
基于机器视觉的手写钢板号图像增强及矫正算法研究与应用
2024-04-23 10:04徐宽广何东隅韩冰刘宇佳李家栋
计算机工程 2024年4期
徐宽广,何东隅,韩冰,刘宇佳,李家栋
(1.南京钢铁股份有限公司板材事业部宽厚板厂,江苏 南京210035;2.东北大学轧制技术及连轧自动化国家重点实验室,辽宁 沈阳 110819)
0 引言
光学字符识别(OCR)文本图像的扭曲变形会影响OCR检测效果,而在钢板号识别的工业应用场景中,钢板位置、钢板号书写位置都存在随机性,每次识别的钢板号图像几乎都存在一定的倾斜角度,人工书写的钢板号则更加复杂,除了更加没有规律的倾斜外,书写的字符行本身还存在扭曲现象,结合字迹深浅不一等情况,更加重了检测难度和识别难度[1-6]。
传统文本区域倾斜校正算法多采用两种方式:一种是采用Hough变换进行图像校正的方法,利用Hough变换发现图像中最长直线,然后计算最长直线的斜率,根据斜率计算水平偏差角度,最后旋转图像使最长直线水平完成倾斜校正;另一种是先获取图像文本区域的最小包围盒,然后同样以最小包围盒的上下边求斜率计算水平偏差角度,最后旋转图像实现倾斜校正。上述两种方式适用于喷印的标准字符检测,对手写造成的字符行扭曲现象纠正效果较差,最终影响识别效果[7-15]。
基于此,本文针对手写钢板号的OCR图像,提出一种OCR文本图像增强及矫正算法。该算法主要基于色阶调整的方式增强手写字符区域与钢板背景的对比度,起到提升检测率的作用,并基于骨骼提取+多项式拟合的方式获取字符行扭曲曲线,再根据二维空间变换算法实现字符行的矫正,消除扭曲效果,起到提升识别率作用。
1 基于机器视觉的钢板号在线检测装置
基于机器视觉的钢板号在线检测装置主要由工业相机、辅助光源、图像处理服务器组成。工业相机采用面阵相机拍摄钢板表面图像,获取钢板号信息;辅助光源用于提升拍摄场景亮度,消除日光、顶棚大灯等其他光线影响,保证相机拍摄区域范围亮度足够且相对均衡;图像处理服务器与工业相机连接,接收采集的图像进行识别处理,同时与过程控制系统通信,传递识别的钢板号信息[16-20]。
1.1 检测流程
在本文项目应用场景中,钢板号在线检测装置部署于辊道旁,使用立柱支架固定,或利用现场墙壁、横梁、立柱固定,保证检测装置高度足够,且视野能够覆盖一定的辊道范围。在本文应用中,相机识别覆盖的辊道范围定义为视觉检测区域,检测区域长度方向范围要求大于钢板号字符行宽度,保证钢板经过辊道运输进入检测区域后,工业相机采集的一帧图像可以呈现完整的钢板号。检测区域示意图如图1所示。
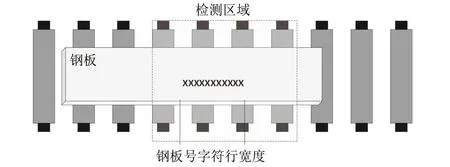
图1 检测区域示意图Fig.1 Schematic diagram of detection area
系统检测方式采用动态检测方式,钢板在辊道上运动,当钢板头部触发检测区域前的光栅信号时,检测装置进入工作状态,开始循环采集图像进行钢板号识别处理,直至钢板尾部离开检测区域,或成功识别钢板号停止。
钢板号识别首先需要对采集图像进行预处理,目标是对图像进行降噪及增强,减弱背景干扰,提升钢板号字符区域的特征,然后采用字符检测模型提取钢板号字符行所在位置,再之后进行字符行的矫正处理,最后通过识别模型得到识别的文本,至此完成一轮图像的检测识别。对于识别结果,检测系统发送给生产跟踪控制系统进行校验,当识别钢板号与计划下发钢板号匹配时,完成该块钢板号的识别检测。
基于机器视觉的手写钢板号自动检测的总体实现流程如图2所示。

图2 钢板号识别检测流程Fig.2 Steel plate numbering identification detection procedure
1.2 图像预处理
钢板号识别硬件装置通常部署在上料辊道处,由于物料钢板是由行车、真空吸盘机从上方吊运至辊道上,为避免干涉,钢板号识别装置通常部署在上料辊道外的立柱高处,斜下拍摄钢板图像,原始图像拍摄效果如图3所示。

图3 原始图像Fig.3 Original image
为了保证最终的识别效果,首先需要对图像进行透视变换,将图像矫正到俯视的角度,透视变换后修正图像如图4所示。

图4 透视变换后的修正图像Fig.4 Corrected image after perspective transformation
2 手写钢板号图像增强及矫正算法
2.1 图像增强
手写字体的线条相比喷印字体往往更加纤细,特征不明显,更容易受到背景的干扰,此时直接基于原图使用检测模型检测字符区域效果较差,存在字符行检查不完整以及漏检的情况。因此,在进行字符行区域检测前,需要提升字符行区域与钢板背景的对比度,使其更加“显眼”[21-24]。
本文采用色阶调整的方式对单驼峰特征图像进行增强,以图4为例,首先获得图像的灰度直方图,如图5(a)所示,在直方图中的175附近出现了单驼峰,也是唯一波峰,可以看出整张图的像素点都集中在该峰附近,参照应用场景可知,该区域应为钢板背景区域,因此低于该波峰的区域都属于背景,需要弱化处理,此处通过提升色阶的起点,起到弱化作用;高于该峰区域部分为偏白色部分,手写字符区域存在于该区域,考虑到图像光照不均匀以及光滑物体反光影响等,白色粉笔字迹通常并不能达到灰度的最大值,因此高于波峰区域需要降低色阶终点,起到字体增强的作用。此外,兼顾手写文本区域的字体存在落笔轻重不一、钢板背景存在明暗不均的情况,最终选择的色阶范围需要包括单峰,也就是钢板区域,色阶起止点则定在波峰左右的两个谷底附近,具体谷底位置采用三角阈值法进行确定,经过三角阈值法的计算,谷底位置如图5(b)中的箭头所示,依据此位置点进行色阶增强,增强后效果如图5(c)所示,可见对比度提升明显。
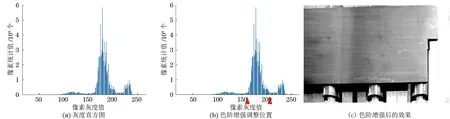
图5 色阶增强过程Fig.5 Color scale enhancement process
2.2 字符区域检测
首先使用机器学习中的文本区域检测模型对文本区域进行提取,本文基于百度PaddleOCR框架的RES-FPN文本区域检测算法,采集500张现场实拍图像进行文本区域检测的标注及finetune优化训练,最终获得字符区域效果如图6所示。

图6 字符区域检测效果Fig.6 Character region detection effect
从图6可以看出,白色粗线条代表了字符行所在的位置,可见字符区域并非水平直线,存在倾斜以及扭曲现象。
2.3 轮廓及字符行提取
基于图6进行轮廓提取,首先进行一次图像形态学中的膨胀操作,扩大白色区域,目的是保证将手写钢板号边缘部分囊括进区域中,保证字符选取完整,避免截断,具体膨胀比例通常设定为:高度 2倍,宽度1.2倍。然后以该图像白色区域作为掩码,提取原始图像的字符区域部分,效果如图7所示。

图7 轮廓字符行提取流程Fig.7 Outline character line extraction procedure
2.4 倾斜矫正
基于图7(c),首先采用传统方式进行倾斜矫正,具体方式为:先获得字符区域的最小包围盒,设包围盒宽为w、高为h,然后以w、h为尺寸创建新图片,最后将包围盒的4个顶点坐标以及新图片的4个顶点坐标一对一建立对应关系,并作为输入条件,使用透视变换方法进行矫正处理,转换效果如图8所示,转换后字符行两端基本处于同一水平线。

图8 字符区域透视变换Fig.8 Character region perspective transformation
2.5 字符行骨骼提取
字符行的骨骼表达了字符行的弯曲程度,如从图8可以看到,进行倾斜校正后字符行左右两端基本处于统一水平位置,但中间区域仍存在扭曲偏离,手写钢板号受书写习惯的影响,通常都会出现该现象,因此需要继续进行扭曲矫正处理。
首先基于图8的转换结果进行宽度方向的图像像素遍历,遍历每一列,然后提取列中白色区域的垂直方向中心点,最后前后连接起来即是字符行的中心线,假设用y0表示x列中从上向下数第1个白色像素位置的纵坐标,y1为x列中从上向下数最后一个白色像素位置的纵坐标,则x列的中心坐标yc如式(1)所示:
yc=y0+(y1+y0)/2
(1)
由此方法遍历图像的每一列后,求得的字符行骨骼中心线如图9所示。

图9 中心线提取Fig.9 Centerline extraction
2.6 多项式拟合
由于字符行受书写时笔画轻重、字符倾斜、字符扭曲以及背景干扰,导致提取的骨骼可能存在断点及毛刺噪声问题,而且钢板号存在字符数量少、扭曲程度小的特征,因此本文方法采用多项式拟合的手段对骨骼进行平滑优化调整,多项式拟合的原理为幂函数可逼近任意函数,如式(2)所示:
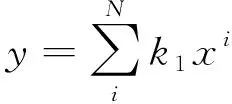
(2)
其中:N为标识多项式阶数,阶数越高,拟合的曲线可变化程度越大。由于字符行变化较小,因此在本文方法应用中N为常量,固定取3,如式(3)所示:
y=k0+k1x+k2x2+k3x3
(3)
将中心线上各个点的横坐标x、纵坐标y代入式(3)中,求得常量k0、k1、k2、k3,然后根据已知公式重新求取骨骼,效果如图10所示。

图10 拟合字符行骨骼曲线Fig.10 Fitting character line skeleton curve
2.7 空间变换
根据第2.6节中求得的骨骼曲线多项式,对图8变换后的结果进行二维空间变换处理,详细处理步骤如下:
1)取得字符行骨骼的中心水平线,设拟合曲线各个点的纵坐标为y,中心线h的计算公式如式(4)所示:

(4)
求得的变换后的中心水平线位置如图11中浅色横线所示。

图11 中心水平线位置示意图Fig.11 Schematic diagram of the center horizontal line position
2)空间变换,主要思路是将原图中骨骼曲线向目标中心水平线靠拢,采用的方式是对原始图像横向扫描,对每一列进行垂直方向的偏移矫正,经过矫正后,根据字符行四周的黑色区域进行剔除(未被写入像素的区域为黑色,灰度值为0),得到字符的有效区域,最后进行一次中值滤波,削弱图像变换过程产生的像素错位问题,算法过程代码描述如算法1所示。
算法1空问转换
输入A bitmap imgSre of sizew×h
输入lines of size n //拟合曲线数组;
输入c// 中心水平线
输出A bitmap imgResult // 输出转换后图像
1. function CORRECTIVETRANSFOR(imgSrc, lines, e)
2. i←0
3. imgResult←0
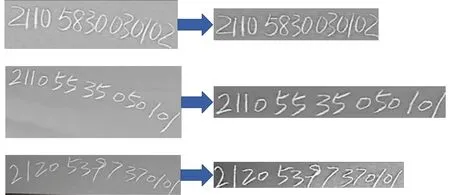
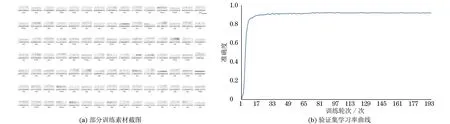
4. while i 5. r←lines[i].x 6. y←lines[i].y 7. j←y-c 8. r←0 9. while j< y+ h do 10. if j >0 and j< h and r 11. imgResulti[i,r]←imgSrc[x,j] 12. end if 13. r←r+1 14. j←j+1 15. end while 16. i 17. end while 18. imgResult←SpaceFiltering(imgResult)//去除//灰度为0的区域外,最大内切矩形范围提取 19. imgResult←MedianFiltering(imgResult,3)//进//行一次中值滤波 20. return imgResult 21. end function 经过算法1矫正后,得到的图像如图12所示,字符行基本处于水平直线,文字信息更加规整,有助于提升CTC(Connectionist Temporal Classification)的切分效果。 图12 最终校正结果Fig.12 Final correction result 随机选择一些手写的素材进行验证,均能得到较好的矫正效果,如图13所示。 图13 素材校正验证效果 Fig.13 Material calibration verification effect 采用第3.1节步骤方式,对现场积累采集的3 220张手写钢板号图像进行矫正处理,然后进行识别模型的finetune训练,其中训练集、验证集和测试集的比例为7∶2∶1,最终训练集准确度为96.86%,验证集准确度为91.52%,测试集准确度为89.23%。识别模型训练过程如图14所示。 图14 识别模型训练过程Fig.14 Recognition model training process 经过图像增强及字符行矫正的预处理操作,使识别模型训练达到了较好的效果,增强了钢板号识别设备应对人工手写钢板号的能力。 钢板号检测应用于在线生产物料的钢板号识别,为了不影响生产节奏,校正算法需要满足一定实时性的要求,通常需要在几秒内完成检测与识别。因此,本文方法所涉及步骤最大化考虑利用CPU并发能力以及GPU并行计算能力,将处理过程压缩在极端时间内,实施现场实际部署的图形工作站电脑配置为:CPU I7 9850,内存 32 GB DDR4 2 667 MHz;显卡 NVIDIA Geforce GTX 3060 Ti 8 GB,开发环境为VS2017,OPENCV4.5.3(GPU编译版本),以此软硬件配置为例,处理一张4 096像素的原始图像,连续测试多轮,各步骤处理时间消耗统计如表1所示。 表1 耗时情况说明Table 1 Describes the time consuming 如表1所示,进行一轮检测合计耗时175 ms,此外本文项目所用识别模型同样采用GPU编译,平均耗时约50 ms。因此,本文项目实际进行一轮钢板号识别总耗时小于等于250 ms,每秒能够进行4次处理,满足现场使用要求。 在实际应用场合中,手写钢板号存在字符行倾斜及扭曲、字体纤细、字迹对比度不足等情况,检测漏检率高,且整体识别率低,传统钢板号识别设备系统无法很好应对。本文针对手写钢板号的特征,提出一种图像增强以及手写字符行矫正方法。经过本文方法处理后文本字迹清晰,字符行工整平直,提供了更好的识别模型训练素材,提高了识别模型的准确率,在整体上提升了手写钢板号识别的应用效果。
3 现场应用与结果分析
3.1 素材校正验证
3.2 应用效果
3.3 方法效率

4 结束语
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10电脑爱好者(2022年15期)2022-05-30故事作文·低年级(2021年12期)2021-12-21作文成功之路·小学版(2020年7期)2020-08-24小学生学习指导(低年级)(2019年12期)2019-12-04电子制作(2019年19期)2019-11-23少儿美术(快乐历史地理)(2018年7期)2018-11-16电子制作(2018年18期)2018-11-14中国自行车(2018年2期)2018-05-09福建人(2016年6期)2016-10-25
