
基于TD-Mask R-CNN的机械装配体图像实例分割*
2024-04-29 05:49唐若仪陈成军王金磊代成刚
组合机床与自动化加工技术 2024年4期
唐若仪,陈成军,王金磊,代成刚
(青岛理工大学机械与汽车工程学院,青岛 266520)
0 引言
近年来,个性化定制与柔性制造逐渐成为工业生产的重要发展趋势,不同类型的机械产品可以在同一条装配线上生产,这种生产模式导致了产品复杂性增加,使机械产品在装配监测过程中更容易产生人为错误,从而导致产品出现漏装、错装等问题。因此,更高效准确的获取装配过程中的零件信息具有重要的理论意义与时间价值。随着深度学习技术的大量涌现,计算机视觉技术逐渐应用于机械装配监测领域。严华等[1]提出了基于边界矩的零件图像轮廓提取方法,实现了机械零件的有效分类。田中可等[2]针对机械装配体识别、监测问题,提出一种基于深度图像和像素分类的零件识别方法,在装配监测和自动化装配领域有一定的研究价值。余永维等[3]提出了一种基于Inception-SSD框架的零件深度学习识别方法,兼顾了目标识别精度和检测时效性。薛珊等[4]提出了一种基于激光扫描三维点云的工件识别方法,有利于解决在流水线上识别机械工件类型困难的问题。
实例分割[5-6]是一个多任务架构网络,能够同时完成目标检测、图像分类与图像分割任务,目前实例分割方法大体可以分为双阶段方法和单阶段方法。双阶段方法是指在执行任务时,分阶段的执行目标检测和分割任务,如Faster R-CNN[7]、Mask R-CNN[8]、RefineMask[9]、Mask-Transfiner[10]等;单阶段方法能够并行的执行分割与目标检测任务,如YOLACT[11]、YOLACT++[12]、TensorMask[13]等。在装配监测领域,使用实例分割技术能够高效且准确的对机械装配体中每个零件进行识别与分割,对分割后的图像进行分析,可识别已装配的零件,同时有利于监测在装配过程中的漏装、错装、装配顺序错误等不规范操作。臧春华等[14]提出一种基于深度学习机器视觉检测的实例分割零件识别方法,通过在Mask R-CNN中使用Pointrend分割模块,提高对机械零件的分割精度。魏中雨等[15]提出一种基于机器视觉和深度神经网络的零件装配检测方法,通过Mask R-CNN网络对装配零件进行分类定位。朱新龙等[16]提出一种基于改进Mask R-CNN算法对堆叠汽车零件快速检测与实例分割的方法,实现对堆叠汽车零件准确的检测与分割。上述的实例分割方法对机械零件有着较高的定位精度,对单个零件有较高的分割精度,但机械装配体具有零件形态多样性和安装重叠的特点,上述方法仍不能对其达到良好的分割效果。因此本文提出一种适用于机械装配体图像实例分割方法TD-Mask R-CNN,其主要贡献为:
(1)在主干网络ResNet101中引入可变形卷积(deformable convolutional networks,DCN)[17],增加模型的泛化能力;
(2)使用Transfiner结构[10]作为掩码分支,引入离散余弦变化(discrete cosine transform,DCT)[18]模块,提高机械零件分割的精准度;
(3)建立了合成深度图像数据集与真实彩色图像数据集,验证本文方法对机械装配体图像分割的有效性。
1 机械装配体图像实例分割方法TD-Mask R-CNN
针对机械装配体图像实例分割问题,本文对Mask R-CNN网络模型进行了3点改进,提出了TD-Mask R-CNN,其网络结构如图1所示。
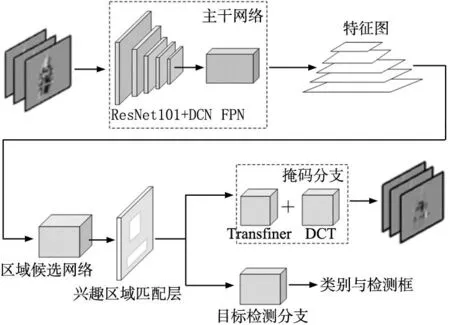
图1 TD-Mask R-CNN网络框架
(1)在使用ResNet101作为主干网络的基础上引入可变形卷积(DCN),更灵活有效的获取机械装配体图像的局部信息;
(2) 使用Transfiner结构作为掩码分支的主体,提高零件边缘部分的分割精度;
(3) 在Transfiner基础上引入DCT模块,对预测的低分辨率掩码进行高分辨率回归,提升模型对机械装配体的分割能力。
1.1 引入可变形卷积(DCN)
TD-Mask R-CNN采用ResNet101作为主干网络,ResNet101包含5个阶段Res1~Res5,将Res3、Res4、Res5阶段中的常规卷积替换为可变形卷积以提高主干网络提取特征的灵活性。
可变形卷积是指在常规卷积操作中的采样点位置添加一个二维偏移量来捕捉更丰富的特征信息,通过学习偏移变量,实现对目标几何特征自适应调整采样位置,不再局限于常规卷积规则的格点采样,可变换卷积的采样位置更符合机械零件本身的形状和尺寸,更有利于特征提取,图2展示了可变形卷积和常规卷积提取零件特征信息的方式。

图2 普通卷积和可变形卷积的区别
可变形卷积的计算是建立在常规卷积计算的基础上的,常规二维卷积计算一般分为两个步骤,首先,对特征图x使用规则网格M进行采样;然后,对采样的值进行加权求和。通过常规卷积得到的特征图y中任意位置p0,可以定义为:
(1)
式中:pn为采样网格中任意的采样位置,w为采样权重。常规的二维卷积固定了感受野的范围,所以限制了对目标物体几何变换建模的能力。可变形卷积则是在常规卷积的采样位置上添加了偏移量Δpn,{Δpn|n=1,2,…,N},其中N=|R|,使得在特征图上实现更灵活的采样,此时特征图的采样位置变为pn+Δpn,因此式(1)变为可变换卷积的计算过程:
(2)
式中:Δpn通常不是整数,为了有效地学习偏移量,一般采用双线性插值的方法来确定偏移后采样位置。根据可变形卷积的可偏移性,使得在提取特征的过程中可以根据减速器零件的形态进行动态调整采样位置,这种能够自适应确定零件形态的方法对机械装配体特征提取有较为重要的影响。
1.2 Transfiner掩码分支
TD-Mask R-CNN使用Transfiner结构代替Mask R-CNN网络中原有的掩码分支。其结构如图3所示,经过粗糙掩码头部网络预测得到的机械零件低分辨率掩码,传入信息损失区域检测结构,通过该结构计算得到容易出错且需要优化的机械零件边缘像素区域,结合多尺度特征,构建多层四叉树结构来表示多层级上不同的离散点,然后将这些离散点转为无序的像素序列,传入基于Transformer的细化网络,最后输出实例掩码。信息损失区域检测结构如图3a所示,将最低ROI层(28×28)特征和零件的低分辨率掩码作为输入,采用一个全卷积网络预测低分辨率的信息损失掩码,对该掩码做上采样处理,并与更高一层的ROI特征进行融合,然后使用单个1×1卷积层预测更精细的信息损失掩码。本文将最低ROI层检测到的信息损失点作为根节点,从上到下递归扩展4个子节点,构建了一个3层的四叉树结构,结构如图3b所示,通过该结构可以从更高层的特征图上选取子节点,获取更多的零件局部细节。
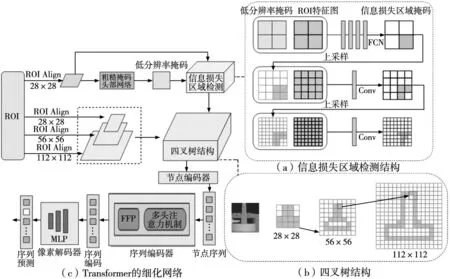
图3 Transfiner网络结构
基于Transformer的细化网络包含3部分,分别是节点编码器、序列编码器和像素解码器,其结构如图3c所示,首先,节点编码器丰富每个离散点的特征表示,补充点的位置编码和临近点局部细节信息;然后,序列编码器中会对输入的序列进行点之间的特征融合;最后,由两层MLP组成的像素解码器对每个节点的输出查询进行解码,以预测最终的实例标签。
1.3 引入离散余弦变换(DCT)模块
1.3.1 离散余弦变换(DCT)模块
在实例分割中,掩码看作为二值图像,大部分信息集中在少数低频分量上,DCT模块通过将高分辨率的二值掩码变换到频域并保留其低频的分量,实现高分辨率且复杂度的掩码表示。
Mask R-CNN网络模型使用28×28分辨率的二值网格预测掩码,但是该分辨率的二值网格不足以捕获详细特征,并且在上采样时容易出现偏差。提高二值网格的分辨率可以减少掩码重建误差,提高掩码的质量,但是将分辨率提高到128×128之后,掩码分支的输出大小从784增加到了16 384,使得训练复杂度大幅增加,导致网络分割能力下降,掩码平均精度(AP)显著降低。利用DCT模块将高分辨率的二值网格掩码编码成一个的紧凑的矢量,从而降低网络的训练复杂度,能够使网络得到高质量掩码的同时提高掩码平均精度。与PCA[19]和稀疏编码[20]不同的是,DCT的计算复杂度很低,在整个实例分割框架中可以忽略不计。
DCT与逆DCT(IDCT)编码方式如图4所示,Mgt表示二值真值掩码,Mgt∈RH×W,其中H和W表示高度和宽度,首先,利用双线性插值法将Mgt大小调整为固定的K×K,其中K×K为掩码的大小,在本文中设定K=112;然后,将MK×K转换到频域空间MDCT,MDCT表示为:
(3)

图4 DCT掩码表示
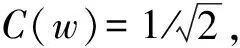
(4)
1.3.2 在Transfiner掩码分支引入离散
余弦变换(DCT)模块
本文在Transfiner掩码分支中的粗糙掩码头部网络之后引入DCT模块,该模块将低分辨率掩码进行高分辨率且低复杂度的掩码回归,进一步提高网络对机械装配体的分割精度。DCT模块结构如图5所示,首先,使用4个卷积核为3×3的卷积层来提取掩码特征;然后,使用3个全连接层回归DCT掩码向量,其中前两个全连接层输出大小为1024。最后一层的输出大小为300;最后,通过逆DCT回归高分辨率掩码。

图5 DCT模块在掩码分支的结构
引入DCT模块后,掩码分支损失函数表达式为:
Lmask=λ1Lrefine+λ2LIns+λ3Lcoarce+λ4LDCT
(5)
式中:Lrefine表示在信息损失区域节点的预测标签和真值之间的L1损失,LIns表示用于检测信息损失区域的二进制交叉熵损失,Lcoarce表示初始粗糙分割预测的损失,LDCT表示DCT模块分支的损失,λ{1,2,3,4}为超参数权重{1.0,1.0,0.5,1.0}。
2 实验与结果分析
2.1 实验数据集构建
由于目前没有公开的机械装配体实例分割数据集,因此本文基于减速器制作了2种类型的装配体数据集,分别为合成深度图像数据集和真实彩色图像数据集,制作流程如图6所示。制作合成深度图像数据集时,首先,使用RGB-D相机拍摄减速器装配体图像,根据图像利用建模软件建立减速器装配体三维模型,使用标注软件对模型中的每个零件进行不同颜色的标注;然后,利用数据集合成软件生成多个角度尺寸为256×256的合成深度图像和标签图像,使用标签图像获取每个零件实例的二值图像;最后,通过数据集生成程序生成用于实例分割的COCO格式数据集;制作真实彩色图像数据集时,首先,使用RGB-D相机拍摄多个角度的减速器装配体俯视图像,经过处理得到尺寸为512×512的真实彩色图像;然后,使用标注软件对图像中各零件实例进行标注得到标签图像,通过对真实彩色图像和标签图像进行旋转以增加图像的数量,使用标签图像获取每个零件实例的二值图像;最后,通过程序生成COCO格式数据集。利用本文的方法制作数据集,人工标注工作量较小,便于扩展到其他类型的机械装配体图像数据集制作中。

图6 减速器数据集制作流程图
本文根据减速器装配步骤在数据集中划分了几种不同的装配过程节点,如图7所示,真实彩色图像数据集中划分了为5个装配过程节点,每个节点都有360张图像,共1800张,按照6∶2∶2的比例划分数据集,其中1080张作为训练集,360张作为验证集,360张作为测试集;合成深度图像数据集中分为4个装配过程节点,前3个节点中每个节点为360张图像,第4个节点为619张,共1699张,只将第4个节点中的150张作为验证集,150张作为测试集。零件类别如图8所示,以合成深度图像数据集为例,2种数据集都包含12类减速器零件。

(a) 合成深度图像数据集
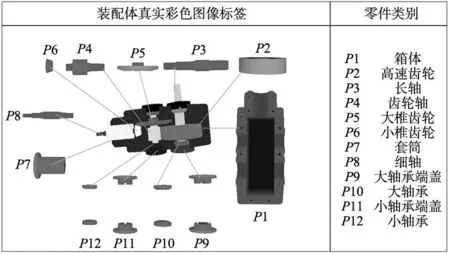
图8 减速器零件分类
2.2 实验平台与模型参数
本实验平台搭建在Ubunt18.04系统下,配置环境Python3.7+Pytorch1.7.1+CUDA10.1,硬件方面,使用1块GPU,型号为Tesla P40,CPU型号为Intel Xeon E5-2650 v4。本实验在Detectron2工具箱中已经实现,本实验所用的网络在数据集上训练9个循环 (epochs),每个循环迭代9000次,初始学习率设为0.02,每完成7000次迭代学习率衰减,衰减倍数为0.1。
2.3 评价指标
为了评估网络性能,本文采用了掩码平均精度(average precision,AP)作为模型检测的评价指标,平均精度能够全面的表达实例分割模型的性能。AP表示以召回率和准确率为横、纵坐标的P-R曲线所围成的面积。召回率、准确率和平均精度的计算公式为:
(6)
(7)

(8)
式中:TP为正确检测为正样本的个数,FP为误检为正样本的个数,FN为捡漏为正样本的个数。
2.4 实验结果分析
使用TD-Mask R-CNN对两种数据集进行了分割实验,实验结果如表1所示,在真实彩色图像数据集和合成深度图像数据集上,平均精度分别达到了92.0%和87.7%。

表1 两种数据集预测结果 (%)
为验证使用改进后的掩码分支能够有效提高网络模型的分割能力,TD-Mask R-CNN与其他主流的实例分割算法在相同测试集上进行对比实验。实验结果如表2和表3所示,使用合成深度图像数据集时,TD-Mask R-CNN相较于实例分割网络Mask R-CNN、TensorMask、RefineMask和Mask Transfiner,掩码平均精度分别提高了3.4%、8.3%、1.7%和0.2%;使用真实彩色图像数据集时,TD-Mask R-CNN相较于Mask R-CNN、TensorMask、RefineMask和Mask Transfiner,掩码平均精度分别提高了6.3%、5.4%、0.7%和0.5%。结果表明,使用改进后的掩码分支回归高分辨率掩码能对减速器装配体图像实现更准确的分割。图9和图10展示了部分网络对2种数据集实例分割的可视化图像。

表2 不同网络模型测试性能对比(合成深度图像数据集)(%)

表3 不同网络模型测试性能对比(真实彩色图像数据集)(%)

图9 不同网络模型在合成深度图像数据集上的分割效果

图10 不同网络模型在真实彩色图像数据集上的分割效果
为了验证在ResNet101主干网络中采用可变形卷积代替常规卷积能够提高网络分割能力,TD-Mask R-CNN使用5种不同的主干网络在两组数据集上进行实验。实验结果如表4和表5所示,在合成深度图像数据集和真实彩色图像数据集上,本文方法均能够达到最高的掩码平均精度,相比于没有引入可变形卷积的ResNet101,掩码平均精度分别提高了0.3%和0.9%。因此,在ResNet101中引入可变形卷积可提高网络模型对机械装配体图像的分割能力。

表4 本文提出的网络在不同主干网络下的测试性能对比(合成深度图像数据集) (%)

表5 本文提出的网络在不同主干网络下的测试性能对比(真实彩色图像数据集) (%)
以真实彩色图像数据集为例,表6展示了5种网络对于减速器装配体中每类零件分割掩码的平均精度,可以看出TD-Mask R-CNN对尺寸较小P11、P12和P8零件能够达更高的分割精度,因此TD-Mask R-CNN可能更适合对小目标分割。

表6 不同网络下各个零件的掩码平均精度 (AP/%)
3 结论
本文提出了一种机械装配体图像实例分割方法TD-Mask R-CNN,该网络在主干网络中使用可变形卷积替代了常规卷积,在掩码分支结构使用Transfiner结构作为主体并引入DCT模块进行优化。实验结果表明,在相同的环境配置下,无论是在合成深度图像数据集上还是在真实彩色图像数据集上,TD-Mask R-CNN在对装配体图像进行分割时均能到达更高的精度,同时有利于对小目标进行分割。未来将在保证分割精度的同时,进一步研究提高分割效率、增强算法实时性的方法。
猜你喜欢
电子制作(2019年16期)2019-09-27
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
自动化学报(2017年5期)2017-05-14
东北电力大学学报(2015年1期)2015-11-13
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电子设计工程(2014年18期)2014-02-27
