
基于qv自注意力的改进YOLOv5航拍目标检测
2024-05-09 03:15唐田尧石永康王浩然吕玉龙
电光与控制 2024年5期
唐田尧, 石永康, 王浩然, 吕玉龙
(新疆大学智能制造现代产业学院,乌鲁木齐 830000)
0 引言
航拍遥感图像的检测是当前军用航空领域的研究热点之一,但图像中不同目标之间的尺寸差距较大,如汽车和飞机,其尺寸可以相差50倍以上,所以在遥感图像中,不仅要考虑小目标的检测精度,还要兼顾其他尺寸目标的检测精度。
基于深度学习的通用目标检测算法可分为3类:两阶段检测算法R-CNN系列[1-3]、单阶段检测算法YOLO[4]和SSD[5]系列,以及基于Transformer[6]的目标检测。Transformer是基于自注意力机制(Self-Attention,SA)和位置编码的模型,一开始仅用于自然语言处理,目前在深度学习各个领域广泛应用,开启了深度学习的新时代。
针对航拍遥感图像小目标多、尺度变化大的特点,研究学者主要做了以下改进:为了实现不同尺度的特征提取,提高小目标的检测性能,文献[7]设计了特征金字塔网络,将金字塔不同层级获取的特征融合,以提高网络对小物体的识别能力;文献[8]提出了一个新的感知生成对抗网络(Perceptual GAN)模型,利用大小物体之间的相关性来增强小物体的表示,从而改善小物体检测;文献[9]在YOLOv5算法的基础上,通过使用K-means++聚类技术、添加scSE注意力模块以及增加小目标检测层来提高小目标的检测精度;文献[10]在YOLOv5网络的第1层引入浅层特征提取网络,然后将浅层特征图与检测头的特征融合,提高了模型的精度和泛化能力;文献[11]构建了深度解耦头模块,并引入了SA注意力机制和GSConv模块,实现了一种新的轻量级网络。
本文以YOLOv5s为基础网络进行改进,提出了LL-YOLOv5s网络和qv自注意力模块,实现对航拍图像的高效识别。
1 YOLOv5算法改进
1.1 YOLOv5简介
YOLOv5模型是Ultralytics公司于2020年6月9日公开发布的,经过一系列优化和改进,目前更新到7.0版本[12]。本文以7.0版本的YOLOv5s模型作为基础结构,进行改进。
图1为YOLOv5s和LL-YOLOv5s结构图。
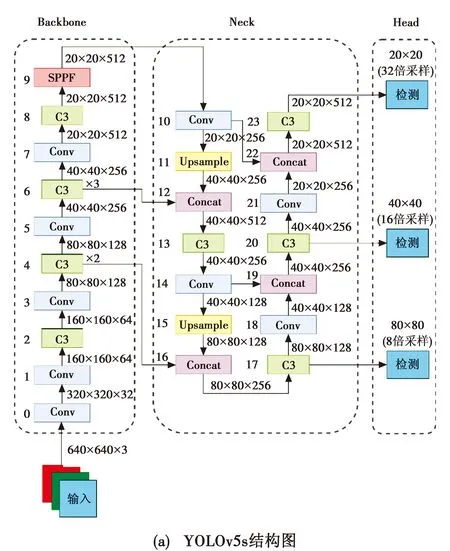
图1 YOLOv5s和LL-YOLOv5s结构图Fig.1 YOLOv5s structure and LL-YOLOv5s structure
1.2 YOLOv5s算法结构
YOLOv5s主要包含了Conv、C3、SPPF、Concat和Upsample模块,其结构如图1(a)所示,假设输入分辨率为640×640(单位为像素)的彩色3通道图像。
在Backbone部分:第0,1层的每个Conv模块都将原图下采样2倍(即图像尺寸减半);第2层的C3模块提取特征信息;第3、第4层的Conv模块和C3模块将图像下采样8倍后,立即提取特征信息;然后将第3、第4层重复3次,在第9层使用SPPF模块融合深层和浅层的网络信息。
在Neck部分:第10层的Conv模块与之前不同,这里特征图尺寸不变,通道数减半;第11层使用Upsample模块上采样,使采样恢复到16倍;第12层使用Concat模块融合第6、第11层的16倍下采样,通道数为两者相加;第13层的C3模块用于提取特征信息;然后重复第10~13层得到第14~17层;第18层的Conv模块,保持通道数不变,特征图尺寸减半,此时为16倍下采样;第19层的Concat模块融合第14、第18层;第20层使用C3模块提取特征信息;重复第18~20层得到第21~23层,此时为32倍下采样。
在Head部分:将颈部第17、第20、第23层的C3模块作为检测头的输入,得到3个8、16、32倍下采样的检测头,用于检测不同大小的目标。
1.3 LL-YOLOv5s结构
针对航拍图像中小目标识别困难和尺度变化大的问题,本文将YOLOv5s结构做针对性改进,得到LL-YOLOv5s结构,如图1(b)所示。
LL-YOLOv5s与YOLOv5s原结构相比,做了以下4点改进。
1) 在第0层后面增加一个具有3×3卷积核且步长为1的卷积层,在保留空间维度的同时,增强网络的特征提取能力和模型的深度。
2) 删去原Backbone部分的第1、第2层,减少一次对特征图的下采样,所以Backbone的输出特征图由32倍下采样512通道数,转变为16倍下采样256通道数,下采样倍数和通道数都减半。
3) Neck部分的输入变为16倍下采样,所以Neck的第1个Concat模块对8倍下采样进行融合,Neck的第2个Concat模块对4倍下采样进行融合。
4) 只使用2个检测头,实现对小目标和中目标的精准检测。由于不再需要第3个检测头,相应地,删去原颈部的第21~23层,不再对16倍下采样做检测,减小计算量。
综上,相比于YOLOv5s结构,LL-YOLOv5s既有删除的部分,也有增加的部分。由于LL-YOLOv5s结构只使用了2个4倍下采样和8倍下采样的检测头,下采样倍数低,图像压缩少,所以对小目标有很好的检测效果,但该结构不适用于大目标检测任务,当数据集中大目标较多时,检测精度会降低。总之,LL-YOLOv5s失去了对大目标的检测能力,将计算资源放在小目标的检测上,是一个对于特定尺寸(小目标)进行检测的网络结构。
2 qv自注意力模块
2.1 自注意力机制
自注意力机制能够对输入信息做全局关联,将这种能力应用于小目标图像检测领域,不仅能够帮助模型捕捉到小目标相互位置之间的依赖信息,还能够帮助模型更好地理解小目标与背景之间的差异,使得网络学习到更多的特征信息,弥补小目标信息量少的缺陷。自注意力[6]可描述为

(1)

由于Q·KT·V的计算和内存需求随着元素数量的增加呈三次曲线增长,导致实际计算过程中出现推理速度慢和内存使用率高的问题,无法做到高分辨率大尺寸图像的实时计算。
2.2 qv自注意力模块
本文所提qv自注意力模块如图2所示。
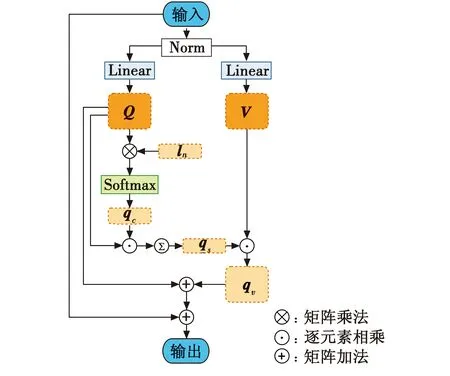
图2 qv自注意力模块Fig.2 The qv self-attention module
假设输入数据的维度为k×d,具体过程如下。
1) 将输入数据通过BathNorm(Norm)进行归一化操作,这有助于加速训练过程,当输入存在特异数据时,可以保证训练过程的稳定。
2) 使用两个k×d的线性层(Linear)将输入矩阵映射为查询矩阵Q和值矩阵V,两个矩阵的维度均为k×d。
3) 初始化可学习参数向量ln,其维度为d,它作为嵌入参数,用于预测输出。将查询矩阵Q与可学习向量ln进行矩阵乘法运算,以学习Q的注意力权重。再进行Softmax运算,得到全局查询向量qc,其特征维度为k,算式为
(2)
4) 根据学习到的全局查询向量qc对查询矩阵Q进行逐元素相乘,得到增强全局查询矩阵,此时特征维度恢复k×d,然后对第一维信息求和,得到增强全局查询向量qs,其特征维度为d,算式为
(3)
式中:qci表示全局查询向量qc中的单个元素;Qi表示查询矩阵Q中的单个元素;*表示广播式逐元素乘法(Broadcasted element-wise multiplication),这种计算方法只做逐元素乘法,并且当两个数组之间的维度不匹配时,可以智能扩展不匹配数组的维度,从而实现高效地计算。与标准自注意力中的点积运算相比,具有更高的计算速度。
5) 将向量qs和键矩阵V逐元素相乘,得到全局查询键矩阵qv,进一步获取的自我学习信息,其中包含了增强后的查询特征和键特征,此时特征维度恢复k×d。qv矩阵表示为
qv=qsi*Vi
(4)
式中:qsi表示全局查询向量qs中的单个元素;Vi表示查询矩阵V中的单个元素;i的值最大为n。
6) 两次相加,也称为两次残差结构:将矩阵qv和Q相加,再将结果与输入相加。这样可以使网络学习到残差部分,即输入与期望输出之间的差异,而不是直接学习整个映射函数。有效防止神经网络中出现梯度消失和梯度爆炸问题,从而改善训练效果。
3 实验结果与分析
3.1 实验数据集
DOTA[13]数据集是一个大型航拍遥感图像数据集,图像来自谷歌地球等多个平台,共包含2806张航拍图像,尺寸一般在800×800到4000×4000(单位为像素,下文同)之间。训练集、验证集和测试集的比例为3∶1∶2。
DOTA-v1.5是DOTA数据集的升级版,两者使用相同的航空图像,但DOTA-v1.5对物体的注释进行了修订和更新,尤其是对DOTA-v1.0中遗漏的许多尺寸大约10×10的小目标进行了额外的注释。完善后的数据集包含16个类别,共40万个标签。
由于数据集中图像大小不统一,尤其包含很多超大尺寸图像,因此在进行目标检测训练时需要先对图像进行分割。本文将图像统一分割为大小1024×1024,为了防止目标被切割导致的目标损失,在分割时设置了20%的重合区域。图片分割后,会产生大量被分割的标注,突出特点是标注目标只有实际物体的一部分,例如飞机的一部分机翼,有助于网络学习目标受到遮挡时的特征,当目标只露出一部分时,也可以有效检测到。
由于数据集中部分类别的标签数量小于三位数,训练结果很差,所以删除这些类别,然后将标签转化为YOLO格式,并删除不包含任何标注的图像。最终,本文使用的数据集中,训练集包含8674张图像,验证集包含2739张图像,共有小型车辆(small-vehicle)、大型车辆(large-vehicle)、飞机(plane)、储存罐(storage-bank)和船舶(ship)5种类别,这些类别在军事上具有重要意义。其中,小型车辆有304140个标注,大型车辆有57937个标注,飞机有23260个标注,储存罐有15199个标注,船舶有95606个标注,共计496142个标注。具体类别数量和分布如图3所示。
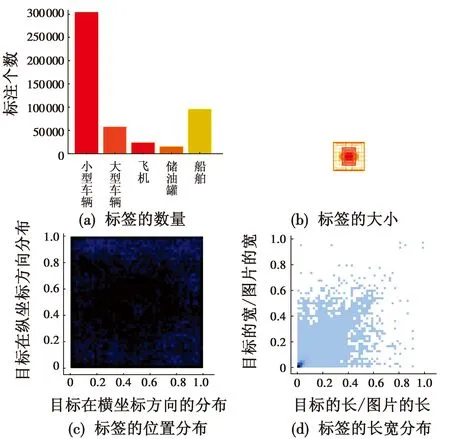
图3 数据集中的类别数量和分布Fig.3 Number and distribution of categories in the dataset
由图3可以看到,在本数据集中,小型车辆和船舶这2类目标的数量占据绝对优势,说明本数据集对于小目标的检测有着非常高的要求。在绝大多数目标为小目标的情况下,也存在一定数量的大目标,例如飞机和储存罐。同时也可以看到,数据集各目标的位置分布较为均匀,是一个良好的中小目标检测数据集。
3.2 性能评价指标
本文采用所有类别的平均精度均值(mAP)、模型的参数量(Parameters)、模型的浮点运算量(FLOPs)、每秒检测帧数(FPS)4个指标作为模型性能的评价指标。mAP是指如果预测边界框与实际边界框之间的重叠程度大于或等于0.5,则将其视为正样本的概率分数;Parameters即模型中需要进行训练的可学习参数的数量,参数量越多,通常意味着模型具有更多的表达能力,但也可能会增加训练和推断的时间;FLOPs指模型每秒进行浮点运算的次数,更高的FLOPs一般意味着模型在推断时需要更多的计算资源。
3.3 实验环境及训练参数设置
本文实验的操作系统为64位Windows10,使用PyCharm 2021.3专业版搭建了Python3.9,Pytorch 1.12.1以及CUDA11.6的软件环境。所用CPU为AMD RyzenTM7 5800H,GPU为NVIDIA GeForce RTX3070 laptop 8 GiB。批量大小(batch size)均设置为16,训练200次,图像大小设置为640×640,其他参数保持默认设置,不做修改。
3.4 消融实验结果与分析
本文进行的一系列消融实验和结果如表1所示。表中:改进1为将qv自注意力模块添加到LL-YOLOv5s的第1个检测头之前;改进2为将qv自注意力模块添加到LL-YOLOv5s的第2个检测头之前;改进3为在改进1的基础上,再在qv自注意力模块后添加一个具有3×3卷积核且步长为1的卷积层,增强网络对于qv自注意力学习特征的提取能力。

表1 消融实验结果
由表1可知,LL-YOLOv5s与YOLOv5s模型相比,在Parameters和FLOPs均减小的情况下,mAP实现了2.9个百分点的提升;另外,在精度超过YOLOv5m模型的前提下,实现了高于YOLOv5s的检测速度,说明LL-YOLOv5s模型实现了对于小目标和中等目标的精确检测。
改进1:mAP提升了0.9个百分点,仅增加很小的Parameters和FLOPs。说明qv自注意力模块是一个简单且高效自注意力模块,可有效提高网络的小目标检测能力。
改进2:mAP提升了0.7个百分点。相比于改进1,mAP的提升稍小,可能的原因有以下两点:1) 数据集中小目标的占比更大,所以将qv自注意力模块添加到小目标检测头的效果更好;2) qv自注意力模块对于小目标的检测效果更好。
改进3:相比于改进1,mAP又提升了0.4个百分点,说明将qv自注意力模块与1个3×3卷积核且步长为1的卷积层连用,可以进一步提升网络对于qv自注意力模块学习的能力。改进3与原YOLOv5s相比,Parameters减小了78.9%,FLOPs增加了5.1%,mAP提升了4.2个百分点,达到79.5%,FPS仅减少了1 帧/s,达到了57.5 帧/s。目前摄像设备的拍摄帧率一般为24~30 帧/s,少数设备能达到60 帧/s,所以57.5 帧/s的检测速度已经可以满足实时检测的需求。与YOLOv5m相比,各项性能指标更是全面超越。所以将改进3确定为最终改进的网络结构。
根据消融实验的结果,得到最终改进后的模型结构如图4所示。

图4 最终改进的模型结构Fig.4 The final improved model structure
3.5 数据集图像的检测效果
利用YOLOv5s与最终改进后的模型,对DOTA数据集中的4个典型的航拍图像做目标检测。结果见图5。

图5 改进前后的检测效果及其可视化Fig.5 Detection effect before and after improvement and its visualization
由第1行图像可以看出,在识别小目标时,最终改进算法可以识别到更多的小型车辆;由第2行图像可以看出,改进算法可以在保证对中等目标(飞机)识别效果的情况下,识别到更多的小目标(小型车辆);由第3行图像可以看出,改进算法可以在保证对小目标(小型车辆)识别效果的情况下,识别到更多的中等目标(船舶);由第4行图像可以看出,改进算法也可以兼顾中型目标的识别。综上,与YOLOv5s相比,本文最终改进算法在航拍小目标和中目标的检测上具有比较明显的优势。具体地,在复杂背景下,本文算法对小目标的检测效果更好,当目标尺度相差较大时,例如飞机和车辆处于同一场景时,本文算法也能检测到更多的目标。
3.6 与最新YOLO系列对比
将改进后的YOLOv5s与最新YOLO系列对比,选择对比对象为YOLOv6s、YOLOv7-tiny和YOLOv8s模型,结果如表2所示。
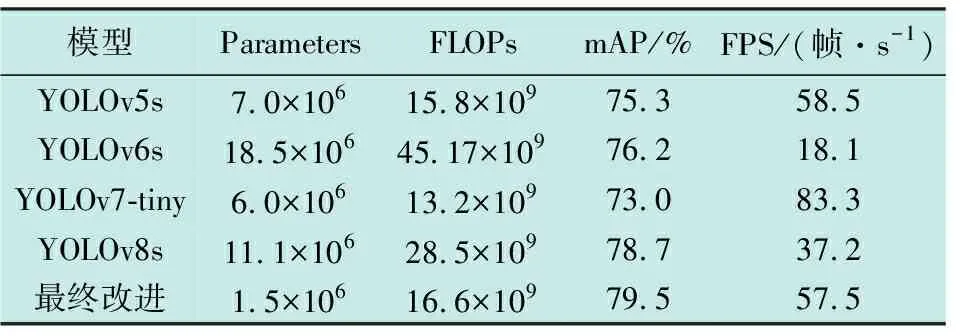
表2 与最新YOLO系列模型对比
由表2可以知道,YOLOv6s和YOLOv8s相比于YOLOv5s,虽然mAP的精度更高,但代价是更多的Parameters、FLOPs以及更低的FPS。YOLOv7-tiny虽然检测速度更快,但是精度低于YOLOv5s。
综上,相比于YOLOv5s,YOLOv6s、YOLOv7-tiny和YOLOv8s模型并没有表现出特别大的优势。而本文基于YOLOv5s最终改进的算法,在Parameters最小的情况下,实现了最高的mAP,与此同时,FLOPs也处于较低水平,57.5 帧/s的检测帧率使得模型具有了实时检测的可能。
4 总结与展望
航拍遥感图像目标检测在军事和民用方面均具有重要的应用价值,图像中的车辆、船舶等目标具有分布密集、尺度小和特征信息少的特点,而飞机等目标具有相对较大的尺寸,在实际应用中,需要模型在检测小目标的同时,兼顾其他尺寸的目标。在YOLOv5s模型的基础上,通过对结构进行改进,本文提出了一种专门针对小目标和中目标的LL-YOLOv5s模型,然后将本文所提qv自注意力模块与此模型融合,简单而又高效地提升了模型对于目标的检测精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中外文摘(2021年10期)2021-05-31
小学生优秀作文(低年级)(2018年6期)2018-05-19
作文通讯·高中版(2017年6期)2017-07-10
传媒评论(2017年3期)2017-06-13
陕西画报(2017年1期)2017-02-11
第二课堂(课外活动版)(2016年2期)2016-10-21
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
