
基于山区中小河流水文资料的洪水预测研究
——以贵州省威宁县为例
2024-04-29 14:21:20马祥
水利科技与经济 2024年4期
马 祥
(威宁县水务局,贵州 威宁 553100)
0 引 言
洪涝灾害的发生受多种因素影响。在保定地区,除了水利设施建设以及人为因素以外,暴雨气候和地形因素等条件也是洪水发生的原因之一[1]。因此,洪水灾害预警和河流径流量预测成为现阶段国内外学者的重点研究对象。陈忠虎[2]以莆田市涵江区为样本,研究了山洪灾害防治项目评价方法,并采用推理公式法进行了洪水评价方法的参数优化。张乾柱等[3]从地貌、高程、坡度、降雨及河网密度等因素方面,分析了重庆山洪灾害发生的空间分布规律,结果表明,重庆地区长江干支流沿线更容易发生洪水灾害,该试验可为重庆市的抗洪建设提供数据支持。周晏等[4]创新性地将智能视觉识别技术和山区洪水防治结合,利用时空特征学习方法和三维卷积神经网络,对山洪进行了视频监测。该方法识别检测快、精度性能高,为传统山洪预警方法进行了有效补充。
基于以上研究,本文通过GA算法优化的水文模型,进行山区中小河流洪水灾害预测,旨在通过径流量的计算模型优化以及威宁县兴隆河样本测试分析,验证模型的有效价值,为河流洪水灾害预警提供有效的技术支持。
1 基于LSTM的山区中小河流水文资料的洪水预测方法
1.1 威宁县水文条件分析及水文模型研究
季节性暴雨是我国南方山区洪水灾害发生的主要原因,周期性的水文条件变化对洪水防治问题提出新的挑战。为了对山区中小河流的洪水灾害进行预警,本次研究将基于河流水文条件和气象资料,对贵州省威宁县地区进行水文资料分析。在水文研究中,一般将长度小于10km、流域面积小于3 000km2的河流定义为中小河流。在山区中小河流流域内,季节性暴雨具有时空分布不均衡的特点。地形地貌特殊,降水时空分布复杂,可能因局地短时强降水引发山洪灾害。极端强降水可能引发滑坡、泥石流、小流域山洪、城市内涝等次生灾害。本次研究构建威宁县兴隆河水文模型,对河流洪水进行预测分析,同时采用长短期记忆网络(Long Short-Term Memory,LSTM)对模型进行优化[5]。首先对威宁县的水文条件和地理环境进行分析,见图1。
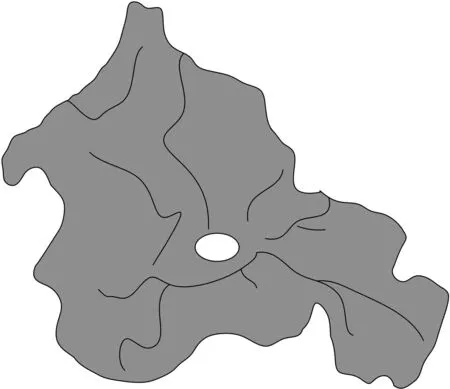
图1 威宁县水系图
图1中,线条表示河流水系,中间椭圆表示草海。由图1可知,威宁县内众多河湖交错,河流总长度1 031.1km,干流长368.5km。县内中小河流可分为四大水系,四大水系又由众多河流湖泊组成。其中,北盘江水系包括小可渡河、麻乍河、文昌河、冒水小河等河流;牛栏江水系包括哈喇河、安丹河、恰西河等河流;横江水系包括羊街河、三道河、兴隆河等河流;乌江水系包括拱桥河、文明小河、妥倮冲小河等河流。县内河网密度16.4km/km2,许多地处河湖地带的乡镇村寨都以河湖来命名,如草海镇由城西南部草海得名、二塘镇因二塘河贯穿其间而得名。
威宁县的气候特征属于亚热带季风性湿润气候,年日照时数1 812h,无霜期180天,年降雨量926mm,降雨集中在八九月份。特殊的地理环境和水文气候条件导致威宁县常常出现特大暴雨,因此也是贵州省的山洪多发地区。2014年8月10日开始,受持续强降雨影响,贵州省多地遭受暴雨洪涝灾害。截至12日14时,强降雨导致12人死亡、12人失踪,3.5万余人紧急转移安置。受灾最严重的习水、赤水、威宁等地交通、电力、通讯设施损毁严重,城镇发生不同程度的内涝。
本次研究借鉴新安江水文模型,构建威宁县兴隆河水文模型,同时从威宁县水务局收集相关水文降雨气象资料[6]。水文模型对于河流洪水的预测,依靠现代信息技术以及径流量计算的原理完成,而河流的水文条件模型表示和径流量计算,依靠流域内产流量和汇流量等参数的分析完成。本次研究构建的水文模型结构见图2。

图2 山区中小河流洪水预警水文模型
从图2可以看出,本次研究构建的模型中主要参数为产流量、降雨气候因素以及汇流量[7]。本次研究中,对于降雨气候的评估将采用误差值、相关系数进行评价,而在水文模型中,对于模型径流量的评估精度采用纳什效率系数(Nash-Sutcliffe efficiency coefficient,NSE)和相关性系数进行评价[8-9]。
1.2 LSTM山区洪水预测模型构建
根据水文模型的理论分析,以贵州威宁县兴隆河作为研究对象,构建水文气象参数模型。对于河流径流量的预测来完成洪水灾害预测的目标,可以看出是一个参数变化之后的时间序列问题[10]。因此,本次研究考虑通过优化的遗传算法(Genetic Algorithm,GA)来进行水文模型的优化处理[11]。水文模型的参数类别、具体参数及其含义见表1。

表1 威宁县兴隆河水文模型参数
从表1可以看出,对于山区中小河流水文模型的构建需要气象参数,其中降雨量和蒸发量决定了通过一个简化的降雨评级和蒸发量阈值进行判定。当河流流域内的降雨量为大且大于蒸发量阈值时,表明河流的径流量会急速增加。当降雨量为小且小于蒸发量阈值时,表示洪水灾害的风险较小[12]。产流量参数中,主要考虑的是透水面积和不透水面积的产流量,两个参数通过蓄水容量参数和蓄水容量曲线指数衡量[13]。汇流量参数分为地面径流、壤中流和地下径流3种,因此3种阶段的径流消退系数以及滞留时间决定了流域内的汇流量。
本次研究采用非支配排序遗传算法,进行多目标优化问题中的参数分析[14]。该算法的优势在于采用精英策略,将父代个体与子代个体合并后进行非支配排序,使得搜索空间变大,生成下一代父代种群时按顺序将优先级较高的个体选入,并在同级个体中采用拥挤度进行选择,保证优秀个体能够有更大的概率被保留。研究通过轮盘赌方式进行选择,同时利用交叉操作,模拟自然界中染色体的交叉换位现象,用于生成新个体,公式表示如下:
式中:p(1,x+1)、p(2,x+1)分别为交叉操作生成的第x+1代个体;α为均匀分布因子;p1,x、p2,x分别为两个新个体的父代个体。
同时,本次研究采用变异操作,是模拟生物的基因变异、丰富子代生产的方式,其表达式如下:
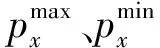
2 GA算法参数优化的水文模型在山区中小河流洪水预测中的应用分析
为了验证本次研究构建的GA参数优化水文模型在山区中小河流洪水灾害预测中具有实际应用价值,本次研究将贵州省威宁县兴隆河作为研究对象,同时选取2022年9月11日凌晨1时至12时的兴隆河径流量数据和流域气候资料进行分析。本次研究的数据来源于威宁县水务局。
本次研究构建的水文模型,经过GA算法参数优化,对比参数优化前后两个模型的相关性系数,见图3。由图3(a)可知,传统模型的相关性系数在提前一天的最高值为0.853,提前两天的预测结果相关性系数为0.703,提前三天的结果降为0.62。由图3(b)可知,优化模型的相关性系数在提前一天的预测结果中最高值为0.957,提前两天最高值为0.917,提前三天的预测结果中相关性系数为0.882。
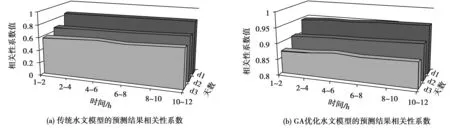
图3 传统水文模型和优化模型的预测相关性结果对比
本次研究对原水文模型和GA优化参数的水文模型进行性能对比分析,水文模型在优化前后的径流量预测能力是随着预测时间的提前而降低,见图4。由图4(a)可知,传统水文模型在提前一天的纳什效率系数最高为0.728,提前二天为0.492,提前三天降至0.337。由图4(b)可知,优化模型的纳什效率系数在提前一天的预测结果中最高值为0.915,提前两天最高值为0.832,提前三天预测纳什效率系数仍然保持在0.77的水平,表明传统耦合模型的稳定性不足。在不同时间段和预测提前量的基础上,本次研究提出的GA优化水文模型在性能中均高于传统模型。

图4 传统水文模型和GA优化模型的效率系数对比
本次研究将不同算法进行参数优化之后的水文模型进行径流量预测性能对比,见图5。从图5可以看出,威宁县兴隆河流域在2022年9月11日当天的河流径流量计算中,蚁群算法当天的预测误差处于[0.457m3/s,1.09 3m3/s]之间,24h内河流径流量预测数据的平均误差为0.851 2m3/s;粒子群算法当天的预测误差处于[0.297m3/s,1.071m3/s]之间,24h内河流径流量预测数据的平均误差为0.674 9m3/s;本次研究提出的GA算法优化模型预测的当天径流量误差处于[0.198m3/s,0.654m3/s]之间,24h内河流径流量预测数据的平均误差为0.436 1m3/s。研究表明,2022年9月11日当天的威宁县兴隆河流域在不同算法优化下,本次研究提出的GA水文优化模型误差较小,对于河流径流量的预测更精确。
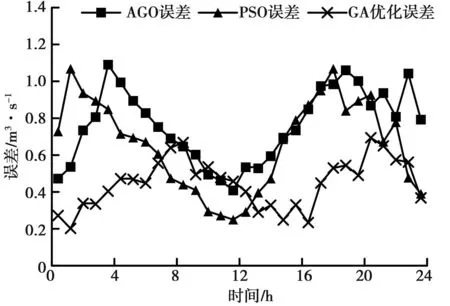
图5 不同参数优化算法的径流量预测误差对比
3 结 论
针对贵州山区暴雨天气中气象参数分布时空不均,导致传统模型径流量预测相应慢、误差大问题,本文研究构建了遗传算法参数优化的水文模型,用于威宁县兴隆河的径流量预测,并对威宁县兴隆河流域2022年9月11日的气象水文数据样本进行了分析。结果显示,本次研究构建的优化模型在降雨预测中相关性系数最高为0.957,而预测结果的最高效率系数为0.915。同时,模型预测当天径流量的误差处于[0.198m3/s,0.654m3/s]之间,24h内河流径流量预测数据的平均误差为0.436 1m3/s,误差小于其他优化算法。研究表明,本次研究构建的GA优化水文模型在威宁县兴隆河的洪水预测中性能优化,径流量预测误差小,相关性高,优于其他算法模型。
猜你喜欢
水资源开发与管理(2023年8期)2023-09-08 13:27:10
乡村地理(2020年4期)2020-09-10 07:22:44
河南水利年鉴(2020年0期)2020-06-09 05:43:48
河南水利年鉴(2020年0期)2020-06-09 05:43:30
水利规划与设计(2017年5期)2017-06-09 08:56:23
河南水利年鉴(2017年0期)2017-05-19 02:29:33
贵州科学(2016年5期)2016-11-29 01:25:37
晚晴(2015年7期)2015-05-30 16:57:06
水土保持通报(2014年5期)2014-06-09 08:27:00
长江蔬菜(2014年1期)2014-03-11 15:09:49
