。随着神经网络的网络层深度不断增加,但是网络的性能和模型的参数并非线性关系。而在模型层数太深时,反向传播的梯度信息并不能更新到浅层的参数,或者梯度太大导致参数不断跳变,模型失效。
ResNet的解决方法是引入了“残差学习”(RL,residual learning)的思想。所谓残差学习,是指将输入与输出的差值(即“残差”)学习到,然后将该残差加到输入上,从而得到输出。这样做的好处是可以让网络更容易地学习到恒等映射(Identity Mapping),从而避免了梯度消失和爆炸的问题。
具体来说,ResNet通过在网络中添加“残差块”(Residual Block)来实现残差学习。它包含了两个卷积层和跨层连接,负责从输入数据中学习和提取特征。通过两个卷积层来保持输入输出的维度不改变,然后通过跨层连接来规避模型在遇到简单任务时拟合难的问题。通过这种结构,既能让模型的梯度传播到浅层网络,也能在更低的维度空间中持续提高模型的学习能力。
ResNet18是ResNet系列的一个变体。与其他变体相比,ResNet18的架构较浅,有18层。虽然它的层数较少,但仍然具有强大的特征提取能力。
在训练数据有限的情况下。ResNet18具有较浅的结构,可以帮助减少过度拟合,提高泛化性能。并且ResNet18在模型容量(捕捉复杂模式和特征的能力)和模型复杂性(参数和层的数量)之间取得了平衡。它提供了一个合理的深度架构,能够有效地捕捉和学习有用的特征,而不会变得过于复杂或容易过度拟合。
2.3.2 神经网络结构参数的确定
鉴于本文将经过预处理和特征提取的信号谱图作为多模态深度神经网络模型的输入,将根据获得的信号数据决定网络结构的具体参数。
对于CNN和ResNet来说,其搭建过程中有关的主要参数如下:
1)卷积层的卷积核大小、卷积核个数;
2)激活函数的种类(常用的如Sigmoid,tanh,relu,leaky relu);
3)网络的层结构(卷积层的个数/全连接层的个数);
4)池化方法的种类;
5)Dropout的概率;
6)有无归一化。
通过神经网络使用的经验可以得到,在调整参数时,重要的是先调整网络的层结构、卷积层的卷积核个数以及激活函数的种类,其他参数虽然也会对性能或多或少地产生影响,但是差异不大,所以首先确定重要参数,然后再对其他参数进行微调即可。
我们根据信号包含信息的丰富程度来调整CNN的结构以及每一层的卷积核个数。由于提取的LOFAR和MFCC谱图具有概括性的特点,CNN的层数不宜过多,以三层为初始值根据实际实验结果进行微调。若声纳数据中只包含单个识别的目标,我们将用适当的卷积核数量,在增强网络对于多层次信息的提取能力的同时避免过拟合问题。对于池化层,由于水声数据具有较强噪声,而可选取最大池化,以突出信号特征。
考虑到该网络模型在深层特征提取方面的优势,构建多层ResNet。而适当增加隐藏层向量的维度有利于增强向量对水声目标特征的表征能力,提高分类识别率。同时为了避免过拟合,在ResNet网络中采用了迁移学习的思想,即将该模型参数的初始值设定为在ImageNet数据集经过训练的模型参数,有利于模型收敛至最优值。对于池化层,选取平均池化,以保留丰富的信号特征。
对于激活函数,常用的激活函数种类包括Sigmoid,tanh,ReLU,leaky ReLU等。Sigmoid和tanh激活函数的缺点在于当输入值过大或过小时易出现梯度消失的现象,不利于神经网络的训练,而相比之下,Leaky ReLU和ReLU可以很好地避免这一现象,因此,采取ReLU作为神经网络的激活函数。
再确定以上3个参数后,对于卷积神经网络的其他参数(如卷积核大小,池化方法等)采用实验微调的方法,寻找在此问题场景下的最佳参数值。
2.3.3 神经网络训练策略及优化方式
对于水中目标识别问题而言,需要搭建的模型往往较为复杂,批量梯度下降法计算量过大,消耗的内存过多,随机梯度下降法易陷入局部最优,从而导致模型过拟合,因此,两种算法均不适用。Adam算法则将批量梯度下降法和随机梯度下降法二者相结合,利用一阶矩估计和二阶矩估计可以实现学习率的自适应调整。Adam算法本质上利用梯度的一阶矩估计和二阶矩估计动态调节每个参数的学习率。在经过偏差修正后,每一次迭代都有确定的范围,使得参数比较平稳,善于处理稀疏梯度和非平稳目标。与此同时,算法对内存的需求小,且较适合应用于大规模数据及参数的场景。
3 实验设计
3.1 平台及数据集
本文实验的运行平台:操作系统为Ubuntu20.04,GPU为NVIDIA RTX 3090,内存大小为16 G。开发语言和平台为Python3.8和Pytorch1.19。
本文实验采用两个数据集,均为舰船噪声信号,每个样本持续3秒,采样率为5 000。数据集A包含6种不同海洋条件下的3类舰船辐射噪声。如表3所示,数据集分为训练集和测试集,训练集共有7 046个样本,测试集共有1 459个样本。训练集为第1~5天采集数据,测试集为第6天采集数据。
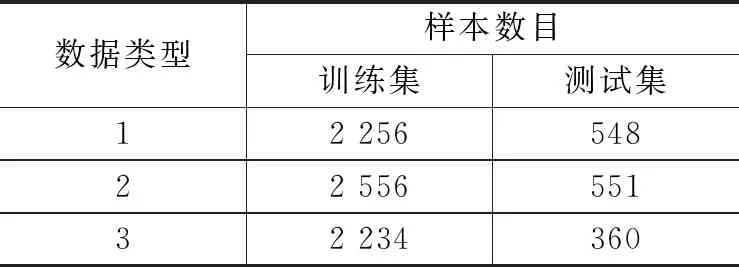
表3 数据集A详细
数据集B包含4类船只在不同海况、航行状态的辐射噪声,单个样本的平均持续时间为3.3 s。总共有11 307个样本,具体情况如表4所示。各种海洋条件下的样本均匀分布在整个数据集中。每一类样本按1∶1的比例分为训练集和测试集。
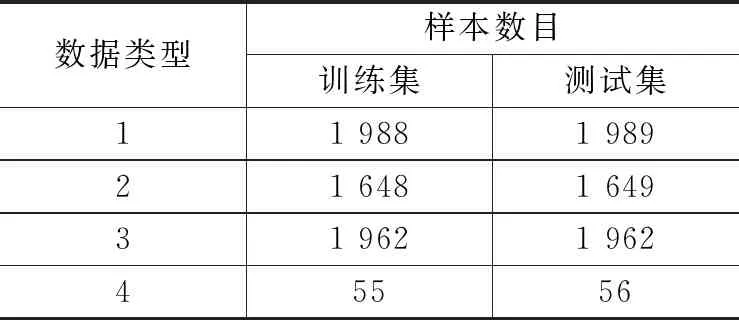
表4 数据集B详细
3.2 网络超参数配置
实验通过对比不同参数设置下的网络性能,得到了最佳参数配置,具体为:生成器和鉴别器的初始层卷积核大小为5*5,卷积层数分别为12和5,训练批次大小为64、训练轮次为160、掩码长度25。
3.3 评估指标
本实验采用3种评价指标来验证算法的性能,分别为声纹识别准确率、损失函数loss值、余弦相似度。
余弦值匹配算法[18]利用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0°,也就是两个身份特征向量越相似,越有可能属于同一个目标个体。公式定义为:
(15)
4 实验结果与分析
本文总共两个独立实验,分别使用A、B两个数据集。实验一旨在验证扩充网络对分类器的整体性能的提升效果。实验二旨在验证扩充网络对分类器识别小样本类的提升效果。
4.1 实验一
首先通过提取舰船噪声的MFCC谱图[19]或LOFAR谱图特征,训练样本扩充网络,让网络能够生成目标域样本的特征谱图,再通过反变换生成一维音频声信号。本次实验在数据集A的三类样本中互相生成对应的声信号样本,使得三类样本训练集的数据量均为7 046,测试集不做变化。
实验中,根据生成器和判别器loss的误差值判断网络的收敛速度[20]。鉴别器的loss曲线呈现先上升后下降趋势,在96轮次后基本收敛。生成器的loss曲线总体呈现下降的趋势,在120轮次后基本收敛。
在样本扩充网络训练完成后,分别对1,2,3类生成样本,并与目标类计算LOFAR谱图的余弦相似度,如表5所示。

表5 实验一 余弦相似度
在完成类间余弦相似度的验证后,通过ResNet18搭建分类器进行对比实验,比较分类器的准确率曲线,验证扩充网络有效性,分类结果如图5所示。
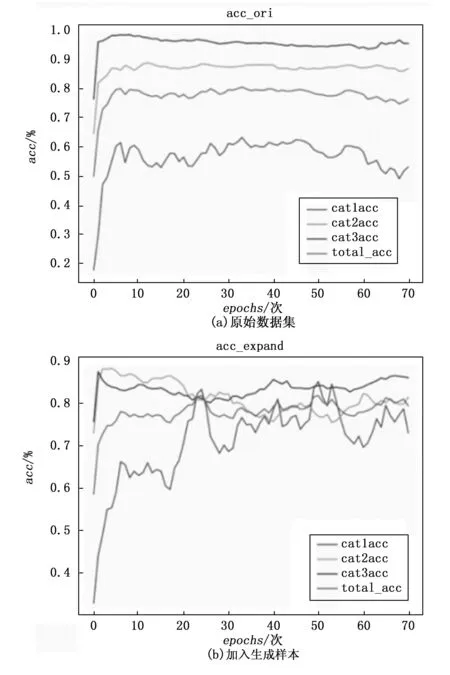
图5 分类器准确率对比
分类器共训练70轮次,自上而下第三条曲线是总准确率。在加入生成样本后,分类器的总准确率从76%提升到80%。为确保结果的准确性,实验进一步选取了3个不同的分类器进行验证,分别为KNN,CNN(4层卷积),ResNet18,每个实验重复5次,并在表6中给出平均统计结果。
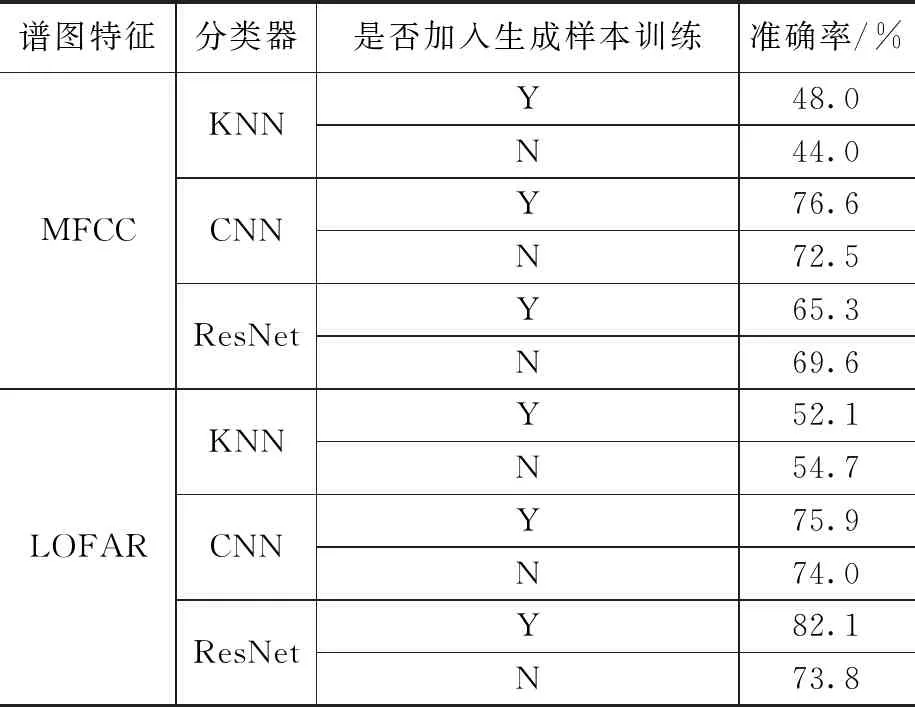
表6 实验一样本扩充前后分类准确率
经过对比实验可以看出,在不同分类器网络中,使用样本扩充网络扩充数据集,均能提升分类识别效果,相较于在原始数据集上最佳准确率74%,加入生成样本后,最佳准确率能提升到82.1%。
4.2 实验二
实验二首先通过提取舰船噪声的MFCC谱图/LOFAR谱图特征,训练样本扩充网络,使得网络能够生成目标域样本的MFCC/LOFAR谱图。再通过反变换生成声信号样本。与实验一不同的是,此次实验采用数据集B的一半作为训练集,一半作为测试集,在样本扩充网络训练完成后,只针对第4类进行扩充。
实验中,根据生成器和判别器loss的误差值判断网络的收敛速度。由于第4类样本数量与其他3类相差过大,训练过程中需要多次调整学习率。判别器的loss曲线训练时呈现先下降后上升的趋势,在300轮次时基本收敛。生成器的loss曲线呈现先上升后下降趋势,在450轮次时基本收敛。
在样本扩充网络训练完成后,对第4类原始样本和生成样本计算余弦相似度,结果如表7所示。

表7 实验二余弦相似度
训练好扩充网络后,通过ResNet18搭建分类器进行对比实验,比较分类器的准确率曲线,验证扩充网络有效性,分类结果如图6所示。
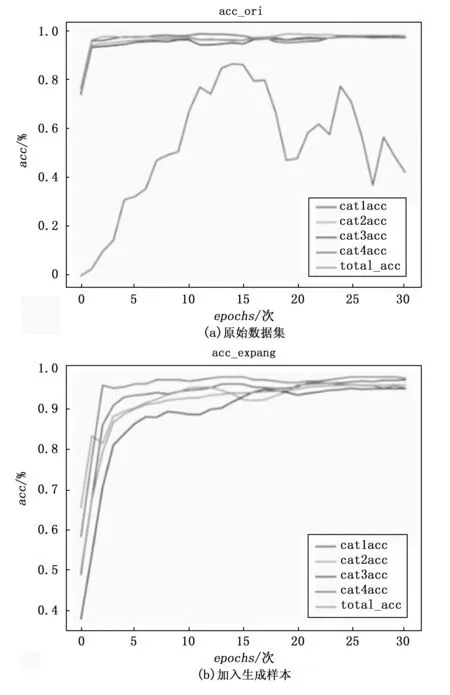
图6 分类器准确率对比
分类器共训练30轮次,前4条曲线是单类的准确率,自上而下第四条曲线为总准确率。在加入生成样本后,分类器的综合识别准确率从88%提升到了96%,且收敛速度加快,模型也更加稳定。
为确保结果的准确性,进一步选取了3个不同的分类器进行验证,分别是KNN,CNN(4层卷积),ResNet18,每个实验重复5次,并在表8中给出平均结果。
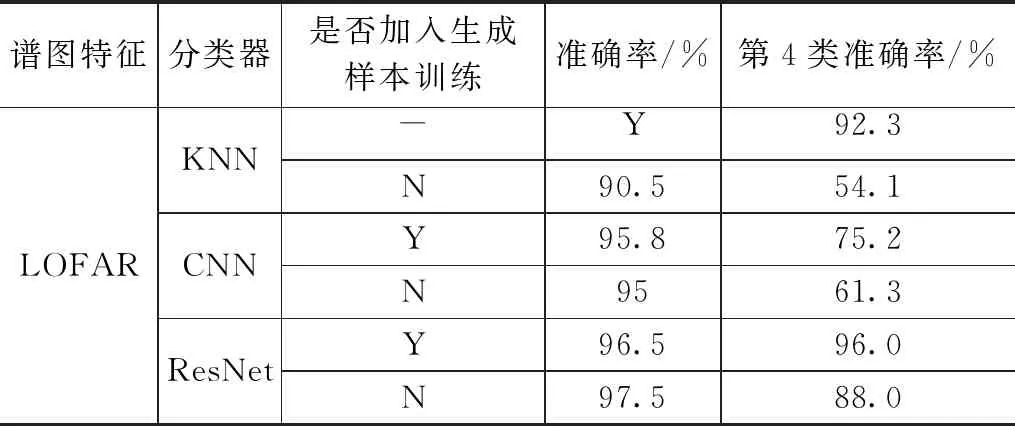
表8 实验二 样本扩充前后分类准确率
经过对比实验可以看出,在不同分类器网络中,使用样本扩充网络对小样本类进行扩充。相较于在原始数据集上最佳准确率96.5%,加入生成样本后,最佳准确率提升到97.5%;针对生成的第4类样本,最佳准确率从88%提升到了96%。
5 结束语
在水声目标识别领域中,样本分布不均衡或有效样本缺失是一种常见问题。为了解决此问题,深度学习领域的研究提出了多种方法,大部分是对模型参数进行配置以实现针对性样本生成。本文提出了一种样本扩充网络,该算法基于CycleGAN网络搭建,通过学习与目标生成水声数据样本相似环境采集的频谱特征和真实分布,生成真实样本,并加入分类器训练中,提升其性能。
本文设计了基于两个不同水声数据集的对比实验,通过3个分类器对扩充网络进行评估。实验表明,扩充网络能加速训练和收敛过程,有效提升分类器的整体性能和对小样本目标类的识别能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
