
面向摄像头视频监控的泥石流发生场景智能识别方法
2024-04-29 02:41胡美辰刘敦龙桑学佳张少杰
计算机与现代化 2024年3期
胡美辰,刘敦龙,桑学佳,张少杰,陈 乔
(1.成都信息工程大学软件工程学院,四川 成都 610225;2.四川省信息化应用支撑软件工程技术研究中心,四川 成都 610225;3.中国科学院水利部成都山地灾害与环境研究所,四川 成都 610041;4.中国科学院重庆绿色智能技术研究院,重庆 400714)
0 引 言
泥石流是一种常见且破坏性极强的山地灾害,具有突发性强和难以防御等特点,给山区人民造成了重大生命伤亡及财产损失[1-3]。据国家减灾网统计,2022 年中国发生滑坡、崩塌、泥石流等地质灾害共5659 起,以中小型为主,主要集中在中南、华南、西南等地,尤以西南为甚[4]。我国泥石流灾害量多面广,无法进行全面的工程治理。为了提高泥石流防御能力,建立科学的泥石流防灾减灾体系,泥石流监测预警技术受到工程界和学术界的广泛关注。
目前的泥石流监测预警技术,大多都是基于雨量、土壤含水率、次声、地声、泥水位、视频和断线等监测指标[5-9]来实现的。胡凯衡等人[10]以土体含水量为预警指标,建立了临界土体含水量与土体渗透系数、孔隙度和颗粒曲率系数的经验关系,提出了一种基于临界土体含水量和实时降雨的泥石流预警方法。周铭[11]分析了不同形态泥石流产生地声与次声的频率范围等特征,为后续进行泥石流地声与次声联合监测预警提供参考。Liu 等人[12-13]分析了泥石流次声与环境干扰次声的特征差异,通过特征参数阈值的方式研制了泥石流次声信号识别系统,大幅提高了次声预警准确率,并利用次声监测阵列与互相关时延估计算法建立了泥石流次声波源定位模型,结合GIS 技术实现了泥石流运动过程的实时跟踪定位。冯苍旭等人[14]通过图像采集卡把视频信号采入计算机中,用与该仪器配套的专门软件对采集到的光斑图像进行处理,计算出光斑的三维中心坐标值,把该值和原点坐标值进行比较,可算出灾害体移动的距离。钟晓清等人[15]采用实时视频网络监测系统观察地质灾害隐患点在汛期内的位移变化,若有异常则将发出警报。邓方雄等人[16]基于视频图像动态跟踪地质灾害目标,设计了一种地质灾害预警系统,能够有效监测滑坡、泥石流等地质灾害的发生,但对于设备的网络环境要求较高。
本文借鉴迁移学习的思想,对TSN(Temporal Segment Networks)模型[17]的底层网络架构进行修改,通过基于ImageNet 数据集和Kinetics-400 数据集的预训练,再结合大量地质灾害类视频(如泥石流、滑坡、崩塌)对模型进行训练和微调,得到更适用于泥石流识别的视频分类模型。该方法可以起到实时监测的作用,提高摄像头监控在泥石流监测预警中的有效性。
1 实验数据
本文采用多元化的数据来源进行地质灾害视频数据的收集与整理。第一类数据来源于互联网上通过关键词检索获取的地质灾害视频。这些视频资源丰富,覆盖了全球各地的不同地区、不同时间段以及不同类型的地质灾害事件,包括泥石流、滑坡、崩塌等地质灾害事件。这些视频片段为理解和分析地质灾害的发生场景提供了重要视角,为模型的训练提供了更加全面的数据基础。在视频筛选过程中,挑选出具有代表性和典型性的视频作为样本,这些视频能够真实反映地质灾害发生的状态和过程。第二类数据来源于沟道附近部署的泥石流监控摄像头。这些摄像头记录了地质灾害的实际运动轨迹和形态信息,对于理解和预测灾害的发展趋势具有重要价值,能够为模型的训练提供更加精准和可靠的数据支持。同时,采用了数据增强等手段来扩充数据集的规模和多样性,使模型训练更加充分,以便更好地应对实际应用中的各种情况。这一步骤不仅增加了数据数量,也丰富了数据多样性,使得模型能够更好地理解和处理各种复杂情况。
经整理分析,实验视频数据集分为泥石流、滑坡和崩塌以及非地质灾害3种类型。
1)泥石流视频数据。
泥石流是一种包含大量泥沙和石块的固液两相流体,其中的固相物质粒度分布比较广,通常呈粘性层流或稀性紊流等运动状态[18]。根据物质组成和颗粒物粒径大小,本文将收集到的泥石流视频划分为泥石流、水石流和泥流3 类,在视频中都可能呈现出快速流动、混浊和携带大量物质的特点,运动速度较快,短时间内可造成大规模破坏[19]。部分泥石流视频数据截图如图1所示。

图1 泥石流灾害视频数据示例
2)滑坡和崩塌视频数据。
滑坡和崩塌是2种常见的地质灾害现象。这2种现象通常是由于斜坡岩土体失稳而引起的,成因往往相互关联[20]。在自然作用(如降雨、地震等)或工程活动(如爆破、灌溉渗漏等)的影响下,斜坡岩土体重度增加和岩土软化,导致山坡或岩石等物质不稳定从而发生下滑现象。这种灾害的运动特征主要表现为碎石流、碎屑流、落石等[21]。它们在视频图像中的表现特征具有一定的相似性,故将这2 种地质灾害现象归为同一类视频进行分析。其视频数据截图如图2所示。

图2 滑坡和崩塌视频数据示例
3)非地质灾害视频数据。
除了收集地质灾害视频外,还收集了一些来自沟道和坡体的正常自然环境视频作为未发生地质灾害的样本集。这些视频内容同样也伴随着剧烈的动态变化,例如大风吹动或者湍急的河流等。图3 展示了非地质灾害视频数据的部分截图。

图3 非地质灾害视频数据示例
2 实验过程
2.1 数据预处理
在深度学习模型的应用中,对泥石流的识别任务需要依赖于大量准确和标记正确的视频数据。然而,当前的原始数据集并未针对地质灾害类视频进行优化,且部分视频同时包含了正常自然环境片段和地质灾害片段,这使得视频的内容过于复杂,无法通过单一标签进行有效的数据分类。针对上述问题,需要将对原始数据进行必要的清理与预处理。
1)分割视频场景。
由于使用的视频采集形式不统一,并不都是由专业设备拍摄采集。部分从网络下载的视频镜头是由非专业人员使用手机手持拍摄,导致镜头转换频繁,视频数据内容缺乏连贯性。为了解决这一问题,利用PySceneDetect工具进行镜头边界检测和视频修剪,将包含过多不同概念的复杂视频分割为短视频片段。首先将所有视频都以30 帧/s 的速率重新生成。统一帧速率可简化映射帧的计算与时间戳的关联,方便数据后续处理。PySceneDetect 提供了内容感知检测器和阈值检测器。阈值检测器采用最传统的场景检测算法,将当前帧的每个像素的强度(如平均RGB 值)与固定阈值进行比较,超过设定阈值时将触发分离事件[22]。在预处理阶段,使用以上方法获取2个连续帧之间的差异超过阈值的视频段,以此检测出视频突然的变化,达到分割视频内容的目的。
2)修剪视频。
在完成视频场景分割后,获得了时间长度不一的视频数据。利用ffmpeg 这一命令行软件来获取具有特定时长的分段视频片段。在处理过程中,保持视频数据的编解码器格式不变,并统一将文件格式设定为mp4。获得视频数据之后,需要将这些视频转化为适合迁移学习的Kinetics-400 数据集的格式,并对其进行剪裁,使其长度固定在约10 s。针对每个视频片段采用Kinetics 的标注方式,将每个样本从起始直至结束划分为不同的部分,每个部分分别对应一个类别。由于事先进行了视频场景分割,所以一个视频只代表着一个类别信息。此外,还将相应的标签信息和原始视频名称嵌入到每个视频片段的文件名中,以便能够准确定位原始视频并检查分类错误。剪裁后再对这些数据进行人工分类。最终,所获取的泥石流灾害视频、滑坡或崩塌视频以及正常自然环境视频的数量分别为432、73、197。
3)数据增强。
为了丰富视频数据并提高模型对泥石流场景识别的准确性,在视频处理过程中采用数据增强技术,对视频进行随机裁剪和50%概率的水平方向的随机翻转,从而提升数据量并丰富数据多样性。预处理结束之后,每个视频片段被标记为具有相同的语义概念。最终得到泥石流、滑坡和崩塌以及正常自然环境视频的视频数量分别为864、146、394。
2.2 模型构建
在基于深度学习的视频分类方法中,Simonyan等人[23]提出的双流神经网络,它由空间流网络和时间流网络组成,为输入的视频建立基于时间序列的特征提取和分类网络结构,可以分别提取视频的空间和时间信息,从而有效地处理多帧视频数据,并基于特征对视频分类。本文参考双流神经网络和TSN 模型[17]的框架构建泥石流场景识别模型。其模型结构如图4所示。
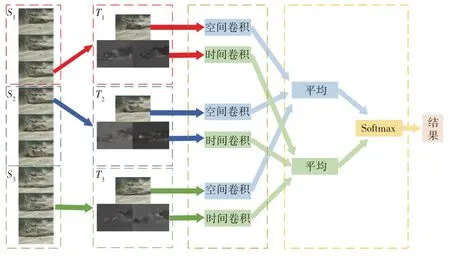
图4 TSN模型架构
具体而言,对于给定的视频V,将其平均地划分为长度相等的K个视频段{S1,S2,…,SK},并从每个视频段SK中随机抽取一个片段TK,此时得到一个子片段序列(T1,T2,…,TK),TSN将通过以下方式对这一系列子片段序列进行建模:
式中,F(TK;W)表示以W为参数的卷积网络函数,它提取片段TK的特征向量,并生成类别分数。G为分段共识函数,它将所有的子片段的得分求平均。H为Softmax 函数,得到输入视频样本被分类到的每一类视频的概率,概率最高的类别就是本段视频所属的类别,即:
根据标准分类交叉熵损失函数,得到分段共识函数G(F(T1;W),F(T2;W),…,F(TK;W))的最终损失函数为:
式中,C是视频类型数,yi是关于类i的基真标签,g函数为均值函数,Gj是G的第j维,可推导出损失值L相对于模型参数W的梯度为:
式中,K为视频的分段数,使用随机梯度下降(Stochastic Gradient Descent,SGD)优化方法来更新参数W。
视频具有空域信息与时间信息,而优秀的视频分类模型能够检索更多离散的空间特征和时间特征。文献[24]的研究结果表明,更深层次的卷积神经网络模型可以提取离散特征,有利于模型在视频中学习到更多特征。然而,过多的卷积层不仅会导致模型训练时间变长,模型训练参数量增多,占用更多内存空间,而且容易导致过拟合现象(即模型在训练数据上表现良好,但在测试数据上表现较差)[25]。ResNet-50[26]的50 层深度使其能更好地捕获和提取图像细节,更深层次的网络结构使ResNet-50 的分类精度高于ResNet-18 和ResNet-34。另外,与ResNet-101 和ResNet-152 相比,ResNet-50 的层数较少,节约了计算成本和训练时间,更易训练和泛化,更具实际应用价值。因此,本文选取ResNet-50 作为模型的底层网络架构(见图5),进一步结合视频图像序列时间流来更好地提取视频的空间特征和时间特征。ResNet-50的网络结构可以分为5 个阶段。1)输入层:使用视频截图作为模型的输入。2)预处理层:对输入图像进行预处理,例如归一化、裁剪等操作。3)Conv1:第一个卷积层,包括一个7×7 的卷积核、步幅为2 的卷积操作,以及一个2×2 的最大池化层。4)Conv2 ~Conv5一共4 个阶段,每个阶段包括多个残差块,每个残差块包括主要分支和跳跃连接分支。主要分支含有多个卷积层,用于学习输入特征的非线性变换。跳跃连接分支则直接将输入添加到主要分支的输出上,以形成残差。每个阶段的第一个残差块中,主要分支的步幅为2,用于降低特征图的维度;后续的残差块中,主要分支的步幅则为1。5)平均池化层和全连接层:用于降低特征图的空间维度,并通过一个全连接层将特征图映射到输出类别上。
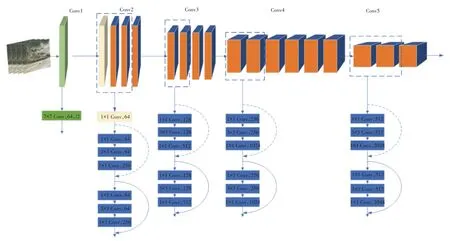
图5 ResNet-50网络结构
原始模型的性能和泛化能力还不够,且如果重新训练一个新的模型需要大量数据样本且会耗费很多时间。文献[27-29]中的研究结果表明,利用迁移学习方法,先使用图像或视频预训练之后再微调的方式已经在多个视频基准测试中取得了巨大成功。为了进一步提升卷积神经网络在泥石流视频分析中的性能和泛化能力,本文引入迁移学习方法。具体而言,利用ImageNet 和Kinetics-400 开源数据集对神经网络进行预训练,以获取通用的特征表达能力。随后,针对地质灾害场景的特殊性,使用预训练模型作为初始化网络,使用大量地质灾害视频数据微调模型。这种方式可以在较小的代价和计算资源的情况下,快速地获得在特定领域表现优良的神经网络模型。
本文模型的处理流程如图6 所示。本文提出的网络结构包含时域和空域流,分别对空域和时域信息建模。首先,将预处理之后的视频分割成固定长度的连续帧序列,称为样本片段,保证每个样本片段内帧图像规格相同以及所有样本片段数量相同。其次,从每个样本片段中稀疏采样得到一系列关键帧,将这些关键帧输入到基于ResNet-50 的空间流卷积网络中,以提取视频的外观特征。同时,在这些关键帧的前后使用Open CV 实现的TVL1 光流算法[30],如图7 所示。将这些光流图像一起输入到时间流卷积网络中,以提取视频的运动特征。最后,每个样本片段都会分别生成外观分析分数和运动分析分数,然后将两者的分数进行加权求均值的方式合并,得到该样本片段的最终预测值。这样依次对所有样本片段进行预测,最终得到整个视频的识别分类结果。
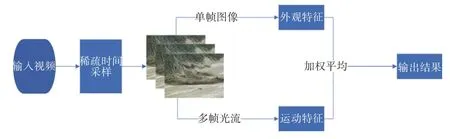
图6 泥石流识别流程

图7 抽取光流示例图
3 实验与结果分析
本文实验采用Windows11 64 位操作系统,并基于x64 架构的处理器进行操作。实验环境中的GPU为NVIDIA GeForce RTX 3050Ti 显卡。本文使用的模型是基于mmaction2 行为识别框平台实现的,训练集与测试集的划分比例为7:3。采用随机梯度下降法来优化网络模型的参数,动量大小设置为0.9,权重衰减项为0.0001,初始学习率设置为0.01。Batch Size(BS)对预模型的训练效率和结果具有重要影响。BS 过小,会导致模型训练过程中出现梯度消失或梯度爆炸的问题,从而影响模型的收敛和性能,而过大则可能导致模型对每个batch 的样本分布过拟合,从而在测试集上表现不佳。因此,选择一个适当的BS对于预模型的训练效率和结果是至关重要的。考虑到设备资源的有限性,为了节约计算资源并加快训练过程中的迭代速度,增加模型的泛化能力,本文采用准确率作为评价指标,经过相同条件下的消融实验,实验结果如图8所示。由图8可以看出将BS设置为6时,网络总体的识别准确率最高,可达87.73%。
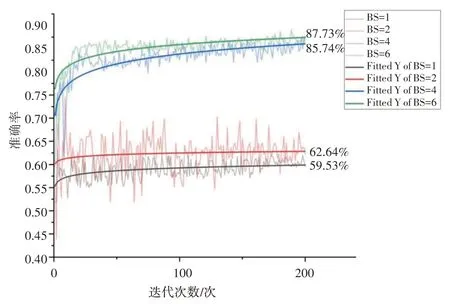
图8 不同BS情况下模型的准确率
在进行研究时,本文采用一系列的数据预处理策略来对视频数据进行处理,为了确保这些策略对模型训练是有利的,设计如下对比试验。将原始的视频数据根据视频的内容进行粗略的分类,生成数据集A。使用分割场景、修剪视频、数据增强的步骤对数据进行预处理,生成数据集B。分别将这2 类数据集输入到模型中进行训练,并记录数据集训练后模型的最高准确率的模型参数值,实验结果如表1 所示。经过数据预处理后,训练集的准确率从原本的63.66%提高到了87.73%,提升了24.07 个百分点,测试集的准确率也从64.58%提升到了89.15%,提高了24.57 个百分点。实验结果表明,本文的数据预处理方式对提高模型的准确率有着正向作用。
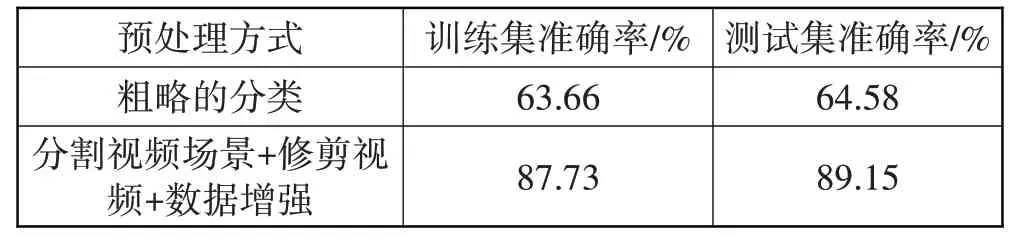
表1 数据预处理对模型准确率的影响
为全面评估分类模型的性能,精细计算每个类别的准确率,实验结果如表2 所示。由实验数据可知,模型在处理泥石流视频分类时的效果最佳,准确率高达93.84%,然而,滑坡和崩塌视频分类的准确率相对较低,为80.27%,自然场景非地质灾害视频分类的准确率为86.33%。这些数据清晰地揭示了模型在处理不同类型自然灾害视频时的性能有所差异。对于泥石流视频的高准确率,可能的原因是该类视频中出现的视觉特征较为独特和明显,如大量的泥土和石头流动,这些显著的视觉元素容易被模型正确识别。然而,滑坡和自然环境非地质灾害视频包含了更复杂的视觉特征,使得模型在进行这2 类视频分类时的准确率有所下降。除此之外,模型的性能表现与训练数据的数量和质量紧密关联。在本文实验中,由于泥石流视频的数量最多,模型在该类别的表现也相应地达到了最佳,然而,滑坡视频的数量相对较少,由于数据不足影响了模型的准确率。针对滑坡视频的分类性能,未来可以通过增加该类视频的训练数据量进行优化和提升。
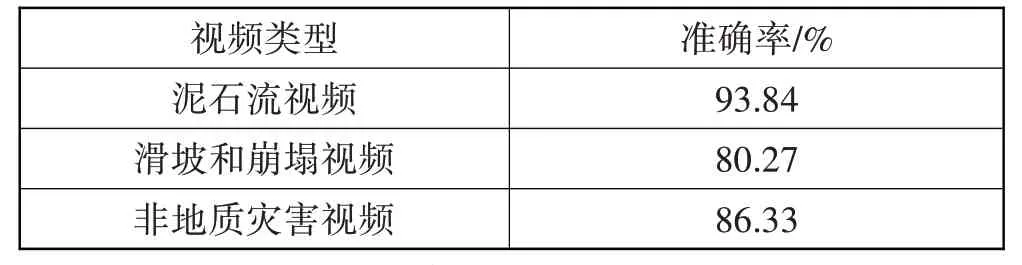
表2 不同视频的分类准确率
为了验证本文所使用的网络模型在自制泥石流数据集上的优越性,设计一组消融实验。为确保实验的公平性,对模型都预先使用Kinetics-400 数据集预训练,并使用相同的测试集和验证集对模型进行测试。如表3所示,特征提取网络采用ResNet-50的网络模型取得了最高的准确率,相对于传统的TSN模型和I3D模型,本文所使用的网络模型具有更优异的表现。
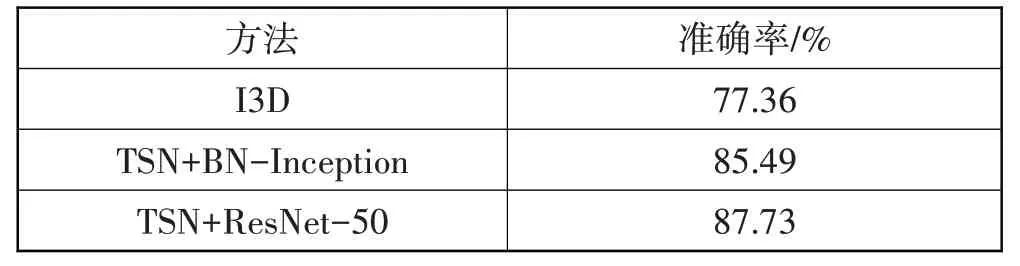
表3 不同方法的分类准确率
为了验证开源数据预训练对模型训练速度和准确率的提升效果,对未经过开源数据集训练的模型、经过ImageNet 数据集训练的模型和经过ImageNet 和Kinetics-400数据集预训练的模型进行对比实验。实验结果表明(见表4),经过预训练的模型在迭代次数更短的情况下,取得了更高的Top1/ACC值。
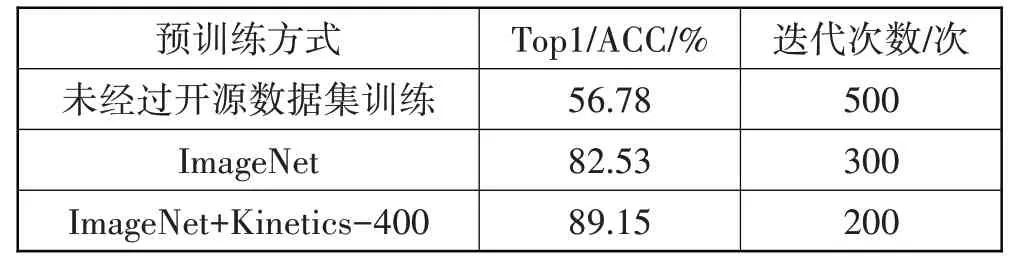
表4 使用公开数据集预训练对模型性能的影响
4 结束语
本文介绍了利用TSN 模型对泥石流视频进行分类的方法,并详细探讨了关键环节的实现过程:
1)数据集的收集与制作:借助互联网和部署在地质灾害点的摄像设备,收集各类地质灾害视频数据,并根据灾害类型将视频分为泥石流、滑坡和崩塌以及非地质灾害3种类型。
2)视频数据的预处理:使用PySceneDetect 工具进行镜头边界检测和使用ffmpeg修剪视频,将包含过多不同概念的复杂视频分割为短视频片段,再通过随机裁剪和水平方向的随机翻转的方式,提升数据量并丰富数据多样性。
3)分类模型的构建:该模型参考双流神经网络和TSN网络的框架,并使用ResNet-50作为模型的底层架构,以捕捉泥石流灾害视频中的运动特征和场景信息。
本文在使用ImageNet 和Kinetics-400 开源数据集对模型进行预训练后,再加入大量地质灾害视频数据对模型进行训练和微调。实验结果表明,本文采用的视频预处理方法和识别模型可以有效提高特定场景下特定摄像头捕捉到的泥石流运动场景视频的识别准确率,并为利用摄像头对泥石流进行监测预警的研究和应用提供了有益参考。
猜你喜欢
河北地质(2021年1期)2021-07-21
杂文月刊(2018年21期)2019-01-05
制导与引信(2017年3期)2017-11-02
海峡姐妹(2017年6期)2017-06-24
环球时报(2017-06-14)2017-06-14
北方交通(2016年12期)2017-01-15
水利科技与经济(2016年6期)2016-04-22
工业设计(2016年11期)2016-04-16
山东青年(2016年3期)2016-02-28
科技知识动漫(2016年1期)2016-01-27
