
基于深度SVDD-CVAE的轴承自适应阈值故障检测
2024-05-07 09:12:42刘云飞张楷菅紫倩郑庆张越宏袁昭成焦子一丁国富
机床与液压 2024年6期
刘云飞,张楷,菅紫倩,郑庆,张越宏,袁昭成,焦子一,丁国富
(1.西南交通大学机械工程学院,四川成都 610031;2.西南交通大学唐山研究院,河北唐山 063003;3.西南交通大学轨道交通运维技术与装备四川省重点实验室,四川成都 610031;4.成都市特种设备检验检测研究院,四川成都 610299)
0 前言
滚动轴承是旋转机械中最重要的部件之一[1-2],苛刻的工作环境易使它发生损坏,因此对轴承的状态进行监测,及时发现故障并发出警报,能有效避免装备运行灾难性事故的发生,具有重要的研究和工程意义[3]。
近年来,数据驱动的轴承故障检测方法由于无需构建复杂的动力学模型和不依赖先验经验而迅速发展[4]。在实际工程中,由于故障数据获取困难而导致异常数据不足,仅采用正常数据进行训练的数据重构故障检测法受到相关研究者的广泛关注[5]。尤其是基于自编码器(Autoencoder,AE)的无监督轴承故障检测方法,该类方法采用正常数据训练自编码器进行数据重构,以重构误差作为异常评分来设定阈值。其优势是仅依靠正常数据便能完成模型训练并取得较高的检测精度。例如,HUANG等[6]提出了记忆残差回归自编码器模型(Memory Residual Regression Autoencoder,MRRAE),将记忆模块和参数密度估计器集成在一起,利用模型的重构误差和意外值对轴承异常状态进行检测;张聪等人[7]构建了复杂系统多变量耦合关系网络,并用无监督学习的变分图自编码模型(Variational Graph Autoencoder,VGAE)提取其特征,以重构概率作为评价指标进行故障检测。
上述方法在仅有正常数据训练的条件下,取得了一定的故障检测效果。但除了模型特征提取和预测能力外,故障阈值的确定对此类方法的检测精度也有着极大的影响。如何准确定义故障阈值在基于数据重构误差的故障检测方法中至关重要。为此,一些学者基于自适应阈值的轴承故障检测方法进行了研究。王雷、孙习习[8]提出了基于时序分解和一维深度卷积自编码网络的无监督轴承故障检测方法,在实现充分提取轴承故障特征的同时自适应地确定了样本临界阈值。但是在这些方法中模型的优化与故障检测器的设计是分离的,以致不能充分提高故障检测准确率。
ZHOU等[9]提出集模型的优化与故障检测器一体设计的深度SVDD-VAE模型,并在手写数字集中验证了自适应阈值的可行性。针对上述滚动轴承故障信号稀缺和故障阈值自适应困难的问题,受ZHOU等[9]研究的启发,本文作者提出基于卷积长短期记忆网络变分自编码器的深度支持向量数据描述(ConvlstmVAE based Deep Suport Vector Data Descrition,SVDD-CVAE)的轴承自适应阈值故障检测方法。首先针对时序信号特征增强提取构建以卷积长短期记忆网络(Convolution Long Short Term Memory,ConvLSTM)为基础单元的VAE特征压缩提取框架,有效提取轴承故障微弱特征。然后,结合支持向量数据描述(SVDD)自适应学习特征空间超球面,以实现故障检测阈值的自适应确定。最后通过全局误差损失反向传播对深度SVDD-CVAE框架进行迭代优化。
1 理论背景
1.1 变分自编码器
变分自编码器(Variational Autoencoder,VAE)是基于自编码器演化而来的一种无监督学习方法[10-11]。VAE通过对样本分布的学习,可以实现估计分布近似逼近样本真实分布,进而由估计分布生成原始样本的重构样本。VAE的结构如图1所示。
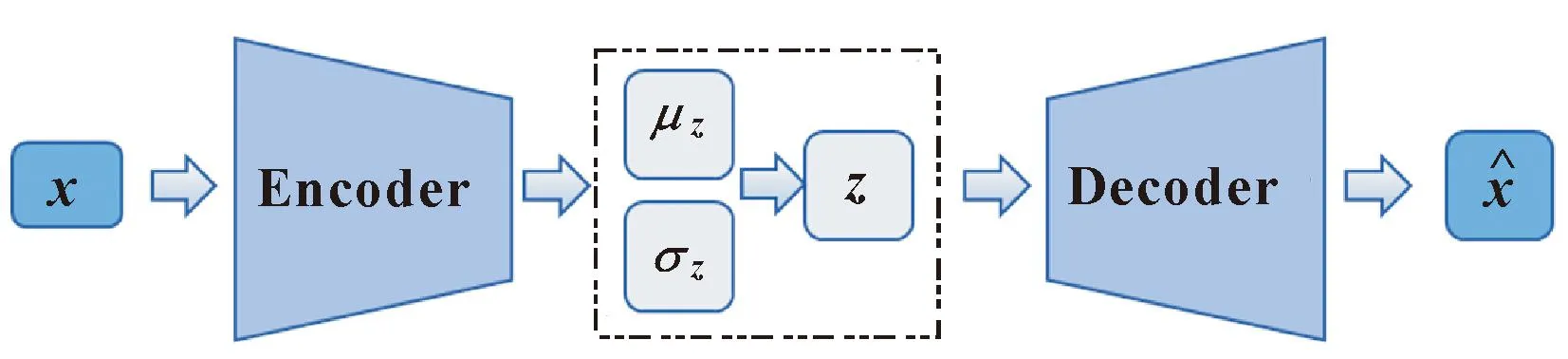
图1 VAE结构
图1中:z是潜在变量;μ和θ是通过编码器(Encoder)计算得到的隐变量均值和标准差,它将z约束为一个根据标准正态分布pθ(z)的随机变量。VAE的损失函数为
L(θ,φ;xi)=Eqφ(z|x)[logpθ(xi|z)]-
(1)
其中:qφ(z|xi)为近似后验分布;pθ(xi|z)为解码过程需要学习的条件分布;pθ(z)为先验分布;DKL为KL散度。第一项根据实际需要可选择二值交叉熵或者平方误差,第二项KL散度为
(2)
VAE巧妙地利用变分推理和重参数化技巧实现了生成过程,既通过对隐藏变量的采样保证其生成能力,又通过反向传播提高生成质量。
1.2 ConvLSTM
长短期记忆网络(Long Short Term Memory,LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,RNN),它由1个细胞单元与3个门控组成,分别是遗忘门、输入门和输出门。细胞单元是核心计算能力,可以记录当前计算状态,而遗忘门、输入门和输出门调节进出存储单元的信息流[12-14],其结构如图2所示。
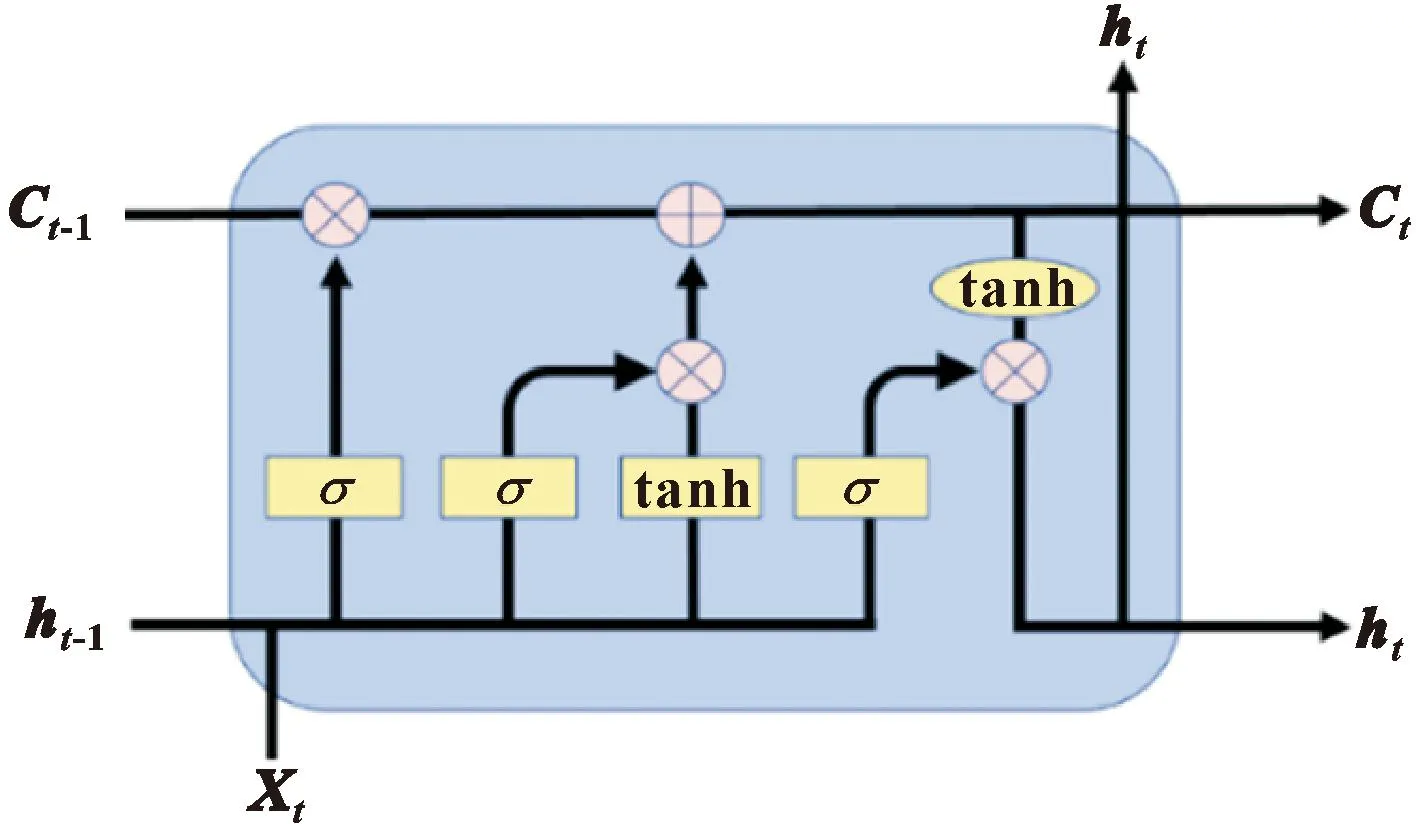
图2 LSTM结构
LSTM的计算原理可以概括为:通过遗忘细胞状态信息和记忆新的信息使得对后续计算有用的信息得以传递,而无用的信息被丢弃,其前向传播可以表示为
ft=σ(Wf×[ht-1,xt]+bf)
(3)
it=σ(Wi×[ht-1,xt]+bi)
(4)
Ct=ft×Ct-1+it×tanh(WC×[ht-1,xt]+bC)
(5)
ot=σ(Wo×[ht-1,xt]+bo)
(6)
ht=ot×tanh(Ct)
(7)
式中:ft为遗忘门;it为输入门:ot为输出门;ht、ht-1为LSTM的输出和上一个单元的输出:xt为当前的输入;σ为Sigmoid函数;Wf、bf为遗忘门权重矩阵和偏置项;Wi、bi为输入门的权重矩阵和偏置项;Wc、bc为状态值计算的权重矩阵和偏置项;Wo、bo为输出门的权重矩阵和偏置项。
ConvLSTM是LSTM的一种变体[15],它在原始LSTM每个单元的3个门之前添加一次卷积操作,使用卷积计算代替权值计算,提取多维数据中隐含的关联信息,在多维数据中通过卷积提取特征,可以更适合空间序列,具体结如图3所示。
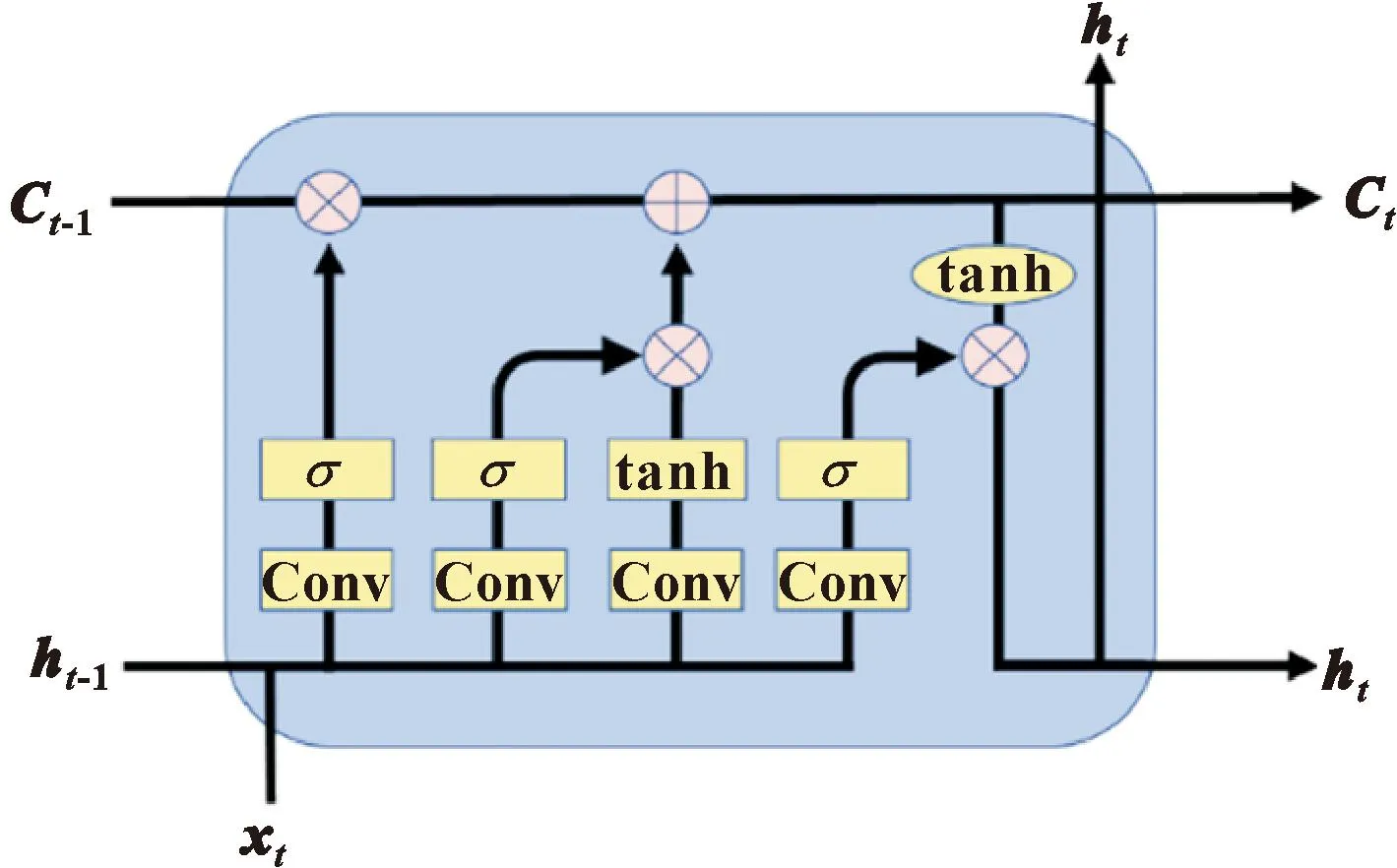
图3 ConvLSTM结构
其前向传播可以表示为
ft=σ(Wf⊗ht-1+Wf⊗xt+Wf⊙Ct-1+bf)
(8)
it=σ(Wi⊗ht-1+Wi⊗xt+Wi⊙ht-1+bi)
(9)
Ct=ft⊙Ct-1+it⊙tanh(WC⊗ht-1+WC⊗xt+bC)
(10)
ot=σ(Wo⊗ht-1+Wo⊗xt+Wo⊙Ct+bo)
(11)
ht=ot⊙tanh(Ct)
(12)
式中:⊗为卷积算子;⊙为哈达玛积。
1.3 SVDD
SVDD的基本思想是寻找一个球心为a、半径为R且能够包含全部或大部分目标样本数据的最小超球体[16-17]。假设有一组正常训练数据H∈Rn×d,其中n为样本数,d为变量数,则SVDD原始优化问题可表述为
(13)
ξi≥0,i=1,2,…,n
(14)
式中:ξi为松弛变量;C为惩罚因子。考虑到核函数对分类器的影响,选择使用最为广泛的高斯核函数,即:
(15)
代替映射后的样本间内积运算为<Φ(hi),Φ(hj)>,引入拉格朗日乘数a=[α1,α2,…,αi]转换为其对偶问题:
(16)
(17)
SVDD算法是经典的单分类算法,训练时只关注正常样本,尤其适合在缺少异常样本的情况下使用。
2 提出方法
文中提出模型(如图4所示)由TCVAE的数据重构和作为故障检测器的SVDD组成。TCVAE是针对时序信号特征增强提取构建的以ConvLSTM为基础单元的CVAE特征压缩提取框架。深度SVDD-CVAE首先通过VAE编码器中的ConvLSTM提取特征,提取的特征被转移到后续的SVDD中学习超球面,最后VAE解码器利用被约束后的特征重建输入实例,深度SVDD-CVAE共同优化这2个过程。在检测阶段,将脱离学习超球的实例视为异常。
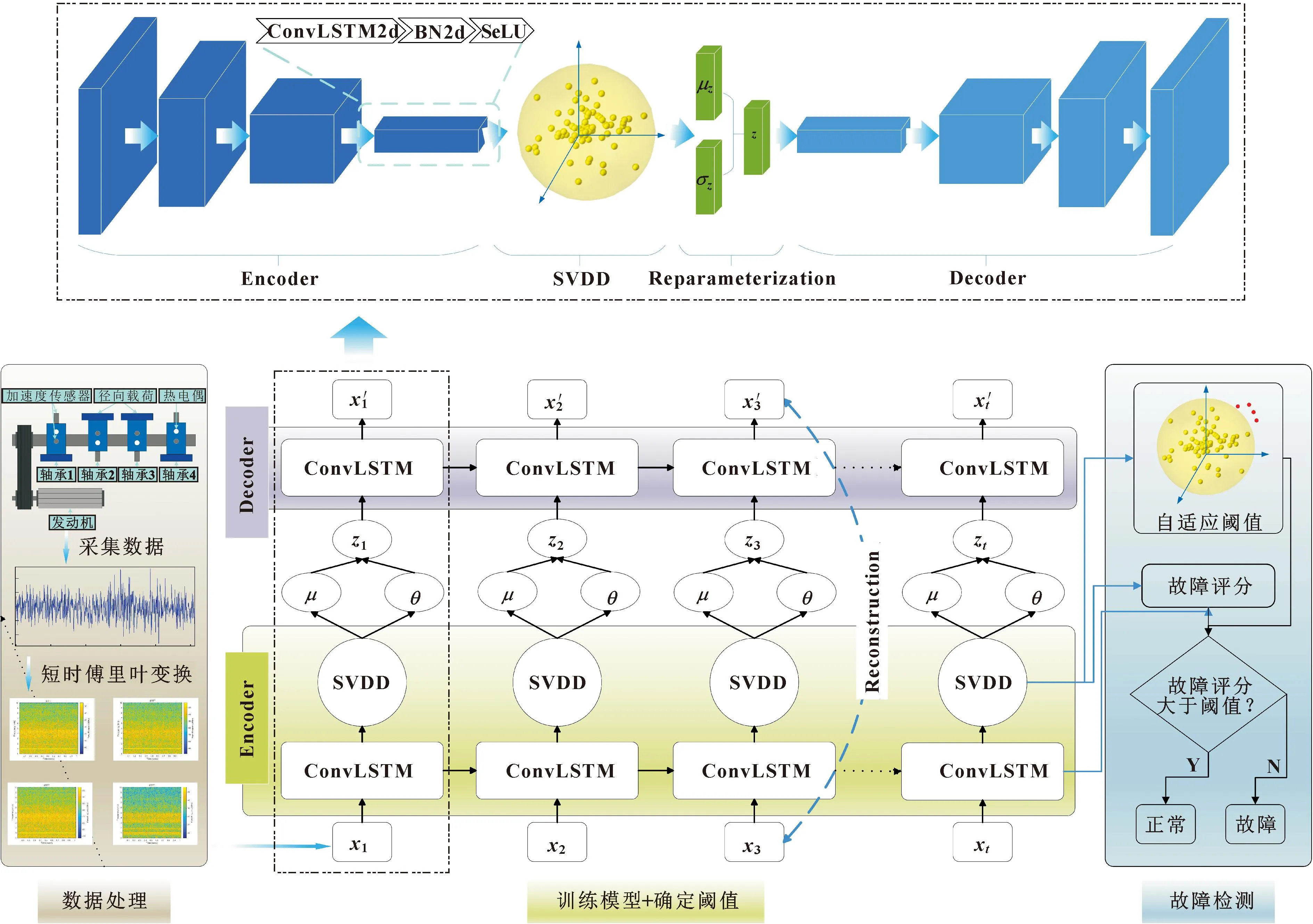
图4 基于深度SVDD-CVAE的轴承自适应阈值故障检测原理
2.1 优化SVDD的目标函数
在第1.3节中所介绍的SVDD旨在构建一个分离正常实例和异常实例的超球。而训练集中所有实例都是正常样本的情况下,可以采用改进的SVDD构建深度SVDD-CVAE模型。改进后的SVDD中,原损失函数可以简化为
(18)
其中:φ(xi;W)是数据点xi的潜在表示;中心c是神经网络学习到的参数。在修改后的SVDD问题中,训练的不再是半径R,而是所有数据点xi到学习中心c的平均距离。由于训练集中不再包含异常数据,所以原始和修改后的SVDD的主要区别是松弛变量不再被惩罚,需要用网络φ(·)映射所有靠近中心c的实例。
2.2 深度SVDD-CVAE模型
深度SVDD-CVAE首先通过TCVAE有效提取轴承故障微弱特征,编码后再将提取的特征用SVDD映射到希尔伯特空间进行约束,然后将约束后的特征进行CVAE重参数化,最后输入到解码器中完成数据重构,解码器和编码器成镜像对立设置。CVAE特征压缩提取框架由4个基础单元组成,每个单元包含ConvLSTM2d、SeLU激活函数和批处理归一化(Batch Normalization,BN)层,其中最后一个单元多包含一个Flatten层,以减少特征空间的维数。时频图可以很好地表征微弱故障信息,ConvLSTM2d可以更好地将每一张时频图的时间序列微弱故障特征提取出来。
文中提出方法的目的是最小化所有数据表示与中心c之间的平均距离,同时保持重构输入数据的能力。给定一个训练数据集Dn=[x1,x2.…,xn],定义深度SVDD-CVAE目标函数为
(19)
式中:φ为CVAE编码器参数;θ为CVAE解码器参数。α是一个可调参数,在训练阶段设定数值,可以平衡CVAE和SVDD对整个模型的影响,如果将所有的输入实例映射到潜在空间的一个点上,那么提取出的所有输入实例所拥有的特征对不同的输入实例进行重构的帮助就会降低,从而导致模型重构损失较大。理论上,最优解需要将所有的输入映射到潜在空间中的不同输出上,不同的输出可以支持超球不崩溃。因此将故障检测器放置在重参数之前可以有效避免噪声带来的影响,提升模型对于早期轴承故障点的敏感程度,降低误报率。
该模型需要找到一个将潜在表示映射到尽可能靠近中心的解决方案,并尽可能重构输入数据。将SVDD纳入CVAE网络的编码器之后,提升了网络模型的检测准确率,在评估阶段,正常数据的表示比异常数据的表示更接近中心。
2.3 深度SVDD-CVAE异常评价
根据输出类型的不同,故障检测可以分为基于评分的方法和基于标签的方法。深度SVDD-CVAE是一种基于评分的方法。异常评分定义为表示到训练后的超球中心的距离。给定的测试点xi的异常分数如下:
(20)
式中:zi为x进行编码学习后的表示;c是训练好的超球的中心。s(xi)值越高,点xi越可能是反常的。半径R*是所有训练实例异常评分的第98百分位。
深度 SVDD-CVAE模型工作流程构造算法:
输入:数据表示Dn={x1,x2,…,xn},训练轮次k;
初始化:模型参数φ,θ和中心c;
(1)当i≤k时进行循环;
(2)x⟸从训练数据集中随机选择小批量Dn;
(3){μ,θ}⟸Encoderφ(x);
(5)z⟸样本的重参数化N{μ,θ2};
(7)计算R*;
(9)结束循环;
(10)Return:迭代优化模型参数φ*⟸φk,θ*⟸θk,c*⟸ck
(12)R*⟸所有训练实例的排序异常评分98百分比;
(13)提取每个测试样本的特征ztest⟸Encoderφ*(xtest);
(15)比较s(xtest)和R*:如果s(xtest)>R*,则xtest为故障。
所提方法的目的是在潜在空间中找到一个最小体积的封闭超球,描述所有训练数据。在该方法中,所有训练数据都是正常的。因此,理论上可以将半径定义为训练数据特征与超球中心之间的最大距离。然而,在训练集中也有一些正态样本偏离了大多数正态数据。选择R*的最大距离可能不合适,会导致故障检测性能不佳。文中考虑到这种情况,并在精度和半径之间进行权衡。因此,将半径定义为所有训练实例的异常分数(数据特征与中心之间的距离)的第98百分位。如果异常分数大于半径,则认为该实例异常。
3 实验研究
为了证明所提方法在轴承故障检测中的有效性,使用一组全生命周期轴承实验数据集进行验证。
3.1 实验设置
3.1.1 IMS轴承数据集
该数据集由美国辛辛那提大学NSF I/UCR智能维护系统中心支持,被广泛应用于机械状态监测的研究[18]。实验系统如图5所示,Rexnord ZA-2115双列轴承安装在轴上,交流电机耦合轴通过摩擦带保持旋转速度在2 000 r/min,弹簧机构施加到轴和轴承上径向载荷为6 000 N,采样频率设置为20 000 Hz。数据包中包含3个数据集,此实验中以第2个数据集为代表进行分析。此数据集为20 480个数据点采集长度的振动信号,记录间隔为10 min,在轴承寿命期内共存储984个样本。在失效实验结束时,轴承1发生外齿圈失效。

图5 IMS实验系统
3.1.2 数据处理
数据集分为训练集和测试集。训练集只包含正常样本,推荐的正常样本数量约为所有正常样本的75%。由于实际工业故障检测所使用的监测数据既包括正常样本,也包括故障样本,因此在测试集中适当添加少量正常样本。所有振动信号都以同样的方式进行预处理。因为时频域的信号比时域的信号对故障更敏感,所以对每一个原始振动信号进行短时傅里叶变换(Short-Time Fourier Transform,STFT)算法处理。为了减少网络的计算时间,每个样本通过滑窗取得4 096个点,采用STFT算法将振动信号变换为64×64的时频域信号。对于IMS数据集前400个正常样本作为训练集,其余584个样本作为测试集。
3.1.3 模型构建
文中实验软件、硬件环境如表1所示。

表1 实验软件、硬件环境
深度SVDD-CVAE的模型参数如表2所示。

表2 深度SVDD-CVAE的模型参数
3.1.4 评价指标
故障检测可以简单理解为二元分类。对其结果的正确预测有2种可能:本来正确的预测本身就是正确的(TP),本来错误的预测本身就是错误的(TN)。对于结果产生的错误也有2种可能:最初正确的预测随后就是错误的(FN),而最初错误的预测在其他方面则是正确的(FP)。这4种可能性构成了二元分类模型的4个基本要素。为了评价所提方法和比较方法的性能,选择常用的指标:精确度、准确度、召回率、F1、AUC,作为故障检测任务的标准指标[19]。各指标定义如下式:
(21)
(22)
(23)
(24)
受试者工作特征曲线(Receiver Operating Characteristic,ROC)主要关注2个指标:真阳性率(TPR)和假阳性率(FPR)。在ROC空间中,横坐标为FPR,纵坐标为TPR。
(25)
(26)
在故障检测领域中,需设置一个阈值将实例分为正类或负类。因此,可以改变阈值,并根据分类结果计算出ROC空间中相应的点。ROC曲线可以很直观地表达分类器的性能,而且易于使用。曲线下面积(Area Under Curve,AUC)是ROC曲线下面积的大小。一般AUC值在0.5~1.0之间,AUC越大,性能越好。
3.2 实验分析
IMS数据集的异常评分变化趋势可用于反映轴承退化趋势,在轴承运行的早期阶段,即健康状态下,异常值始终保持在一个相对稳定的范围内。随着运行时间的延长,IMS轴承的异常评分在5 320 min时开始超过设置的阈值,而且当轴承开始退化时,随着振动的加剧,异常评分显著增加。相应的故障起始点可以很好地指示退化时间,也可以作为剩余寿命预测的第一个预测时间。
各方法的异常评分如图6所示。AE模型的异常评分虽然也具有一定的退化趋势,但是整体的变化幅度比较大,模型精度较低,误判率高;虽然VAE-LSTM模型精度有所提升,但是整体的变化幅度比较大,没有很好地反映整体退化趋势;SVDD-VAE对于轴承开始出现退化的时间节点有着一定的敏感度,但是由于在重参数阶段加入了一定的噪声,使得模型精度降低,误判率高。而文中方法对于轴承开始出现退化的时间节点有着更强的敏感度,很好地反映了轴承的退化趋势,模型的精度更高。
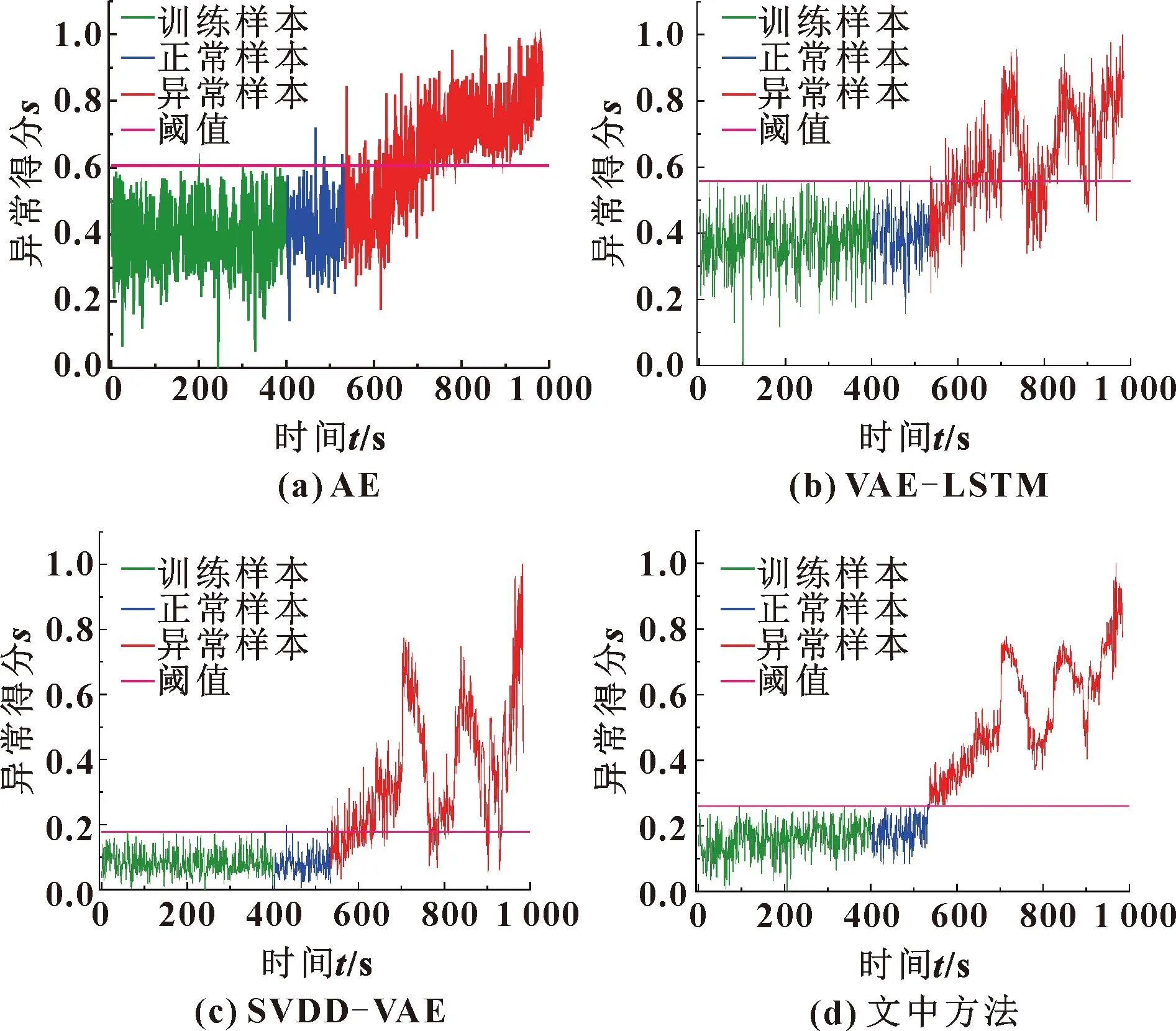
图6 各方法IMS数据异常评分曲线
根据分类结果和标签的比较,计算出Accuracy、Precision score、Recall score、Fl score和Accuracy score,可用于定量描述不同方法的性能。各方法的评价指标见表3。所提出的方法在故障检测上表现出良好的性能,准确率为0.976 6,说明错分类样本很少,该方法的综合指标AUC得分达到0.998 5。在所有方法中最大。
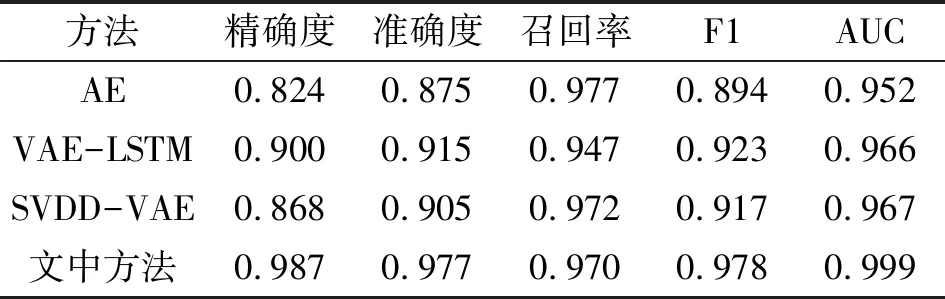
表3 各方法的性能评价指标
在第1、3个数据集上也进行了同样的实验,由于第1、3数据集包含了更多的噪声,所以诊断准确率略微下降,分别为0.942 8、0.936 7。
4 结论
为解决滚动轴承故障信号匮乏和故障阈值自适应困难的问题,文中提出一种基于深度SVDD-CVAE的轴承自适应阈值故障检测方法。与现有方法相比,该方法的优点如下:
(1)构建ConvLSTM作为基础单元的CVAE特征压缩提取框架,有效地提取轴承故障微弱特征,提高了对轴承微弱故障的敏感度。
(2)将故障检测模块与模型优化进行联合设计,实现了轴承故障检测中自适应阈值的确定,并取得了更高的检测准确率。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22 06:39:32
哈尔滨轴承(2022年1期)2022-05-23 13:13:24
哈尔滨轴承(2021年2期)2021-08-12 06:11:46
哈尔滨轴承(2021年1期)2021-07-21 05:43:16
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
河北遥感(2017年2期)2017-08-07 14:49:00
电子设计工程(2017年20期)2017-02-10 03:39:29
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
