
曲线吻合度算法在高层住宅小区庭院管道漏损控制中的应用
2024-05-06 06:30田泽辉李立宏
净水技术 2024年4期
田泽辉,李立宏,王 瑾
(唐山市自来水有限公司,河北唐山 063000)
城镇化建设的快速推进带动二次供水设施建设持续发展。 二次供水系统是连接水司和用户水龙头之间的“最后一公里”,是城镇供水系统中的重要环节之一,而“最后一公里”的庭院管网漏损往往被水司、物业所忽视。 由于供水管网普遍深埋地下,难以及时发现渗漏,使得管网渗漏成为国内外供水行业普遍面临的问题[1],不仅造成水资源浪费和经济损失,还会引起管网压力降低、水质二次污染、地面塌陷等次生灾害,严重威胁供水安全和公共安全。
水是人类赖以生存和从事生产不可缺少的宝贵资源,供水企业应采取措施,控制管网漏损,提高供水效率,达到节约水资源的目的。 针对如何利用现有的技术手段来降低高层住宅小区庭院管网漏损,本文依托某水司二次供水监控平台采集的海量数据资源,提出利用曲线吻合度算法预判管网漏点的解决方案。
1 管网漏损的主要原因以及影响
1.1 管网漏损的主要原因
(1) 供水管网老化,管材质量不佳,附属设施腐蚀严重,采用易腐蚀的管材材质容易引发后期漏损。铸铁管由于强度低、易腐蚀,加上接口易渗漏,最容易引发漏损现象[2]。
(2) 施工质量不高,也是造成管道漏水的直接原因,主要是管道接口处刚性太强,发生不均匀沉降时,管道易产生环向断裂或大头处挠断而造成大的漏损;管道基础承载力不够,当土壤发生不均匀沉降时造成管道接口漏损;管道接口质量不好,安装完成后通水即有渗漏。
(3) 管道内壁防腐不均匀,受腐蚀后会直接影响输水能力和水质,造成管道强度降低,易发生爆管现象。 外壁防腐不彻底,遇到污水等带有侵蚀的情况,易造成腐蚀,形成漏损现象。
(4) 局部管道埋深不够,造成管网不均匀沉降,导致断裂,形成漏损。
1.2 管网漏损造成的影响
(1) 造成水资源浪费。 我国住房和城乡建设部发布的《2021 年城乡建设统计年鉴》[3]显示,2020年全国供水总量约为630.8 亿m3,漏损水量约为80.4 亿m3,全国平均漏损率约为12.7%。
(2) 造成能源浪费和经济损失。 我国供水管网大部分采用加压系统输送到企业各个装置,漏水相当于漏能,每年漏损导致的电能消耗约10 亿kW·h,由此还产生了大量无效的碳排放。
(3) 导致水质污染。 漏水意味着管道不再是封闭的系统,管道内压力低的时候、停水的时候,管道外的污染会进入管道,特殊情况下的射吸现象也会产生对管道内水的污染。
(4) 导致路面塌陷。 管道漏水会使土壤具有流动性,遇到附近有排水管道,土壤不断流失,地面下形成空洞,空洞变大,地面就会塌陷。
(5) 导致地下水位上升。 有供水管网覆盖的区域,地下水位因为管道持续漏水而变高,冬季地面冻胀也和地下水位有直接关系。
2 漏损预测的大数据基础支持
本文所说的高层住宅小区庭院管网特指主街/主路管网的市政管网分支到具有二次供水小区内的管网。 庭院管网的管线数量、管线总长度、复杂程度和维护成本都很高。 按照独立计量区域(DMA)分级分区的思路,一个高层住宅小区即为一个最小分区。 高层住宅小区庭院管网的数量至少有1 条市政管线,1 条甚至多条加压管线。 目前,有的小区最多有7 条加压管线。 DMA 分区漏损控制方法虽然能预判小区内存在漏点,但不能准确定位到哪根管线有漏点,给测漏工作造成很大麻烦。 同时,增加人员劳动强度,降低工作效率。 此外,为了提高测漏的准确性,一般要在晚上23:00—次日5:00 进行测漏作业,加之其方法还要结合营收数据。 因此,营收数据的滞后性,也会导致管网漏失量增加。 管网明漏一般流量都很大,漏失容易被发现,对周边环境及用户产生较大影响,处理起来很快,漏失持续时间不是很长。 暗漏可以被检测到但不宜察觉,漏失量中等水平。 暗漏的持续时间取决于主动测漏、解决漏损措施的积极性及强度,持续几天、几个月、甚至一两年都有可能的。 由此来看,在不改变现有DMA 分区管理的前提下,深度挖掘二次供水泵房的监控数据,能及时准确发现管线漏点,快速处理,从一定程度上降低高层住宅小区庭院管网漏损,节约水电能耗。
“统建统管”二次供水模式的推进,加快了老旧二次供水设施改造步伐,拓展了中高端二次供水设施需求空间,催生了二次供水集中管理平台需求。某水司为了实现对二次供水泵房专业化、规范化的管理,积极推进二次供水远程监控中心的建设,同时制定了规范化的技术标准。 其中,必须采集的数据有电压、电流、有功功率、累计电能、水压、水量、频率等参数。 秒级采集、分钟存储的海量大数据,对分析判断庭院管网是否存在漏点提供了重要的数据支持。
3 基于二次移动平均法的管网暗漏预测
3.1 预测原理
3.1.1 二次移动平均法
二次移动平均法是对一次移动平均数再进行第二次移动平均,再以一次移动平均值和二次移动平均值为基础建立预测模型,计算预测值的方法。 这一方法解决了预测值滞后于实际观察值的矛盾,适用于时间序列,呈现线性趋势变化的预测。
二次移动平均法的数学计算如式(1)~式(5)[4]。
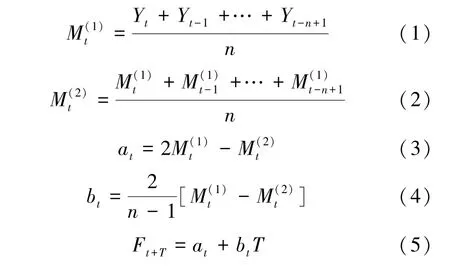
其中:Yt——第t期的观察值;

n——计算移动平均值的跨越期;
T——向未来预测的期数;
at——截距,即第t期现象的基础水平;
bt——斜率,即第t期现象的单位时间变化量;
Ft+T——第t+T期的预测值。
3.1.2 曲线吻合度算法
将预测数据做出以时间为横轴、预测值为纵轴的预测趋势曲线,与当日的实际测量值比较,将偏差率较高的数据记为异常数据,计算异常数据条数Na与日抽取数据记录条数Nt的比值,来判断实际测量值曲线与预测曲线的相似、相近的程度,Na/Nt的值越低,说明曲线吻合度越高。 偏差率、吻合度的计算如式(6)~式(7)。
其中:S——偏差率;
Vm——数据实测值;
Vp——数据预测值;
C——曲线吻合度。
3.2 预测数据抽取
3.2.1 预测数据的选定
在数据预测前需要合理选取某一阶段的历史监测数据,以便根据历史数据完成后续的预测工作,提高数据预测的准确性。
传统做法是采用DMA 分区分析漏点的方法,通过测算表的日累计流量、夜间瞬时小流量判断管网有没有漏点,但是此种方法不适合某水司统建统管的二次供水泵房。 某水司统建统管的每个泵房只在进水侧配置流量计,出水侧未配置流量计,无法实现单个加压供水区域的用水计量,即便通过进水侧流量计发现管网有漏水的异常数据,但对于多泵组的泵房并不能确定是哪个加压区漏水。 此外,采用“水箱+变频供水”方式的泵房,采集到的进水流量计数据是不连续的,只有在水箱进水时才会有瞬时流量。 如果在每个分区泵组出口增加水量计量仪表,不仅安装条件受限、投入成本高,且根据供水水量趋势,深夜用水量非常小,可能满足不了大口径流量计的最低流速要求,故选取流量计瞬时流量作为数据支撑不可取。 在既有的二次供水设备配置情况下,泵组有轮泵机制,泵组单泵电流、频率的数据不连续,都不适宜选取。
水泵电机轴功率P计算如式(8)。
其中:Q——泵的流量,m3/s;
ρ——泵输送液体的密度,kg/m3;
g——重力加速度,m/s2;
H——泵的扬程,m;
η——水泵效率。
推算出水泵有功功率的曲线与供水量的曲线相似,完全可以反应实际供水量的变化。 因此,选取可编程逻辑控制器(PLC)变频恒压控制柜PAC3200仪表采集到的有功功率参数值作为数据支撑。
3.2.2 预测数据采集的步骤
数据采集:数据采集与监视控制系统(SCADA)会将各二次加压泵房传感器或监测设备的有功功率实时数据,按照固定间隔频率传输到数据中心的前置数据库。
数据处理:数据中心端会通过定时作业调用相关存储过程,将接收到的实时数据按照“流量”“进站压力”“出站压力”“控制柜有功功率”等监测类型,进行分流转存到相关历史数据表或临时计算数据表。 每日00:00,定时作业会在“控制柜有功功率”历史数据表中将前1 d 00:00—24:00,固定间隔频率的数据与前8 d 的同时段的数据进行平均计算,将计算结果存入一次平移数据表。 一次平均计算完成后会对该结果按照相同的方式进行平均计算,将计算的结果存储到二次平移数据表。
基准值设定:将前1 d 的一次平移的结果数据与二次平移的结果数据通过固定公式进行计算生成当日预测基准值。
异常检测:将前1 d 各时段的有功功率数据与前1 d 的基准值进行比较,使用统计方法检测计算数据的偏差。
阈值设定:根据实际情况,通过设定的偏差阈值来判断是否存在泄露。 当有功功率超过设定的阈值时,可以判断为泄露。
报警机制:当有功功率超过设定的阈值时,触发报警机制。 可以通过数据库触发器、定时任务或者与其他系统的集成来实现报警功能。
3.3 预测实施方案
3.3.1 相关参数的选定
利用MATLAB 生成不同小区的供水历史数据散点图(图1 展示了4 个小区不同日期的历史数据)。 观察用水趋势发现,该地市的用水早高峰基本集中在6:00—9:00,晚高峰从19:00—22:00,两个高峰时段的持续时间共计6 h,占1 d 的25%,其余75%在低谷区。 由于用水高峰期的区间段居民的用水习惯随机性很强,数据的抖动很大,不能作为定性判断的依据;在低谷区间段用水比较平稳,而且在正常供水的前提下每天的相似非常高。 因此,设定吻合度<75%时判定庭院管网有漏水现象。 通过图1 很容易发现,散点密集区域在供水低谷区。 吻合度的设定值应依据当地用水趋势做相应的调整,如果用水低谷区间增加,则提高吻合度设定值;如果用水低谷区间减小,那么降低吻合度设定值。 原则参照用水趋势低谷区间的占比大小进行设定。结合高层供水恒压控制原理的约定,一个泵组至少有两台水泵,每台水泵的特性有所不同,工艺位置的不同以及水泵出口的止回阀微泄漏,都会造成在相同压力相同流量的情况下,能耗不同,这样就会对定性判断造成扰动。 在测试数据时发现,偏差率如果取值较大,对于大漏损量的定性判断准确,偏差率取值小可以实现小漏损量的定性判定,但是太小了又会造成误判。 经过多次测试约定偏差率≥20%比较合理,这个约定的数值可以根据实际供水状况修订。偏差率的设定可根据本地高层恒压供水控制原理的约定做相应的修订,影响偏差率设定的主要原因:轮换倒泵周期的设定、有无夜间保压休眠功能、泵组出口有无配置稳压罐。 轮换倒泵周期设定时间短(4 h 以内),具备夜间保压休眠功能,泵组出口未配置稳压罐,那么会造成不同特性的水泵切换次数增加、水泵频繁启停,水泵启动瞬间会增加能耗,突变数据的条数也会随之增加。 对于这样的控制原理适当增大偏差率的设定值;反之,水泵在1 d 之内运行平稳,突变数据的条数也会随之减少,那么就可以减小偏差率的设定值。 偏差率的设定值要适当,务求提高定性判断的准确性,尽量降低误判及漏判的次数。
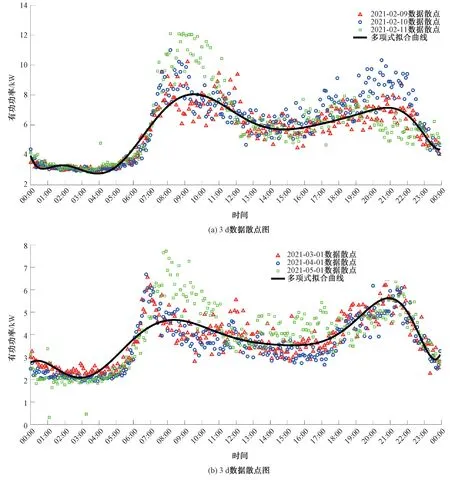
图1 利用MATLAB 生成供水历史数据散点图Fig.1 A Scatter Plot of Historical Water Supply Data Generated by MATLAB
选用A 小区2021 年2 月—6 月的113 d 的设备有功功率监测数据作为数据样本,已知此段时间内设备运行平稳、未出现漏失现象,取样周期为5 min,则每日抽取288 条数据记录,总计抽取32 544 条数据记录。 分别计算n取不同值时设备有功功率的预测值、偏差率、吻合度。
以n=3 为例,计算设备有功功率的预测值、偏差率、吻合度(表1),此时预测值比实际值滞后5 d,预测得到108 d 的数据,吻合度>75%的数据100条,占预测总数据的92.6%。

表1 A 小区2021 年2 月—6 月设备有功功率预测值(n=3)Tab.1 Prediction of Equipment Active Power in Community A during February to June in 2021 (n=3)
对比n取不同值时的预测数据(表2),由于已知取样时间内设备运行平稳、未出现漏失现象,那么认为吻合度>75%的预测数据为有效数据,有效数据率均达到90%以上,均能实现对漏损性质的判定。n取值越大,预测数据的滞后天数越长,则实施预测需要的历史数据越多。 考虑到计算机数据存储容量以及处理速度,在实际应用中取n=3。
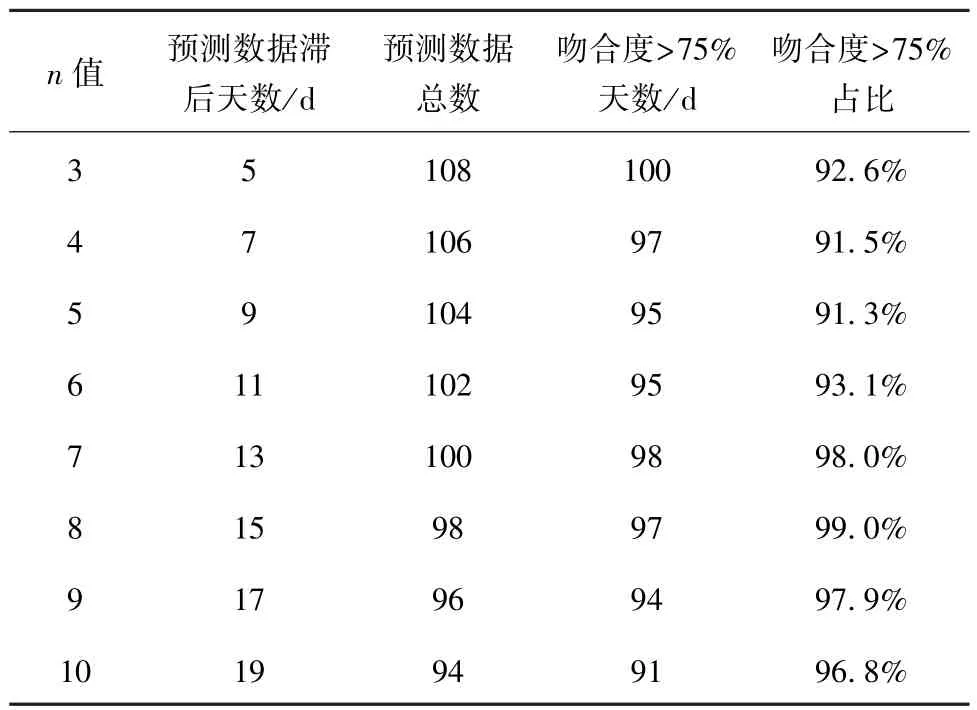
表2 不同n 取值预测数据对比Tab.2 Comparison of Prediction Data for Different n Values
3.3.2 预测庭院管网暗漏过程
以B 小区2021 年3 月的设备有功功率监测数据作为数据样本,取样周期为5 min,则每日共抽取288 条数据记录。
将历史数据库的数据记录导入Excel 表中,定义Y22,Y23,…,Y27分别为3 月22 日—27 日设备有功功率的实际监测值(表3)。

表3 B 小区2021 年3 月17 日—27 日设备有功功率实际监测值取样Tab.3 Sampling of Actual Monitoring Values of Active Power of Equipment in Community B during 17 to 27 March 2021
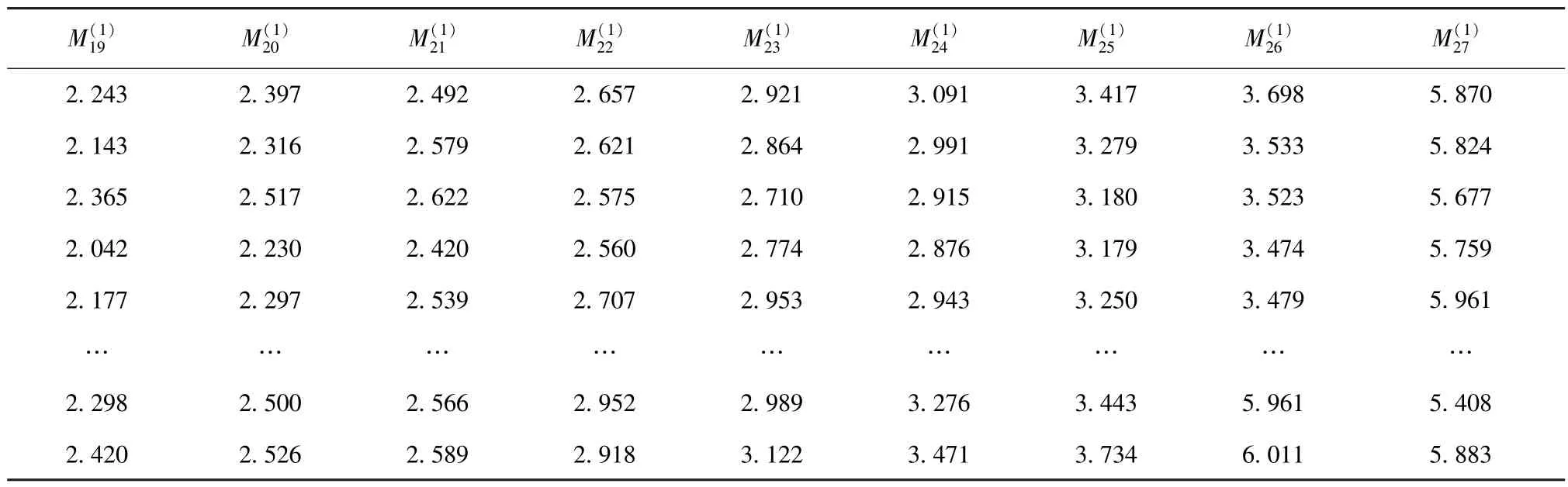
表4 设备有功功率的一次移动平均值Tab.4 First Moving Average of Equipment Active Power
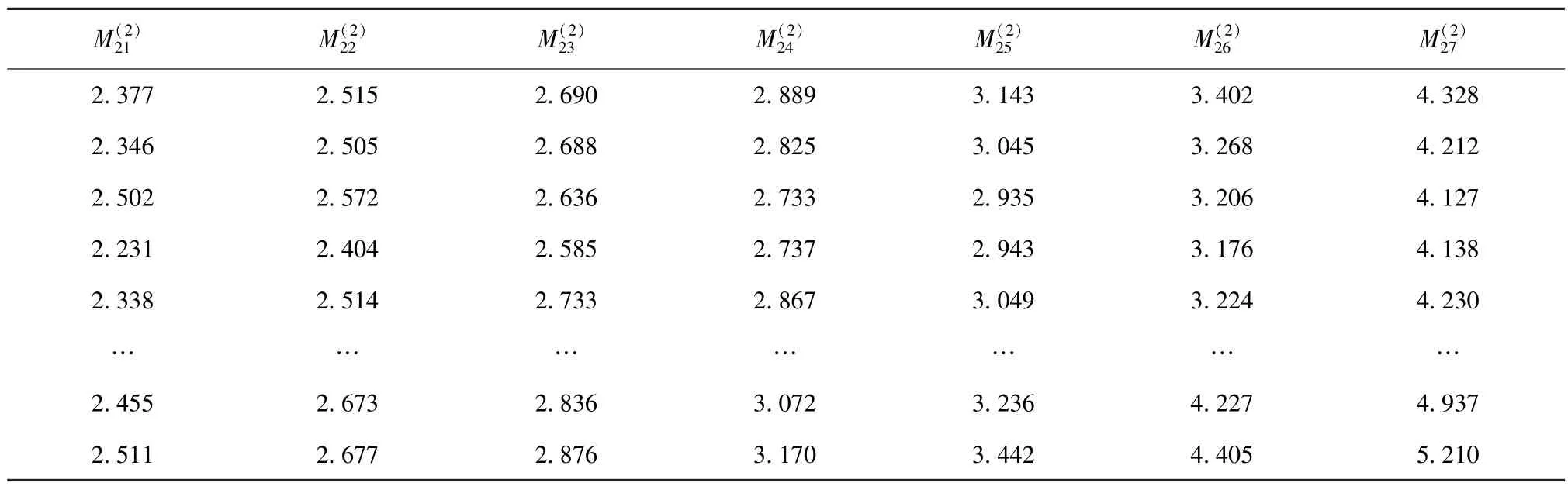
表5 设备有功功率的二次移动平均值Tab.5 Double Moving Average of Equipment Active Power

根据式(3)~式(5),计算3 月22 日—27 日设备有功功率的预测值F22,…,F27(表6)。

表6 设备有功功率的预测值Tab.6 Predicted Values of Equipment Active Power
根据式(6)、式(7),计算3 月22 日—27 日设备有功功率偏差率(表7),考虑供水量随季节、节假日会发生变化,取正向偏差率≥20%作为异常数据记录,吻合度<75%则判定庭院管网有漏水现象。
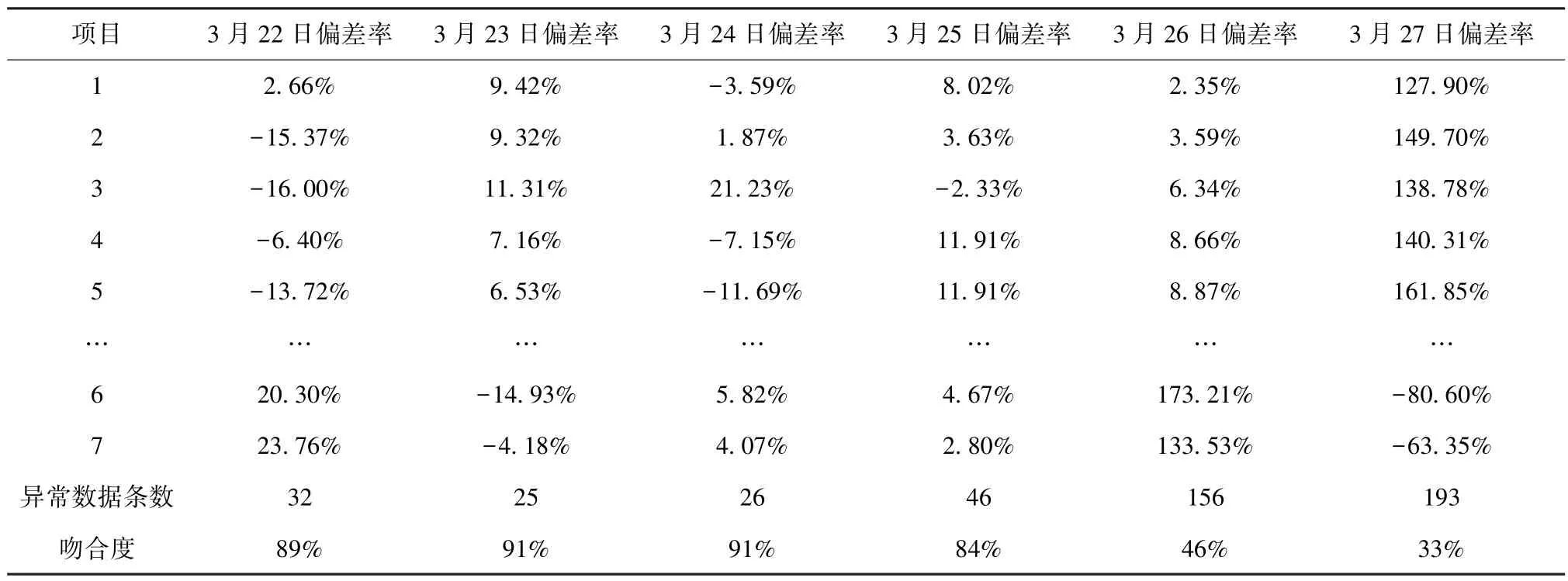
表7 设备有功功率曲线吻合度Tab.7 Curve-Fitting Degree of Equipment Active Power Curve
通过计算,3 月22 日—25 日设备有功功率曲线吻合度均>75%,判断供水量基本正常,稍有波动。3 月26 日设备有功功率曲线吻合度为46%,3 月27日设备有功功率曲线吻合度为33%,连续2 d 低于75%,可以判定加压管道有漏水点,结合进水流量历史数据,判断管网有暗漏的2 d,每天的进水量较以往增加47~50 t,计算平均漏失量在2 t/h 左右。

(续表6)
利用MATLAB 生成3 月22 日—27 日实测数据与预测数据的曲线图(图2),可以看出3 月22 日—25 日两条曲线基本重合,而从3 月26 日开始,实测数据曲线突然升高,说明当日开始出现漏水现象。此处漏点由于漏水量较小,又属于暗漏,不容易发现,先后经过几次测漏,于3 月28 日上午查找到漏点,DN100 管道的承插口处漏水。 受到前2 d 漏水数据的影响,漏水修复当日的预测数据偏高,因此,在漏点修复后再进行数据预测时,应当剔除漏水之日的数据,保证预测的准确性。
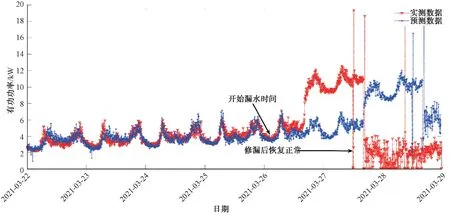
图2 实测数据与预测数据的对比曲线Fig.2 Comparison Curve Diagram of Measured Data and Predicted Data
3.3.3 成功预测管网暗漏案例
近两年来,笔者带领的团队已利用上述算法成功预判出50 多处管网暗漏,受篇幅所限,本文展示4 个成功预测管网暗漏的案例。
采用二次移动平均法计算出预测数据曲线吻合度(表8~表11),再利用MATLAB 生成实测数据与预测数据的对比曲线(图3~图6),可以直观判断出漏水现象,再通过及时采取查漏修复措施,有效降低了经济损失。
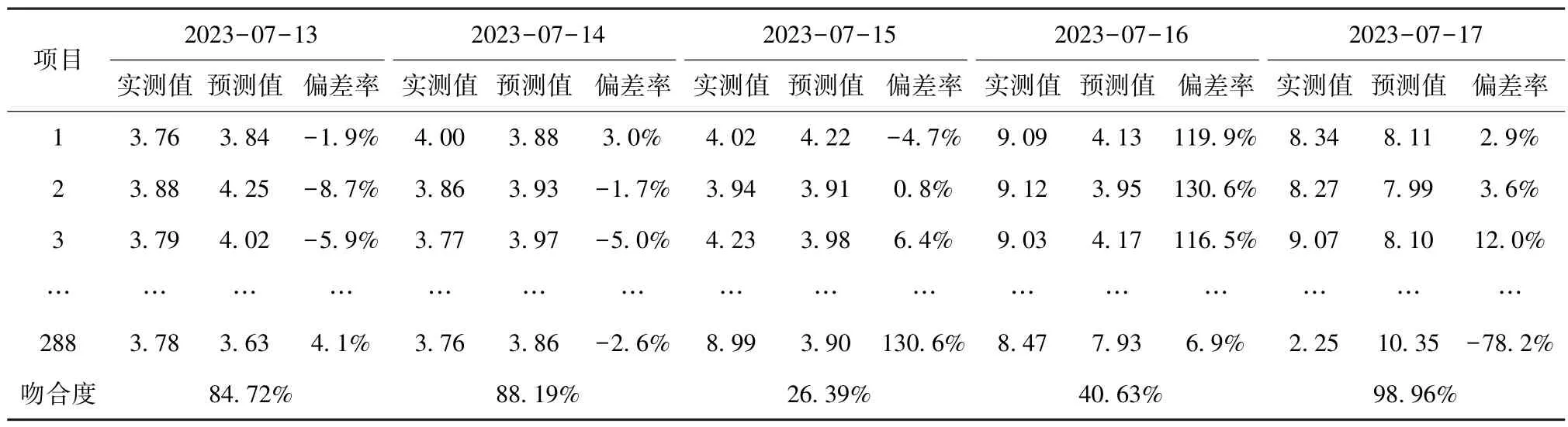
表8 a 小区2023 年7 月13 日—17 日设备有功功率曲线吻合度Tab.8 Curve-Fitting Degree of Equipment Active Power Curve in Community a during July 13 to July 17 in 2023
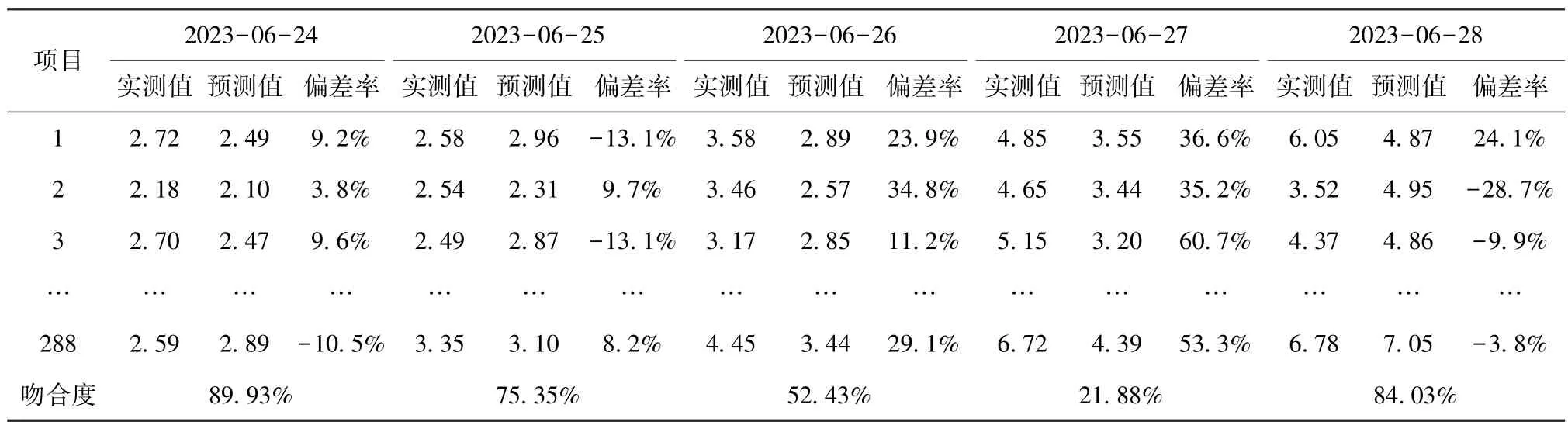
表9 b 小区2023 年6 月24 日—28 日设备有功功率曲线吻合度Tab.9 Curve Fitting Degree of Equipment Active Power Curve in Community b during June 24 to June 28 in 2023
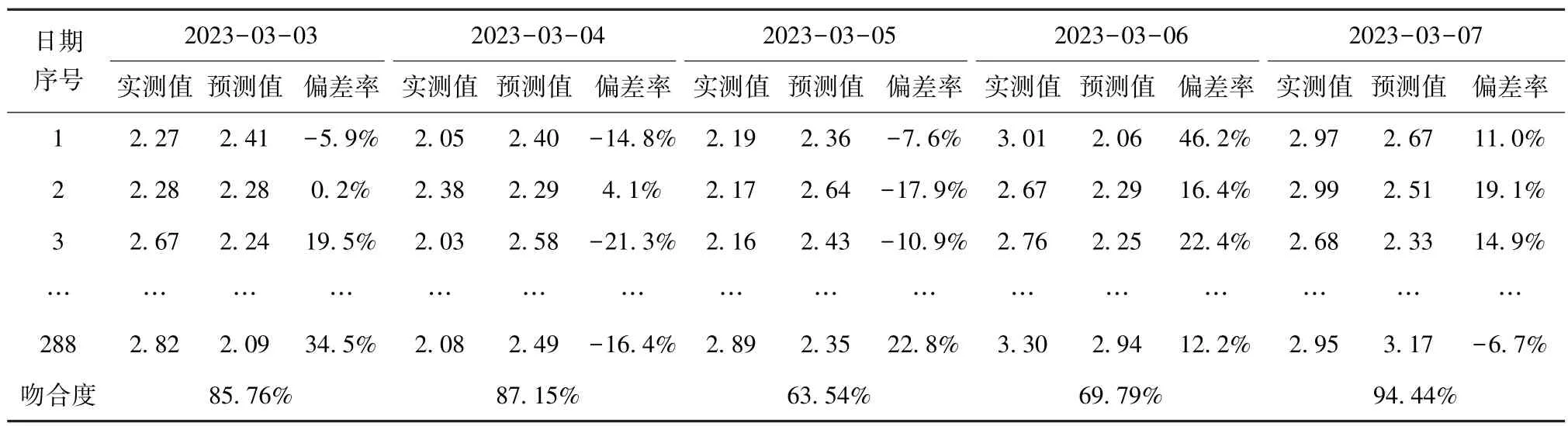
表10 c 小区2023 年3 月3 日—2023 年3 月7 日设备有功功率曲线吻合度Tab.10 Curve Fitting Degree of Equipment Active Power Curve in Community c during March 3 to March 7 in 2023
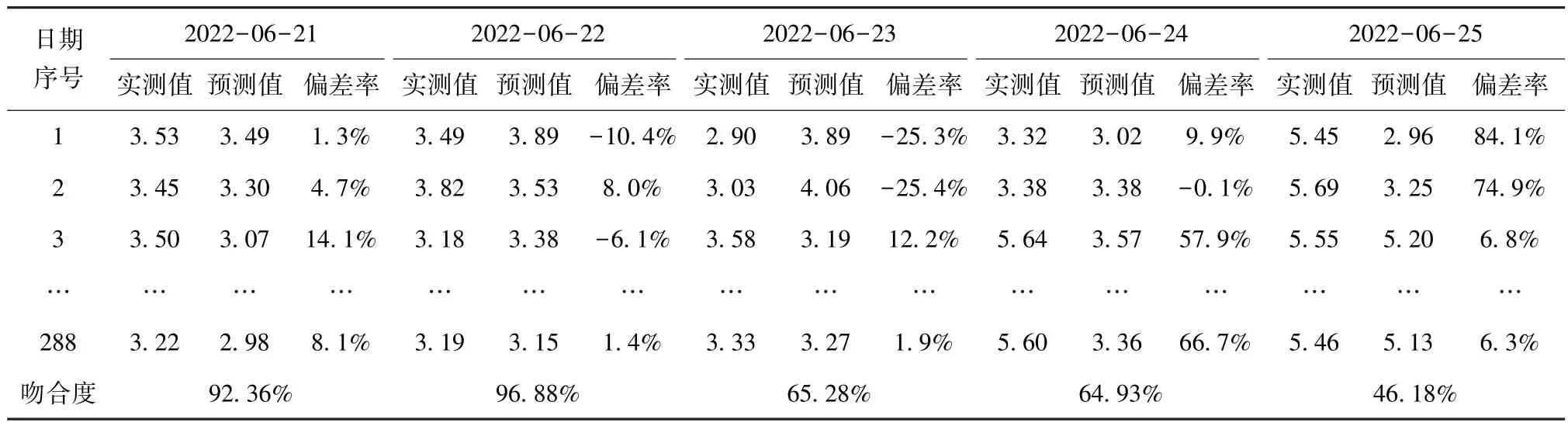
表11 d 小区2022 年6 月21 日—2022 年6 月25 日设备有功功率曲线吻合度Tab.11 Curve Fitting Degree of Equipment Active Power Curve in Community d during June 21 to June 25 in 2022
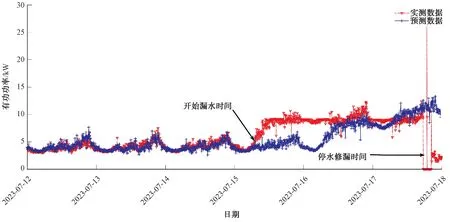
图3 a 小区实测数据与预测数据的对比曲线Fig.3 Comparison Curve of Measured Data and Predicted Data in Community a
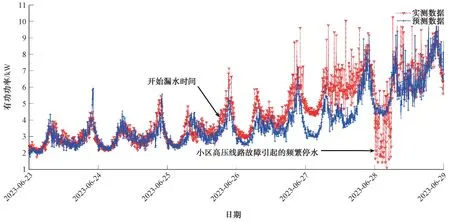
图4 b 小区实测数据与预测数据的对比曲线Fig.4 Comparison Curve of Measured Data and Predicted Data in Community b
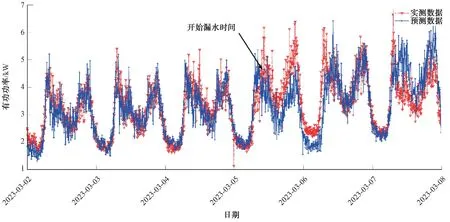
图5 c 小区实测数据与预测数据的对比曲线Fig.5 Comparison Curve of Measured Data and Predicted Data in Community c
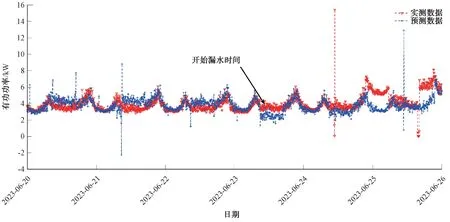
图6 d 小区实测数据与预测数据的对比曲线Fig.6 Comparison Curve of Measured Data and Predicted Data in Community d
4 结论
(1)曲线吻合度算法通过对数据进行合理计算、分析和预测,能有效识别加压管线暗漏,具有较高的准确性和实用性。
(2)该算法降低了水量计量器具的投入成本,将原本的被动探漏转变为主动探漏,实现了精准的漏水定位。 这不仅显著降低了管网漏损率,还为供水企业节约了大量水电能耗,确保了居民的用水安全。
(3)曲线吻合度算法为供水漏损控制领域提供了新的研究思路,应用数据同化,将有功功率转化为供水量的一个同化参数,数据稳定且便于采集。
(4)尽管曲线吻合度算法在预测高层住宅小区庭院管网的漏点方面表现出了高准确性,但目前仍存在滞后严重的问题,从预警到实际确认至少需要3 d 的数据。 未来研究可以在此基础上,进一步扩展数据来源,整合水司的其他业务数据,以提高判断的准确性和及时性。
猜你喜欢
石油化工建设(2019年4期)2019-10-10
石油钻采工艺(2019年3期)2019-09-25
作文周刊·小学一年级版(2019年44期)2019-01-08
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
电子测试(2018年1期)2018-04-18
中国建筑防水·悦居(2017年7期)2017-09-07
中国公路(2017年8期)2017-07-21
小学生导刊(2017年16期)2017-06-15
