
心肺音分离方法研究进展
2024-05-13 07:05孙文慧陈扶明张乙鹏李川涛李楠
中国医疗设备 2024年3期
孙文慧,陈扶明,张乙鹏,李川涛,李楠
1. 中国人民解放军联勤保障部队第940医院 医疗保障中心,甘肃 兰州 730050;2. 甘肃中医药大学 信息工程学院,甘肃 兰州 730000;3. 海军军医大学 海军医学中心 航空生理心理训练队,上海 200433
引言
近些年,心血管疾病和呼吸系统疾病患者数量逐渐增加,心血管疾病和呼吸系统疾病严重威胁到了人类的生命健康安全[1-4]。世界卫生组织发布的《2018 世界卫生统计报告》统计,心脑血管疾病排在非传染性疾病的首位(占所有非传染性疾病的44%),死亡人数高达1790 万,是癌症死亡病例的2 倍[5]。根据世界卫生组织的数据,慢性阻塞性肺病是全球第三大死因,2019 年造成323 万人死亡[6]。医生对于病情的正确诊断是保证患者恢复健康的先决条件,而对听诊器所采集的心肺音信号进行分析有助于诊断心血管疾病和呼吸系统疾病[7-10]。医务人员诊断心血管疾病和呼吸系统疾病最简单的检测方法是听诊[11],即在患者胸部使用听诊器获取心肺音信号以判断心肺系统健康与否。但传统听诊器有一定的缺点,如不能无线传输数据、不能存储回放数据、抗环境干扰能力差等[12],制约了传统听诊器在远程医疗、移动医疗等领域的进一步应用。因此,使用具有分析、存储、传输功能的电子听诊器进行智能听诊在传染病盛行的环境下显得更为重要[13]。
正常情况下,心音信号的频率范围为20~150 Hz[14],肺音信号的频率范围为50~2500 Hz[15]。不难看出,心音信号和肺音信号存在频率混叠区间,心音信号和肺音信号之间互相干扰,导致听诊和诊断效果大大降低。而医务人员使用听诊器进行听诊时,听诊器与衣服摩擦的噪音、外界环境和仪器运转的噪声都会和心肺音一起被采集到电子听诊器中[16-17]。同时,听诊器所采集的信号通常是心音信号和肺音信号的混合信号,无法采集到干净的心音信号和肺音信号[18]。为了对病情进行正确诊断,实现心肺音分离是智能听诊中极其重要的步骤。图1为心肺音混合信号,从图上可以看出心音和肺音之间存在大量混叠区间,使用心肺音分离算法可以将混合心肺音信号分离为图2 所示的心音信号和图3 所示的肺音信号。因此,对心肺音进行分离对辅助医疗具有极其重要的意义。本文综述了心肺音分离方法的相关文献,总结了近些年心肺音分离技术的研究现状,对心肺音分离方法进行了梳理。
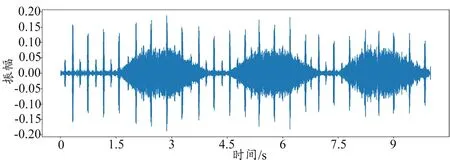
图1 心肺音混合信号
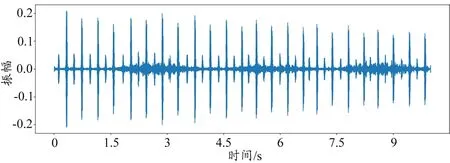
图2 心音信号

图3 肺音信号
1 心肺音信号
1.1 心音信号
心音指由心肌收缩、心脏瓣膜关闭和血液撞击心室壁、大动脉壁进而产生振动所引发的声音,可在胸壁一定部位使用听诊器采集[19]。正常心音波形图如图4 所示,该心音信号取自心音分类竞赛数据集[20]。正常情况下,心音频率范围为20~150 Hz,当心脏出现病变而异常工作时,心音频率甚至会超过1400 Hz。
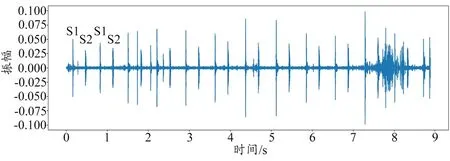
图4 心音波形图
第一心音(S1)、第二心音(S2)、第三心音(S3)以及第四心音(S4)是心音信号的主要分段,心音不同分段频率各不相同。S1 与S2 的频率范围为20~150 Hz,较易被听见。S3 和S4 频率较弱,范围为10~50 Hz[21],不易被听见。S1 发生在心脏收缩期,其音调低、时限长,在心脏尖部较响。S2发生在心脏舒张期,S2较S1音调高、时限短,在心脏底部较响。S3 发生在S2 后0.1~0.2 s,频率和幅度低,所以通常仅在儿童心音中能听到S3。同样,S4 幅值较低[22],一般不易听到。此外,一些心脏疾病还会产生心杂音和额外心音。
1.2 肺音信号
肺音也称作呼吸音,呼吸过程中空气流动时会产生肺音[23]。肺音频率范围为50~2500 Hz,为非平稳周期信号。正常肺音波形图如图5 所示,该肺音取自ICBHI 2017 挑战赛肺音数据库[24]。
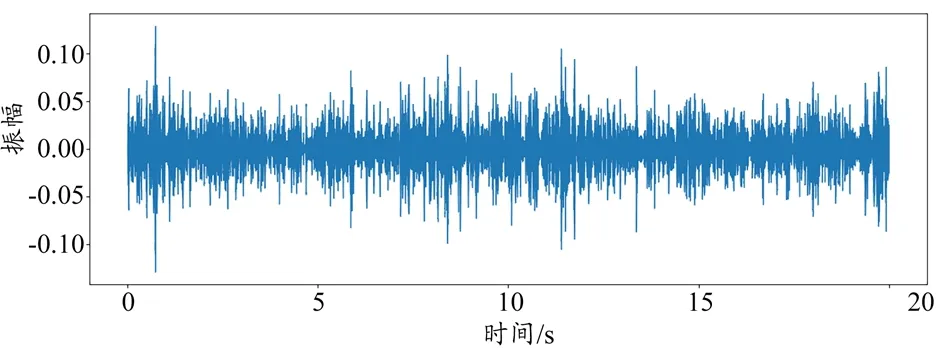
图5 肺音波形图
肺音分为正常肺音与异常肺音,当肺部健康时,可以用听诊器听到肺泡呼吸音、支气管呼吸音和气管音。当肺部异常时,可以听到连续或非连续附加音,如哮鸣音、喘鸣音、罗音和嘎音等。异常肺音按肺音频率、持续时间、开始偏移宽度等物理特性划分,可分为以喘鸣音为特征的连续性肺音和以爆裂音为特征的断续性肺音[25]。不同的异常肺音可以诊断不同的肺部疾病,如哮鸣音可用于检测哮喘病[26]、爆裂音可用于检测肺炎和肺纤维化疾病[27]等。
2 心肺音分离研究现状
近些年心肺音分离研究已经成为医学领域的热点话题,研究心肺音分离算法的国内外研究团队逐年增加。目前国内外针对心肺音分离研究主要有以下几种方法。
2.1 基于小波变换方法
近些年,心肺音分离研究中小波变换主要用来对心肺音信号进行降噪处理和特征提取。2018 年, Mondal 团队提出了一种将小波变换与其他方法结合的算法[28]。该算法在小波包变换基础上与奇异值分解(Singular Value Decomposition,SVD)进行组合对心音去噪。SVD 算法通过对选中的小波树中信息量最大的节点所对应的系数进行处理,进而对心音的噪声分量进行抑制。实验结果证明,该方法的心音去噪效果优于其他基于小波变换的方法。同年,Emmanouilidou 团队提出了一种利用小波多尺度分解方法的噪声抑制技术。该方法将心音作为噪声进行抑制,先使用4 阶巴特沃兹滤波器在[50,250] Hz 对原始肺音信号进行带通滤波,并将其下采样至1 kHz 以增强心音成分。该算法在真实临床条件下采集的患者数据集上进行了进一步验证,效果良好[29]。计算量小、计算速度快是小波变换方法的优点,因此常用于对信号进行降噪处理。自适应性差、对干扰因子抑制效果差是小波变换方法的缺点。
2.2 基于经验模态分解方法
基于经验模态分解(Empirical Mode Decomposition,EMD)是一种非平稳信号的非线性分解方法,是一种自适应分解方法,由于直接从信号中提取信息,因此无须使用内核或母波形。其时频分辨率随输入信号特征变化而变化,该方法在心肺音分离领域取得了一定的成果。2016 年,重庆大学的雍希团队提出一种EMD 与其他算法相结合的算法来对心音信号进行降噪和特征提取[30]。该算法将EMD 与SVD 相结合,利用EMD 获得固有模态函数分量,再对其进一步分解,然后筛选和重构之前工作中得到的特征信号,最后重构出纯净的心音信号。自适应强是EMD 的一大优势。EMD 算法的模态混叠问题是该算法的缺点,因此将其应用于心肺音分离上会存在一定误差。
2.3 基于信号周期性方法
由于心音信号具有周期特性,许多学者利用心音信号和肺音信号的周期特性来进行心肺音分离。2015 年,武伟宁团队提出一种周期提取算法用于信号分段[31],该方法不用识别心音的基本成分,首先对心音使用小波变换去噪,然后对去噪后的心音使用快速Hilbert 变换进行包络提取,心动周期由自相关分析函数获得,进而根据获得的心动周期从原始信号中提取整周期信号。同年,李婷[32]提出一种对心音信号进行处理的算法。该算法基于循环平稳信号理论,根据在心音信号提取出的瞬时相位来估计心动周期。因为心音信号的循环频率明显区别于肺音信号的循环频率,因此根据二者的差异可以对心音信号和肺音信号进行有效分离。利用心音准周期性分析处理心音信号,确定周期开始的位置非常关键,因此基于信号周期性的方法受到了很大限制。
2.4 基于非负矩阵分解方法
考虑到心肺音信号的稀疏性,越来越多研究人员采用基于非负矩阵分解(Non-negative Matrix Factorization,NMF)的方法对心肺音进行分离。2017 年,Canadas-Quesada 提出了一种从心音和肺音混合物中提取心音的NMF 方法[33],提出了由聚类原理驱动的3 个方法:其中两个聚类基于频谱内容,一个基于时间内容以区分心音和肺音。第一个频谱聚类算法对由NMF 方法分解的基向量和由心音训练数据库所创建的字典的基向量进行频谱相似性的评估与测量。第二个频谱聚类算法对由NMF 提供的基向量的频率分布特性进行研究。评估表明,所提方法取得了良好的结果,优于最近的NMF 方法和基于NMF 的最新方法。2021 年,Grooby 团队提出了一种新的基于非负矩阵共因子分解的方法[34]。这种方法通过训练20 个高质量的心肺声音来实现,同时分离嘈杂录音的声音。该方法在包含心音和肺音的68 个10 s 嘈杂录音上进行了测试,并与当前最先进的NMF 方法进行了比较。结果显示,与现有方法相比,心肺音质量分别显著提高,心跳和呼吸频率估计的准确性分别提高了3.6 bpm 和1.2 bpm。2023 年,Wang 团队提出了一种基于NMF 和深度学习的无监督单通道盲源分离算法[35]。该算法首先利用多约束NMF算法和K 均值及支持向量机聚类方法对心音信号进行提取,并使用卷积神经网络对不同类型的心音信号进行分类;最后,利用嵌入空间质心网络来分离混合心肺音信号。基于NMF 的优点是可以对单通道的心肺混合信号进行无监督分离,NMF 的另一个优点是只需要单通道作为输入信号,而不是其他盲源分离方法通常需要的多通道;缺点是在分离时域和频域混叠严重的心肺音信号时效果不太理想。
2.5 基于独立分量分析方法
近些年,独立分量分析(Independent Component Analysis,ICA)广泛应用于数据分析和信号处理领域。由于心音信号和肺音信号的短时平稳性,2010 年,王春华提出一种基于ICA 的方法用于心肺音分离[36],该算法结合了快速不动点算法和信息极大准则算法,可使用该算法对混合信号进行盲源分离。2013 年,Ayari 团队提出了ICA 子算法与其他算法相结合的算法。该算法使用快速ICA 算法与自适应滤波算法对心肺音混合信号中的心音成分进行滤除[37]。对该算法进行实验得到了很高的精度。使用ICA 算法的一个重要前提是获取的信号是多通道的,因此单通道信号的处理受到了限制。
2.6 基于深度学习方法
深度学习算法由于挖掘非线性映射关系和特征提取的优秀能力受到许多研究团队的青睐。深度学习方法在处理语音信号和图像方面的效果远超其他方法。近些年,越来越多研究人员使用深度学习分离心肺音信号。2017 年,Nersisson 等[38]提出一种基于最小均方(Least Mean Square,LMS)算法的改进自适应噪声消除技术对心肺音进行分离。LMS 算法中的步长参数使用混合Nelder-Mead(NM)优化算法进行最佳选择。NM 算法通过使用随机搜索来计算全局最小值的估计值,从而使用良好的初始解进行初始化。使用良好的初始化NM 算法避免了收敛到浅局部最小值,提高了最终解的质量。实验结果表明,该方法心肺音分离效果优于其他方法。2018 年,Al-Naggar 团队研究了一种基于归一化尾均方算法的改进自适应噪声消除方法[39]。同年,雷志彬等[40]提出一种基于全连接长短期记忆(Long Short Term Memory,LSTM)的心肺音分离方法,该方法将LSTM 网络用于实现心肺音信号分离,实验结果显示,基于全连接LSTM 方法效果优于基于NMF 的方法。2020 年,陈骏霖团队比较了3 种循环神经网络的变体和2 种时频掩码组合的心肺音分离方法[41],实验结果显示,基于双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)的算法分离心肺音效果最好。与其他3种方法相比,基于BiGRU 算法分离的心音的信噪比分别提高了1.44 dB,0.58 dB 和0.27 dB。2020 年,Tsai 团队提出了一种周期性编码深度自动编码器算法[42],该方法对心音信号和肺音信号的不同周期进行假设,使用无监督的方式对混合心肺音进行分离。周期性编码深度自动编码器算法使用深度学习模型提取心音和肺音的代表性特征,并考虑心肺声音的周期性应用调制频率分析来执行分离。2022 年,林家荣团队提出一种基于知识蒸馏的算法[43]。该模型使用BiGRU 作为算法的基本框架,然后将知识蒸馏方法应用于该模型上,简化了模型,旦更加简便。2023 年,Yang 等[44]利用深度自编码器的数据驱动特征学习优势和常见的准环稳态特性进行单信道分离。与目前大多数仅处理短时傅里叶变换频谱幅值的分离方法不同,该方法构建了一种具有深度自编码器结构的复值U-net,以充分利用幅值和相位信息。作为心肺音的共同特征,心脏音的准循环平稳性参与了训练的损失函数。对数据进行特征提取是神经网络的优势,近几年,利用深度学习方法进行心肺音分离掀起了一股热潮并取得了不错的成果,但对比较复杂的心肺音信号进行分离时会出现神经网络泛化弱的问题是该方法的缺点所在。
3 总结与展望
综上所述,听诊是针对听呼吸声的普通而简单的方法,但也有缺点,因为该方法是一项高度主观的工作,主要依赖于观察者的经验和训练,因此呼吸声的采集本身将会成为高度非线性的噪声源。由于两个信号的卷积重叠性质,本文中讨论的所有技术在从心肺音混合信号中分离心音和肺音时遇到了许多问题,比如分离后的心音和肺音存在背景噪声过大的情况或者会损失原始信号的一些信息。更好的技术仍有待实现,以用于从混合信号中分离出心音和肺音,而不会在任何频率范围内损失任何需要的信号。呼吸音记录和心音记录分别是危重患者在重症监护病房中的两个非常重要的记录。在对现有算法进行整理之后,很明显,近些年心肺音分离的重心主要是基于NMF 和基于深度学习的方法。
实现对心肺音混合信号进行分离后,下一步可以考虑对分离后的信号进行去噪处理以得到更纯净的心音和肺音,再对得到的纯净心肺音进行分类以辅助医生诊断病情。
猜你喜欢
中老年保健(2022年5期)2022-08-24
疯狂英语·读写版(2022年11期)2022-05-30
中老年保健(2021年3期)2021-08-22
工业设计(2020年2期)2020-03-16
小学科学(学生版)(2018年7期)2018-08-13
计算机技术与发展(2018年5期)2018-05-28
当代陕西(2017年12期)2018-01-19
计算机技术与发展(2017年12期)2017-12-20
儿童故事画报(2017年4期)2017-05-26
无线互联科技(2017年6期)2017-04-26
