
多尺度增强特征融合的钢表面缺陷目标检测
2024-04-27 13:29:10林珊玲彭雪玲林志贤林坚普郭太良
光学精密工程 2024年7期
林珊玲,彭雪玲,王 栋,林志贤,3,林坚普*,郭太良
(1.福州大学 先进制造学院,福建 泉州 362252;2.中国福建光电信息科学与技术实验室,福建 福州 350116;3.福州大学 物理与信息工程学院,福建 福州 350116)
1 引言
钢坯在轧制阶段由于表面受热不均、轧辊夹杂碎屑等原因,部分区域存在孔洞、冷热裂纹等缺陷,影响铸造成品的抗拉强度、硬度和韧性。早期的钢表面缺陷主要依靠人工查验[1],通过主观视觉判定钢材损伤位置及受损程度,效率不高并且经常发生漏检。频闪光检测技术虽然能够从一定程度上提高钢表面缺陷的识别准确率,但大量重复性工作导致其检测速度较慢,无法满足工业检测需求[2]。
近年来,卷积神经网络(Convolutional Neural Network,CNN)发展迅速,基于CNN[3]的目标检测算法的识别精度不断提高。现阶段的目标检测算法大致分为两类,一类是基于区域候选提议(Region Proposal Network,RPN)的算法,如R-CNN(Region-based CNN)[4],Faster R-CNN[5]等,通过生成候选框提升检测精度,需要消耗大量检测时间。另一类是基于回归的算法,如YOLO(You Only Look Once)[6],SSD(Single Shot multibox Detector)[7],在回归目标位置的同时直接预测类别。其中,SSD 算法采用VGG-16[8]作为骨干网络进行多尺度分治检测,模型体积与计算量较大。为了降低卷积网络的复杂度,Sandler等[9]提出MobileNetV2,采用深度可分离卷积进行特征提取。在增强特征表达方面,Lin 等设计了特征金字塔(Feature Pyramid Network,FPN)[10]结构,通过横向连接与自顶向下融合方式,加强了深层语义与浅层细节的交互。Li 等受到FPN 结构的启发提出FSSD(Feature Fusion Single Shot multibox Detector)[11],将深层特征上采样后直接与浅层特征拼接融合,为浅层特征融入了深层语义表示。Hu 等[12]则提出SE(Squeeze and Excitation)注意力机制,通过通道方向的特征挤压与激励,使模型更加关注图像细节。与此同时,许多专家学者开展了钢表面缺陷目标检测算法的相关研究,特征融合结构、注意力机制等成为重要的算法优化手段。He 等[13]提出一种基于深度学习的钢板缺陷检测系统,通过组合池化层、普通卷积、反卷积形成全段多尺度特征融合结构,促进了杂质、刮痕等钢表面缺陷的细粒度表达与深层语义融合。Tang 等[14]提出一种带钢表面缺陷检测方法,采用带注意力机制的残差模块结合多尺度池化结构,解决了由于网络感受野过于单一导致的无法感知补丁、结疤等缺陷尺度变化问题。此外,Guo 等[15]提出一种检测钢表面缺陷的改进算法,结合视觉Transformer 检测模块辅助全局特征提取,增强了算法对于裂纹、点蚀等覆盖范围较广的缺陷目标的识别能力。虽然上述方法都能提升钢表面缺陷的检测效果,但识别精度仍具有提升空间,并且网络模型的计算成本较高,实际应用于工业检测设备具有一定难度。
针对钢表面缺陷目标检测算法的识别准确率不高、模型计算量大的问题,本文在SSD-MV2算法的基础上提出一种多尺度增强特征融合的钢表面缺陷目标检测算法(Enhanced FSSD with MobileNetV2,EFSSD-MV2)。首先,设计了一种自适应加权融合模块,采用自适应权重指导不同尺度层级的特征拼接融合。其次,设计了一种空间特征增强模块,进一步加强融合特征的有效信息描述。接着,改进了训练样本选择方法,使模型根据先验框与真实框的整体交并趋势动态调整训练样本数量,提高损失函数计算的准确性。
2 原 理
EFSSD-MV2 算法以SSD300 算法[16]框架为基础,采用更加轻量的MobileNetV2 代替VGG16 作为特征提取骨干网络,并移除它在Conv18 层后的分类输出层,算法网络结构如图1所示。为了将深层语义表达快速传导至浅层,选择其中的Conv7,Conv14,Conv18 层进行类似FSSD 中的多尺度特征融合,并通过增强特征融合(Enhanced Feature Fusion,EFF)单元提升融合效果,包含自适应加权融合(Adaptive Weighted Fusion,AWF)模块与空间特征增强模块(Spatial Feature Enhancement,SFE)。AWF 模块用于计算不同层级特征的自适应融合权重,而SFE 模块则用于进一步提高融合特征的空间特性。之后,利用附加特征提取网络生成6 个不同尺度的特征图,将其特征通道分布由原始的512,1 024,512,256,256,256 调整为256,128,128,64,64,32,并采用深度可分离卷积代替普通卷积作为分类与回归预测器,目的是降低网络后端的计算成本。改进的训练样本选择方法应用于模型训练阶段,通过将交并比(Intersection Over Union,IOU)阈值关联先验框与真实框的整体交并程度,使模型获得更为合适的训练样本。最后,采用非极大抑制算法筛选目标框。
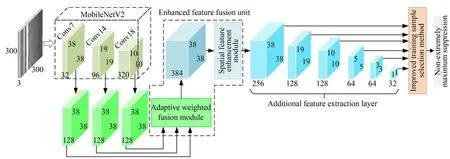
图1 EFSSD-MV2 算法的网络结构Fig.1 Network structure of EFSSD-MV2 algorithm
2.1 自适应加权融合模块
基础特征融合结构一次性聚合多个不同尺度的特征图[17]。大尺度特征图包含众多几何细节,而小尺度特征图则包含更为强大的语义表达。这种融合方式的本质是将深层特征直接传递至浅层,使浅层特征在不丢失细节信息的同时获得丰富的深层语义。然而,它在融合前必须规范特征图尺度与通道,弱化了不同层级特征之间的相对差异,抑制了融合特征描述检测目标特异性的能力。加权特征融合是指通过计算每个特征图对检测目标的贡献程度,使得不同尺度的特征信息得到充分融合。为了弥补基础特征融合结构的不足,设计了AWF 模块,其网络结构和算法流程框图如图2(a)和2(b)所示。
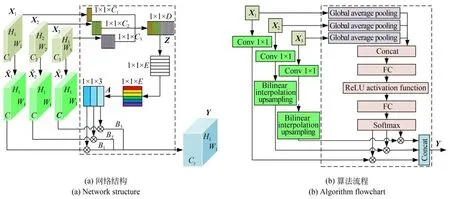
图2 自适应加权融合模块Fig.2 Adaptive Weighted Fusion(AWF)module
其中D为Cn之和,其值为448;Θ 表示Concat 特征拼接,zn表示第n层输入的全局特征,(i,j)表示特征空间坐标。采用2 个全连接层(Fully Connected,FC)与1 个ReLU 激活函数组合形成瓶颈层,用于学习特征在通道方向上的全局非线性关系,从而自适应地生成一组映射特征A∈R1×1×3,其表达式为:
其中:W1∈RE×D表示全局特征通过第一个FC 层后降至E个通道的参数,为了使前后2 次通道降维更加平缓,E设置为32;W2∈R3×E表示特征通过第二个FC 层后降至3 个通道的参数。为了更加准确地描述映射特征之间的相对性,采用Softmax 函数对A的特征值进行归一化指数约束,该过程可表示为:
其中:an表示A中的第n个特征值,对应的权重值为bn,代表特征对融合结果的影响程度。最后,将权重值分别与特征层对应相乘,输出加权融合特征,其表达式为:
其中:Cy为C的3 倍,其值为384;Bn表示第n层规范化输入特征经过加权后的结果。AWF 模块以特征融合分支为基础,按照输入特征的全局相对关系,在通道方向上以极少的参数量分配融合权重。
2.2 空间特征增强模块
为了进一步提取融合特征中包含的上下文先验知识,同时消除由于输入特征尺度差异而产生的混叠效应,基础特征融合结构对融合特征应用一个3×3 的卷积核,通道数降至原始特征的三分之二。该方法虽然在一定程度上能提高特征的全局表示能力,但通道数减少会产生特征丢失,且过于单薄的特征联系会影响附加特征提取网络对于检测目标的分类与定位。因此,本文结合空间注意力机制(Spatial Attention Mechanism,SAM)设计了如图3 所示的SFE 模块,从3 个不同方向强化融合特征的空间表达,通过引出残差旁路增强网络结构的稳定性,使卷积过程能够挖掘到更多的关键信息。
虽然3×3 的卷积核在提取特征时能够扩大感受野,但其处理大尺度特征层的计算成本较高,因此,SFE 模块中所有卷积操作均采用1×1的卷积核。SFE 模块首先对加权融合特征Y采用一组并行层进行类似SAM 中的挤压与激励操作。通过2 个并行的GAP 编码生成全局特征序列,同时采用1 个卷积层提取通道方向上的依赖关系,从而得到融合特征在不同空间取向的独立表示。输出特征的表达式为:
对全局特征Q,R,S应用ReLU 激活函数,目的是增强特征描述的多样性。该过程输出的表达式为:
为了使SFE 模块的输出特征通道数与附加特征提取网络的输入通道数保持一致,同时最大程度地保留原始融合特征信息,对融合特征Y与空间增强特征分别进行卷积特征提取,输出特征的表达式为:
其中U和为输出特征,并且U的通道数Cv小于通道数Cy,Cv设置为256。最后,将二者进行类似残差结构中的矩阵叠加,输出特征V∈的表达式为:
其中:σ表示Sigmoid 激活函数,将其应用于特征Uˉ可得到具有约束特性的空间增强系数;批量归一化函数(Batch Normalization,BN)用于增强网络模型的稳定性,使模型训练不易发散;ReLU6激活函数用来进行全局非线性化,相比ReLU 激活函数能够抑制无效特征,提高特征表达信息的准确性。
2.3 改进训练样本选择方法
在网络模型的训练阶段,SSD 算法按照交并比为每个先验框匹配一个真实框,若该值小于预设阈值则将此先验框判别为负样本。虽然该方法能够简单快速地区分先验框的正负属性,但6个不同尺度的检测层级先验框匹配程度并不相同,并且固定阈值的选取依赖于主观经验,训练阶段无法进行自适应调整。为了缓解这一问题,本文结合自适应阈值思想改进SSD 算法的训练样本选择方法(Adaptive Training Sample Selection,ATSS),改进方法具有更加强大的样本包容性。
将改进方法记为改进训练样本选择(Improved Training Sample Selection,ITSS)方法,它应用于每个检测层级的先验框与真实框的匹配过程,主要包含正样本选择与阈值计算两个部分。假定在第l个尺度检测层级的第r个先验框为Pr,其中心点坐标为C1(x1,y1),第s个真实框Gs的中心点坐标为C2(x2,y2),则C1与C2的欧式距离Lrs可表示为:
对于每个尺度检测层级,分别为每个真实框筛选前k个欧式距离L最小的先验框作为候选正样本,通过超参数k可调整纳入候选正样本的先验框数量,进而控制先验框与真实框的匹配程度。
在ATSS 方法中,通过遍历每个真实框所匹配的候选正样本来计算二者的IOU 值,并为每个真实框构建一个IOU 集合;而ITSS 方法则更加关注交并比的总体关系,将前述集合统一归并为I={I1,I2,···,Im},总数为m。为集合I计算基本统计学特性可得到自适应IOU 阈值T,其数学表达式为:
其中:集合I的均值M代表候选正样本与真实框的平均交并程度,而I的标准差S则用于描述候选正样本与真实框的交并比差异。在实际正负样本判定过程中,若第q个先验框Pq与其匹配真实框的IOU 值Jq≤T,则判定Pq为负样本。通过ITSS 方法,模型能够综合不同检测层级的先验框与真实框的交并程度,根据不同训练阶段的样本匹配程度动态调整IOU 阈值,使损失函数在计算过程中获得更加优质的正负样本。
3 实验结果分析
3.1 数据集与参数设置
为了检验EFSSD-MV2 对于钢表面缺陷目标的检测性能,实验采用东北大学公开发布的NEU-DET 钢材缺陷公共数据集作为训练样本,该数据集以PASCAL VOC 数据集格式为标准,包含6 类常见的钢表面缺陷图像与标定数据,分别为裂纹、补丁、杂质、点蚀、结疤和刮痕。其中,裂纹为钢表面产生的开裂现象;补丁为金属的某一部分因具有特定特征而与其余部分区分开的区域;杂质为金属表面缺陷中的典型缺陷,有些夹杂物比较松散,易脱落,有的则压入板中;点蚀是一种腐蚀形式,集中在钢金属表面的一个非常小的范围内,并渗入金属内部,通常直径小但深度较大;结疤是轧制过程中轧机鳞片被卷入金属中形成的;刮痕是钢表面磨损的痕迹。在保证实验公平性的前提下,本文去除了4 张仅含有难标签的数据样本,因此,数据集共包含1 796 张钢表面缺陷样本图片,训练集与测试集的比例为8∶2。
所有实验均在戴尔Precision 7920 高性能图形工作站上完成,其主要配置为Intel Xeon Silver 4210R 2.40 GHz CPU 以及NVIDIA Quadro RTX 5000 GPU,软件环境为Python 3.8 与Pytorch 1.11 深度学习框架,配备CUDA 11.6 图形加速平台。网络输入尺寸设为300×300,先验框尺度保持在(30,60),(60,111),(111,162),(162,213),(213,264),(264,315),数量分别为4,6,6,6,4,4;批量大小为32,最大训练轮数为20 000 轮,推理置信度阈值为0.01,检测准确率阈值为0.7;采用原始SSD 算法的SGD(Stochastic Gradient Descent)梯度下降法优化训练梯度,动量参数为0.9,权重衰减参数为0.000 01;为了使模型在训练过程中达到最优结果,在学习率调整策略上采用余弦退火学习率策略,使得网络模型能够逃离局部稳态,重新寻找更为合适的极值点。学习率α的数学表达式为:
其中:αmin表示学习率的最小值,设置为0;αmax表示学习率的最大值,设置为0.01;Tcur表示当前运行步数,随实验过程迭代更新;Tmax表示单个退火过程所需要的步数,设置为2。
3.2 评价指标与消融实验
为了验证所提出方法的性能,采用所有类别精度均值(Averrage Precision,AP),平均精度均值(mean Average Precision,mAP)指标验证多类别的检测精度,其计算公式如下:
其中:TP 表示真正例,FN 表示假反例,FP 表示假正例,TN 表示真反例,K为类别数目。
本文主要采用目标检测任务中常用的平均精度均值指标衡量算法精度,通过帧率(frame per second,fps)、参数量以及计算量等指标量化模型的实时检测性能。以算法在每个类别上的召回率(Recall)为横轴坐标,准确率(Precision)为纵轴坐标绘制Precision-Recall(P-R)曲线,通过计算P-R曲线与坐标轴围成的区域面积即可得到类别平均精度(Average Precision,AP)。将 SSD-MV2 算法、FSSD-MV2 算法以及EFSSD-MV2 算法分别在NEU-DET 数据集上进行实验,3 种算法的P-R曲线对比如图4 所示。从图中可以看出,FSSD-MV2 算法的检测精度高于SSD-MV2 算法,但由于仅采用基础特征融合结构,算法准确率的增加幅度有限;而EFSSD-MV2 算法在召回率大于0.2 之后的准确率则明显高于其他两种算法,这表明该算法对钢表面缺陷的检测精度相比改进前显著提升。
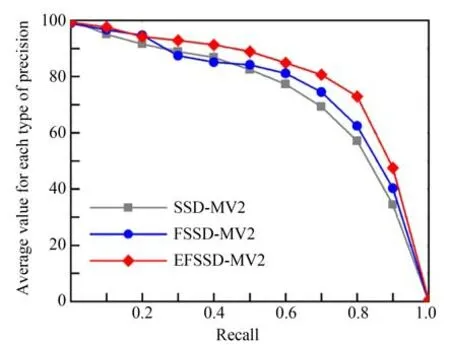
图4 算法改进前后的检测精度对比Fig.4 Comparison of algorithm detection accuracy before and after improvement
为了验证EFSSD-MV2 算法与提出方法的有效性,本文以SSD-MV2 算法模型为基础进行消融实验,结果如表1 所示。其中,mAPITSS表示采用ITSS 方法后的模型平均精度均值,超参数k=30。结果表明,EFSSD-MV2 算法的mAP 达到了80.47%,相比SSD-MV2 算法提升了6.81%;此外,算法模型的参数量为2.36 M,计算量为952.67 MFLOPs,整体参数量与计算成本较低。在传统SSD 算法的训练样本选择方法下,整体网络结构修改使算法的mAP 提升了4.19%;其中,基础特征融合结构使算法的mAP 提升了2.45%,计算量增加了239.48 MFLOPs;EFF 单元使算法的 mAP 提升1.74%,计算量增加了144.51 MFLOPs。由此可知,EFF 单元能够有效提高算法的检测精度,计算成本比基础特征融合结构更低。以特征融合结构为基础,单独添加AWF 模块后算法的mAP 提升了1.22%,模型参数量仅增加0.02 M;单独增加SFE 模块后算法的mAP 提升了1.07%,模型参数量增加0.1 M。在SSDMV2 算法的基础上,将训练样本选择方法更改为ITSS 方法,算法mAP 提升了3.75%。由此可知,AWF 模块以极小的计算成本提升了检测精度,其原因在于通过在通道方向上的全局特征计算自适应权重;采用SFE 模块虽然略微增加计算开支,但也提高了检测精度;通过改进训练样本选择方法,算法的检测精度取得了显著提升。整体而言,本文提出的方法对于SSDMV2 算法的检测精度提升是十分有效的。
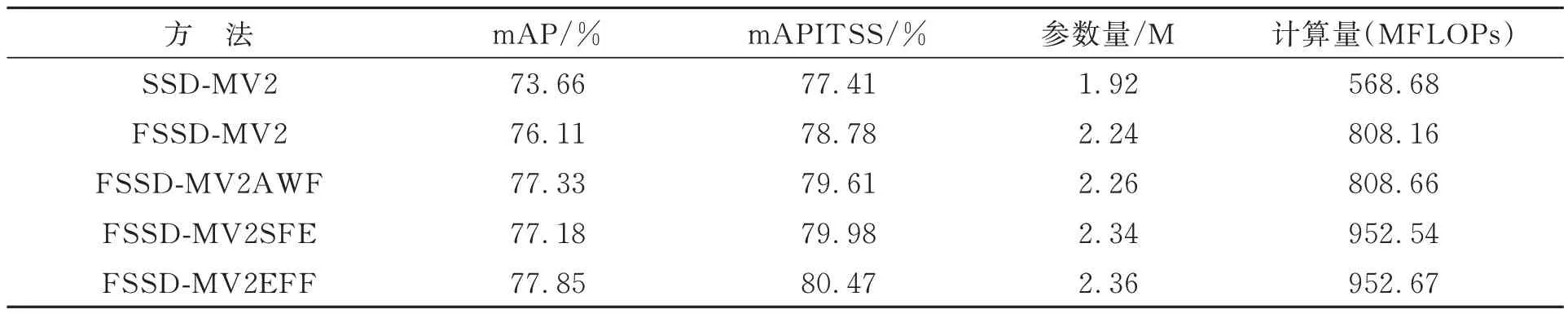
表1 EFSSD-MV2 算法的消融实验(1 M=106)Tab.1 Ablation experiments for EFSSD-MV2 algorithm(1 M=106)
3.3 检测算法对比
为了进一步评价EFSSD-MV2 算法对于钢表面缺陷目标的检测性能,本文选取目标检测领域10 种主流的轻量级检测算法进行比较。实验过程中,所有算法均在前述数据集上训练,保持原始训练参数不变,对比实验结果如表2 所示。结果表明,EFSSD-MV2 算法在钢表面缺陷检测任务上的mAP 指标超过了其他检测算法,对裂纹、点蚀缺陷的检测精度均为最高,说明算法对于检测难度较大的细粒度钢表面缺陷目标的识别具有明显优势。EFSSD-MV2 算法相比输入图像尺寸相近的SSDLite 算法和NanoDet 算法,mAP 分别高出6.44%和30.19%,体积分别减少了15.71 MB 和1.71 MB,表明算法能够利用较少的图像输入资源取得较好的检测效果。同时,EFSSD-MV2 算法相比超轻量级目标检测算法FastestDet 的mAP 高出9.05%,相比新型轻量级目标检测算法MutualGuide 高出3.75%;相比YOLO 系列的经典轻量级检测算法YOLOv3-tiny,YOLOv4-tiny 分别高出12.63%和11.98%,体积则减少了23.87 MB 和13.21 MB;相比同系列主流算法YOLOv5n 以及YOLOv6n 算法,mAP 分别高出4.75%和4.92%;相比先进轻量级检测算法YOLOv7-tiny 和YOLOX-nano,mAP 分别高出5.6% 和3.69%。EFSSD-MV2算法在检测精度上超越了同等级别下的YOLO系列算法,而模型体积除了YOLOX-nano 之外均相比更小,表明该算法以较低的计算成本,取得了相对较高的钢表面缺陷检测精度。在实时检测速度方面,虽然EFSSD-MV2 算法的fps 指标处于中间水平,但66.4 frame/s 的检测速度能够满足钢铁行业的日常检测需求。据此可以得出,EFSSD-MV2 相较于主流轻量级目标检测算法,无论在对钢表面缺陷目标的检测精度还是在模型轻量化程度上都具有明显的优势。
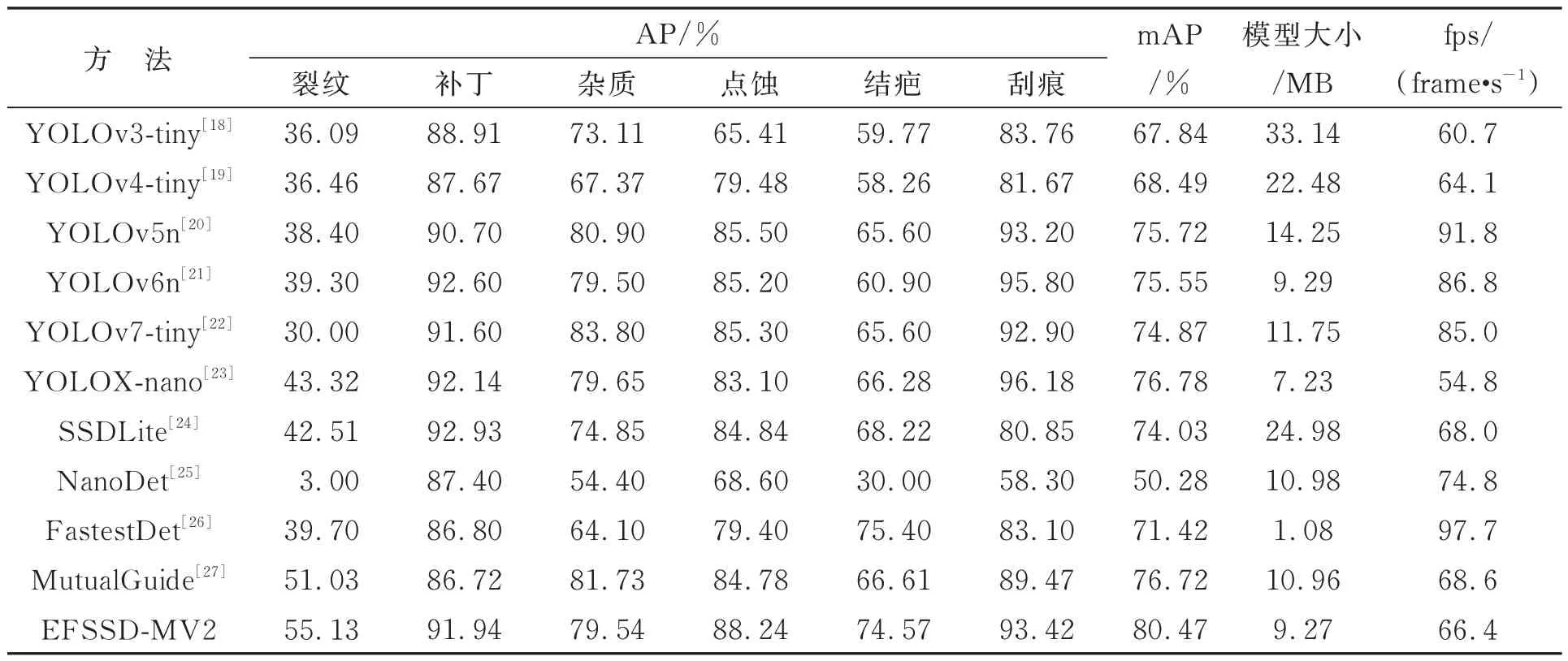
表2 与其他轻量级目标检测算法的实验结果对比Tab.2 Comparison of experimental results with other lightweight target detection algorithms
3.4 超参数讨论
对于ITSS 样本选择方法,超参数k的取值直接决定候选正样本的数量,需要通过实验验证其取值的合理性。这里以EFSSD-MV2 算法的网络结构为基础,分别比较ITSS 及ATSS 方法中k对算法mAP 指标的影响,实验中k取值为5~50,间距为5。表3 为实验结果,其中,mAPATSS表示采用ATSS 方法后模型的平均精度均值。结果表明,超参数k会影响算法的检测精度,当超参数k为30时,采用上述两种方法的算法mAP 指标分别达到极大值。从不同k取值下的mAP 变化趋势可以得出,当k取值较小时,由于正样本数量不足,样本选择方法的mAP 提升效果不明显;当k取值较大时,由于正样本数量过多而导致方法的mAP 提升效果回落;采用ITSS 方法后算法的mAP 的整体变化幅度相对较小,原因在于其计算过程考虑了先验框与真实框的整体IOU 特性,样本筛选过程更加符合自然分布规律,模型经过训练后对于不同的钢表面缺陷拥有更强的泛化检测能力。

表3 超参数k 对EFSSD-MV2 算法mAP 指标的影响Tab.3 Effect of hyperparameter k on mAP metrics of EFSSD-MV2 algorithm(%)
3.5 测试结果对比
本文通过 Grad-CAM(Gradient-weighted Class Activation Mapping)绘制附加特征提取网络的权重可视化效果图,分别对SSD-MV2 算法、FSSD-MV2 算法以及EFSSD-MV2 算法进行实验,并为每个类别随机抽取1 组实验结果,3 种算法的类激活映射输出对比如图5 所示。从图中可以看出,SSD-MV2 算法各个缺陷类别的热力图分布都较为宽泛,对于裂纹、补丁以及杂质缺陷的特征敏感性较差;FSSD-MV2 算法虽然对于所有缺陷特征表达都具有识别能力,但其特征感知范围仍然存在局限;相比于其他两种算法,EFSSD-MV2 算法则具有更加完整全面的钢表面缺陷捕获能力,主要原因在于EFF 单元中合理运用了特征融合与注意力机制,网络模型的特征提取更加符合人类视觉。
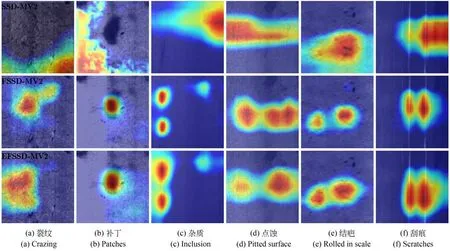
图5 算法改进前后的类激活映射输出对比Fig.5 Comparison of class activation mapping output before and after algorithm improvement
为了直观展示钢表面缺陷目标检测算法的有效性,本文分别对3 种算法进行了样例测试,检测效果对比如图6 所示。可以看出,SSDMV2 算法对于所有缺陷目标均存在不同程度的漏检问题,检测效果不佳;FSSD-MV2 算法提高了裂纹、补丁以及杂质缺陷的检测质量,但对于刮痕缺陷的检测精度依然较低;而EFSSD-MV2算法能够较为准确地检测出6 种常见的钢表面缺陷,相比于其他两种算法明显改善了缺陷漏检问题,对不同尺度的缺陷定位更加精准,如样例图中杂质与刮痕缺陷的算法测试结果对比;同时,该算法能够检测出更为细致的缺陷目标,如算法对小目标疤痕的有效定位。

图6 算法改进前后样例的检测效果对比Fig.6 Comparison of sample detection results before and after algorithm improvement
4 结论
本文以SSD 检测模型为框架,提出一种轻量级钢表面缺陷目标检测算法EFSSD-MV2。首先,在基础特征融合结构之后加入EFF 单元,其中AWF 模块为不同层级的特征自适应分配融合权重,SFE 模块则重点关注融合特征在3 个方向的全局表达。而后,通过将先验框与真实框的整体交并特性应用于IOU 阈值的自适应计算,使模型在训练阶段能够获得更为合适的数据样本。最后,本文在公共数据集NEU-DET 上进行了算法对比实验,并对影响实验结果的超参数进行分析。结果表明,EFSSD-MV2 算法具有良好的钢表面缺陷检测性能,所提出的改进方法对算法检测精度的提升是十分有效的。下一步将开展高效特征融合结构的研究,从而以更少的计算开销提升算法的检测精度。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子制作(2018年11期)2018-08-04 03:25:38
自动化学报(2017年5期)2017-05-14 06:20:44
数学学习与研究(2017年3期)2017-03-09 18:12:42
测绘科学与工程(2016年5期)2016-04-17 06:51:15
中国老区建设(2016年1期)2016-02-28 09:32:00
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
