
基于机器学习对呼吸机报警分析
2024-05-13 07:05刘强郭瑞王勤孙凯
中国医疗设备 2024年3期
刘强,郭瑞,王勤,孙凯
北京医院 a. 器材处;b. 呼吸与危重症科;c. 医务处,北京 100730
引言
呼吸机是重要的危重急救和生命支持设备,国家卫健委发布的《呼吸机安全管理》要求运用管理和医学工程技术手段,对影响治疗使用安全的因素进行系统化管理,提高临床保障能力[1]。目前呼吸机设备厂商不断改进技术,提供更加敏感的算法,使呼吸机不漏掉患者报警,因此有效报警会伴随更多的无效报警出现,而在急诊或重症监护病房,无效的误报警会使医护人员产生报警疲劳,出现响应迟缓现象,从而降低医疗质量[2]。当前呼吸机普遍使用单变量报警算法和数字阈值预警模式[3],不同厂商主要使用流量传感器、压力传感器、氧传感器(氧电池)、温湿度传感器等来监测患者端的通气情况。当患者实际数值超过医生预设阈值时,即触发报警,因而不能分辨这一报警产生的原因是生理状态改变、阈值设置范围较大,还是外界医疗干预,且不同呼吸机品牌的报警项目可相差多项报警信息和视觉信息。本研究基于呼吸机环境和参数设置,便捷、高效地对单中心数据建立预测模型。由于患者病情变化从而导致呼吸机环境和参数设置变化较大,故无法用建立数学模型的方法建模。本研究应用机器学习中主流的随机森林算法对呼吸机报警进行分析及对重要参数进行排序,通过建模识别每次报警是否为误报警,并将报警提示对应发送给医生、呼吸治疗师和临床工程师。利用临床在用呼吸机的实时数据真实反馈呼吸机的临床使用情况,基于临床数据采用机器学习的方法分析判别主要因素,可提升呼吸机的有效报警能力,降低无效报警数量,在临床上对呼吸机的使用方面具有重要意义[4]。
1 方法
1.1 呼吸机数据平台的建立
呼吸机数据平台的建立[5-6]是整合呼吸机临床数据并进一步进行统计分析、机器学习的基础。平台基于国际医疗信息系统集成(Integrating the Healthcare Enterprise,IHE)的规范流程和相关技术框架[7-8]实现数据整合。我院采用呼吸机中心集中管理的模式,对有创呼吸机建立了呼吸机数据监测拓扑图(图1)。呼吸机通信协议是系统平台建立的核心问题,本研究采用IHE规范中的患者护理设备(Patient Care Device,PDC)框架,明确各厂家的数据流标准,确保各厂家设备与系统平台联通[9]。呼吸机硬件连接在RS232 口上[10],系统平台为B/S 架构,医护端以移动手机或平板App 的形式[11]实时监测所关注的呼吸机报警数据,服务器端支持对数据的统计分析。
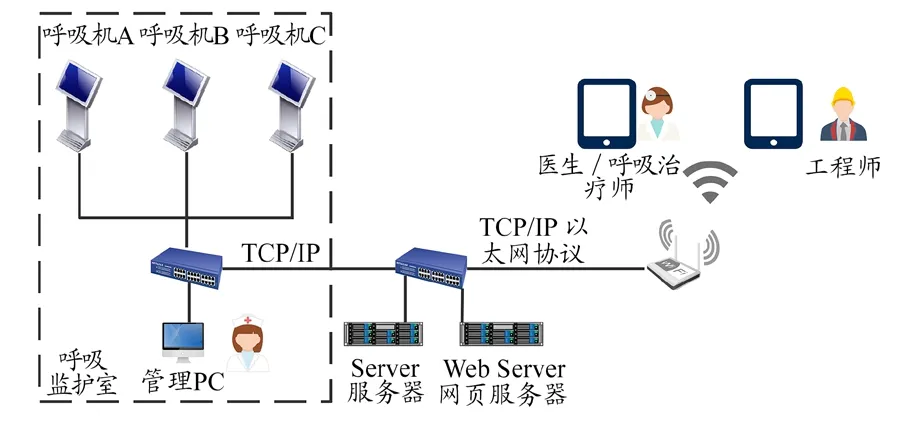
图1 呼吸机数据平台建立拓扑图
1.2 呼吸机报警统计分析
1.2.1 数据准备
接入数据平台的呼吸机全部符合国际电工委员(IECEE)医用设备及系统中警报的通用标准[12]。我院呼吸机中心有30 台有创呼吸机接入呼吸机数据平台,均为临床常用的品牌,呼吸机型号及呼吸机数据平台所记录的报警数据量如表1 所示。

表1 接入呼吸机数据平台设备列表
对呼吸机数据平台单日的报警次数进行统计得出报警总量为3699 次,其中只有近2%的报警为设备报警,其余均为通气类报警,见图2。

图2 呼吸机报警分类对比
基于呼吸机特点及报警定义级别,将呼吸机报警分为设备报警和通气报警[13]。设备报警也称故障报警,通常指呼吸机及配件发生问题。由于各呼吸机厂家设备的报警等级最高,且在临床使用中,设备报警产生的次数极低,因而设备报警(故障报警)在本研究中全部默认为真实报警。临床实际数据表明,通气类报警数量最多且频繁[14],与临床使用操作等关系紧密,不确定因素较多,报警真实性有待提高。本研究基于呼吸机数据管理平台,针对表1 中的4 款型号共5 台呼吸机,选取呼吸科病房持续上机大于30 d、情况相对稳定的5 例患者,调阅30 d 的报警数据,报警数据按临床通气报警进行数据统计,见表2。
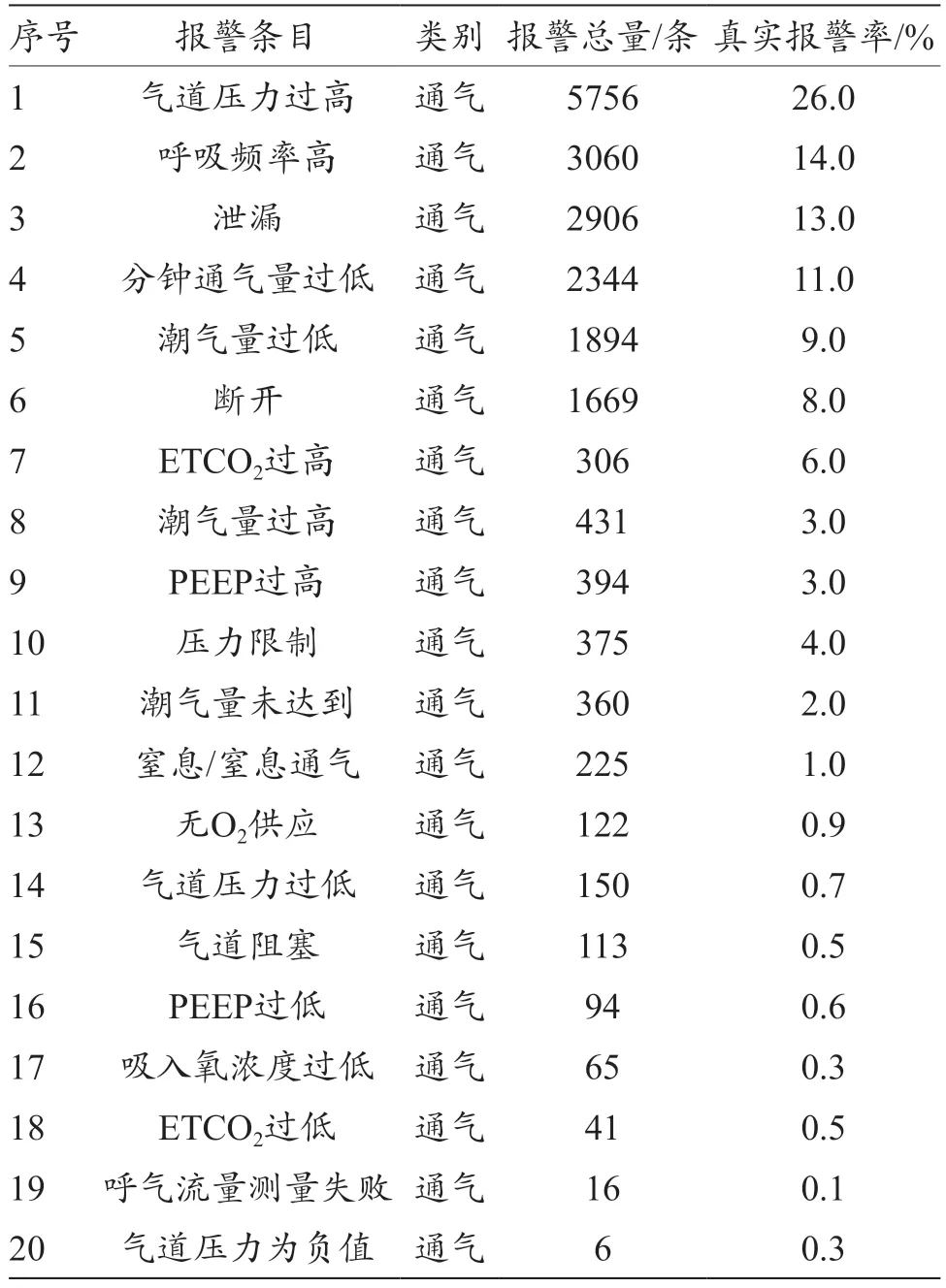
表2 呼吸机临床常见报警真实率统计
1.2.2 数据标注
训练数据集由呼吸科医生、呼吸治疗师对该科室的在用5 台呼吸机、30 d 共计20327 次临床通气报警进行标注,每条报警需在获得一致的判断后才被标注为真或假,常见报警真实率统计如表2 所示。
1.3 研究方法
1.3.1 算法架构分析
随机森林算法目前已成为医学数据分析中较常用的一种机器学习方法[15-16]。本研究使用随机森林算法构建模型进行训练和测试。随机森林算法的优势在于能够处理数量庞大的高维度特征,且不需要进行降维,能评估各个特征在分类问题上的重要性,临床训练速度快,可平衡误差、生成树状结构、判断各个特征的重要性;缺点是在噪声较大时容易出现过拟合现象,对异常值、缺失值不敏感。本文对影响真假报警的相关参数采用随机森林算法研究的变量进行表征[17],变量名及赋值说明如表3 所示。

表3 变量参数表
由表2 可知,报警总量为20327 条,其中真报警2948 条。由于正负样本严重不均衡,因此在无效报警中随机抽取和真实报警数量相同的样本数组成要研究的数据集。首先,将数据集按照分层抽样法分成训练集(14391 条)和测试集(5936 条),因变量为Y,其余13 个变量X 为自变量。先对数据进行训练,再对测试集进行验证完成预测。
1.3.2 建模过程
(1)导入所有必需的Python 库并设置环境配置。使用Python 的“read_excel”方法从保存呼吸机数据平台中加载数据并对数据进行预处理,具体包括检查数据中是否有缺失值,并使用Python 函数“dropna”删除包含任何空值的行,再将阻力、分钟容量等列的值转换为浮点数并用“NaN”替换空字符串。
(2)将数据集划分训练集和测试集,并在训练集上进行模型训练[18]。训练模型前,使用scikit-learn 的“train_test_split”方法划分数据集,确保模型不会过度拟合训练数据,并在测试集上测试。模型的输出为0 和1 之间的概率值,该值等同于无效报警或真实报警的估计值,可确定模型具有泛化能力。本研究定义了一个Pipeline来处理缺失值(使用SimpleImputer)和特征缩放(使用StandardScaler)以填充缺失数据和特征缩放,避免不同特征的规模相差过大。
(3)随机森林模型的初始化和超参数调优。本研究执行网格搜索并根据最高精度找到模型的最佳超参数(“n_estimators”“max_depth”和“criterion”)。本文通过GridSearchCV 实现超参数调优,该方法执行交叉验证,可有效避免过度拟合。随机森林模型的最优超参数组合如表4 所示。其中,“gini”作为标准,意味着使用基尼系数来衡量模型的质量,也就是组成森林的决策树的分裂;Max_depth 为4,表示森林中每棵决策树的最大深度,据此可避免因树生长得太深而导致的过度拟合;N_estimators 为150,说明森林由150 棵树组成。
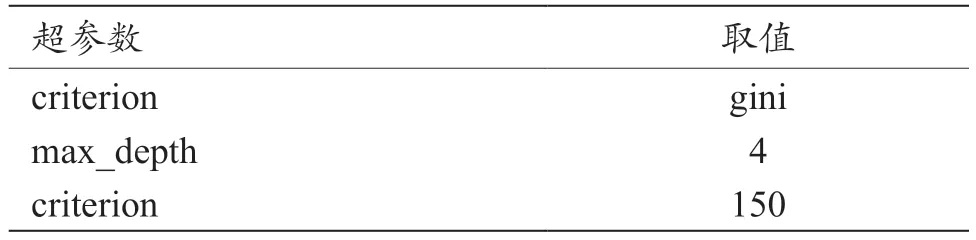
表4 最优参数模型
2 结果
模型训练完成后,提取特征重要性并在条形图中进行可视化排序。特征重要性可清晰地显示呼吸机的哪些特征对于判断无效报警最为关键。特征重要性排序图如图3 所示。
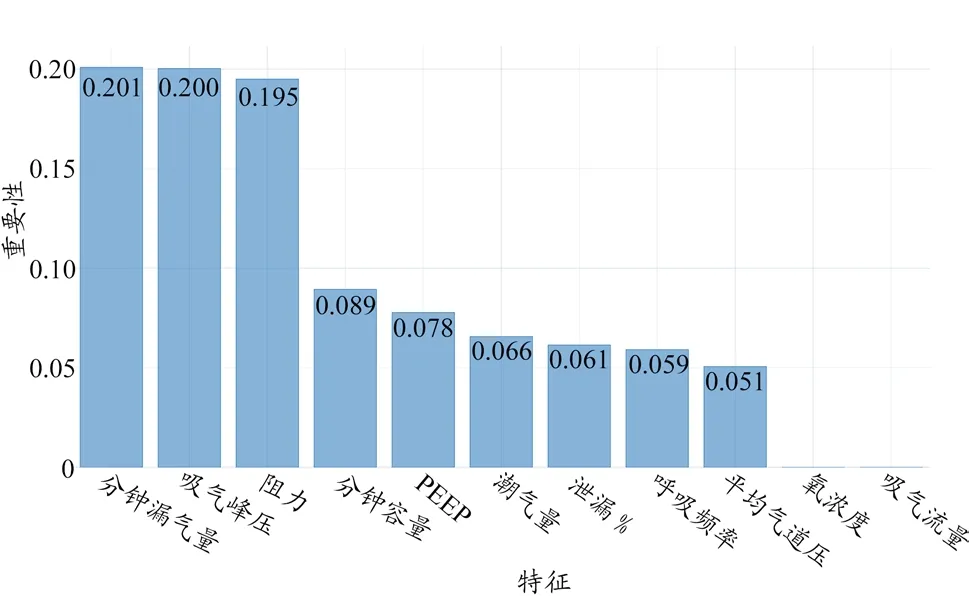
图3 特征重要性排序图
根据此次单中心数据建模分析获得的特征重要性结果为:分钟漏气量>吸气峰压>阻力>分钟容量>PEEP(呼气末正压)>潮气量>泄漏 %>呼吸频率>平均气道压>氧浓度>吸气流量。从结果来看,“分钟漏气量”和“吸气峰压”是最重要的特征,每个特征的重要性约为0.201。“阻力”的重要性比前两个稍低,为0.195。其他特征的重要性较低,“氧浓度”和“吸气流量”的重要性为零,说明“氧浓度”和“吸气流量”可能对模型预测无效报警用处极小。
在测试集评估模型性能方面,本研究通过计算得出的混淆矩阵如图4 所示。在测试集的1484 个样本中,模型正确识别了1204 个无效报警(True Negatives),正确识别了196 个真实警报(True Positives)。该模型错误地将28 个无效警报分类为真实警报(假阳性),并将56 个真实报警错误分类为无效报警(假阴性)。从不同方面评估本文模型指标[19],可得模型准确度为0.94,精准度为0.78,召回率为0.88,F1 得分为0.82,受试者工作特征(Receiver Operating Characteristic,ROC)曲线下面积(Area Under Curve,AUC)为0.92(图5),说明模型表现较好,正确区分真实或无效报警的能力较强。

图4 混淆矩阵图
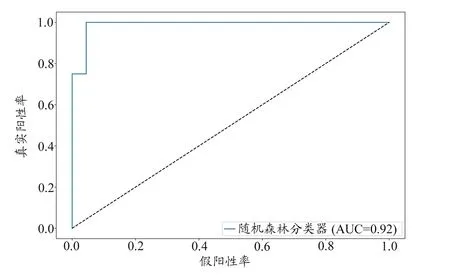
图5 ROC曲线图
3 讨论
根据随机森林模型得到的各因素重要性得分图可知,分钟通气量、吸气峰压、阻力特征重要性值最高(>0.19);氧浓度和吸气流量的重要性几乎为零,说明这2 项报警均为设备报警而非通气类报警,一旦报警即为真实报警,符合目前临床操作。通过超参数调优建模可预测报警的真假,评估指标中召回率为0.88,即约88%的报警可提示临床为无效报警。随机森林建模不同于公式建模,本研究的呼吸机设备、参数发生变化,包括报警设置改变,均须重新建模再进行分析。同比其他数学模型训练方法,本研究的建模方式更符合临床科室的实际情况,对于医院单中心的数据分析更加适用。呼吸机数据平台的服务器在获得分析报警的真假结果数据后[20],由呼吸机数据平台将真实报警或可能为误报警的信息分别发送给工程师[21]和临床医护App 端,其中共有5223 次通过App 对医护端提示存在误报警可能,包括16 次延迟。网络延迟目前在院内测试中虽有20~30 s的延迟,但不会漏掉任何报警信息,且符合美国医疗器械促进协会(Association for the Advancement of Medical Instrumentation,AAMI)规定的报警响应时间。本研究的不足之处在于建模训练前期的20327 次报警需由医生标注,不可避免地会由于主观判断造成误差以及产生标注疲劳。获得大量的数据标注虽可提升算法的精度,但需要不断克服临床数据标注中的困难。后续机器学习数据的积累可为呼吸机设备保障的早期预警提供参考。
4 结论
基于呼吸机数据平台的真实临床数据,用Python 语言建立超参数调优的随机森林模型和重要参数排序,经测试集数据验证可及时、高效地进行呼吸机报警数据分析和预测。在降低无效报警方面,设备报警及通气类报警中真实报警被降低得较少。在不降低真实报警率的情况下,氧浓度和吸气流量等真实报警很难被抑制,也客观验证了无效报警目前无法完全被抑制但可以被提示。下一步,随着呼吸机平台数据量的不断积累,基于重要报警参数的软件算法不断更新,以及整合心电、血氧、心率等监护信息的多模态数据的导入,未来有望实现精准地评价呼吸机的每次报警,最终实现完全抑制呼吸机的无效报警。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
现代仪器与医疗(2022年2期)2022-08-11
现代仪器与医疗(2021年5期)2021-12-02
世界最新医学信息文摘(2021年12期)2021-06-09
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
铁道通信信号(2018年5期)2018-06-28
汽车维护与修理(2016年10期)2016-07-10
小学生·多元智能大王(2015年3期)2015-05-25
