
基于深度学习的中文讽刺定义与识别研究
2024-04-23 02:29:16张艺博
中阿科技论坛(中英文) 2024年4期
严 帅 张艺博
(成都锦城学院,四川 成都 611731)
在语言学与计算机两大研究领域,尤其是在对中文复杂情感识别的探索中,讽刺与反语、反讽这两个近义词在定义上经常产生混淆。深度学习作为近年来人工智能领域逐渐成熟的技术,为我们提供了全新的视角与方法来探索和理解这类复杂的语言现象。其通过模拟人脑神经网络的工作原理,在大量语料库中学习和提取语言的深层次特征,从而能够实现对中文讽刺等复杂情感的精准识别。
无论是社交媒体情感分析,还是智能客服语义理解等场景,都需要对中文讽刺进行准确的识别和处理以提升任务效果。讽刺与反语、反讽虽然在情绪表达的功能与效果上较为相似,但在具体界定和语境运用上存在一定的差异。这种差异可能导致语料库构建过程中采集和标注的不准确,进而影响基于深度学习的中文讽刺识别分类模型的训练效果。因此,有必要深入分析讽刺规律,探索有效的讽刺语料库有效性验证方法,以及利用注意力机制捕捉与讽刺密切相关的上下文信息,以提升模型训练效果。
1 中文讽刺及其近义词定义
1.1 反语的定义
《辞海》将“反语”定义为用与本意相反的话语来表达本意。李泽娟(2010)认为反语可以等价理解为说反话[1]。阎苹等(2009)则认为反语是通过使用与字面意思相反的话语来表达难以直接表述的内容[2]。反语可划分为正义反说和反义正说两类。正义反说指用否定的形式来表达肯定的意思,从而形成一种反差的效果。这种反差不仅增强了语言的趣味性,还使得表达的内容更加引人注目。例如“自古以来主贤臣直,……今魏征敢于立言劝谏,全赖圣上贤明”[3]中,“赖”字与夸奖本意的相反关系。反义正说则是用肯定的形式来表达否定的意思,这种方式与正义反说正好相反,它是通过将负面的内容以正面的方式表达出来。如“我真是喜欢让我春游不了的雨天”(出自本文构建的数据集IROLIT 2024)中,“喜欢”一词与不喜欢本意的相反关系。反语的修辞重点在于“反”而不在于反讽和讽刺两种修辞所着重强调的“讽”,这是反语与两者最明显的区别。
1.2 反讽的定义
《辞海》将“反讽”定义为语境对一个陈述语的明显的歪曲。曾衍桃(2006)认为作者在生成反讽时关注的生成重点在于是否产生嘲弄嘲讽的情绪,而不着重在于说反话[4]。本文认为,反讽是通过言辞与实际情况之间的明显矛盾来表达言外之意的一种修辞方式。它往往依赖于特定的语境和听者的理解,因为字面上的意义与实际意图之间存在差异。反讽与反语之间存在“反”这一共性,但反语主要依赖于字面意义与实际意图之间的反差,而反讽则更侧重于言辞与实际情况之间的矛盾。如“多养珍禽异兽,敌人就不敢来了,如果敌人从东方来了,可以下令麋鹿把他们顶回去,就不用士兵了”[5]中,表面是通过言辞在赞同“多养珍禽异兽以抵御敌人”的主意,实际上“珍禽异兽能够抵御敌人的能力”与事实之间存在明显矛盾,正是这种矛盾构成了反讽的核心。
1.3 讽刺的定义
《辞海》将“讽刺”定义为用讥刺和嘲讽来揭露、挖苦丑陋的落后事物和荒谬行为。范岳(1981)认为讽刺时常以反语的形式表现出来,且有些讽刺的效果是通过说话者的语言同他所要表达的真实思想之间的矛盾性造成的[6]。曹婉君(1999)则认为反语可以具有讽刺意味,但大多数情况下并不具有讽刺意味[7]。本文认为讽刺是反讽的扩展,讽刺在反讽的定义基础上不再过于依赖言辞与实际情况之间的矛盾,而是引入了讽刺情景信息详细度与客观事实矛盾需求间的反比关系。讽刺情景信息详细度越接近于极限,讽刺对语境反转陈述句表面意思的需求就越低,同时讽刺还常运用比喻和夸张等修辞手法。整个句子没有构造反转和矛盾,而是通过细化阐述以提高讽刺情景信息详细度,并降低对客观事实矛盾的需求或使用夸张手法。
2 中文讽刺语料库现状
目前已有的中文讽刺识别研究中存在语料库规模太小、讽刺数据标注方法不够准确等语料库质量问题。Tang等(2014)用基于表情符的规则从plurk挖掘繁体中文讽刺语料1 005条,并总结了多种讽刺语言模式[8]。此语料库基于传统反语的“说反话”定义,但将数据归类为“高强度副词短语+正形容词短语+负面背景”“高强度积极形容词+负面背景”“高强度积极名词+负面背景”等基于语法结构的反讽分类模式,存在定义不明、反讽分类模式泛用性较低等语料库质量问题。例如,给词语添加双引号制造反语以及将语境联系产生反讽等多种反讽模式都无法归类进Tang的讽刺模式中。大部分讽刺研究者都是直接使用已有语料库或在已有语料库基础上进行少量扩充。例如,李明峰等(2018)使用Tang标注的1 005条讽刺语料与从COAE2014中抽取筛选的2 000条非讽刺语料构成语料库[9]。Sun等(2016)通过人工筛选,从新浪微博获取了1 030条讽刺语料,加上Tang的1 005条反讽语料以及从微博、博客随机获取的1 000条非反讽语料,共同构建了一个包含反讽、讽刺和正常三个类别的语料库[10]。但这些语料库存在的共有问题是忽视了语料库的质量对模型效果的影响。即便对模型进行了优化,也没有很好把握到讽刺文本的多种特征。
3 讽刺识别相关技术
3.1 卷积神经网络
卷积神经网络(CNN)是主要用于处理网格状数据的神经网络,其通过卷积层对数据的空间层级特征自动进行提取,并通过池化层减小数据的空间维度[11]。通过对多层次的抽象特征表示进行学习,CNN模型能更好地理解和捕捉输入文本数据的局部和全局结构。
讽刺文本有时是短小的句子,CNN能通过卷积操作捕捉局部的语义特征,有效地识别一些局部的情感表达。CNN通过卷积核的滑动操作可保持平移不变性,即模型能无视情感表达所在位置影响来检测情感特征。这对处理讽刺文本中情感信息的位置不确定性有一定帮助。
3.2 长短时记忆网络
长短时记忆网络(LSTM)[12]作为一种特殊的循环神经网络(RNN),相比传统的RNN结构,其设计的初衷在于解决长期依赖问题。LSTM的核心结构包括细胞状态、输入门、遗忘门和输出门。这些组件使得网络具有了长期记忆、抗梯度消失和灵活性等特点。在处理讽刺文本这样的复杂长语境时,LSTM具有独特优势。讽刺文本通常具有多层次的语义结构和丰富的上下文信息,传统模型往往难以捕捉其中的长期依赖关系。而LSTM能够通过其门控结构对文本中的关键信息进行更有效的提取,特别是其对输入的敏感性可调,使得网络能够根据情感表达的细微变化进行灵活调整,从而更好地捕捉讽刺文本中的情感信息变化。此外,LSTM对变长序列的处理能力也使其更适应讽刺文本的多样化长度,为讽刺识别模型的建模提供了更大的灵活性。
3.3 注意力机制
注意力机制允许神经网络在处理输入数据时集中注意力于相关的部分。其克服了传统神经网络中随着输入长度增加系统的性能下降、输入顺序不合理导致系统的计算效率低下、系统缺乏对特征的提取和强化等局限,能更好地建模具有可变长度的序列数据,以此增强自身捕获远程依赖信息的能力,在减少层深度的同时提高精度[13]。
在深度学习中,注意力机制能够通过不断调整权重的方式将网络的关注点聚焦于数据中最重要的小部分。注意力机制会对序列中各元素与其余元素之间的相似度进行计算,并归一化为注意力权重。再将每个元素与其注意力权重进行加权求和,以产生自注意力输出。注意力机制对中文语境讽刺文本的处理,在理想情况下会对每个元素计算相似度,找出差值过大个体并增大其输入权重。相似度差值过大的元素,为语句中的不和谐元素,即讽刺语句中“反”的部分。因此,在由注意力机制对语句中的不和谐元素增大权重后,模型相比引入注意力机制前能更精确地捕捉到讽刺语句的特点,从而增强模型训练效果。
4 实验与分析
4.1 基于近似关系的讽刺定义
基于对讽刺及其近义词定义与相互关系的探讨,本文认为无论是自身真实意图与陈述句表面意思相反的讽刺型反语,还是通过语境来反转陈述句表面意思的反讽,都属于讽刺领域的一部分。反语中的大部分反义正说和少部分带有幸灾乐祸的正义反说属于讽刺型反语,反讽与讽刺型反语由于各自“反”的性质不同所以两者是讽刺中相隔离开的概念,讽刺相比反讽而言有更多的情景信息以及修辞手法的使用,其所含情景信息越多,修辞手法程度越强,对语境反转陈述句表面意思的需求就越低,在情景信息详细度与修辞手法程度达到一定量时,无须任何种类的“反”都可以体现出讽刺。所以讽刺是部分反语、小情景反讽、修辞讽刺和大情景讽刺共同组成的概念,有必要从词语反向、事实违背、修辞强度、情景信息量与事实反向间的关系等方向展开探讨。
4.2 IROLIT 2024讽刺语料库构建与探索
本文基于近似关系的讽刺定义提出更符合讽刺产生规律的讽刺文本采集标准,此标准将词语反向和事实违背量化为违和度,将修辞强度量化为标点符号的使用情况,将情景信息量量化为文本长度。其中违和度包括“形容词褒贬不和谐”“感谢或期望不和谐”“同音字或谐音字替代不和谐”“双引号表反义不和谐”“称呼与自嘲不和谐”“专有名词及关联标题不和谐”“程度不和谐”。为保证文本分类的可靠性,采用人工采集与标注方法。本文分别从Tang的语料库获得了946条(2014年)、从新浪微博采集了1 331条(2018年)、从B站采集了670条(2024年),共计2 947条中文讽刺文本,与2 947句从三个采集点随机采集的非讽刺文本构成共计5 894条文本的中文讽刺语料库IROLIT 2024,其文本长度单位为字符。此语料库中的讽刺文本长度分布与非讽刺文本长度分布大致接近,且0~20字符长度之间的文本数量分布的坡度远比20~30和30~100字符长度之间的文本数量分布的坡度陡峭。可以发现,各社交媒体的用户在发表看法时更倾向于使用字符长度为20~100的文本。不论是讽刺还是非讽刺文本,如果社交媒体用户希望表达复杂情感,都需要结合一定情景信息量,而情景信息量的多少很大程度上取决于文本长度。
为验证中文讽刺特征规律随时间变化这一观点,本文对自建自标注IROLIT 2024语料库进行了中文讽刺情感符号使用频度随时间变化的统计分析。
本文对数据集中所包含的三个来源的数据分别按照时间进行了统计,三个来源分别是2014年的plurk,2018年的新浪微博和2024年的B站。为保证结论的严谨性,之后又从2024年的plurk、新浪微博、B站各采集100条文本作为同一年代不同平台条件下的补偿文本,用于补偿平台不同对统计结果的影响,提高统计结果的可靠性。以下是补偿系数和补偿结果公式:

图1 中文讽刺情感符号频度随时间变化规律
4.3 对抗训练及注意力机制效果实验
本节实验在训练时语料库均采用4.2节中建立的IROLIT 2024讽刺语料库,并对各模型学习率和训练轮数等参数的设置进行了统一,以保证对比结果的变量控制。考虑到本文将中文讽刺识别任务设定为文本二分类的任务,选择常用于文本分类任务的两种实验性能指标——准确率和F1值作为本实验中评价模型性能的指标。按照语句长度分布规律使用IROLIT 2024对Tang的含1 005条讽刺语料的COLING 2014语料库进行了非讽刺文本的补充,使其变成由数量均衡的讽刺文本和非讽刺文本构成的COLING 2014_Z语料库。之后对IROLIT 2024和COLING 2014_Z进行了十折交叉,将两个语料库各自分成了训练集、验证集和测试集并分两种情景进行对抗训练实验。情景一是使用COLING 2014_Z自身的训练集、验证集和测试集在各模型上进行训练和测试。情景二则是使用COLING 2014_Z的训练集、验证集和IROLIT 2024的测试集在各模型上进行训练。训练模型构建了TextCNN、TextRCNN、DPCNN、TextRNN、Transformer、LSTM、FastText这7个深度学习常用模型,训练效果如表1所示。
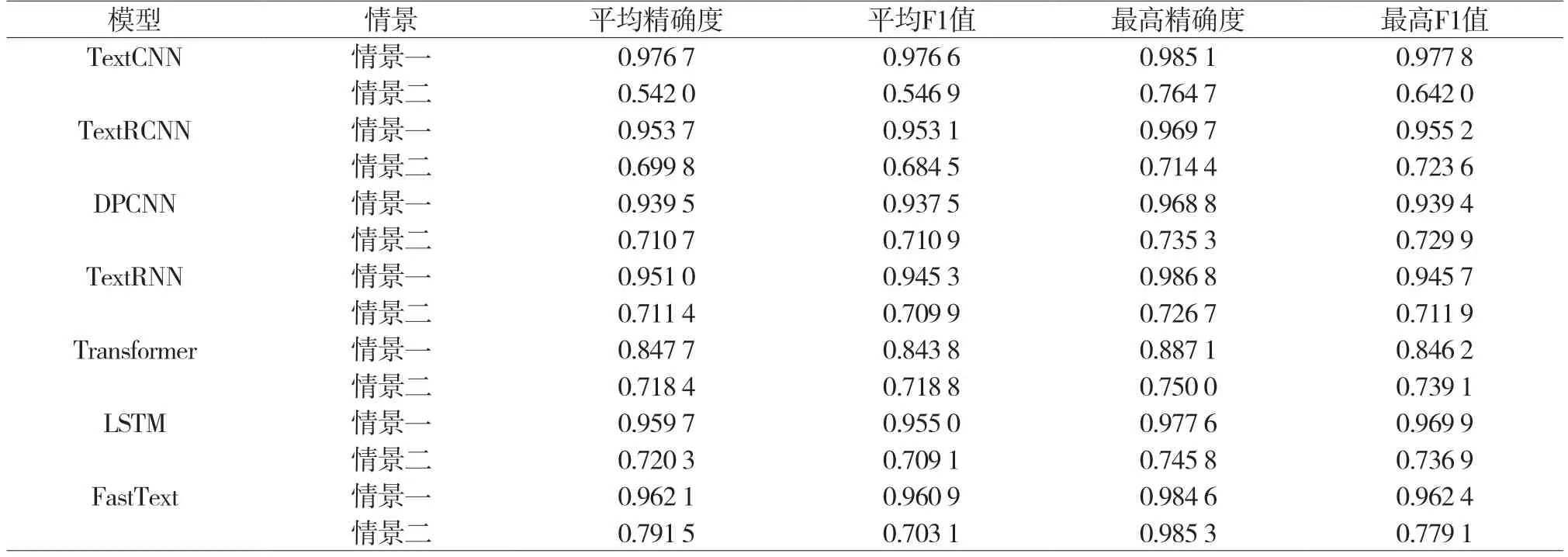
表1 对抗训练情景实验结果比较
对抗训练实验结果表明,即使用于测试的IROLIT 2024测试集中包含一些COLING 2014_Z语料库在训练中已见过的文本,依旧让原本在情景一中自身测试集上获得了较高精确度和F1值的COLING 2014_Z语料库在情景二中IROLIT 2024测试集上获得的精确度和F1值产生了明显的下降,最终在所有训练模型上的平均精确度下降了25.51%,平均F1值下降了26.94%。
依据对抗训练情景实验结果,本文认为传统讽刺定义过于宽泛,易产生定义不清的问题。COLING 2014语料库采用的讽刺模式定义的范围也过于狭窄,很大程度上影响讽刺语料库中讽刺种类与特征的多样性以及在这一语料库上训练获得的模型的泛化性能。本实验采取使用新语料库的测试集对以往语料库进行测试攻击的方式,证明了本文基于近似关系的讽刺定义相比以往中文讽刺语料库构建的讽刺定义标准,能更好地捕捉不同种类和特征的中文讽刺文本,且拥有更好的泛化性能与可靠性。
此外,本文还选取TextRNN模型与LSTM模型进行注意力机制效果实验,并与引入注意力机制后的TextRNN_Att和LSTM_Att模型训练效果进行对比,结果如表2所示。

表2 注意力机制效果实验结果比较
注意力机制效果实验结果表明,引入注意力机制后,RNN模型各方面性能反而下降,而LSTM模型则有明显提升。推测RNN由于其简单循环结构,加入注意力机制后可能无法有效利用额外信息而性能下降,同时RNN更容易受梯度消失影响,此缺点会在引入注意力机制后进一步加剧,而注意力机制需要更稳定的梯度来进行学习。相比之下,LSTM本身已经具有处理长期依赖的能力,引入注意力机制后,LSTM获得了更加精细的信息筛选方式,使得模型在预测每个输出时,能够更加准确地关注到对应的输入信息。因此,引入注意力机制在对中文语境讽刺的判断任务中并不一定对所有架构的模型都具有正向作用,是否引入这一机制需要结合实际情况判断。
5 结语
本文提出了新的讽刺定义并按照该定义构造了新的中文讽刺语料库IROLIT 2024,为未来的中文讽刺语料库构建提出了中文讽刺标注改进思路。随后基于新语料库进行了中文讽刺情感规律的探索,得出了语料库长度分布特点及用户讽刺习惯随时间推移在不断变化的结论,为将来如何更符合讽刺发展规律地选择和捕捉中文讽刺特征提供了新的思路和角度。
本文重点分析了深度学习技术融入讽刺识别任务的思路,包括CNN、LSTM、注意力机制等,特别是通过实验分析证明了基于新定义的语料库构建方法的有效性,并结合新语料库验证了注意力机制的引入进一步帮助神经网络模型捕捉中文讽刺的上下文特征,但也存在梯度问题风险。此发现不仅为未来自然语言处理研究者提供了新方法,也为相关具体应用提供了风险规避建议。
展望未来,研究将持续关注中文讽刺的语言学解构、中文讽刺相关规律探索、注意力机制优化以更好地捕捉中文讽刺特征等方向,以期推动自然语言处理技术进一步发展。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
传媒评论(2017年3期)2017-06-13 09:18:10
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
外国语文(2017年3期)2017-03-11 15:11:53
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
广州大学学报(社会科学版)(2016年7期)2016-03-09 09:22:39
语言与翻译(2015年4期)2015-07-18 11:07:45
福州大学学报(哲学社会科学版)(2013年4期)2013-04-18 08:33:55
当代外语研究(2010年3期)2010-03-20 14:36:38
