
CNN-Transformer 结合对比学习的高光谱与LiDAR 数据协同分类
2024-04-27 13:29:12吴海滨戴诗语王爱丽岩堀祐之于效宇
光学精密工程 2024年7期
吴海滨,戴诗语,王爱丽*,岩堀祐之,于效宇
(1.哈尔滨理工大学 测控技术与通信工程学院 黑龙江省激光光谱技术及应用重点实验室,黑龙江 哈尔滨 150080;2.中部大学 计算机科学学院,日本 爱知 487-8501;3.电子科技大学 中山学院 电子信息学院,广东 中山 528400)
1 引言
高光谱图像由同一区域数百个连续波段的光谱组成,具有光谱分辨率高、“图谱合一”的独特优势,其丰富的光谱信息可以用于识别不同地物的组成材质与内在结构[1-2]。近年来,深度学习端到端的特征学习框架,如卷积神经网络(Convolutional Neural Network,CNN)[3-4],3D CNN[5]等深度模型,能自动学习图像中的复杂特征表示,为高光谱图像分类提供了新的方法路径。
激光雷达(LiDAR)可以生成数字表面模型(Digital Surface Model,DSM),反映地表目标的三维立体信息[6-7],地物在高程形态特征上的差异被广泛应用于分类任务中。高光谱图像和Li-DAR 数据作为两种不同的遥感模态,存在明显的异质性。充分利用两种数据之间的互补信息,提取更丰富的特征表达是当前限制异构遥感数据深层次协同的关键难题之一。
相较于使用单传感器数据源,协同后的高光谱和LiDAR 数据集成了光谱特征、空间结构以及高程信息,能够从更多维度全面描述地物。具体来说,高光谱数据提供细致的光谱信息,在识别和表达地物光谱差异性方面具有明显优势;而LiDAR 数据提供高精度的空间分辨率和高程信息,能够准确反映地物的空间分布特征。两种数据源在表征地物方面呈现互补性,深层次协同可以增强地物类别的可分离性,进而提高分类的准确率。
ConvNeXt[8-9],ViT[10],DaViT[11]和Spect-Former[12]等网络架构,通过自注意力机制和全局上下文信息的建模,能够更好地捕捉图像的关键特征,实现更准确的视觉推理和分析。基于深度学习的CNN 和Transformer 模型,也被引入遥感图像的多源数据协同分类任务,取得了令人满意的协同分类效果[13-18]。例如,采用形态学扩展的属性剖面[13]、IP-CNN[14],Transformer[15]、双分支卷积网络(Two-Branch CNN)[16]、深度编码器-解码器网络(EndNet)[17]、多源特征中间层融合网络(MDL-Middle)[18]和多注意力分层稠密融合网络(MAHiDFNet)[19]。
对比学习作为一种自监督表示学习方法,可以学习到具有强大区分能力的特征表达,在多模态领域得到了广泛的应用[20]。通过使用同一样本在不同视角下的代理任务进行训练,对比学习能够获得具有语义对齐的特征表达[21-22]。为解决异构多模态数据特征表达能力不足的问题,本文提出了基于对比学习CNN-Transformer 高光谱和LiDAR 数据协同分类网络(Contrastive Learning based CNN-Transformer Network,CLCTNet),结合ConvNeXt V2 Block 设计了共有特征提取网络,增强模型对异构多模态数据的表征能力,实现跨模态数据之间的特征对齐。然后,充分发挥CNN 的局部特征学习和Transformer 的全局上下文建模能力,构建了包含空间-通道分支和光谱上下文分支的双分支HSI 编码器,以及结合频域自注意力机制的LiDAR 编码器,挖掘不同模态数据之间的互补信息。最后,利用集成对比学习进行分类,进一步推动模态特征对齐,提升多模态数据协同分类的精度。
2 原 理
2.1 CLCT-Net 模型架构
图1 展示了CLCT-Net 模型的架构框图。该模型主要包含以下三个部分:共有特征提取网络、HSI 编码器、LiDAR 编码器和集成对比学习损失函数。CLCT-Net 模型首先经过共有特征提取网络进行共有特征提取,共有特征提取网络由ConvNeXt V2 Block 组成,通过全局响应归一化、深度可分离卷积等实现共性特征提取。提取后的共有特征分别输入HSI 编码器和LiDAR 数据编码器中,HSI 编码器由空间-通道子分支、光谱上下文子分支组成,其中空间-通道子分支利用局部空间窗口多头双注意力(Spatial Window Multi-headed Self-attention,SW-MHSA)机制和通道组多头双注意力(Channel Group Multiheaded Self-attention,CG-MHSA)机制,LiDAR编码器利用频域注意力机制(Spectrum Former)。HSI 编码器学习图像的空间结构和光谱信息,Li-DAR 编码器学习数据中的高程信息以及其空间结构依赖性。最后,两种模态特征通过基于集成对比学习的联合分类器,其中损失函数同时包含对比损失和分类损失,可以增强特征的判别能力,将同源数据特征距离最小化,异源数据特征距离最大化,实现高光谱图像和LiDAR 数据的协同分类。
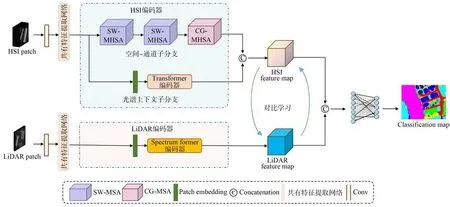
图1 CLCT-Net 模型架构Fig.1 Model architecture of CLCT-Net
2.2 共有特征提取网络
由于异构多模态特征分布存在差异性,这给模型建模跨模态的相关信息对齐带来困难,模型难以直接学习到不同模态间隐含的联系规律。为解决异构多模态特征的对齐问题,本文设计了基于ConvNeXt V2 Block 的共有特征提取网络,通过深度可分离卷积高效提取两种模态数据的低频共性特征,再通过全局响应归一化(Global Response Normalization,GRN)更好地传导共有信息,进而实现异构数据的深层协同,从而在多层抽象程度上挖掘不同模态之间的语义关联信息,实现跨模态数据之间的特征对齐,如图2 所示。其中,24 维7×7 深度可分离卷积层(d7×7,24)用于聚合全局特征信息,深度可分离卷积将标准卷积操作分解为深度卷积和点卷积,大大减少了计算量而保持了等效的建模能力。在可分离卷积后进行层规范化(Layer Normalization,LN)操作,96 维1×1 卷积层进行通道数升维,GELU 激活函数引入非线性,GRN 层对特征进行校准,增强模型的稳定性。最后,24 维1×1 卷积层负责通道数降维,并通过残差连接,使网络更专注于学习两种异构模态之间的低频共有特征。其中,GRN 是通过划分特征图中的相邻区域,对区域内特征响应值进行归一化处理,实现共有信息的传递,即有:
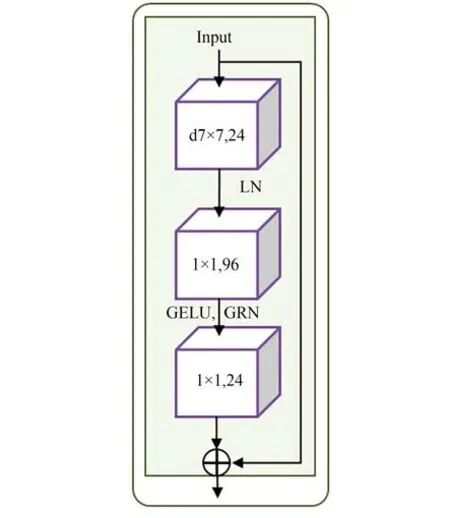
图2 共有特征提取网络示意图Fig.2 Schematic diagram of shared feature extraction network
相比直接串联原始特征或分别单独训练,共有特征提取网络具有更少的参数量、更加紧凑的特征表达能力。因原始HSI 图像中独立的光谱通道存在一定程度的冗余性,共有特征提取网络能够对HSI 光谱通道信息进行整合,以减少冗余并增强光谱通道间的关联性。
2.3 双分支HSI 编码器
在高光谱图像中,每个像素都包含多个光谱波段的信息,波段之间存在复杂的空间和光谱关联。因此,本文设计了基于Transformer 的双分支HSI 编码器(Two Branch HSI Encoder,TBHSI),由空间-通道子分支和光谱上下文子分支组成,如图3 所示。其中,空间-通道子分支专注建模局部光谱-空间依赖,而光谱上下文子分支聚焦于全局光谱特征挖掘。相比单一分支结构,该设计可以同时捕获局部光谱-空间特征和全局光谱语义信息,全面提高了模型对HSI 特征的理解和表达能力。
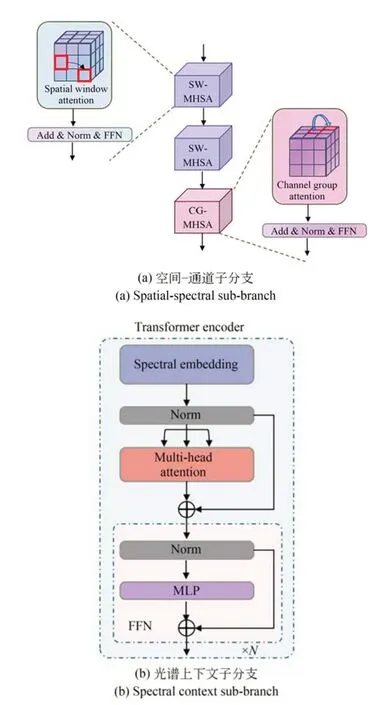
图3 HSI 编码器示意图Fig.3 Schematic diagram of HSI encoder
2.3.1 空间-通道特征提取子分支
空间-通道特征提取子分支利用SW-MHSA和CG-MHSA 学习高光谱图像的空间依赖关系和不同光谱通道之间的关联性,以增强模型对高光谱图像空间-通道特征的表达能力。如图3(a)所示,SW-MHSA 将输入高光谱图像分割成多个局部图像块,在每个块周围定义一个空间窗口,仅计算窗口内块之间的注意力权重。在多头结构下,不同的头学习不同类型的局部空间依赖模式。SW-MHSA 能够更高效建模局部空间信息,增强对空间信息的学习能力。
设输入特征矩阵为X∈RN×C,其中N为空间位置数,C为特征维数。对于窗口w,提取局部特征子集Xw,Xw=Xi:i+w,根据线性映射得到Query,Key,Value 矩阵:
这里的WQ,WK,WV表示线性映射的参数矩阵,将输入X映射到Query,Key,Value 的对角空间中。
对于每个窗口w,计算注意力分数:
其中d表示线性映射的参数矩阵的第二维,也就是映射后的特征维度。计算窗口内Value加权和:
最后,串联所有窗口输出得到最终的多头自注意力输出。
CG-MHSA 将输入特征的通道分成多个组,在每个通道组内计算自注意力,学习同组内通道之间的依赖关系。设输入特征X∈RN×C×H×W,其中N为batch size,C为通道数,H,W为高度和宽度。将X重塑为X∈RN×C'×M,其中M=H×W,g为组数。在通道组维度上计算注意力分数,串联所有通道组输出得到最终多头自注意力输出。相比全通道的注意力计算,CGMHSA 更高效并可捕捉光谱之间的关联性,增强对光谱信息的建模能力。
2.3.2 光谱上下文特征提取子分支
光谱上下文子分支使用Transformer 编码器结构,如图3(b)所示。通过自注意力机制学习光谱维度之间的依赖,并利用编码器部分进一步充分捕捉光谱特征之间的上下文语义信息。
设高光谱图像块为X∈RH×W×C,其中H,W为高光谱图像块的高度和宽度,C为光谱波段数量,提取该光谱特征矩阵中对应中心像素的C维特征向量作为光谱上下文子分支的输入,进行线性投影生成Query,Key,Value 矩阵。通过多头自注意力计算获得中心像素光谱特征的上下文表示,重复该过程进行多层编码,以学习光谱特征之间的依赖关系,获得中心像素在光谱全局视角下的上下文表示。
2.4 结合自注意力机制的LiDAR 编码器
LiDAR 数据有丰富的建筑物边界、植被形状等高程信息,充分学习LiDAR 数据的高程特征,能够极大提升协同分类性能。因此,本文设计基于频域自注意力机制的LiDAR 编码器(Spectrum LiDAR Encoder,Spectrum-LiDAR),该编码器使用Transformer 编码器结构,采用基于傅里叶变换的自注意力机制,学习LiDAR 的全局依赖关系,聚焦高程信息。
如图4 所示,设LiDAR 数据经过共有特征提取网络获得空间域特征为z(x,y),进行二维离散傅里叶变换得到其频域表达Z(u,v),即:
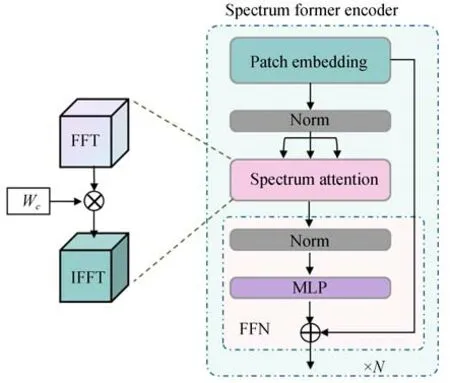
图4 LiDAR 编码器示意图Fig.4 Schematic diagram of LiDAR encoder
其中u和v是频率域的变量。
随后,定义频域滤波器Wc(u,v),与Z(u,v)进行逐点乘法,得到加权后的频域函数:
最后,对Z'(u,v)进行反傅里叶变换,以取得空间域的输出函数:
z'(x,y)反映了LiDAR 数据在不同频率下的特征分布,能够捕获到不同频率下丰富的高程信息。
2.5 集成对比学习的损失函数
为实现更加有效的异构多模态特征对齐与模态协同性能,本文构建了包含对比学习损失和分类损失的联合损失函数。对比学习损失通过拉近同类异构特征之间的距离,着重跨模态数据中的共性信息,为异构数据协同分类提供更统一可靠的特征表示,以提升模型分类性能。
对比损失函数由两部分构成:HSI 对LiDAR的特征对比损失函数,以及LiDAR 对HSI 的特征对比损失函数。第i个样本的对比损失函数如下:
HSI 对LiDAR,LiDAR 对HSI 的对比损失函数的计算公式如下:
其中:
其中:fHSI(·)和fLiDAR(·)分别是HSI 和LiDAR 模态的特征提取函数;表示样本对中HSI 与Li-DAR 特征之间的相似性;τ∈R,表示温度参数。
总的对比损失函数通过对所有样本对的对比损失求平均得到:
通过最小化该损失函数,可以学习到语义上对齐的HSI 和LiDAR 表征,从而提升两者特征的联合表示能力。
分类损失采用交叉熵损失的形式,用于度量预测类别分布与真实类别分布之间的距离。
其中:yi是样本i的编码类别标签,pi是模型预测的类别分布概率,分类损失能够优化神经网络的分类性能。
最终的损失函数为对比学习损失和分类损失的加权结合:
通过联合训练两种损失函数,模型既学习了判别性的特征表示,又获得了准确的地物分类结果。
3 实验结果与分析
3.1 实验数据集
Houston2013 数据集由美国国家科学基金会资助的空中激光雷达制图中心(NCALM)在2013 年获取,覆盖休斯顿大学校园及周边城市区域。高光谱和LiDAR DSM 数据都包含349×1 905 个像素,具有相同的空间分辨率(2.5 m)。高光谱图像包含144 个光谱波段,波段为380~1 050 nm,包含15 个类别。表1 列出了不同类别的样本数量及对应的颜色,图5 给出了Houston2013 数据集的可视化结果,可在IEEE GRSS网站(http://dase.grss-ieee.org/)上获得。
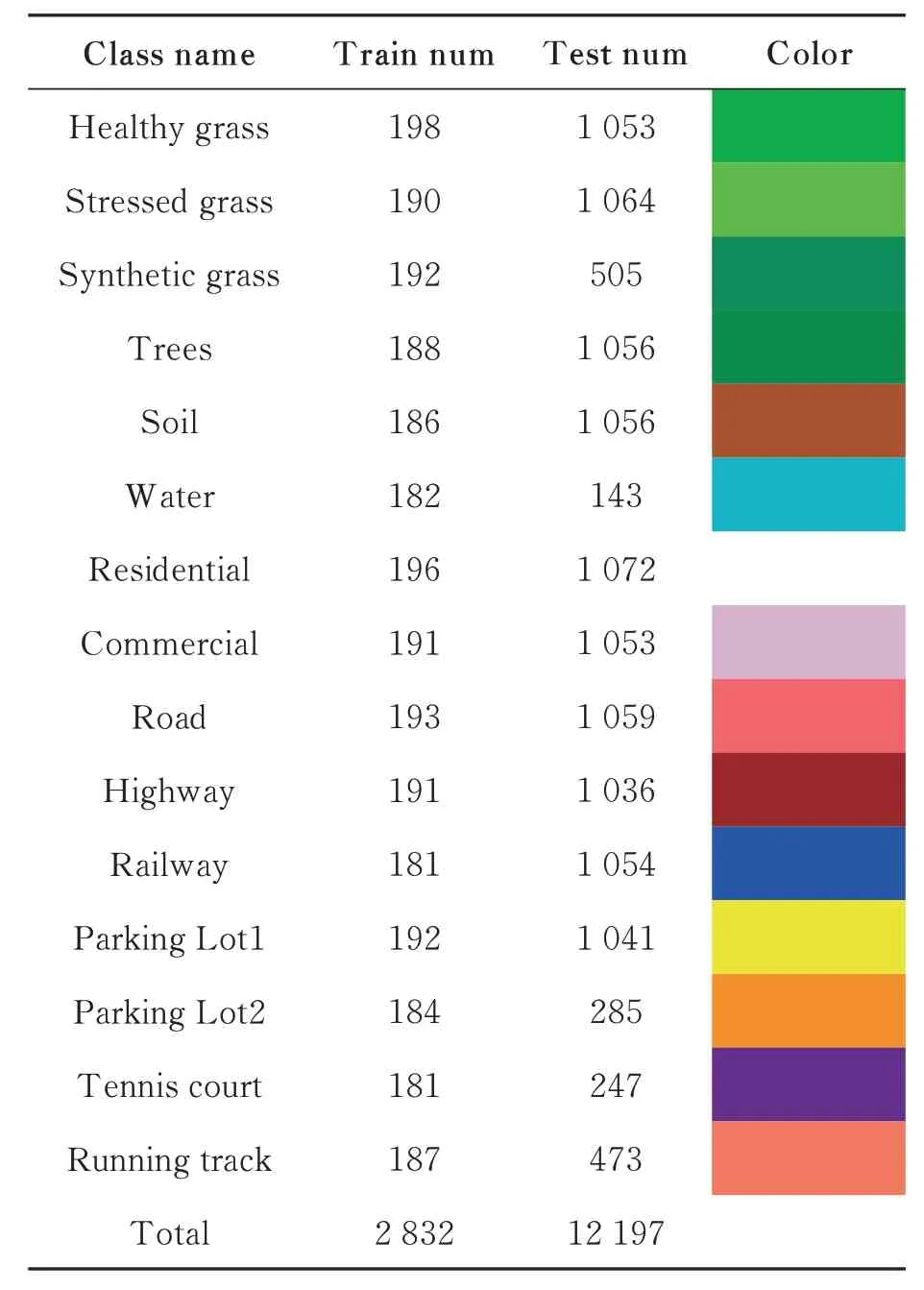
表1 Houston2013 数据集土地类别详情Tab.1 Land class details in Houston2013 dataset

图5 Houston2013 数据集的伪彩色图和真值图Fig.5 Pseudo color map and ground-truth map of Houston2013 dataset
Trento 数据集中高光谱图像由AISA Eagle传感器获取,LiDAR DSM 利用Optech ALTM 3100EA 传感器的第一和最后一个点云脉冲生成,两者均为600×166 像素,空间分辨率均为1 m。高光谱图像包含63 个波段,覆盖402.89~989.09 nm,包含6 个类别。表2 列出了不同类别的样本数量以及对应的颜色,图6 给出了Trento数据集的伪彩色图和真值图。

表2 Trento 数据集土地类别详情Tab.2 Land class details in Trento dataset

图6 Trento 数据集的伪彩色图和真值图Fig.6 Pseudo color map and ground-truth map of Trento dataset
3.2 实验平台及参数
实验基于Ubuntu 18.04 系统,使用配备Tesla P100 GPU 与Intel(R)Xeon(R)CPU E5-2640 v4 @ 2.40 GHZ 处理器的计算服务器,Python3.7 语言及PyTorch 1.10 深度学习框架构建实验环境,模型训练使用的batch size 为64,epoch为200,随机划分训练集和验证集,训练集和验证集的划分比例为8∶2,采用AdamW 优化器、cosine 学习率调度策略,初始学习率设置为5×10-4,权重衰减系数为1×10-1。CG-MHSA 中组数g设置为1,对比学习损失中超参数τ 设置为0.07,最终联合损失中的比重超参数,本文设置为λ1=0.5,λ2=1.0。
3.3 实验对比及分析
3.3.1t-SNE 分析
根据图7 和图8 所示的t-SNE(t-Distributed Stochastic Neighbor Embedding)可视化结果,在Houston 2013 和Trento 两个数据集上仅利用HSI 图像进行分类,不同类别的数据点分布存在明显的重叠现象。这表明仅依靠光谱信息进行分类的效果受限。另一方面,仅利用LiDAR数据进行分类时,数据点的分布比较散乱,这表明仅依靠空间结构信息进行分类的性能也较差,且明显不及仅使用HSI 图像进行分类的效果。

图7 Houston2013 数据集的特征可视化Fig.7 Feature visualizations of Houston2013 dataset
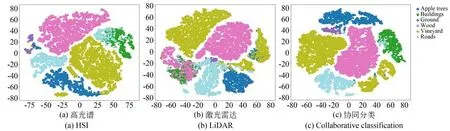
图8 Trento 数据集的特征可视化Fig.8 Feature visualizations of Trento dataset
相较而言,同时利用HSI 图像和LiDAR 数据进行联合分类时,不同类别的数据点能够获得更好的聚类和区分。由此表明,高光谱和LiDAR协同分类模型能够更有效地利用两种数据的互补信息,提高对不同地物类别的判别能力,从而获得优于单数据源的分类性能。
3.3.2 不同分类方法的对比
为验证CLCT-Net 模型的联合分类的有效性,将它与Two-Branch CNN[16],EndNet[17],MDL-Middle[18]和MAHiDFNet[19]进行比较。同时,本文还比较了双分支HSI 编码器(TB-HSI)、基于频域信息的LiDAR 编码器(Spectrum-Li-DAR)两种单传感器分类模型。
实验评价指标为整体精度(Overall Accuracy,OA)、平均精度(Average Accuracy,AA)和Kappa 系数。OA 表示模型在所有测试样本上的正确预测样本与总样本数之间的比例。AA 是每个类别中正确预测数与该类别总数之间的比例,取各类别精度的平均值。Kappa 系数用于评估分类准确性,验证遥感分类结果图与地面真实图之间的一致性。
表3 和表4 给出了不同算法在 Houston2013和Trento 数据集上测试15 次得到的平均分类结果。由表3 可知,双传感器协同分类模型的分类精度明显优于单传感器分类方法,这一结论与t-SNE 的分析结果一致。与Two-Branch CNN,EndNet,MDL-Middle 和MAHiDFNet 相比,本文提出的方法在OA,AA 和Kappa 系数方面都有明显改善,尤其对Stressed grass,Road,Railway 和Tennis court 有显著提升。其中,Stressed grass 的分类精度达到了98.05%,Tennis court 的分类精度为100.00%。
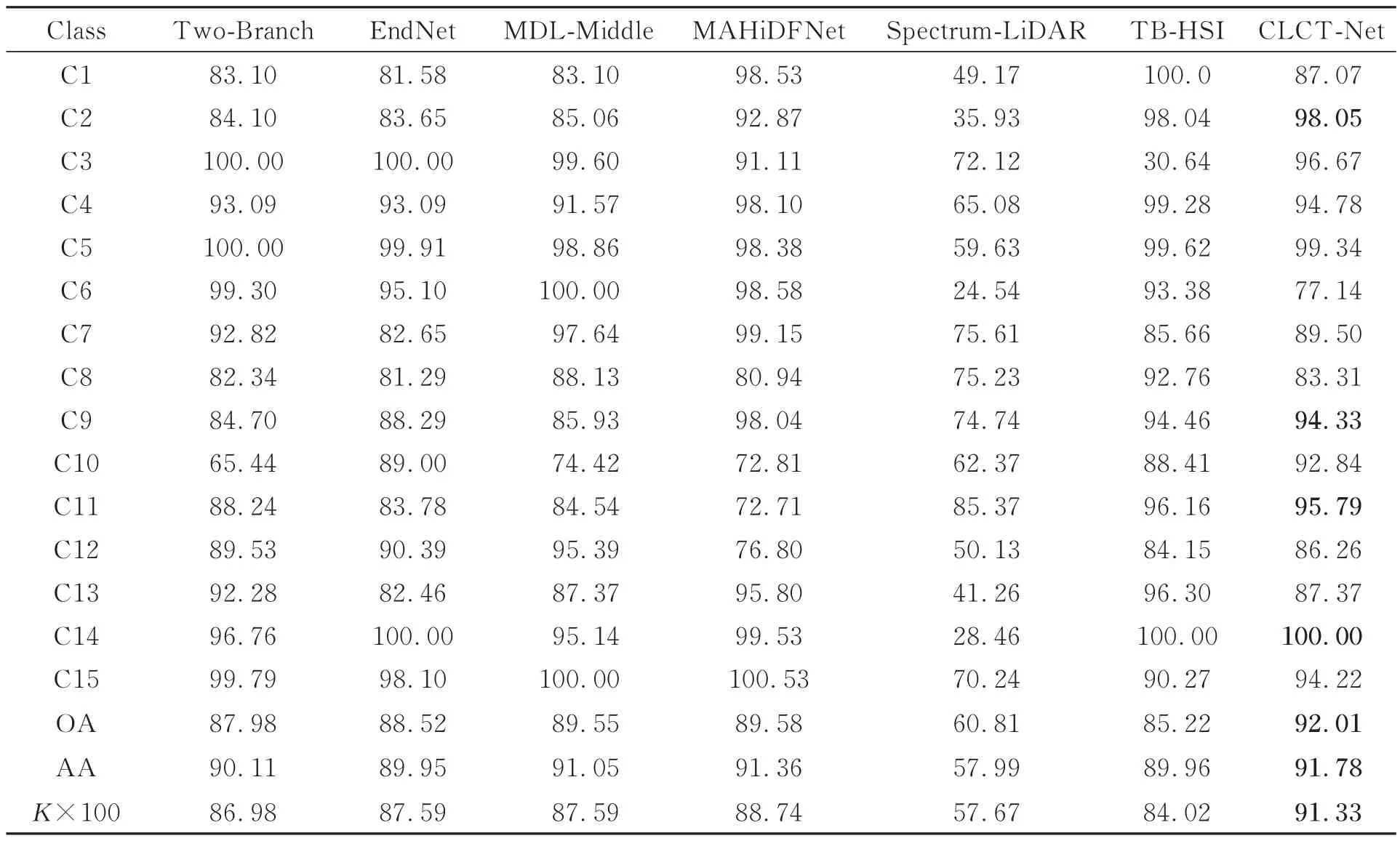
表3 不同方法在Houston2013 数据集上的分类精度对比Tab.3 Comparison of classification accuracy of different methods on Houston2013 dataset(%)
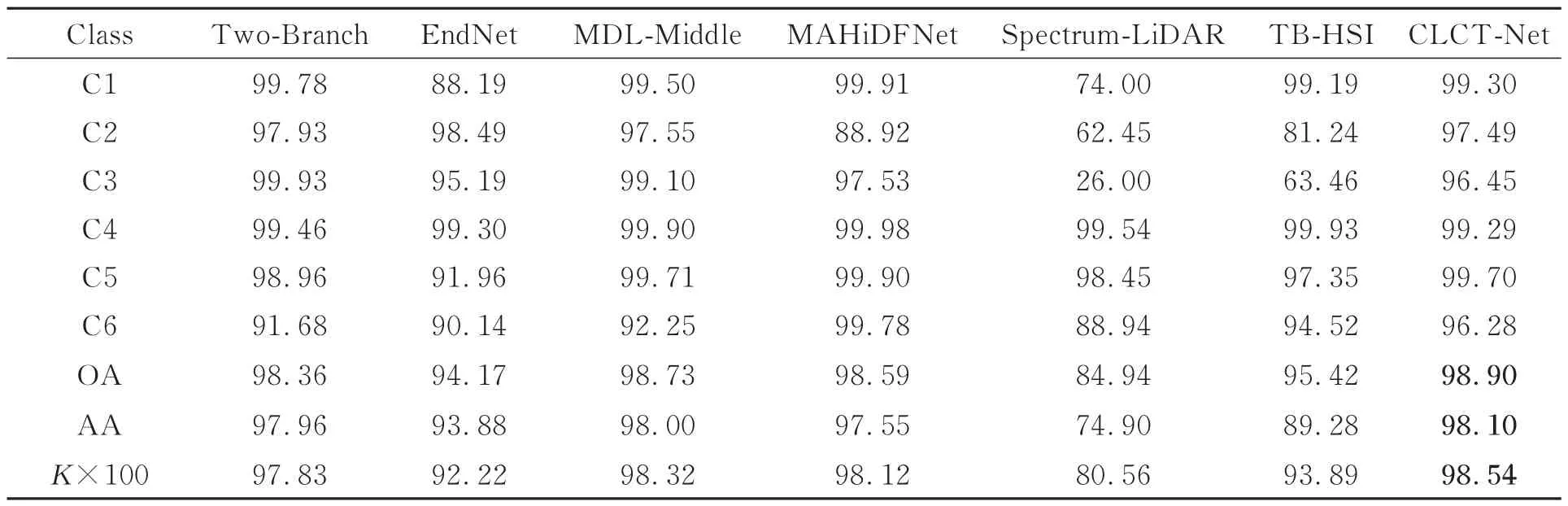
表4 不同方法在Trento 数据集上的分类精度对比Tab.4 Comparison of classification accuracy of different methods on Trento dataset(%)
根据表4,在Trento 数据集上,Spectrum-LiDAR 分类模型的OA 为84.94%,AA 为74.90%,Kappa 为80.56%。TB-HSI 分类模型这三个指标分别为 95.42%,89.28% 和93.89%。联合使用双传感器进行分类时,OA 提高到98.90%,AA 提高到98.10%,Kappa 提高到98.54%。本文方法在Roads 的分类性能方面也有明显提升,达到了96.28%。
为了直观验证所提出的CLCT-Net 模型的效果,在Houston 2013 和Trento 两个数据集上进行了分类结果的可视化对比,如图9 和图10所示。本文提出的CLCT-Net 能够更准确地描绘出Highway 区域以及Apples 区域的边缘,呈现更清晰且平滑的轮廓,其他方法获得的地物边界存在明显的锯齿状边界,不够平滑。这表明CLCT-Net 模型在细粒度特征表示和提取能力方面更为强大,能够捕捉复杂场景的微小细节,进行更精细和连贯的语义理解,在复杂边界描绘方面的表现更加出色。

图9 不同方法在Houston2013 数据集上的分类结果Fig.9 Classification results of different methods on Houston2013 dataset

图10 不同方法在Trento 数据集上的分类结果Fig.10 Classification results of different methods on Trento dataset
3.3.3 计算复杂性分析
本文采用浮点运算数(FLOPs)和参数量(#param)两个指标评估不同模型的计算复杂性,如表5 所示。其中,FLOPs 表示模型处理单幅图像并完成一次前向传播所需的浮点数运算量,反映了模型的时间复杂性。#param 表示模型的参数总量,决定了模型本身的大小,并直接影响模型在推理时所需的内存占用,反映了模型的空间复杂性。
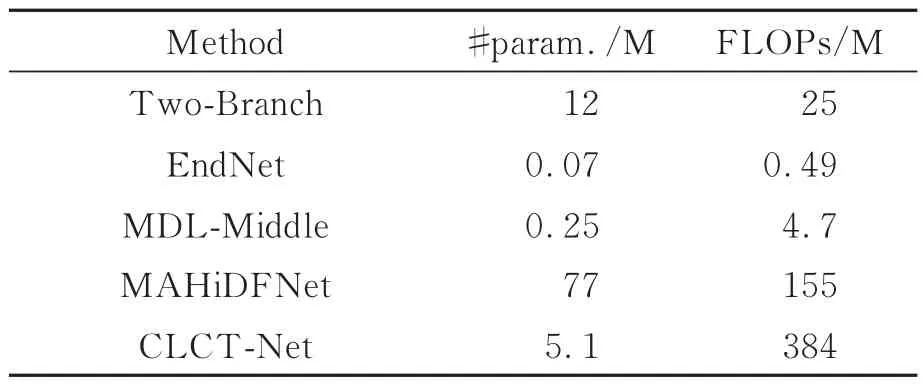
表5 不同分类模型的FLOPs 和参数数量Tab.5 FLOPs and parameters of different classification models
由于未考虑空间邻域信息,EndNet 模型的时间和空间复杂度相对较低。仅使用单个像素作为输入可以降低模型复杂度,忽略邻域依赖关系也会导致特征表达能力的局限,降低模型的分类准确率。对比Two-Branch,MAHiDFNet模型,本文提出的模型具有更为紧凑和高效的模型结构,可以在模型空间复杂度较低的情况下保持较好的性能。CLCT-Net 采用多个基于Transformer 的编码器分支,能够更全面地提取特征。然而,由于多头自注意力机制的特性,Transformer 常需大量计算资源,这使得模型的浮点数运算量不可避免地增加。考虑到效果和复杂度综合因素,CLCT-Net 模型虽然需要较多浮点数运算,但占用的内存空间较少。这种权衡使分类准确率显著提升,达到了性能和复杂度的最佳平衡。
4 结论
本文提出了一种基于CNN-Transformer 的端到端联合分类网络CLCT-Net。该网络应用共有特征提取网络模块,通过提取不同模态间的共性特征实现异构传感数据在语义级别的深层对应。其次,设计了双分支HSI 编码器和频域自注意力LiDAR 编码器,结合各模态特性分别学习丰富有效的特征表示。最后,引入集成对比学习策略,进一步提升了模型协同跨模态数据的地物分类能力。实验在Houston 2013 和Trento 数据集上进行,CLCT-Net 的OA 值分别为92.01%和98.90%,AA 值分别为91.78% 和90.10%,Kappa 值分别为91.33%和98.54%,优于其他分类方法。实验结果表明,基于CNN-Transformer的框架进行异构数据联合表达和建模是地物分类任务的有效途径。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
自动化学报(2017年11期)2017-04-04 02:52:58
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
噪声与振动控制(2015年4期)2015-01-01 07:08:21
