
基于门控循环单元-注意力机制模型的股票价格预测
2024-05-13 09:39张庭溢陈香香黄礼钦
洛阳师范学院学报 2024年2期
张庭溢,陈香香,黄礼钦
(福建理工大学 1.管理学院; 2.互联网经贸学院,福建 福州 350118)
0 引言
股市预测是金融和计算机科学交叉领域的经典问题.法玛(Fama)提出了有效市场假说(Efficient Markets Hypothesis,EMH)[1],即在一个有效的股票市场,投资者无法通过技术分析获得超过市场平均水平的超额利润.然而,有效市场假说的有效性依赖于所有参与者都是足够理性的前提,这在现实世界中很难实现.股票市场受到各种因素的影响,如国家政策变化、国内外经济环境、国际形势等,因此,股票价格的变化是非线性的,这使得股票价格的预测成为了一个长期备受关注的问题.如果能准确预测股价的变动,将对投资者的风险规避和收益最大化具有重要帮助.
目前,股价预测的模型主要有线性模型和非线性模型两种.线性模型是早期的预测模型,但由于预测效果不理想,学者们逐渐将非线性模型引入该领域.其中,GRU是长短期记忆网络(Long Short-Term Memory network,LSTM)的一种变体,属于循环神经网络(Recurrent Neural Network,RNN)之一.LSTM的门控机制能够避免RNN模型存在的梯度消失和梯度爆炸问题,适合进行长时间序列预测.相比之下,GRU对LSTM进行了简化.但是,GRU无法捕捉时间特征,而股票价格在不同时刻的重要性是不同的.为了进行更准确的价格预测,我们通过引入注意力机制,给重要的信息更多的关注,抑制不重要的信息.
GRU能够学习到股票价格这一时间序列数据间的特征关系,而AM能够根据其时间特征进行重分配.因此,本文将GRU和AM的优势相结合,建立了GRU-AM模型.该模型旨在学习股票数据的特征并分配这些特征的重要度.为了验证模型的预测效果,我们使用了七种基准模型与本文实验结果进行对比.最终实验结果表明,本文模型对股票价格预测效果具有一定的提升.
1 相关工作
股价预测方法一直是研究的热点.最初,人们使用线性模型如线性回归(Linear Regression,LR)、自回归(Autoregressive,AR)、移动平均(Moving Av-erage,MA)和差分自回归移动平均(Autoregressive Integrated Moving Average model,ARIMA)来进行预测.但由于股票数据存在许多非线性特征,线性模型存在许多局限性,因此开始尝试使用非线性模型,引入了机器学习方法,比如支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)和神经网络(Neural Networks,NN)等[2-3].在神经网络中,循环神经网络RNN是一种含有循环结构的神经网络,其每个时刻的输入不仅包含当前时刻的输入数据,还包括当前时刻的隐藏层状态数据.这些隐藏层状态具有记忆模块的功能,能够保存历史信息并随着新数据的输入不断更新.RNN的记忆能力可以将过去的信息运用到当前的预测任务上,有效地解决时间序列的长期依赖问题[4].因此,使用RNN相关方法尤其是LSTM和GRU进行金融市场时间序列预测逐渐成为热门课题[5].
GRU作为RNN模型的一种类型,许多研究者对使用GRU进行股票价格预测进行了探究.左勒盖尔奈英(Zulqarnain)等将CNN和GRU相结合来预测股票价格,通过CNN层学习金融时间序列预测股价特征,并直接传递到GRU层以捕获股价长期特征,验证了GRU模型在股价预测任务中表现更好[6].李潇俊等引入技术面和基本面分析并将LSTM和GRU方法相结合构建股价预测模型,提高了模型在长期预测上的预测精度[7].张倩玉等引入自适应噪声的完整集成经验模态分解(CEEMDAN)算法提取股票价格时间序列在时间尺度上的特征,利用注意力机制捕获输入特征参数的权重并结合门控循环单元(GRU)网络进行股票价格预测[8].实验结果表明与RNN、LSTM等模型相比,所提模型能有效减少预测误差,提高模型拟合能力.
近年来,诸多研究者将注意力机制和神经网络相关模型相结合来预测股票价格.陆文杰等提出一种CNN-BiLSTM-AM模型,AM用于捕捉特征状态对过去不同时间股票收盘价的影响,以提高预测准确性[9].李成宇等利用 GRU、LSTM和多头注意力 (multi-head attention,MHA)Transformer开发了一种用于价格预测的新型混合神经网络[10],能够捕捉到从过去到当前每个时间步的不同权重的影响,从而实现准确预测.并将结果与其他先进方法获得的结果进行比较,比较表明该模型提供了有效的价格预测.此外,还进行了消融研究,以验证所提出模型中每个组件的重要性和必要性.刘翀等使用深度LSTM网络对金融数据进行建模,解决了数据间长依赖的问题,引入了注意力机制,使得不同时间的数据对预测的重要程度不同,预测更加精准[11].景楠等提出CNN-LSTM模型用于预测铜期货价格序列,并将LSTM与AM相结合以提高预测性能[12].最终证明了注意力机制对CNN-LSTM模型的预测准确性有所帮助.
邹婕等构建了RF-SA-GRU混合模型,该模型使用自注意力机制加强对重要因子的关注和因子内部的联系.实验表明RF-SA-GRU模型在18只股票上均取得较好的预测效果,且预测精度和稳定性均优于其他模型[13].
2 基于GRU-AM的股票价格预测模型
在处理股票价格这类时间序列数据时,前馈神经网络并不能很好地处理与历史数据的关系.因为股票价格不仅与当前时刻的输入相关,还与之前的输入(即历史状态)有关.因此,RNN可能更适合处理这类数据.此外,不同时间的特征对股票价格的影响程度是不同的.通过引入注意力机制,可以为这些特征分配不同的权重,从而更准确地预测股票价格.本文选择GRU-AM方法进行研究,以探讨如何更好地利用历史数据和当前数据来提高预测精度.
2.1 GRU模型
2.1.1 GRU模型原理
秋(Cho)等在2014年首次提出了GRU[14].GRU在LSTM的基础上进行了简化,只保留了两个门,即重置门和更新门.GRU单元的内部结构如图1所示.
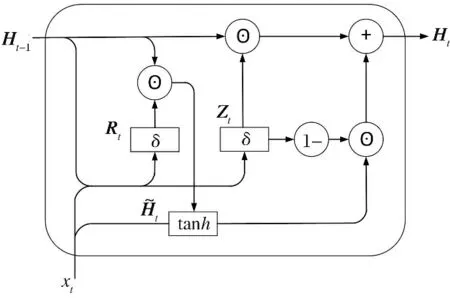
图1 GRU单元结构图
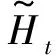
(1)

2.1.2 GRU模型构建
本文构建的模型采用单层GRU层,初始时隐藏层信息被设置为0.模型的输入数据是三维张量,其形状为[b,s,f].其中,b代表批次尺寸,即一次输入的序列数量;s是设置的输入序列长度,即后续提到的滑动窗口长度;f为输入序列包含的特征数量.本文选取了5个特征:最高价、最低价、收盘价、开盘价和交易量,因此f=5.模型的输出为二维张量,其形状为[b,1],即通过输入序列对未来时刻的收盘价进行预测.
2.2 AM模型
2.2.1 AM模型原理
早在1980年,特雷斯曼(Treisman)和盖雷德(Gelade)就已经提出了注意力机制[15].2014年,弗拉基米尔(Volodymyr)等将RNN与AM相结合,并成功地应用于图像分类中[16].AM的本质是资源分配过程,主要分为三个阶段:权值计算阶段(计算资源分配的系数)、权值缩放阶段和用权值计算最终值阶段(进行资源分配).AM的计算过程如图2所示.其中,Query(Q)和key(K)表示输入的值,用Q和通过函数F()计算相似度,通过第二阶段归一化[使用softmax()函数]计算出AM的权值,最后是第三阶段将ai和vi进行加权求和得到最终值

图2 AM计算过程
Attention value.AM的三个阶段公式分别如下:
(2)
2.2.2 AM模型构建
AM可以分为三类,分别是硬注意力、软注意力和自注意力,本文的AM方法使用的是注意力.具体地说,输入数据经过GRU层其输出为O=[o1,o2,…,on],和隐藏层为H=[h1,h2,…,hn],O作为Key以及H作为Query传入AM层进行三个阶段的计算.其中第一阶段为计算AM层的权值,本文中,权值是通过点积的方式直接计算得出的.GRU层的输出O实际上是所有时刻的隐状态数据,隐藏层H则是最后一个时刻的隐状态数据,即H=on,所以公式(2)中第一个公式的点积计算可以算出最后时刻隐藏层状态数据和每一时刻隐藏层状态数据的相似度; 公式(2)中第二个公式是对第一阶段得出的权值进行归一化处理; 公式(2)中第三个公式是第三阶段加权求和(其中vi=oi),计算出的值就是根据其时间特征完成重分配的预测值.
2.3 GRU-AM模型
基于上述方法,本文建立了使用GRU方法预测后输入AM进行重分配的股票价格预测模型,即GRU-AM模型.这个模型是以序贯模型为基础设计的,它由GRU层和AM层叠加构成,并最终通过一层全连接层实现输出.在AM层中,O和H均来自GRU层的输出数据,而Query则采用GRU层的隐藏层数据.模型的详细结构如图3所示.

图3 GRU-AM模型结构图
3 实验
为了评估GRU-AM模型的性能,我们首先对数据进行了预处理,随后将本文模型与多种基准模型进行了对比.接着,我们采用了四种评估指标来评估模型的预测结果.值得注意的是,本文的代码是基于Python语言和PyTorch框架编写实现的.
3.1 实验设置
实验设置涵盖了数据处理、GRU-AM模型的训练与预测过程、对比模型的选择以及评估指标的确定这四个关键方面.
本实验数据是从Baostack网站提供的接口获取的,包含了沪深300成分股之一的浦发银行s的股票日频数据.数据的起始时间为2001年1月1日,结束时间为2022年10月31日,总共有5 291条数据.
在获取数据之后,我们首先进行了数据预处理过程.本实验收集的数据属性包括股票的最高价、最低价、收盘价、开盘价和交易量这5个维度.因此,第一步,删除下载下来的数据中不需要的信息.
第二步,考虑到价格之间的波动比率较小,并且交易量和价格的数值差异较大,如果直接进行预测,模型可能无法识别.因此,我们对数据按维度进行了标准化处理.标准化处理公式如下:
(3)
经过数据预处理后的数据如表1所示.

表1 参数调整表
在完成标准化处理后,需要设置序列(即模型的输入数据)以及序列对应的标签,这个标签用于对模型结果进行检验.本实验采用滑动窗口的方式设置序列和标签.假设滑动窗口长度为s,步长为p.这意味着序列是股票五个特征维度s天的值,而标签是收盘价未来第p天的值.具体来说,第0到第s条数据构成一个序列,第(s+p)条数据是这个序列的标签; 第1到第(s+1)条数据构成第二个序列,第(s+1+p)条数据是第二个序列的标签,以此类推.最终生成的序列形状为(5189-s-p+1,s,5),标签形状为(5189-s-p+1,1).数据滑动窗口图如图4所示.

图4 数据滑动窗口图(黑框为输入序列,黄框为标签)
为了评估算法的性能,我们将数据集划分为训练集和测试集.具体而言,前70%的数据被划分为训练集,用于训练模型参数; 而后30%的数据则被划分为测试集,用于验证模型的性能.设训练集的大小为t1,测试集的大小为t2.其具体的计算公式如下:
t1=t*0.7,
t2=t-t1.
(4)
其中,t为数据集总长度,为向下取整.
最后,还需要分别将训练集和测试集划分批次,训练集批次数量b1和测试集批次数量b2计算公式如下:
(5)
其中,b为每一个批次的尺寸,为向上取整.
3.2 GRU-AM训练与预测过程
经过数据处理后,我们将训练集按批次作为输入数据依次输入到模型中进行训练.模型的输出目标是对应序列未来第p天的收盘价的预测值.我们将这些预测值与实际值通过损失函数来计算损失.在本文中,我们采用的是均方误差(MSE)作为损失函数.优化器算法我们选择的是自适应动量随机优化算法(Adam),通过优化器进行梯度下降来更新模型参数,从而实现迭代训练.通过训练过程,我们能够训练出合适的模型参数.接下来,我们将测试集数据输入到训练好的模型中,模型的输出值会进行反归一化处理.不同的模型会输出不同的预测值,我们将这些预测值分别与测试集的标签通过评估指标来计算评估结果,用以对比各个模型的优劣程度.具体的过程如图5所示.
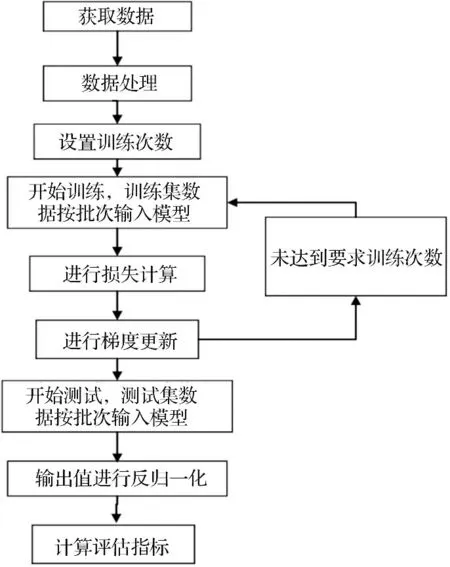
图5 训练与测试过程图
3.3 对比模型
本文共选取了7种基准模型进行对比实验.首先,为了检验混合模型的效果,我们引入了4种单一模型,分别是GRU、双向门控循环单元(Bi-directional Gate Recurrent Unit,BiGRU)、LSTM和BiLSTM.在这些模型中,GRU和LSTM都采用了门控机制,但GRU将LSTM中的遗忘门、输入门和输出门简化为重置门和更新门,因此GRU的运行速度通常更快,效率也更高.不过,从效果上来看,两者各有优势,具体选择需要根据实际情况来决定.而BiGRU和BiLSTM则是在GRU和LSTM的基础上增加了一层从后往前的隐藏层,这样的双向模型能够对同一个输入序列分别进行正向和反向计算,再将每个时刻计算出的两层隐含层共同连接到输出层.通过这4个单一模型之间的对比,我们可以验证本文模型选择GRU层的合理性.其次,我们将这4个单一模型分别与AM层结合,形成了本文的GRU-AM模型以及另外三种基准模型:BiGRU-AM、LSTM-AM和BiLSTM-AM.通过这4个混合模型之间的对比,我们可以验证本文模型的有效性.同时,将单一模型和对应的混合模型的效果进行对比,可以进一步验证单一模型结合AM层后的性能提升.
综上所述,本文共设置了7种基准模型,包括BiGRU-AM、LSTM-AM、BiLSTM-AM、GRU、BiGRU、LSTM和BiLSTM.这些模型将为我们提供全面的比较和分析基础.
3.4 评估指标

(6)
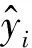
4 结果与讨论
本节通过四个实验来全面阐述本文算法的性能.首先,我们对参数设置进行了详细的讨论.接着,我们将AM-GRU与单一模型进行了性能对比,以突显其优势.为了进一步验证本文模型的合理性,我们还将其与三个混合模型进行了对比分析.最后,我们进行了模型的稳健性分析,具体使用了光大银行和民生银行的数据来测试本文模型在不同数据集下的预测效果.
4.1 参数讨论
本节主要探讨GRU层的宽度h以及训练次数epoch的设定,通过多次实验来确定最佳参数值.通常来说,h的大小决定了GRU层中隐藏单元的数量,进而影响模型的拟合效果.较大的h值虽然可以提高拟合效果,但也可能导致过拟合现象的出现.因此,需要通过实验不断调整,找到最合适的h值.同时,训练次数epoch的选择也至关重要.太少的训练次数可能导致模型欠拟合,而太多的训练次数则可能引发过拟合.此外,本文还对比了在输出层前添加RELU层与不添加RELU层的情况,具体的评价指标和预测结果如表1所示.经过反复实验,我们发现当使用RELU层,并将h设定为32,epoch设定为800时,模型的MSE达到最小,R2达到最高,即模型表现最佳.
他参数设定为:GRU隐藏层数量layers=1,学习率lr=0.001,窗口滑动长度s=10,步长p=1,批次尺寸b=20,训练集划分比例设为0.7.使用经过调整的参数(h=32,epoch=800)进行模型的训练和预测.训练过程中训练集的损失变化如图6所示.

图6 GRU-AM训练过程损失图
4.2 单一模型预测效果
本小节将本文的GRU-AM模型与基准模型GRU、LSTM及其双向变体BiGRU、BiLSTM进行了实验对比.
评估结果如表2所示.从表中可以看出,本文模型的MSE最小,最接近0,同时R2最大,最接近1.其次是BiGRU、LSTM、GRU和BiLSTM模型.与GRU-AM模型的实验结果相比,GRU模型的MSE增加了约0.011,增长了约28.81%; 而RMSE和MAE则有所减少,分别减少了约0.030 6和0.029 4,减少比例分别为15.62%和22.51%.此外,R2提升了约0.001 5,提升了约0.15%.由此可见,加入AM模型后,预测的准确性和稳定性均得到了一定的提升.

表2 单一模型预测评估结果表
4.3 混合模型预测效果
为了验证本文模型选择GRU和AM结合的合理性,本节选择了LSTM-AM、BiLSTM-AM和U-AM这种混合模型作为基准模型.
使用评估指标对混合模型的预测值和实际值进行比较,结果如表3所示.将表3与表2中没有添加注意力机制的对应模型进行比较,可以发现GRU、BiGRU和BiLSTM在与注意力机制结合后,性能都有不同程度的提升.
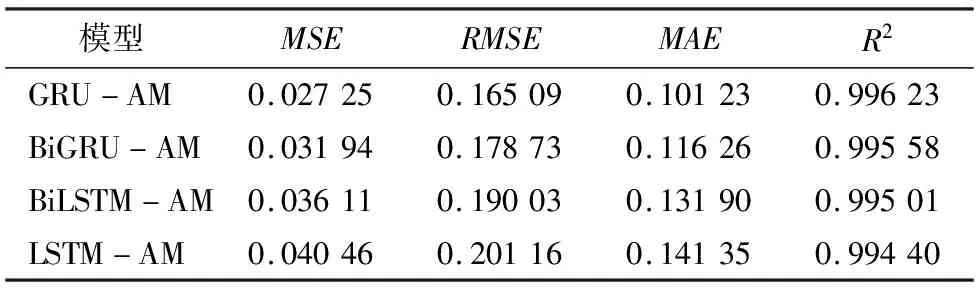
表3 混合模型预测评估结果表
4.4 模型稳健性分析
为了进一步验证模型的稳健性,本文选取了沪深300指数和上证50指数自2002年11月1日至2022年10月31日共计4 857条数据作为研究样本,数据处理过程与上文保持一致.表4展示了沪深300指数和上证50指数数据在本文模型以及7种基准模型下的预测评估结果对比.通过对比分析,可以明显看出本文模型表现最佳.

表4 沪深300指数和上证50指数模型预测评估结果表
5 结论
本文提出了一种GRU-AM模型,旨在提高股票价格预测的准确性.鉴于股票价格数据具有显著的时间特征,我们引入了注意力机制来学习股票价格序列数据的时间依赖性.通过与7种基准模型的对比实验,验证了本文模型的有效性,结果显示在准确性和稳定性方面均有显著提升.然而,本文仍存在一些局限性.首先,在数据方面有待改进,由于股票数据通常包含较高的噪声,因此计划对股票数据进行降噪预处理,以期进一步提高模型的预测准确性.其次,模型方面也有改进的空间,例如对注意力机制进行更深入的研究和优化.最后,训练过程也需要进一步优化,我们打算采用早停法来避免过拟合问题,但相关参数设置仍需进一步研究确定.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
四川工商学院学术新视野(2021年3期)2021-11-05
传媒评论(2017年3期)2017-06-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
第二课堂(课外活动版)(2016年2期)2016-10-21
管理现代化(2016年5期)2016-01-23
中国林业经济(2015年2期)2015-02-28
