
重载铁路列车障碍物检测研究
2024-05-01 14:57张东涛
铁路通信信号工程技术 2024年4期
张东涛
(国能新朔铁路有限责任公司,呼和浩特 010300)
1 概述
从列车行车方面来看,异物入侵是影响其安全的一项重要因素。铁路覆盖区域跨度大,沿线地形地貌复杂多变,部分线路没有布置于高架桥上且没有铁丝网防护,周围人员和动物活动频繁、两侧树木生长茂盛时均有可能入侵轨行区,总体运营环境复杂,所以对于轨行区异物入侵检测的需求较大。由自然灾害引起的泥石流覆盖轨道等,国内外均有事故发生。列车一旦在运行中与障碍物发生碰撞,将会带来严重后果,研究障碍物检测技术具有重要意义。另外,货运铁路通常存在运力紧张、作业繁忙等问题,加上货物装卸、巡检等作业人员较多,容易发生工作人员误入线路的情况。仅依靠司机瞭望检测轨行区障碍物这种传统方式存在以下缺点:1)在恶劣天气或光线昏暗时肉眼识别的可靠性低;2)受到生理机能限制,人眼远距离识别障碍物困难,难以预防或避免事故;3)检测结果受人员注意力是否集中等主观因素影响较大;4)人工瞭望的方式不适应全自动轨道交通的发展要求。通过增加障碍物探测装置可以有效避免列车与人员之间的碰撞事故,其能够实时检测线路上的障碍物,及时向司机发送警报,以便司机能够采取制动措施。
当前,关于列车自主障碍物检测技术的研究较多。有学者以激光雷达作为传感器,提出考虑激光反射强度的全自动运行列车障碍物检测方法,实现列车自主障碍物检测,但由于激光束沿直线传播,该方法在轨道弯曲区段应用效果差,导致最远探测距离只能达到80 ~100 m。张林等以小型障碍物作为目标,提出基于视觉和Faster RCNN(Faster Region Based CNN)网络的障碍物检测算法,融合FPN(Feature Pyramid Network)网络与Faster RCNN 原始网络,使小型障碍物的位置信息和语义信息融合,提高了对小型障碍物的辨识能力,但是无法避免基于视觉传感器的算法在雨、雪、雾和隧道等环境下检出率低的缺陷。综上所述,传感器本身固有的限制导致基于单一传感器的障碍物检测方法信息来源单一、检出率有限。多传感器融合的检测方法才能实现多源信息采集,许多学者开始研究基于多传感器的障碍物检测方法。赵宇恒分析了铁路环境的特点及各传感器性能,面向振动剧烈、检测目标信号难以区分和具有电磁噪声污染的高动态铁路环境提出毫米波雷达与激光雷达融合检测的方法,用毫米波雷达检测目标位置、速度信息,用激光雷达采集轨道限界信息,再进行时间配准和空间配准,以融合检测目标信息和轨道信息进行障碍物检测。鞠夕强在机动车的环境感知中提出基于毫米波雷达与双目视觉融合的方法,其中,在雷达数据处理方面采用基于DBSCAN 算法的自适应聚类算法提高毫米波雷达数据聚类效果,在多传感器融合处理方面,在进行时间配准、空间同步后采用了特征级与决策级结合的方法融合两种传感器的数据,最后经实验证明该方法的物体识别率优于单传感器检测,但是由于实验中使用的毫米波雷达不具备高度信息,视角仅为一个平面,对高处物体的检测能力弱,如会将高处的高架误检为障碍物。孙一珉研究了隧道内微光、封闭环境的障碍物检测,提出热成像仪与光学摄像机融合的方法,用时间戳配准方法和以世界坐标系为过渡坐标系的方式进行两个传感器数据时间、空间配准,采用基于IHS(Intensity、Hue、Saturation)技术和小波的融合方法,将热成像图像中物体温差特征与光学图像中物体色彩细节特征结合起来,提高隧道环境下对障碍物的辨识能力,但是由于热成像仪对远距离目标的成像效果差,所提方法难以满足对远距离障碍物检测的需求。综上所述,多传感器融合的方法虽然为障碍物检测提供了多源的信息,但是不合适的传感器也会限制整个系统的检测性能。
本文提出了一种基于激光雷达和视觉融合的障碍物检测系统(简称系统),结合了激光雷达测距、定位精度高且受光照、天气影响小的优势与高清像机能获取丰富环境、颜色信息的优势,实现精准、可靠识别轨行区障碍物。
2 研究方法
系统具有障碍物检测功能,利用视觉技术检测轨行区,辅以激光雷达点云数据,依托车载探测主机的深度学习算法,实施精准检测、主动预警,为列车运行提供主动安全保障。
系统结构如图1 所示,分别在机车两端车头安装激光雷达和高清像机。其中,像机选用长短焦结合的双目摄像机,内置1 台远焦摄像机和1 台近焦摄像机,能扩大图像采集范围,在隧道、高架等照度变化范围大的环境中,系统采取激光补光、滤镜等组合措施,确保采集视频质量,为障碍物辨识提供高质量基础数据。激光雷达(LiDAR),全称为激光探测和测距(Light Detection and Ranging),激光发射器向外发射激光,激光遇物体后反射,雷达接收器接收反射光线,由反射光线和发射光线可计算出反射点的相关信息,如距离和高度等。激光雷达采用半固态激光雷达,由于不具备旋转组件,能降低设备磨损消耗、降低硬件成本,且在个别光束阵元损坏的前提下,整个雷达仍可持续工作,提升了可靠性,符合轨道交通长寿命要求。
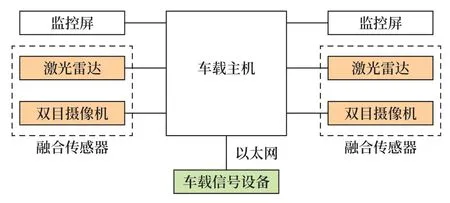
图1 系统结构Fig.1 System structure
3 视觉融合方法描述
分别进行基于视觉和激光点云的障碍物检测,再将检测结果后融合,如图2 所示,使两者互为校验,从而实现提高检测结果准确性和可靠性的目的。

图2 后融合流程Fig.2 Post-fusion flow chart
3.1 基于视觉的障碍物检测
基于视觉的障碍物检测流程如图3 所示。

图3 基于视觉的障碍物检测流程Fig.3 Vision-based obstacle detection flow chart
步骤如下:
1)图像预处理,包括提升运算速度的灰度化处理等。图像由像素点组成,由于每个像素点内均有R、G、B三个颜色分量,每个颜色分量的取值范围均为[0,255] ,因此每个像素点的颜色变换有1 670万余种,不便于后续计算。图像灰度化处理使图像像素点中的R、G、B三分量取相等值,则每个像素点的颜色变换只有在[0,255] 范围内的256 种,大大降低了计算量。本文用彩色图像中每个像素点R、G、B三分量的平均值作为其灰度值(Grayscale),如公式(1)所示。
2)通过Canny 边缘检测算法提取轨道线,结果如图4 所示。
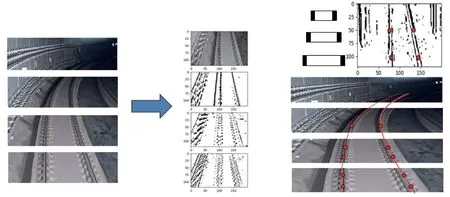
图4 轨行区提取Fig.4 Track area extraction
首先,应用高斯滤波去除图像噪声,减少噪声对图像边缘的干扰;其次,利用Sobel 算子计算图像像素梯度,得到图像中可能存在的边缘像素点,计算如公式(2)~(4)所示,其中I为图像像素矩阵,Gx为x方向像素梯度矩阵、Gy为y方向像素梯度矩阵,G与θ分别为梯度的幅度与方向;再次,应用非极大值抑制法去除非边缘的像素点:遍历图像像素点,根据梯度幅度是否为周围同梯度方向像素点中的最大值来判断是否抑制该点,即是否将该点归零,若该像素点是同梯度方向中的极大值,则保留该点,否则抑制该点;最后,应用双阈值的方法剔除可能存在的由噪声产生的边缘。
3)对图像进行二值化处理,将所有像素点的值设置为0 或255,此时图像变为黑白图像。再通过当前帧与背景帧的差分算法,检测出障碍物在图像上的位置。
4)深度学习提取障碍物特征,进一步计算障碍物的大小和距离。
3.2 基于激光点云的障碍物检测
基于激光点云的障碍物检测原理如图5 所示。

图5 基于激光点云的障碍物检测流程Fig.5 Flow chart of obstacle detection based on laser point cloud
步骤如下:
1)对点云数据进行预处理:因为在激光雷达采集数据的过程中,受到扫描环境、待测物及雷达自身的影响,点云数据中会存在一定噪点,需要进行数据清除或平滑等处理,以保证后续过程的准确性。
2)因为激光雷达采集的点云数据比较稀疏,所以叠加当前帧与前3 帧数据,并对叠加后的数据进行体素下采样,在保持点云形状特征基本不变、空间结构信息基本保留的情况下,减少点的数量,降低计算量。体素下采样原理如图6 所示,在空间上将采集到的点云数据网格化,也称体素化,得到的小格子称为体素,对各体素内的点取平均,用平均值来代替体素内原有点即完成体素下采样过程。体素化时选取的网格大小决定采样后得到的点云数据量,网格越大,则采样后获得点云数据量越少,计算速度越快,但对原先点云数据的还原度越低,因此需合理选择网格大小。

图6 体素下采样原理Fig.6 Schematic diagram of voxel downsampling
3)对采样后的点云数据进行截取,根据检测对象不同来决定截取数据的范围:在本文中暂定,检测列车前方是否有其他列车时,假设h为激光雷达的安装高度,以激光雷达的安装位置为坐标原点,截取高度范围在(-h+0.3 m,-h+5 m)内的点云数据,以减去高空数据和地面数据的干扰;检测轨行区是否有异物侵限时,同样以雷达位置作为坐标原点,截取宽度范围在(-1.5 m,1.5 m)的点云数据,因为在近距离范围内轨道弯曲程度不大,因此可近似将轨道视为两条直线,则轨道限界范围可视为固定值1.435 m,选择(-1.5 m,1.5 m)宽度范围作为固定范围。
4)通过K-means 算法对截取后的数据进行聚类,检测是否有异物侵限或前方是否有车辆。
3.3 后融合法
采用后融合法处理基于激光点云和基于视觉检测结果的融合,后融合是指各传感器根据各自算法得到结果,再将其融合。由于各传感器输出已经为目标输出,因此,后融合也称为目标级别融合。其优点在于:1)障碍物检测精度不低于最好的传感器,并能降低单传感器的漏检率或虚警率;2)系统鲁棒性强,可容错单传感器模块失效。在本文所提出的系统中,只有基于激光点云和基于视觉的检测算法均未检测到前方存在障碍物时才认为前方没有异物侵限,其余情况均给出告警信息,如表1 所示,其中,0 表示未检出障碍物,1 表示检测到障碍物。

表1 检测结果真值Tab.1 Test result truth value
4 实验验证
对系统功能进行验证实验:分别以人(170 cm)、行李箱(64 cm×41 cm×26 cm) 和反光三脚架(35 cm×43 cm)作为障碍物模型,分别在列车前方20 m、50 m、100 m、150 m 和200 m 处进行实验,3种障碍物检出率均达到100%。结果如表2 所示,该系统能有效、准确地检测出列车前方障碍物。
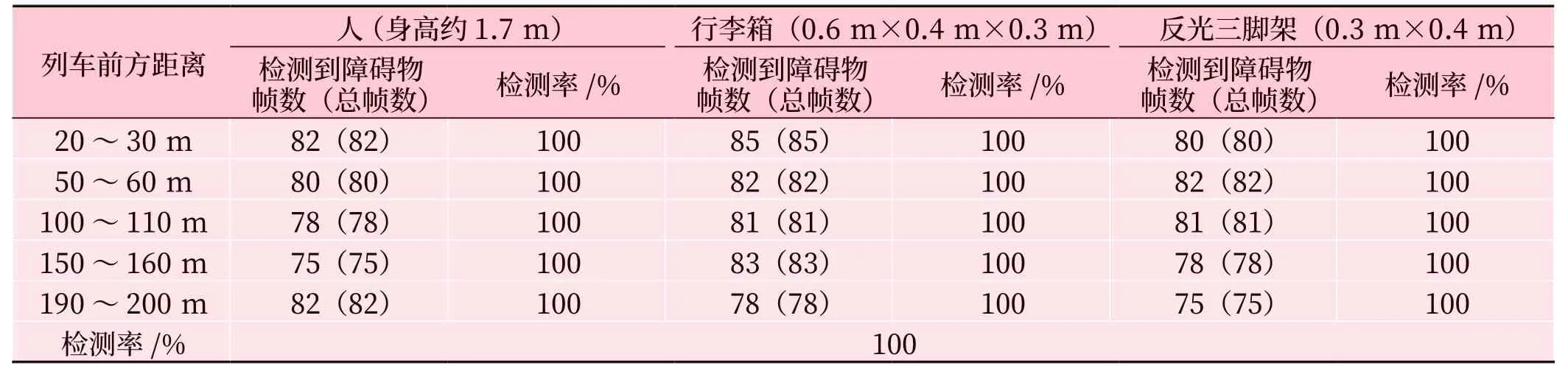
表2 不同障碍物在不同距离下的检测结果Tab.2 Detection results of different obstacles at different distances
5 实验数据分析
结合表2 的数据,可以大致获得以下4 类数据关系及结论。
1)障碍物类型与检测率的关系
对不同类型的障碍物具有很高的识别能力。人、行李箱和反光三脚架在所有距离范围内都被100%检测到。
2)距离与检测率的关系
在较远的距离上也能保持高检测率。在20 ~30 m、50 ~60 m、100 ~110 m 和150 ~160 m 的距离范围内,障碍物的检测率均为100%。但在190~200 m 的距离范围内,虽然人被检测到的帧数有所下降,但总体检测率仍然为100%。
3)检测到的帧数与总帧数
无论距离远近,人、行李箱和反光三脚架在大多数帧数中被检测到,能够实时、准确地检测到障碍物。
4)不同障碍物在同一距离内的比较
在20 ~30 m、50 ~60 m、100 ~110 m 和150~160 m 的距离范围内,人、行李箱和反光三脚架的检测率均为100%。这说明对于不同类型的障碍物检测性能是一致的。
在各种距离范围内都能保持高检测率,对不同类型的障碍物也有很好的识别能力。尤其在短距离上具有非常高的检测率,但在较远的距离上,如190 ~200 m,可能需要进一步提高检测精度。
6 结束语
本论文提出的雷达和视觉融合技术解决了单一技术的固有问题,为重载列车自主障碍物检测提供了方法,能替代传统人工瞭望检测方式,提高列车主动安全防护能力。由于目前检测距离受到商用传感器设备的性能限制,暂时只适用于列车低速运行下且制动距离短的场景。若应用于高速线,仍需要深入研究从而顺应全自动轨道交通系统的发展。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
北京测绘(2022年5期)2022-11-22
家庭医学(2022年3期)2022-04-07
汽车观察(2021年8期)2021-09-01
计算机集成制造系统(2020年4期)2020-05-08
中国惯性技术学报(2019年1期)2019-05-21
中国交通信息化(2019年1期)2019-03-26
上海大学学报(自然科学版)(2018年5期)2018-11-02
电子制作(2018年16期)2018-09-26
电脑知识与技术(2018年35期)2018-02-27
