
基于YOLOv7的交通目标检测算法研究
2024-05-17 11:56:32王沛雪张富春董晨乐
计算机测量与控制 2024年4期
王沛雪,张富春,董晨乐
(延安大学 物理与电子信息学院,陕西 延安 716000)
0 引言
随着经济的发展和社会的进步,自动驾驶技术的研究与发展受到人们的广泛关注[1]。在自动驾驶领域,良好的实时交通目标检测与识别对保障道路环境安全十分重要。道路交通目标检测通常分为4类:车辆检测、行人检测、交通标志检测和其他障碍物检测。如何准确快速地识别前方道路上出现的物体,为规范行车安全、保护公共安全并制定下一步如何避免障碍物的策略,拥有重大的实际意义。
近年来,深度学习的发展带动了基于卷积神经网络(CNN,convolutional neural network)[1]的目标检测算法的迅猛发展,其具有结构简单、检测效果好、速度快等优势,已成为当前目标检测研究的主流方向[2]。目前,基于深度学习的目标检测算法分为两种类型:两阶段模型(Two-stage)和单阶段模型(One-stage)[3]。其中,两阶段模型通过生成目标候选框区域来进行分类和目标定位任务,代表算法以区域建议网络的R-CNN为主,随后发展出Fast R-CNN[4]、Faster R-CNN[5]等算法,检测精度大幅提升,但参数量较大,导致检测速度慢。单阶段模型将目标检测问题变为一个回归问题,不生成指定的候选区域,直接输出分类和定位信息,以YOLO算法和SSD[6]系列算法为代表。相比于两阶段目标检测算法,单阶段目标检测算法在检测精度上虽然有所降低,但在检测速度上得到了一定幅度的提升。尽管近些年来世界各地的专家学者们围绕交通场景中的目标检测算法的研究取得相当大的进步与发展,但从长远的角度来看,现有的目标检测算法并不能满足实际的应用需求,仍有许多问题亟待解决:如存在待检测目标密集且遮挡、由于设备或环境原因造成捕获图像存在分辨率低或模糊以及所捕获照片背景复杂等情况,从而使检测精度和速度难以满足实际需求。
针对交通目标检测领域存在的诸多挑战,文献[7]在基于Tiny-YOLOv3模型的基础上增加卷积层和引入1×1卷积核来增强模型特征提取能力,减少模型计算力,保证了检测实时性,但不适用各种复杂交通场景下的检测任务;文献[8]提出了一种新的多传感器和多级增强卷积网络结构模型MME-YOL,在处理尺度、遮挡和照明等问题中该模型检测效果很好,但模型复杂度较高;文献[9]提出了一种Attention-YOLOv4,在主干网络中将注意力机制与残差块结合,提高复杂背景下目标的检测精度,但低分辨率图像中物体的检测能力不足;文献[10]改进了YOLOv4-Tiny算法,通过暗通道先验理论对图片进行去雾处理,提高了在雨、雾等恶劣环境下小目标识别能力,但模型结构复杂,不易于移动端的部署;文献[11]提出了Faster R-CNN和YOLO的混合模型来进行检测,拥有较高的检测精度,但检测速度慢,训练时间长,无法满足实时性要求。
本文提出了一种改进的基于YOLOv7[12]交通目标检测算法,旨在解决目前关于复杂交通场景下道路交通目标检测算法的问题。本文的主要贡献有以下几点:在原有YOLOv7网络结构上新增加一个浅层网络检测头,提高模型对小目标的检测能力;提出一个新的模块EL-MHSA,将多头注意力机制(MHSA,multi-head self attention)融入主干网络中,增强模型获取全局信息的能力;在颈部网络加入协调注意力(CA,coordinate attention)模块,使模型可以忽略无关信息的干扰,提高模型检测能力;将损失函数改为SIoU,减少损失函数收敛不稳定的问题,提高了网络对于目标尺寸的鲁棒性。实验结果表明,改进的YOLOv7算法在复杂交通目标检测任务中检测精度mAP@0.5和mAP@0.5:0.95分别提升了2.5%和1.4%的同时,检测速度可以达到96.2 FPS,满足复杂交通场景下目标检测的准确性和实时性要求。
1 YOLOv7算法概述
YOLOv7是目前目标检测YOLO系列中比较先进的算法,该网络进一步提高了目标检测的速度与精度。YOLOv7算法相比于其他算法,在5~160 FPS间的速度和精度方面表现得更优秀。
YOLOv7算法采用了许多新的策略,如高效聚合注意力网络(ELAN,efficient layer aggregation network)、基于级联的模型(concatenation-based models)缩放、卷积重参数化等,并在速度和精度之间取得了很好的平衡。YOLOv7网络结构主要由输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和头部(Head)组成,如图1所示。Input模块将输入的图像经数据增强、裁剪、缩放等一系列处理后,将图像统一变为640×640像素,以便能满足主干网络的输入要求。Backbone模块主要由卷积(BConv)、ELAN层和MPConv层这3个部分组成。其中,BConv用于提取不同尺度的图像特征;ELAN模块结构对不同尺度的连接路径进行控制,在预防了由于输入信息和梯度信息在经过多层网络传播后出现信息丢失的同时还提升了网络精度。MPConv模块通过融合当前特征层和卷积处理后的信息的方式,从而提高网络的提取能力。Neck模块中,在颈部中引入路径聚合特征金字塔网络(PAFPN,path aggregation feature pyramid network)结构,加强不同层次间的特征聚合。在Head模块中,YOLOv7利用3种不同大小尺寸的IDetect检测头,经过重参数化输出3个不同尺寸的预测结果。
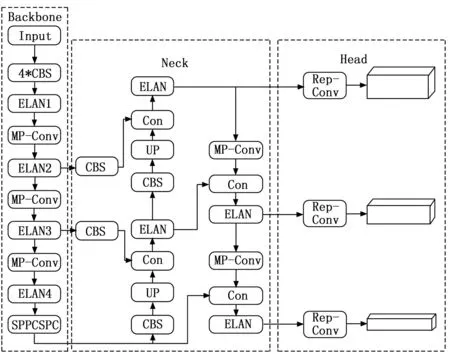
图1 YOLOv7网络结构图

图2 改进后的网络结构图
2 改进的YOLOv7算法
2.1 总体网络结构
为了解决目前交通场景中目标检测由光照、遮挡、目标小以及背景复杂等原因[13]而造成模型检测精度较低,出现漏检和误检现象的问题,本文使用YOLOv7网络进行改进,改进后的网络模型如2所示,其中虚线框起来的部分即改进的模块。
2.2 增加浅层网络检测层
原YOLOv7模型通过8倍、16倍和32倍下采样的方式获取3种不同大小的特征图,其尺寸分别为80×80、40×40、20×20,并将他们输入到特征融合网络中。在特征提取过程中,浅层网络更关注目标的细节信息,例如目标的纹理和边缘特征[14];而深层网络更注重于提取目标的语义信息。由于特征图经过多次卷积和池化后,大部分远景小目标特征信息会丢失,通过原始网络的检测头很难检测到这些信息。
交通道路场景下存在大量小尺度目标和密集遮挡目标,而这些目标特征信息大多存在于网络更浅层,因此需要扩大网络检测尺度范围,检测出更小尺度目标,提高模型的检测性能。本文在YOLOv7模型上通过浅层网络P2增加了一个新的检测头,模型结构如图3所示。该检测头通过主干网络将输入图像经过4倍下采样操作而得到,具有160×160 的分辨率,该特征含有待检测目标更丰富的细节特征信息,可以增强模型对小目标特征的提取能力。尽管添加小目标检测头增加了模型的计算量和内存开销,但是有助于增强微小目标的检测能力。
图3 添加浅层网络检测层结构图
2.3 EL-MHSA模块
由于交通目标检测的图像往往包含着许多复杂背景或者目标之间存在遮挡的问题,其图像经过多次卷积层提取特征后,存在许多非感兴趣区域信息,这些信息会干扰模型对目标的检测,从而影响了检测效果。为了更好地提取交通检测目标的关键信息并弱化无关背景的干扰[15],本文对YOLOv7网络中的ELAN模块进行改进,将多头自注意力机制融入ELAN模块中,如图4所示。具体来说是将ELAN模块中的要使用Cat进行融合的两个3×3卷积改为多头自注意力机制,可以在目标检测中建立长距离依赖关键,而且对于路测图像检测表现出更好的效果,解决了路测图像中因无效信息引起检测效果不佳的问题,能更高效地提取图像特征信息。在特征层间添加全局注意力虽然可以有效增加目标检测的精度,但是也会使模型带来额外的计算量和内存开销,因此本文只在主干网络Backbone中以最低分辨率的ELAN层(即ELAN4模块)进行多头注意力的融合。
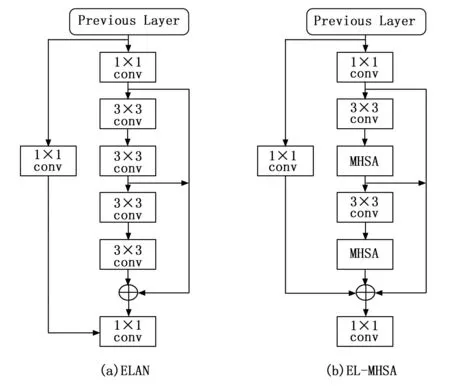
图4 改进的EL-MHSA模块
多头注意力机[16]是一种全局操作,在网络中融入多头注意力机制可以有效地获取特征图中目标周围的上下文信息,增强模型全局信息的关注能力。多头注意力机制的结构如图5所示。MHSA由多个自注意力模块组成,每个Self-Attention模块在不同空间上捕捉全局特征信息。
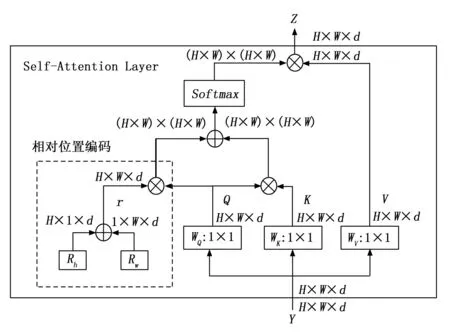
图5 多头注意力机制结构图
Q、K、V分别为 Query、Key、Value 矩阵,1×1 表示逐点卷积,WQ、WK、WV为注意力权重,整个过程中所学习并更新的就是注意力权重,RW和RK分别为像素a到b之间宽、高的相对位置编码信息。使用多头注意力机制可以将特征图的全局信息与CNN卷积的局部信息相结合,从而形成参数量较少且能力更强的特征图[17]。
2.4 协调注意力机制(CA)
由于待检测的交通目标尺寸差异颇大且分布不均匀,使用原网络来检测时会出现漏检误检的情况,因此在网络中引入协调注意这种高效的注意力机制,让模型更加关注自己感兴趣的部分,增强网络对检测目标的提取能力。
CA注意力机制相比较传统的SE注意力机制,它将位置信息嵌入到通道注意力机制中,避免使用2维全局池化造成的位置信息的丢失[18]。CA注意力机制还是一种轻量化的模型,它可以灵活地插入任何的网络,还不会产生大量的计算开销。
CA的结构如图6所示,其中XAvg Pool和YAvg Pool分别表示沿着水平和垂直方向进行一维全局池化,进行各个通道间特征的聚合,使网络结构可以获得更多的感受野。
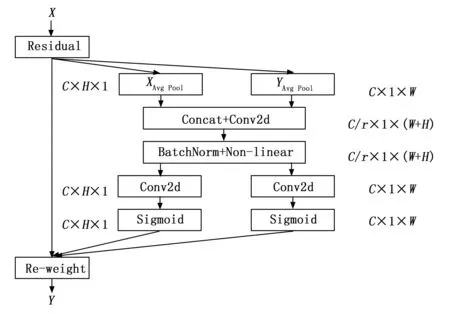
图6 CA注意力机制结构图
此过程可以表示为:
(1)
(2)
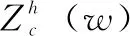
f=δ{F1([zh,zw])}
(3)
其中:[ ,]表示在某一空间维度进行拼接操作。然后将沿着空间维度拆分的两个张量fh和fw,利用1×1卷积、Fh、Fw将其变为具有相同特征的张量,得到结果如下所示:
gh=δ[Fh(fh)]
(4)
gw=δ[Fw(fw)]
(5)
最后,将得到的结果与输入特征图相乘,得到CA输出结果如式(6)所示:
(6)
通过向YOLOv7网络中插入CA模块,可以使模型更加关注自己感兴趣的区域,削弱复杂背景下无关信息的干扰,从而提高模型的检测效果。
2.5 损失函数的改进
YOLOv7网络的损失函数同YOLOv5网络相同,都是由置信度损失、分类损失和坐标损失这3部分组成。YOLOv7网络的坐标损失采用CIoU来计算,是在先前的损失函数的基础上增加了对宽高比之间的考虑,但是并没有考虑预测框和真实框之间的角度和比例,即真实框与预测框之间的方向不匹配的问题。为此,Gevorgyan等人在CIoU的基础上提出了SIoU损失函数算法[19],它不仅聚合了以往损失函数的优点,而且还考虑了真实框与预测框之间的矢量角,并重新定义了损失函数。
简单来说,SIoU损失函数更加全面细致地考虑了目标检测中各个因素的影响,使得模型更加准确地学习目标特征和位置信息,从而提高检测精度。因此,本文采用性能更加高效的SIoU来代替模型的CIoU损失函数,增加了网络损失函数的收敛性,从而提高了模型的精度。SIOU 损失函数由4个Cost函数组成:即角度损失、距离损失、形状损失和IoU损失。
角度损失是指在目标检测任务中,用于度量预测框与真实框之间角度差异的一种损失函数。其计算方式通常采用如余弦距离等方法,通过将角度误差映射为连续值来进行优化。角度损失的引入可以进一步提升目标检测模型对于目标位置和方向的识别能力,提高模型的精度和鲁棒性。角度损失定义为:
(7)
为了进一步提高目标检测模型的精度和可靠性,角度成本计算被引入到距离成本中。重新定义的距离成本不仅考虑了预测框与真实框之间的位置差异,还融合了角度误差的测量,通过同时优化位置和方向的损失函数来学习目标检测任务中的特征表示。这种重新定义的距离成本相对于传统的只考虑位置的距离计算方式,能够更准确地对目标位置和方向进行建模,并在目标尺度和旋转角度变化较大的情况下表现出更好的鲁棒性和泛化能力。角度成本计算被应用为距离成本,为此重新定义距离成本如下:
(8)
距离损耗是目标检测中用于度量预测框和真实框之间距离差异的一种损失函数。它通常采用均方误差、IoU等方式来计算。在距离损耗的优化过程中,除了考虑位置信息,还需要关注目标的尺度和旋转角度等其他关键特征。距离损耗定义为:
(9)
由以上分析可知,在目标检测任务中,综合考虑位置、尺度和旋转角度等关键特征的SIoULoss损失函数公式可以表示为:
(10)
3 实验结果及分析
3.1 实验环境
本文实验环境在Linux系统中运行,利用两块内存为32 G的v100 GPU进行训练,Python版本为3.8,CUDA版本为10.2,深度学习框架为Pytorch1.8.0。
模型训练参数设置:迭代次数epoch=100,batch_size=8,学习率选取0.01,权重衰减系数为0.000 5,动量为0.937,输入图片采用640×640的分辨率,其余均采用默认设置。
3.2 数据集
本文选用由伯克利AI实验室发布的公开交通场景数据集BDD 100 K中的10 K来验证改进的YOLOv7模型在复杂交通情况下的有效性和优越性。该数据集是在6种不同天气、场景和白天、黄昏、夜晚共3种不同时间段的所采集的图[20],且该数据集有Person、Rider、Car、Bus、Truck、Bike、Motor、Traffic light、Traffic sign、Train这10个感兴趣的对象类别,其各类别标签数量如图7所示,该数据集基本上涵盖了交通检测中所出现的所有基本目标。
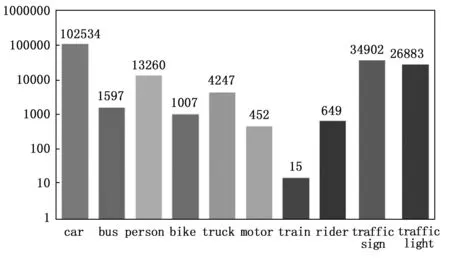
图7 BDD100K数据集各类标签分布图
在本次实验中,本文按照8∶1∶1的比例对数据集进行了划分。其中,训练集包含8 000张图像,验证集包含1 000张图像,测试集包含1 000张图像。这些数据集的使用,旨在评估和改进YOLOv7模型在交通场景下的表现,以期提高交通检测的准确度和效率。
3.3 评价指标
本文的性能评价主要采用以下4个指标:检测精度(AP)、平均检测精度(mAP)、准确率-召回率(P-R)曲线以及检测速度(FPS)。相关指标的计算公式如下所示,旨在综合评估本文提出的基于YOLOv7的交通目标检测模型在不同方面的表现:
(11)
(12)
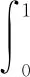
(13)
(14)
式中,TP为模型预测正确的正样本数,Fp为模型误检的正样本数,FN为模型漏检的正样本数。需要注意的是,由于检测结果是基于一定置信度阈值得出的,因此在计算AP时需要对不同置信度下的结果进行平均化处理。具体而言,需要计算多个不同置信度阈值下的AP值,然后求其平均值,得到最终的mAP指标。
3.4 消融实验
为了更好地验证本文所提出的改进模型与方法的有效性,使用BDD00K数据集进行消融实验。不同的改进策略使得模型的结构、检测精度、速度、参数量也进行变化,具体的实验结果如表1所示。

表1 算法在BDD100K数据集上的消融实验结果
模型1为原始的YOLOv7算法的实验结果,将本次结果作为后面几组实验的对比基准,检测的mAP@0.5为57.3%,mAP@0.5∶0.95为31.9%,检测速度是最快的。模型2在原网络结构的基础上引入EL-MHSA模块,使BDD100K数据集mAP@0.5和mAP@0.5∶0.95分别提升了1.4%和0.9%,提升了网络的整体性能。模块3在颈部添加了CA协调注意力,挖掘各个通道间的相互依赖关系,增强对目标特征的提取能力,使mAP@0.5和mAP@0.5∶0.95分别提升了0.6%和0.2%。模块4通过增加一个小目标检测层保留了更多浅层细节信息,使模型的mAP@0.5和mAP@0.5∶0.95分别提升了2.3%和1.0%。模块5将损失函数改为SIoU,mAP@0.5和mAP@0.5∶0.95分别提升了1.6%和0.4%,虽然提升的效果较小,但是在模型收敛方面有着较好的结果。
通过上述实验,发现模块4添加小检测头与模块6整体改进的实验数据相差不大,这是因为将上述所有模块融入网络中后,模型参数量增加,网络结构相比单加模块的方式更为复杂,影响了检测精度。总的来说,每种改进的策略都可以让模型性能有不同程度的提升。将每个模块都融入后的算法与YOLOv7原算法相比,mAP@0.5和mAP@0.5:0.95分别提升2.5%和1.4%,表明该改进算法可以促进网络对交通目标特征的学习,更易避免误检与漏检情况的发生。该算法检测速度为96.2 FPS,比最快的YOLOv7降低了10.2,但是完全可以满足检测实时性的要求。
3.5 改进算法与YOLOv7算法在BDD100K中各个类别的比较
为了验证本文算法模型的优越性,让本文改进算法和YOLOv7算法各项参数指标相同的情况下,将两个算法在BDD100K数据集中训练的各个类别的AP值进行对比,结果如图8所示。从图中明显可以看到本文改进算法的每个类别的平均精度都高于原始算法。其中,car的AP值从80.5%到84.1%,提升了3.6个百分点;bus的AP值从66.4%到68.6%,提高了2.2个百分点;person的AP值从68.2%到71.1%,提高了1.9个百分点;bike的AP值从50.8%到52.9%,提高了2.1个百分点;truck的AP值从67.9%到69.1%,提高了1.2个百分点;motor的AP值从49.1%到53.5%,提高了4.4个百分点;rider的AP值从50.1%到52.4%,提高了2.3个百分点;traffic sign的AP值从73.6%到74.7%,提升了0.9个百分点;traffic light的AP值从68%到71.6%,提升了3.6个百分点;尤其是train目标,由于检测物体标注过于少,原算法没有检测出这个物体,而改进的算法检测出精度为1.8%。从以上数据可以得出,本文改进的算法相比于YOLOv7原算法表现出更为优越的性能,对交通道路场景下检测任务具有更可观的检测效果。
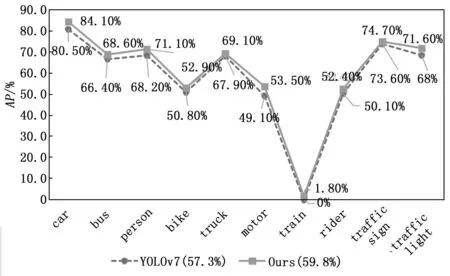
图8 改进算法与YOLOv7算法在BDD100K中10个类别比较
为了更加直观地展示出本文改进算法在真实场景下的效果,在BDD100K数据集的测试集中随机选择了多张不同交通场景下的图片进行对比分析,如图9所示。其中,左侧为本文改进算法的结果图,右侧为YOLOv7算法的结果图。

图9 不同交通场景下模型检测对比结果
图9的(a)组图片检测的是背景比较复杂的场景,右图将车子上面的梯子误检成交通灯,左图并没有出现误检的情况;(b)组图片是在夜间图像像素模糊情况下进行检测的结果,右图将墙的边沿检测成了交通标志,而左图正确地检测出目标;(c)组图片是在黄昏时光照不均匀的情况下的检测结果,明显可以看出,右图由于光线昏暗且树木遮掩,没有识别出车辆,而左图准确地检测出被遮掩的车辆;(d)组图片在目标交叉密集时,左图明显比右图的精度检测高。总的来说,本文改进的算法相对于YOLOv7算法表现出了更好的性能,一定程度上改善了漏检和误检问题,可以更好地适应于交通场景下的检测任务。
3.6 对比试验
3.6.1 本文算法与其他同类改进算法对比试验
本实验将本文改进的算法与其它采用BDD100K公共数据集且应用于交通目标检测的改进算法的性能进行比较,如表2所示。本文改进的算法相比AFFB_YOLOv5s[20]和M-YOLO[21]算法的检测精度分别高了8.3%与3.0%,检测速度分别高了20.3和33.2。可见,本文改进的算法相较于其他改进的算法表现出更为显著的优势,可以更好地解决交通目标检测中出现漏检与误检问题的情况。
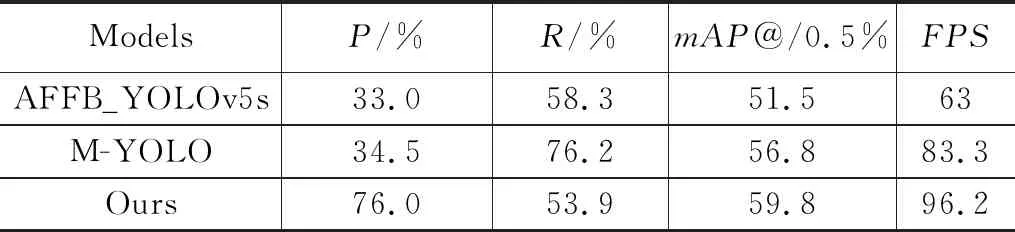
表2 本文算法与同类改进算法对比结果
3.6.2 本文算法与其他主流算法对比实验
本实验将改进的算法与Faster R-CNN、SSD、YOLO-v3[22]、YOLOv4[24]、YOLOv5和YOLOv7算法在同等条件下进行实验对比,实验结果如表3所示。
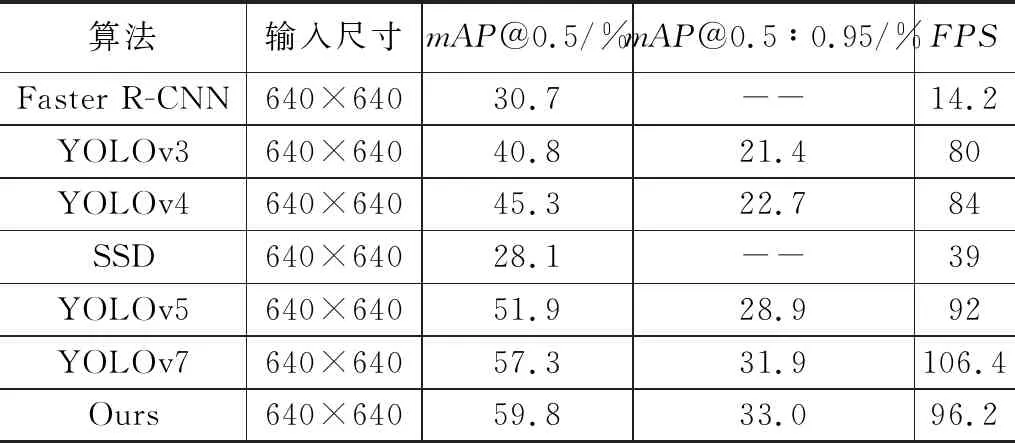
表3 不同算法在BDD100K数据集的性能对比结果
本文通过改进算法,针对现有目标检测算法在实时性和精度之间的权衡问题,提出了一种新的解决方案。实验结果表明,Faster R-CNN算法的mAP@0.5值为30.7%、FPS值为14.2,检测速度太低,无法满足实时性的需求;SSD算法的mAP@0.5值为28.1%、FPS值为39,相比Faster R-CNN,在提高速度方面有提升,但是检测精度下降了2.6个百分点;而YOLOv3、YOLOv44和YOLOv5算法在检测速度上都有很大的提升,但其检测精度仍然存在局限。
相比之下,本文改进算法在速度和精度方面达到了一个良好的平衡。虽然相较于原算法,速度方面有所降低,但96.2 FPS的速度仍然是除原算法之外最优的,完全可以满足实时检测任务的需求。在精度方面,本文算法在mAP@0.5和mAP@0.5∶0.95等多个评价指标上排列第一,明显优于其他主流算法。因此,本文算法可以在实时性和精度之间取得一个更好的平衡,为目标检测任务提供了更加高效和准确的解决方案。
4 结束语
本文在YOLOv7网络的基础上进行改进,并将改进算法应用于交通场景的目标检测中。通过在YOLOv7原网络中融入全局注意力机制,设计一个新的EL-MHSA模块,获取全局结构化信息;通过在颈部网络加入CA协调注意力机制,使其更好地提取细节特征;通过添加一个浅层网络检测头,进一步提取小目标特征信息;通过改变网络损失函数,减轻了模型收敛不稳定问题。在BDD100K数据集上的实验结果表明,该改进算法检测结果优于其它主流目标检测模型,检测精度在达到59.8%mAP的同时,检测速度为96.2 FPS,该算法可以在保证检测速度的同时还可以提高算法精度,在一定程度上减轻了误检和漏检问题,能够有效地完成交通场景下的目标检测任务。但是,由于模型中添加检测头和注意力机制等方法使得模型复杂度上升,参数量变大,检测速度稍有下降,后期可以考虑采用更加高级的特征提取算法和更加先进的目标检测网络结构,以进一步提高模型的检测精度和速度。此外,还可以探索基于深度学习的模型量化和剪枝技术,以减小模型的计算和存储开销,从而提高模型在边缘设备上的应用效果。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年11期)2018-08-04 03:25:38
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
电子设计工程(2015年3期)2015-02-27 12:03:45
