
基于Bert模型对不完整事件日志的多属性修复
2024-05-13 09:39张振虎王丽丽
洛阳师范学院学报 2024年2期
张振虎,王丽丽
(安徽理工大学 数学与大数据学院,安徽 淮南 232001)
0 引言
流程挖掘作为一门新的学科领域,近年来已经得到非常广泛的研究和应用.它包括流程发现、一致性检测和流程增强三个研究方向,并且三者皆可使用事件日志构建过程模型来很好地表示和分析业务流程的执行[1].因此,事件日志是业务流程挖掘的起点,一个完整的事件日志是业务流程正确分析的重要基础.然而,在现实生活中的行业应用中,由于存在不完全可靠的记录行为或者不准确的数据传输,可能会使事件日志出现一定的丢失,产生不完整的事件日志,从而严重影响流程挖掘的结果.因此,修复事件日志对于过程挖掘来说是至关重要的问题.
目前不完整的事件日志大多指事件日志中数据的缺失或者说是数据的质量问题[2],主要的修复事件日志的方法是修复事件日志的缺失值.文献[3]首先提出了一种处理缺失数据的方法,分析了观测数据中数据缺失的原因,定义了缺失值的类型,并进一步提出了利用统计模型解决问题的方法.此后,许多学者针对修复事件日志缺失值做了大量研究.经过不断的研究,人们提出了各种方法,将贝叶斯网络方法、核方法、深度学习方法、对齐方法、随机Petri网等方法相互结合,在修复缺失值方面取得了优异的性能.文献[4]结合随机Petri网方法、对齐方法和贝叶斯网络方法修复事件日志中的缺失值,首先利用对齐方法计算随机Petri网中迹变体的路径概率确定事件日志缺失的事件,然后利用贝叶斯网络方法计算可能插入事件的时间戳以达到修复缺失事件的效果.文献[5]采用与文献[4]同样的方法修复缺失事件,以提高文档的准确性.文献[6]提出了基于迹聚类的方法,利用迹相似性修复缺失迹以得到更完整的流程模型,该方法针对的是迹中缺失的活动.针对事件日志中缺失活动的问题,文献[7]用一种基于LSTM的预测模型来预测事件日志中缺失的活动标签.该模型利用以活动标签缺失的事件的前缀和后缀作为输入,事件日志的附加属性用来提高性能.文献[8]提出了一种结合迹行为特征的神经网络模型,同时考虑日志中活动的时序关系和行为关系,将其转换为图像矩阵,通过卷积神经网络预测迹中缺失的活动.
综上所述,目前的事件日志修复方法主要是针对迹中缺失的活动或时间戳等单一属性进行修复,而未同时针对多个属性的缺失进行修复工作.本文提出了一种结合Bert模型的方法修复事件日志中缺失的多属性.核心思想是利用Bert模型的预训练任务中特殊的遮掩策略学习判断事件中属性是否正确,在微调阶段对缺失值进行预测.在Transformer层中利用多头注意力机制从不同角度学习属性间的依赖关系,根据其上下文信息修复事件中缺失的属性,甚至进行纠错.
本文的主要工作如下.
第一,结合Bert模型从数据流视角对事件日志中的多属性进行修复,而非只针对单一属性,同时具有一定的纠错能力.
第二,使用公开可用的数据集进行仿真实验,对结果进行分析,验证提出的方法的可靠性.
本文的剩余部分组织如下:第1部分介绍了本文方法的相关基础定义以及Bert模型.第2部分详细描述了本文提出的方法.第3部分利用公开可用数据进行仿真实验并对结果进行分析.第4部分总结全文.
1 基本概念
1.1 基础知识
本文使用的一些基础定义,主要包括事件、属性、迹、事件日志、缺失属性、缺失事件、缺失迹、缺失日志等内容.
定义1[1](事件和属性)业务流程中任一事件e是其对应的活动a∈A在某个时刻的执行步骤,每个事件e的执行包含活动名称、资源、时间戳、成本等相关信息,通常被定义为多元组e={caseid,a,timestamp,attr1,2,…,n},其中caseid为e所属流程实例,a为e执行的活动名称,timestamp为e执行的时间戳.以上所述皆被称为事件e的属性,而attr1,2,…,n为e的其他附加属性,如资源、成本等.
定义2[1](迹和事件日志)迹σ是若干事件组成的有序序列,记为σ=〈e1,e2,…,e|σ|〉,其中|σ|为迹σ中事件e的数量.事件日志L是迹σ的集合,记为L=〈σ1,σ2,…,σL〉,其中L为事件日志的长度.
表1为一个事件日志案例.包含三条迹,每条迹包含若干事件,总共15个事件,每个事件包含Trace Id,Activity,Resource,Timestamp等属性.

表1 完整日志案例
定义3(缺失属性和缺失事件)设事件e=〈attr1,attr2,…,attrn〉为迹σ的一个执行事件,若存在attri∈e为空,则称事件e为缺失事件,attri为缺失属性.
定义4(缺失迹和缺失日志)设σ=〈e1,e2,…,e|σ|〉为业务流程中事件日志的一条迹,若存在事件ei∈σ为缺失事件,则称迹σ为缺失迹,而事件日志L=〈σ1,σ2,…,σL〉为缺失日志.
表2为表1的缺失日志,迹1为一条缺失迹,事件e2和e4为缺失事件,其中的Activity和Resource为缺失属性.
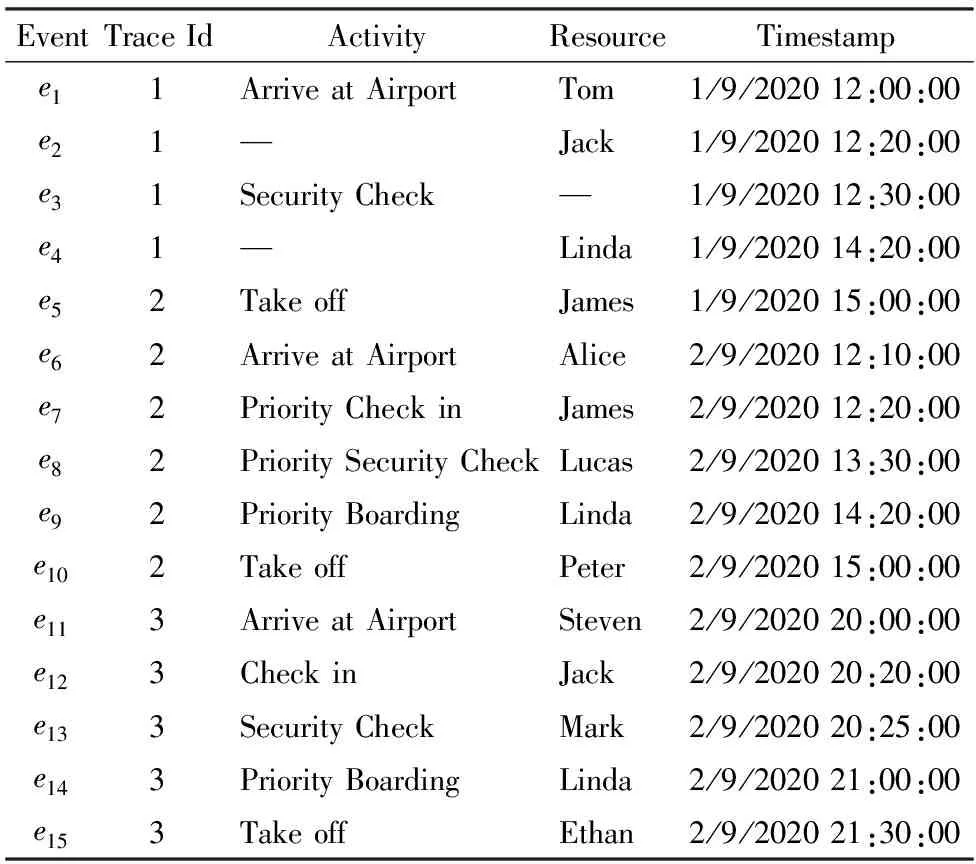
表2 缺失日志案例表
1.2 Bert模型
Bert是一个预训练的表征模型,同时在11个NLP(自然语言处理)领域取得了最先进的成果[9].它改变了传统的采用单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,采用新的双向Transformer语言表征模型.采用新的MLM(Masked Language Model)进行预训练生成包含上下文信息的深度语言模型.
Bert模型的架构如图1所示,词嵌入、分割嵌入和位置嵌入三个嵌入特征的总和构成了Bert模型的输入,Bert的模型架构采用的是双向Transformer编码器(如图2为Transformer编码块的模型架构[10]),多头注意力机制使得Bert能够在不同层次提取关系特征,进而更全面反映句子语义.因此,Bert的表示能力更彻底地捕获了基于所有级别左右上下文的句子中的长期双向依赖关系.
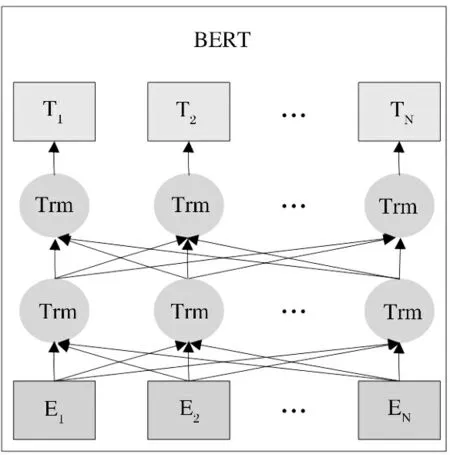
图1 Bert模型架构图
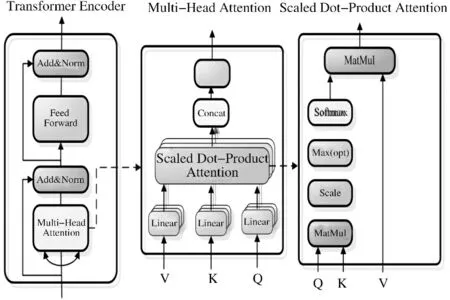
图2 Transformer编码块模型架构图
Bert的本质是采用遮掩策略预训练的一个语言模型,通过自监督的方法学习文本中地通用语义,提取词在不同层次的双向依赖关系.然后通过微调策略转移到预测事件日志中缺失值的下游任务中.
2 不完整日志的多属性修复方法
目前在过程挖掘领域的研究工作已经探索了各种深度学习模型在修复事件日志中的应用,比如LSTM[7]、CNN[8],然而这些方法只是针对活动缺失或者其他单一属性缺失,不能推广到多属性缺失的修复任务当中.此外,由于实际应用中事件日志的复杂性和多样性,在相关系统的执行过程中发生的所有事件,在业务流程的执行过程中不可避免地会造成各种属性的丢失,传统的RNN和LSTM不能很好地捕获属性之间的长期依赖关系,并且存在梯度消失的问题.
本文提出了有一种结合Bert模型的多属性修复方法,图3是多属性修复的整体架构.
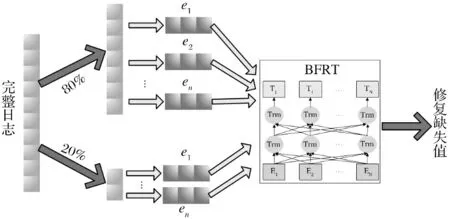
图3 修复缺失值模型架构
在输入模型之前,将一个完整的事件日志的80%作为训练集,用于预训练模型,以事件为单位,使用Bert中的双向Transformer模型捕获属性之间的长期双向依赖关系,并最终训练出广义的深度双向表示模型.剩余的20%作为测试集,用于目标模型,即预测缺失事件的缺失值,从而验证该模型在修复多属性方面的准确性.
Bert模型是一个多任务模型,在预训练阶段包含两个自监督任务,即MLM(Masked Language Model)和NSP(Next Sentence Prediction),本文主要研究通过预训练任务预测事件中缺失属性,从而修复事件日志.
本文针对修复多属性任务制定了预训练任务MAM(Masked Attribute Model),通过属性的三个嵌入特征(即词嵌入、字段嵌入和位置嵌入)和学习属性的语义信息、文本信息和位置信息,在双向Transformer层中利用多头注意力机制捕获属性间的双向语义信息和长期依赖关系.因此,该模型可以在多层上下文中轻松预测出缺失的目标属性.如图4为多头注意力机制模型.

图4 多头注意力模型图
本文制定的MAM采用的预训练策略是传统的80%-10%-10%的掩码([Mask])策略,即在识别出被掩蔽的属性后,被掩蔽的属性80%的可能被直接替换为“[Mask]”;10%的可能被转换为任意属性; 10%的可能会保持不变.
修复事件日志的缺失值是过程挖掘领域的一个重要研究,准确地修复事件日志能够极大地提高业务流程分析的性能.本文采用微调策略,在完成预训练任务MAM后,将Bert模型转移到预测事件日志缺失值模块进行训练.
首先,将预训练阶段的输出输入到全连接层,以捕获在预训练阶段学习到的属性的语义信息及其上下文信息.然后,将得到的输出输送到Softmax层,微调参数的同时利用Softmax激活函数计算出缺失值出现的概率,选取概率最高的属性值修复事件日志.Softmax激活函数公式定义如下:
(1)
在神经网络模型训练的过程中,采用反向传播算法寻找最优可训练参数.此外,采用交叉熵作为损失函数,寻找修复模型中的最优权值和偏差,从而能够准确高效地预测出事件日志的缺失值.
3 实验评估
3.1 与现有方法进行比较
为了评估本文提出的方法的性能,使用准确率作为评估指标.它衡量了成功修复的缺失属性占所有缺失属性的比例.公式(2)定义了修复准确率,其中corrnum为修复成功的属性数量,alldata为所有缺失属性的数量.
(2)
本部分使用韩国一家钢铁公司的数据集进行案例分析,以验证本文提出的方法的有效性.该事件日志包含21 201个事件、2 391个案例、12个活动以及其他5个属性.我们在以5%的间隔随机生成5%到20%的缺失值后,使用所提出的方法进行修复.此外,在本案例研究中,将本文提出的方法与各种现有方法进行比较.
表3和图5显示了本文提出的方法与现有(MICE[11]、EMBI[12]、RFI[13]、KNNI[14]、GDT[15]五种方法在数据挖掘和过程挖掘领域处理缺失数据的方法)的比较结果,显然本文提出的方法无论从事件日志中缺失属性的比例,还是在修复缺失值上相比其他方法都有很大的改善.虽然随着缺失率的提高,修复缺失值的准确率也在逐步降低,但是在修复缺失的多属性方面仍然有着良好的效果,并且在逐渐趋于稳定.
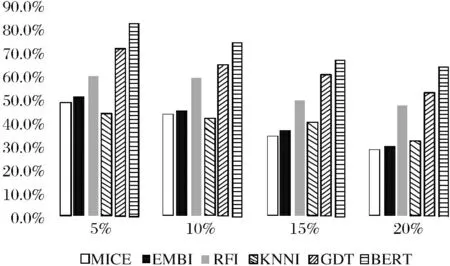
图5 与现有方法比较结果图

表3 与现有方法比较结果
3.2 属性类型数量对修复效果的影响
为了进一步分析本文提出的方法在修复缺失值方面的性能,本部分还对属性类型是否影响修复缺失值的效果进行进一步分析.同样依次随机生成缺失率分别为5%、10%、15%和20%的事件日志.分别对修复5个属性类型和8个属性类型的结果进行比较分析.表4为不同数量属性类型的修复效果.
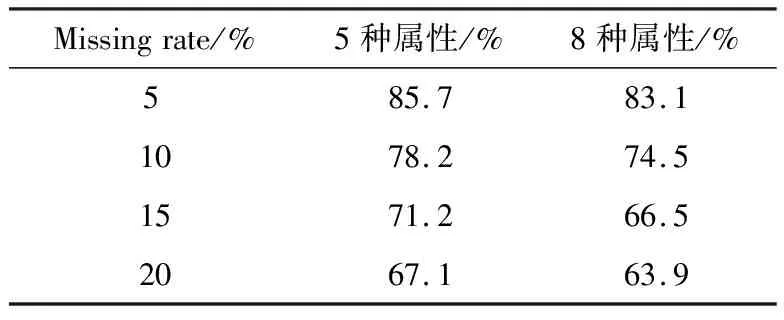
表4 不同属性数量的修复效果
从表4可以看出,修复属性数量的多少对事件日志的修复效果会产生影响,实验结果表明,修复的属性越多,则修复日志的准确率越低.但同样可以发现,在本文提出的模型中,属性种类的增加相对于缺失率的提高修复缺失值的效果影响程度较小,同时,结果表明本文提出的方法在修复事件日志方面有着良好的效果.
4 结论
本文提出了一种修复事件日志中多属性缺失的方法,该方法首先利用嵌入特征学习输入属性的语义信息、文本信息和位置信息.然后利用Bert模型的预训练任务MAM 捕获属性间的双向语义信息和长期依赖关系,训练出深度双向表示模型.最后在微调阶段转移到预测缺失值的模块,对所有参数进行端到端的微调,寻找到符合模型的最优参数,利用激活函数计算并选取出概率最高的缺失值,从而修复事件日志.
与传统的修复事件日志不同的是,本文首次提出利用Bert模型修复多属性缺失,而不仅仅是针对活动、资源、时间戳等单一属性.实验表明该方法有着良好的修复能力.
然而该方法也有一定的局限性,该方法只考虑了从数据视角修复多属性缺失.未来的工作可从行为和数据的视角提高事件之间的依赖性,以达到更好的日志修复的效果.
猜你喜欢
出版人(2022年11期)2022-11-15
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
小学生(看图说画)(2017年6期)2017-11-06
意林原创版(2016年10期)2016-11-25
Coco薇(2016年2期)2016-03-22
通信电源技术(2016年5期)2016-03-22
Coco薇(2015年1期)2015-08-13
电源技术(2015年9期)2015-06-05
小雪花·成长指南(2015年4期)2015-05-19
