
基于位置信息和注意力机制的路面裂缝检测
2024-04-23 10:03王安政党建武岳彪杨景玉
计算机工程 2024年4期
王安政,党建武*,岳彪,杨景玉
(1.兰州交通大学电子与信息工程学院,甘肃 兰州 730070;2.轨道交通信息与控制国家级虚拟仿真实验教学中心,甘肃 兰州 730070)
0 引言
近年来,随着公路交通的快速发展,人们出行不仅对公路行驶的舒适度和经济性有了较高要求,而且更加关注出行的安全性,公路安全问题成了人们日常生活中的一个热点问题。路面裂缝作为公路病害的常见病害之一,对道路安全具有潜在的威胁[1]。路面裂缝是公路健康状况的重要指标,形成原因主要包括车辆挤压、雨雪渗透和施工质量不佳。若裂缝不及时被修补,则会增加公路安全事故的风险。目前,人工方法结合半自动化方法是广泛使用的路面裂缝检测方式。然而,人工参与检测成本高、效率低,检测结果依赖于检测人员的主观性[2]。因此,为了满足当前对高效路面裂缝检测的需求,研究一种高效且准确的裂缝检测模型具有重要意义,对于提升交通安全具有重要作用。
目前,随着深度学习在计算机视觉领域的广泛应用,已经涌现出多种用于路面裂缝检测的目标检测方法。目标检测通常分为分类和边界框回归两种,其中分类任务主要判断图像中是否存在裂缝,回归任务是对图像中的裂缝进行框选,并得到边界框的顶点信息。文献[3]在模型中使用可变形卷积(DCN)提高复杂场景中的裂缝检测性能。文献[4]利用更快速的区域卷积神经网络(Faster R-CNN)实现路面裂缝的检测。文献[5]改进RetinaNet实现路面裂缝的检测,此方法比两阶段模型计算复杂度小,并且使用Focal loss解决数据不均衡问题。文献[6]提出一种能够建立长距离依赖关系的裂缝检测模型。现有的目标检测方法主要通过回归框实现对裂缝的定位,但普遍存在裂缝检测不准确的情况,并且无法获取裂缝的形状以及参数信息,给后续的裂缝修补带来了很多困难。
此外,大量研究者还通过基于深度学习的图像分割方法来检测路面裂缝。利用分割方法来检测路面裂缝通常分为传统的图像分割和基于深度学习的图像分割2种方法。对于第1种方法:文献[7]提出使用图像阈值分割进行裂缝检测的模型,该模型将动态阈值和图像熵组合使用,但该方法依赖于背景不同的阈值;文献[8]通过Prim最小生成树(MST)实现裂缝的连接和检测,效果优于灰度直方图方法,但未测试噪声图像;文献[9]使用Gabor函数检测背景纹理复杂的裂缝图像,但检测的准确率有待提高;文献[10]采用小波变换(WT)方法获取裂缝图像的检测模型,但该方法容易受到噪声的干扰,不能很好地检测连续性差的裂缝。对于第2种方法:文献[11]提出一种编解码结构的裂缝检测模型,通过学习裂缝的高级特征来实现多尺度深度卷积特征融合,能够分割裂缝区域,但检测到的评估指标不够高;文献[12]通过把图片切割成像素级图像块,然后输入卷积神经网络(CNN)进行训练和测试,但该模型的样本相似度高,需要考虑样本中正负样本的比例,且实现较困难;文献[13]提出一种深度学习和注意力机制相结合的编解码模型,较好地实现对路面裂缝的检测,但检测结果受图像背景影响较大;文献[14]通过残差模块(ResNet)来改进U-Net的卷积层结构,在多个公开数据集上获得了优良的性能,但其并未测试阴影遮挡、背景纹理复杂的裂缝图像,模型鲁棒性不足;文献[15]在U-Net的基础上引入注意力机制和残差模块,但模型的检测指标不够高,有待提升;文献[16]在高分辨率深度神经网络(HRNet)的基础上对模型进行优化,改变上下采样的方式,并在上采样的过程中加入挤压和激励块(SE-Block)对特征进行加强,但裂缝的边缘还需要细化,抗干扰能力有待提高。现有多数分割模型是在编解码器的架构上进行优化和改进的,当存在干扰因素时,模型提取特征和关注目标的能力不够,导致部分像素点会被误识别,从而使得路面裂缝分割不完整。
本文受到现有工作的启发,为了解决路面裂缝检测不完整的问题,提出一种基于位置信息与注意力机制的路面裂缝检测模型(PA-TransUNet),主要工作包括:1)在Transformer的自注意力机制中引入位置信息,以解决裂缝特征空间结构信息和形状信息缺失的问题,避免对裂缝全局特征信息提取不充分;2)设计一种基于注意力门控(AD)的解码模块(AGDM)来提升特征图的融合能力,不只是简单地拼接特征图,而且还使模型对裂缝局部区域进行更针对性的学习,突出有利于裂缝分割的特征,抑制特征图中与裂缝不相关的特征,从而提升裂缝分割的性能;3)使用公开的路面裂缝检测数据集(CFD)、Cracktree200和自制无人机裂缝(UAV Cracks)数据集进行实验验证,所提模型在各个数据集上的F1值均有所提升。
1 基于位置信息和注意力机制的路面裂缝检测模型
将路面裂缝检测看成一个像素级的二分类任务,用0和255像素分别表示背景和裂缝。
1.1 总体结构

图1 PA-TransUNet模型结构Fig.1 PA-TransUNet model structure
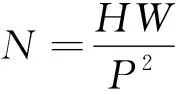
(1)
其中:H和W分别为输入图像的高和宽;P为Patch的大小。
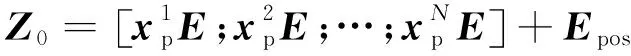
(2)

针对裂缝检测时出现的阴影遮挡、背景复杂造成的裂缝检测不完整问题,TransUNet有优异的性能表现,因此选择TransUNet作为本文的基础网络。
1.2 带有位置信息的自注意力机制
Transformer由VASWANI等[19]于2017年提出并将其应用于机器翻译。在计算机视觉领域,Vision Transformer[20]首创性地应用了Transformer。目前,自注意力机制已经广泛被应用于计算机视觉领域,得益于自注意力机制,模型能够获取卷积神经网络所无法获得的裂缝全局信息,以辅助提升最终输出结果。然而,在获取裂缝全局信息的过程中,自注意力机制并未考虑查询项(q)、键(k)、值(v)的位置信息,而这些位置信息对于捕捉路面裂缝的空间结构和形状也具有重要意义。为了增强对裂缝的空间和形状信息的捕获能力,在Transformer中引入位置信息。这样做有效地解决了在特征提取过程中可能出现的信息丢失问题,并提高了分割的性能。
原始的自注意力机制中并没有考虑到q、k、v的位置信息,如图2所示,输入特征图通过变换矩阵得到q、k、v,q和k相乘结果通过Softmax操作,然后将得到的结果与v相乘得到最终的输出,计算公式如式(3)所示:
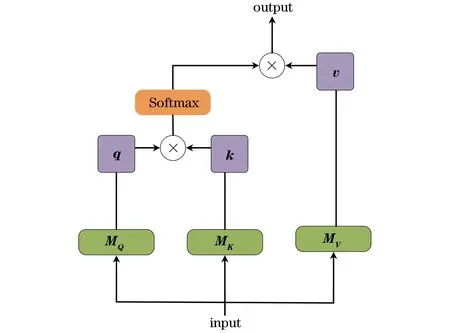
图2 自注意力机制Fig.2 Self-attention mechanism
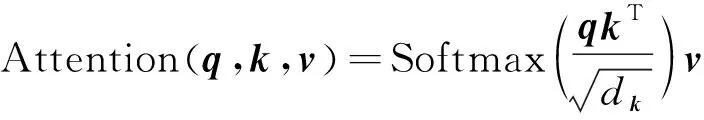
(3)
其中:q=MQx、k=MKx、v=MVx,q、k、v为输入x的线性投影;MQ、MK、MV为可学习的矩阵;Softmax为激活函数;dk为k的维度。
在模型中初始的q、k、v的位置编码通过一个可学习的矩阵初始化获得,然后初始化的位置编码和q、k、v分别相加,赋予每个q、k、v位置信息,这样模型可以根据具体任务学习到更适合的位置表示,计算公式如(4)所示:

(4)
其中:rq、rk、rv分别为q、k、v的位置信息;qposition、kposition、vposition分别为q、k、v初始化可学习的矩阵。
引入q、k、v的位置信息之后的自注意力机制如图3所示,输入特征图通过变换矩阵分别得到q、k、v,此处的q、k、v并没有像式(3)一样直接进行计算,而是q和k先相乘,再分别与自己的位置信息相乘并相加,结果通过Softmax操作分别与v的位置信息和v相乘,最终相加得到输出结果,计算公式如式(5)所示:
Attention(q,k,v)=

(5)
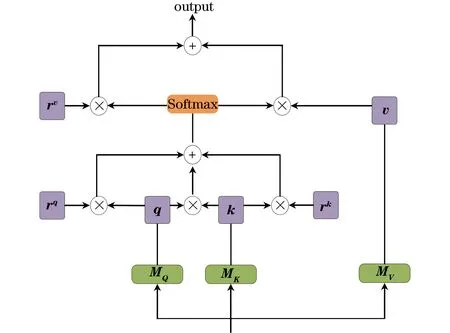
图3 带有位置信息的自注意力机制Fig.3 Self-attention mechanism with location information
1.3 AGDM模块
为了确保网络在训练过程中能够获得更大的感受野,进而捕获足够的特征图上下文语义信息,卷积神经网络会逐渐对输入的原始图像进行下采样。为了提升分割性能,在上采样解码过程中,通过跳跃连接充分利用解码器的深层特征和编码器的浅层特征。然而,原始的TransUNet仅将深层特征上采样并将其与浅层特征融合,随后经过卷积操作和激活函数,这样会缺乏对裂缝局部的精细学习。这种融合过程可能会丢失许多关键特征信息,进而导致裂缝分割不完整。AG可以自动学习聚焦于不同形状和大小的目标结构,抑制输入图像中不相关的区域,同时突出对特定任务有用的显著特征[21]。为了在上采样过程中恢复裂缝的细节信息,提升裂缝分割的完整性,设计AGDM。AGDM主要包含左侧和右侧两个子模块,左侧子模块利用AG增强深层特征和浅层特征之间的特征表达,右侧子模块将经过注意力提取的特征与深层特征进行融合。AGDM结构如图4所示。
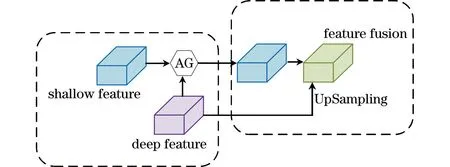
图4 AGDM结构Fig.4 AGDM structure
AG结构如图5所示,其中,g为门控向量,是来自解码器的深层特征图,xl为输入图,是来自编码器的浅层特征图,g和xl分别通过1×1的卷积操作Wg和Wx得到特征图F1和F2。因为g和xl不是来自同一层操作的特征图,g的空间尺寸要小于xl,所以要对g进行上采样,或者对xl进行下采样,然后才可以实现特征图F1和F2的相加操作。

图5 AG结构Fig.5 AG structure
首先,通过特征图F1和F2相加操作得到特征图F3,计算公式如式(6)所示:
F3=F1⊕F2
(6)
其中:⊕为对应元素相加操作。
其次,特征图F3通过ReLU激活函数生成特征图F4,计算公式如式(7)所示:
F4=ReLU(F3)
(7)
其中:ReLU表示激活函数。
再次,特征图F4通过ψ操作,ψ操作是一个卷积操作,该卷积操作的作用是通过一个1×1的卷积核对输入特征图F4进行卷积运算,生成一个通道数为1的新特征图F5,计算公式如式(8)所示:
F5=f1×1(F4)
(8)
其中:f1×1()为1×1的卷积操作。
然后,特征图F5再通过一个Sigmoid激活函数生成特征图F6,计算公式如式(9)所示:
F6=Sigmoid(F5)
(9)
其中:Sigmoid表示激活函数。
最后,通过上采样对特征图F6的尺寸进行重构,使其与输入特征图xl的尺寸相同,得到注意力系数矩阵α,计算公式如式(10)所示。输入xl与α通过相乘的操作得到最终的输出。
α=fup(F6)
(10)
其中:fup()表示上采样操作。
2 实验设置
2.1 实验环境与配置
使用PyTorch深度学习框架,硬件为Intel®Xeon®CPU E5-2678 v3,实验使用的显卡为NVIDIA Tesla K80,显卡内存为12 GB。在训练过程中,选用SGD优化器对模型进行优化,学习率设置为0.01,动量系数为0.9,衰减值为0.000 1,设置的批次大小为16,迭代次数(epoch)为100。
2.2 数据集
为了验证所提模型的有效性,选取公开数据集CFD、Cracktree200和自制数据集UAV Cracks进行实验。
CFD数据集由SHI等[22]创建,包含118张分辨率为480×320像素的北京城市道路路面裂缝图像,图像中包含了水渍、阴影等噪声。Cracktree200数据集由ZOU等[23]创建,包含206张分辨率为800×600像素的路面裂缝图像,这些图像被进行了像素级标注,其中包含了阴影遮挡、背景复杂等噪声。UAV Cracks数据集是一种自制数据集,使用无人机对甘肃省路面进行拍摄而得,该数据集包含了299张分辨率为512×512像素的路面裂缝图像,图像中包含了水渍、行车线等噪声,旨在测试模型在实际工程应用中的性能。此外,由于光照条件、视角和尺度等因素影响,无人机收集的道路裂缝图像可能更具挑战性[24]。
由于3个数据集的数据量较小且所提模型需要输入256×256像素的图像,因此对数据集进行数据增强操作,包括随机裁剪、亮度调整、对比度调整和角度调整等。最终CFD数据集包含3 150张图像,Cracktree200数据集包含3 000张图像,UAV Cracks数据集包含3 800张图像,将每个数据集按照8∶1的比例随机分为训练集和测试集。当训练数据较少时,模型可能会过度依赖有限的样本,导致在新的未见过的数据上表现不佳。通过数据增强操作,可以有效地扩大训练数据集的规模和增加数据多样性,避免模型在训练过程中出现过拟合的现象。
2.3 评价标准
为了对比评价所提模型的分割性能,主要使用了精确率(P)、召回率(R)、F1值(F1)、交并比(IoU)4个性能评价指标。
精确率是指在预测为正的样本中真正样本所占的比例,计算公式如式(11)所示:
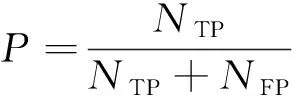
(11)
其中:NTP表示模型将样本中的正样本正确预测为正样本的数量;NFP表示模型将样本中的负样本错误预测为正样本的数量。
召回率是指在所有的正样本中被预测为正样本的比例,计算公式如式(12)所示:
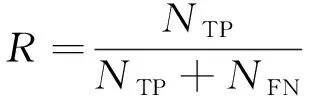
(12)
其中:NFN表示模型将样本中的正样本错误预测为负样本的数量。
F1值是精确率和召回率的调和平均值,在分割任务中常用来评价模型的分割性能,F1值越高代表模型性能越好,计算公式如式(13)所示:
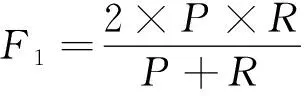
(13)
交并比是真值集合和预测集合之间交集和并集的比例,计算公式如式(14)所示:
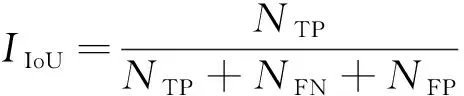
(14)
2.4 损失函数
路面裂缝检测属于二分类的分割任务,并且由于路面裂缝的形态差异,会导致在路面裂缝数据集中存在严重的正负样本不平衡现象,因此经典二值交叉熵(BCE)损失函数不适用于分割正负样本极不平衡的任务,计算公式如式(15)所示:
LBCE=
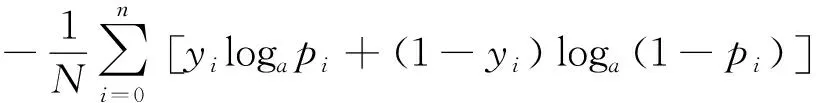
(15)
其中:LBCE代表二值交叉熵损失函数;N代表分类的类别数;yi代表第i个像素的标签值;pi代表第i个像素的预测概率值。
在路面裂缝分割任务中,如果只使用交叉熵损失函数训练模型,则会使得模型更倾向于分割占比更大的类别,而裂缝恰巧是占比更小的类别,因此采用适用于解决这种样本不平衡问题的Dice损失函数,计算公式如式(16)~式(17)所示:

(16)
(17)
其中:DDice代表Dice系数;LDice代表Dice损失函数。
将BCE和Dice损失函数组合使用,不仅能够保证像素的有效性,而且还能够解决样本中正负样本不平衡的问题,计算公式如式(18)所示:
L=(1-λ)LDice+λLBCE
(18)
其中:L为总的损失;λ为交叉熵损失函数所占权重,在训练过程中λ被设定为0.5。
本文的裂缝检测任务属于图像分割任务的范畴,而像素点分类则是作为该分割任务的一个辅助任务。因此,在衡量模型输出与真实值之间差距的交叉熵损失函数中,应该避免将权重设置过大。如果权重过大,则模型会更加倾向于预测占比较大的背景像素,进而影响分割结果的准确性。
3 实验结果与分析
为了验证所提模型的有效性,将其与TransUNet[17]、Attention U-Net[21]、SegNet[25]、U-Net[26]、DeepCrack[27]5种先进的深度学习模型进行实验对比,并在CFD、Cracktree200、UAV Cracks数据集上进行训练和测试。
3.1 CFD数据集实验
为了验证所提模型对裂缝图像的分割性能,在CFD数据集上进行实验,不同模型的实验定量结果如表1所示,其中最优指标值用加粗字体标示,下同。由表1可以看出,PA-TransUNet优于其他分割模型,F1值达到87.44%,交并比达到78.52%,相比于原始TransUNet模型分别提升了2.24和3.67个百分点,能够达到更好的裂缝分割效果。然而,PA-TransUNet在精确率上没有取得最优值,但是较原始的TransUNet提升了2.82个百分点,可能的原因为模型在预测过程中分割的裂缝更加明显,使得裂缝边缘的1或2个像素点也被预测为裂缝像素所致。
为了能够更加直观地感受不同模型的分割差异,展示了3幅测试集中图片在不同模型上的分割结果,如图6所示。通过对比3幅图片发现,经典分割模型SegNet、U-Net、Attention U-Net、DeepCrack对于较为复杂的裂缝分割效果很差,出现很多漏检的情况,虽然原始TransUNet的分割效果要优于前面4种模型的分割效果,但也存在裂缝细节部分的漏检,从标注框中可以看出,PA-TransUNet的分割效果更好,分割的裂缝与真值标签最相似,很少出现漏检、误检的情况。
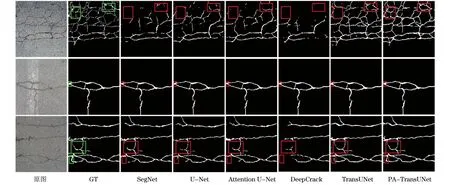
图6 CFD数据集上的可视化效果对比Fig.6 Visual effect comparison on CFD dataset
3.2 Cracktree200数据集实验
为了进一步验证所提模型的有效性,在Cracktree200数据集上进行了实验,不同模型的定量实验结果如表2所示。由表2可以看出,PA-TransUNet的精确率、召回率、F1值和交并比分别达到83.55%、81.64%、82.58%和69.70%,相比于在CFD数据集上的定量结果,在Cracktree200数据集上PA-TransUNet相对于SegNet、U-Net、Attention U-Net和DeepCrack的分割性能提升更加明显,F1值和交并比相对于原始TransUNet分别提升了0.96和0.84个百分点,指标提升不明显的主要原因为:1)该数据集的数据比较单一,大多是比较简单的裂缝,存在少量阴影遮挡的裂缝,虽然PA-TransUNet在检测阴影遮挡的裂缝时效果有显著提升,但此类数据的数量远少于普通的裂缝;2)数据的标注过于精细,正负样本严重失衡。
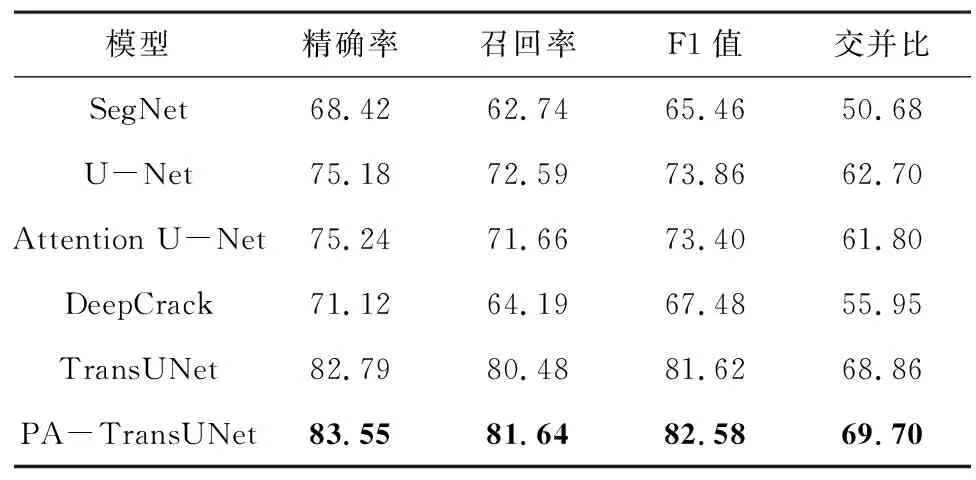
表2 不同模型在Cracktree200数据集上的评价指标对比Table 2 Comparison of evaluation indexes of different models on Cracktree200 dataset %
为了能够更加直观地观察不同模型在Cracktree200数据集上的分割性能,选取4幅测试集中的图片进行可视化对比,如图7所示。通过对比4幅图片发现:对于第1行简单路面裂缝的分割,6种模型的分割性能并没有太大差别,只是在一些细节处理方面PA-TransUNet表现更好;对于第2行复杂路面裂缝,SegNet、U-Net、Attention U-Net和DeepCrack的分割效果远不如TransUNet和PA-TransUNet;对于第3、4行这种阴影遮挡的路面裂缝,SegNet、U-Net、Attention U-Net、DeepCrack和TransUNet的分割出现大量的漏检情况,而PA-TransUNet表现出更好的分割性能。观察图8的分割结果可以看出,PA-TransUNet把原图中存在但真值标签中没有标注的裂缝也检测了出来。
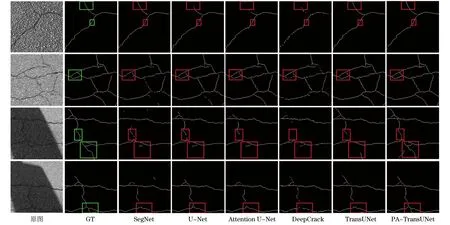
图7 Cracktree200数据集上的可视化效果对比Fig.7 Visual effect comparison on Cracktree200 dataset

图8 PA-TransUNet检测结果对比Fig.8 Comparison of PA-TransUNet detection results
3.3 UAV Cracks数据集实验
为了验证所提模型在实际工程中的应用,使用UAV Cracks数据集对模型的性能进行实验验证,自制的UAV Cracks数据集更具挑战性,其中背景更加复杂,裂缝更加不明显。不同模型的定量实验结果如表3所示。由表3可以看出,PA-TransUNet的所有评价指标均优于SegNet、U-Net、Attention U-Net和DeepCrack,精确率、召回率、F1值和交并比分别达到了90.84%、86.62%、88.68%和80.90%,较原始的TransUNet的F1值和交并比分别提升了3.78和5.66个百分点。可见,PA-TransUNet在公开数据集和自制数据集上都取得了较好的分割结果,表明其具有更好的泛化性。
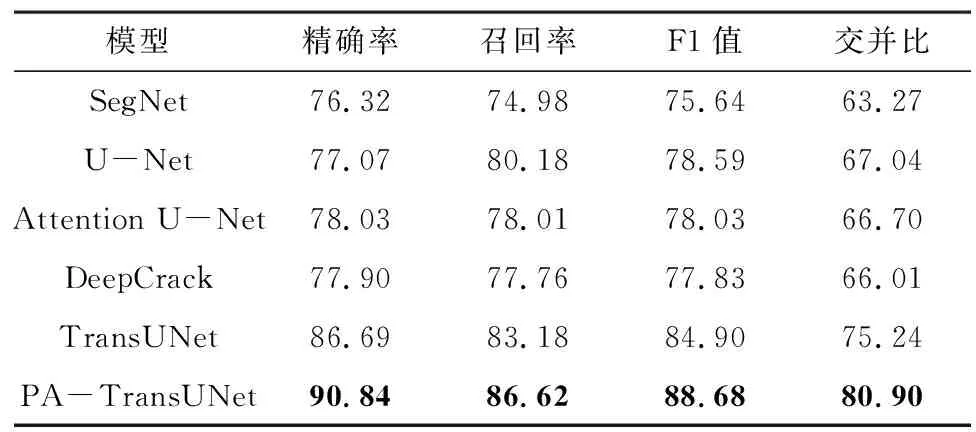
表3 不同模型在UAV Cracks数据集上的评价指标对比Table 3 Comparison of evaluation indexes of different models on UAV Cracks dataset %
为了更加直观地观察各个模型的分割性能,选取4幅测试集中的图片进行可视化对比,如图9所示。由图9可以看出,SegNet、U-Net、Attention U-Net和DeepCrack在UAV Cracks数据集上对于背景复杂的路面裂缝会出现大量的误检和漏检现象,原始的TransUNet的表现优于前面4种模型,但是在某些部位的检测也会出现漏检现象,而PA-TransUNet的分割性能要优于前面5种模型,误检和漏检的情况比较少,证明了该模型的性能更好,可以应用在实际工程中。
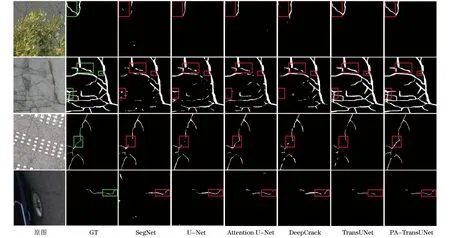
图9 UAV Cracks数据集上的可视化效果对比Fig.9 Visual effect comparison on UAV Cracks dataset
3.4 消融实验
为了验证本文在编码器的Transformer中引入q、k、v的位置信息和AGDM模块的有效性,选择在CFD数据集上将其与原始TransUNet进行对比测试,在与上文同一个环境下进行消融实验。消融实验总共分为4组,实验0是原始的TransUNet;实验1在原始TransUNet的基础上改进编码器的Transformer,即为q、k、v引入位置信息;实验2是在原始TransUNet的基础上改进解码器部分,即使用AGDM模块;实验3是在原始TransUNet上结合第2组和第3组的改进。
表4为消融实验的对比结果,其中,N表示未使用该信息和模块,Y表示使用该信息和模块。由表4可以看出:对比实验0和实验1可以发现,F1值和交并比分别提升了0.98和1.09个百分点,验证了在编码器的Transformer中引入q、k、v的位置信息可以提升分割性能;对比实验0和实验2可以发现,F1值和交并比分别提升了1.81和3.23个百分点,验证了AGDM模块可以提升分割性能;对比实验0和实验3可以发现,F1值和交并比分别提升了2.24和3.67个百分点,验证了两个改进部分的结合可有效提升分割性能。

表4 消融实验结果对比Table 4 Comparison of ablation experiment results %
通过在编码器的Transformer中引入q、k、v位置信息,模型能够更好地关注裂缝的形状,从而提高了分割裂缝的准确性。同时,本文设计的AGDM模块有效地融合了浅层特征和深层特征,进一步提升了模型在分割裂缝中的精度。综上所述,两个改进部分对提升模型的路面裂缝分割性能方面起到了积极作用,并且两者的结合达到了更好的效果。
4 结束语
本文提出一种基于位置信息和注意力的PA-TransUNet模型,旨在解决路面裂缝在背景复杂、阴影遮挡等干扰因素下分割不完整的问题。由卷积神经网络和Transformer混合的编码器对全局特征提取不充分,在Transformer的自注意力机制中引入位置信息,实现了模型对裂缝形状信息和空间信息的充分提取,在特征提取部分确保局部信息和全局信息的有效结合提升了分割的完整性。考虑到采用直接拼接的编码模块的特征融合能力弱,设计AGDM模块,增强了深层特征和浅层特征的融合能力,突出裂缝特征并抑制不相关特征,从而提高了裂缝分割的准确性。在CFD、Cracktree200公开数据集以及UAV Cracks自制数据集上的实验结果表明,PA-TransUNet模型取得了较好的裂缝分割效果,可应用于实际工程任务。由于本文通过Transformer提取全局信息,造成模型的计算量较大和复杂度较高,因此后续将考虑采用轻量化的Transformer结构进一步改进PA-TransUNet模型。
猜你喜欢
石油与天然气地质(2021年3期)2021-06-29
鸭绿江(2021年35期)2021-04-19
中学生数理化·高一版(2021年2期)2021-03-19
疯狂英语·新悦读(2019年11期)2019-12-18
知识经济·中国直销(2018年8期)2018-08-23
意林·全彩Color(2018年7期)2018-08-13
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
专用汽车(2015年4期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
