
基于双向注意力机制的多模态关系抽取
2024-04-23 10:03吴海鹏钱育蓉冷洪勇
计算机工程 2024年4期
吴海鹏,钱育蓉,3,冷洪勇
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆维吾尔自治区信号检测与处理重点实验室,新疆 乌鲁木齐830046;3.新疆大学软件学院,新疆 乌鲁木齐 830046)
0 引言
关系抽取是知识图谱构建的基本任务,也是自然语言处理(NLP)的重要任务之一,旨在从给定句子中抽取出实体间的关系。传统的关系抽取方法主要是纯文本的单模态方法,只利用文本信息进行关系抽取。传统关系抽取方法通常从一段文本中提取出指定的关系三元组,具体表现形式为
近些年,社交网络发展迅速,单模态的关系抽取方法已经无法满足海量多模态数据抽取的需求,因此多模态关系抽取技术应运而生。多模态关系抽取任务的输入为一个多模态实例L,它包含一个文本T和一个与文本关联的图像I。文本T由一个单词序列组成,即T={w1,w2,…,wi,…,wn},其中,wi表示第i个单词。在文本T中,有2个被标记的实体E1和E2,任务的目标是利用文本T以及图像I的信息预测实体E1和E2之间的关系类型r。
现有的多模态关系抽取方法利用图像数据作为文本数据的补充,以辅助模型进行关系抽取,但实际上图像中往往存在与文本无关的冗余信息,而在现有方法下这些冗余信息最终会影响关系抽取的结果。
为了解决这一问题,本文提出一种基于双向注意力机制的多模态关系抽取模型。与仅计算图像到文本的单向注意力的现有模型不同,该模型利用双向注意力机制计算图像到文本与文本到图像2个方向上的注意力分布。这样图像中与文本更相关的物体将被赋予较高的权重,而与文本无关的冗余信息被赋予较低的权重。通过该模型可以在多模态关系抽取中削弱冗余信息的影响,从而提高抽取结果的准确性,并且在公开的用于神经关系提取的多模式数据集(MNRE)[1]上进行了实验验证。
1 相关工作
1.1 多模态关系抽取
关系抽取作为知识图谱构建的关键环节[2],长期以来都是学者们关注和研究的重要领域。早期的关系抽取方法主要是基于统计学[3],近年来随着神经网络与深度学习的兴起,大量基于深度学习与神经网络的方法开始出现。
基于神经网络的关系抽取方法起初多数依赖于外部NLP工具[4],容易受到NLP工具带来的错误影响,学者们对此进行了大量研究。WANG等[5]提出一个基于多级注意力卷积神经网络的抽取模型,该模型在不使用NLP工具的前提下依然取得了较好的效果。ZHANG等[6]提出一种基于长短期记忆(LSTM)网络的关系抽取模型,该模型可以有效地从文本中挑选相关内容而摒弃无关内容,从而提升了抽取效果。ZENG等[7]利用多示例学习有效地解决了抽取过程中的噪声问题。WEI等[8]提出一个重叠式的指针网络较好地解决了关系抽取中存在的实体重叠问题。SOARES等[9]通过在来自Transformer的双向编码器表示(BERT)预训练过程中额外添加匹配空白(MTB)任务,有效地提升了关系抽取性能。
虽然以上方法在面向纯文本的关系抽取任务上都取得了良好的效果,但面对多模态数据时却往往因为文本中信息缺失而表现不佳。
已有抽取方法主要是针对纯文本信息进行抽取,一般只利用了文本的单模态信息,随着社交平台的盛行,面对大量的多模态信息,面向纯文本的单模态抽取方法已经无法满足社交媒体等多模态场景下的关系抽取需求[10-12],并且多模态关系抽取数据集也极为缺乏。为此,ZHENG等[1]提出MNRE数据集以解决多模态关系抽取数据集匮乏的问题,之后ZHENG等[10]又提出高效图对齐的多模式关系抽取(MEGA)模型。该模型将图像信息视为对文本信息的补充,利用视觉信息辅助模型进行关系抽取并利用注意力机制对齐语义,在获得对齐后的文本表示后再进行关系抽取。
MEGA在多模态数据集上的抽取效果明显优于传统单模态抽取模型,然而存在信息冗余问题,图像中与文本语义无关的物体也被学习到对齐后的文本表示中,对抽取结果造成干扰。为解决这一问题,本文利用双向注意力机制缓解无关信息对抽取结果的干扰,进一步提升了关系抽取效果。
1.2 双向注意力机制
双向注意力机制由SEO等[13]提出,之后被广泛应用于机器阅读理解领域。传统的注意力机制只通过查询项(query)到键(key)进行单向查询,从而得出汇总值(value)所需的权重,建模的是查询项到键之间的单向关系,而双向注意力机制通过计算双向查询建模了查询项与键之间的双向关系。在很多场景下,查询项与键往往是2种平行的数据,如多模态场景中平行的图像和文本、平行的语音和文本等,在这样的情况下,另一个方向上的查询,即键到查询项的查询也具有实际含义。近年来,学者们开始探索将双向注意力机制应用于相关领域。LI等[14]将双向注意力机制应用于神经网络强制对齐,实验结果表明双向注意力机制应用在2种平行的数据上能够提升任务效果。黄宏展等[15]将双向注意力机制引入多模态情感分析任务,实验结果证明了双向注意力机制在多模态场景下可以更充分地利用2种模态间的交互信息。
根据以上研究,本文提出基于双向注意力机制的多模态关系抽取模型,将双向注意力机制应用于多模态关系抽取任务,以缓解无关信息对抽取结果的干扰,使模型能更准确地抽取关系。
2 基于双向注意力机制的多模态关系抽取模型
基于双向注意力机制的多模态关系抽取模型由特征表示层、多模态特征对齐层、多模态特征融合层和输出层4个部分组成,如图1所示(彩色效果见《计算机工程》官网HTML版)。特征表示层分为语义特征表示层和结构特征表示层,通过BERT模型和依存句法树分别提取文本的语义特征表示和文本的结构特征表示,并利用一个以Faster R-CNN为骨干网络的场景图生成模型同时提取图像的语义特征与结构特征。多模态特征对齐层分为语义特征对齐层与结构特征对齐层,分别进行结构特征的对齐与语义特征的对齐。多模态特征融合层将结构特征与语义特征整合成对齐后的视觉特征,再将文本中实体的语义表示与对齐后的视觉表示连接起来形成文本与图像的融合特征。输出层对融合特征计算所有关系分类的概率分数并输出预测关系。
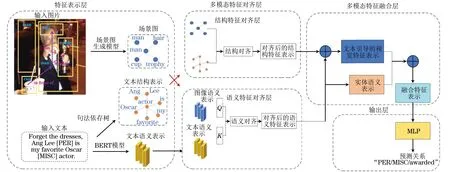
图1 基于双向注意力机制的多模态关系抽取模型结构Fig.1 Structure of multimodal relation extraction model based on bidirectional attention mechanism
2.1 特征表示层
2.1.1 语义特征表示层
MNRE数据集中每条数据都包含了一段文本描述和一张与其对应的图片。对数据中的文本信息,采用BERT模型作为编码器提取特征,具体步骤如下:
1)将文本信息转换为一个token序列s1,在序列头部增加“[CLS]”标记,在序列尾部增加“[SEP]”标记。
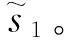
3)通过对数据集的观察以及对实验效果的权衡取n=128作为token序列的最大长度,用“[PAD]”标记将小于最大长度n的输入序列填充到最大长度n。
4)通过设置segment序列区分序列中的有效部分与填充部分,segment序列可以表示为s2=(1,1,…,1,…,0,0),数字“1”表示有效部分,数字“0”表示填充部分。
5)通过词嵌入与字符嵌入相结合来表示输入文本中的词,以充分获取文本特征。
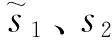
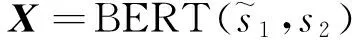
(1)
为了获取视觉信息,采用对象级视觉特征(OLVF)作为图像信息表示[16],OLVF是一种自下而上的图像信息表示方式,通过提取视觉对象表示获取输入图像的语义特征。为了提取图片中的视觉对象,利用以Faster R-CNN为骨干网络的场景图生成模型,将图像输入场景图生成模型获取输入图像的场景图。在场景图中包含多个节点以及与节点相关的边,节点包含视觉对象的特征,而边则表示不同视觉对象之间的视觉关系。
输入图像被表示为所提取的场景图中的一组区域视觉特征,其中每个区域视觉特征代表图像中的一个视觉对象,并以一个维度为dy的向量yi来表示。为检测到的视觉对象设置一个置信度阈值,若大于该阈值则将其视为视觉对象,该阈值的具体取值由深度神经网络训练得到。为尽量减少图像中无关对象对抽取结果的干扰,取置信度较大的前m个视觉对象作为图像的视觉特征,通过对实验效果的观察,在实验中取m=10能取得较好的效果。最后,输入图像被转换为矩阵Y,若图像中检测到的视觉对象数量少于m,则通过零填充将矩阵Y扩充到最大尺寸m,如式(2)所示:
Y= [y1,y2,…,ym]m×dy
(2)
2.1.2 结构特征表示层
在以往的工作中,句子的结构(如依存句法树)能为关系抽取提供重要信息[17],因此利用依存句法树和场景图生成模型分别为输入文本和图像生成2个单向图,以提供协助多模态关系抽取的结构特征信息。
依存句法树是一种表示词与词之间关系的结构,依存句法树能够为关系抽取提供重要信息,句子中2个词之间对应的依赖可以被表示为如式(3)所示的依存关系三元组:
Rdependency=(wg,rtype,wd)
(3)
其中:wg是支配词;wd是从属词;rtype表示从属词对支配词的修饰关系。使用ELMo模型[18]作为句法树提取工具,获取输入文本的依存句法树及对应的依存关系三元组。生成的依存树的图表示记作G1,如式(4)所示:
G1=(V1,E1)
(4)
其中:V1是图中点的集合,代表句子中的支配词和从属词;E1是图中边的集合,代表2个词之间的依赖关系。
通过场景图生成模型获取输入图像中的m个视觉对象以及视觉对象间的视觉关系,由于视觉对象间的关系都是单向的,因此类似于依赖树,在图像中的每个视觉对象也会被它的关联对象所指向,最后获得输入图像的图表示G2。G2由图像中检测到的视觉对象及视觉对象间的关系组成,如式(5)所示:
G2=(V2,E2)
(5)
其中:V2是图中点的集合,代表图像中检测到的视觉对象;E2是图中边的集合,代表视觉对象间的视觉关系。
通过生成图G1和G2得到输入文本和图片的结构特征信息。
2.2 多模态特征对齐层
为了充分利用文本与图像间的交互信息,从语义和结构2个方面对齐多模态特征,利用双向注意力机制对齐语义特征,并利用节点间的相似性对图G1和G2进行结构对齐。
2.2.1 语义对齐
现有的多模态关系抽取模型主要依赖注意力机制,实现图像到文本方向的单向对齐,以获取对齐后的文本语义表示。然而,实际上图像中往往存在与文本无关的冗余信息。例如,在图1中,输入图像中检测到的视觉对象“cup”显然与对应文本无关,但在单向对齐过程中,对象“cup”的信息也会被学习到对齐后的文本表示中,从而影响关系抽取的准确性。
为解决这一问题,本文提出一种基于双向注意力机制的多模态关系抽取模型,通过同时建立图像到文本方向和文本到图像方向的双向对齐,通过赋予图像中冗余信息较低的权重来降低其对文本语义表示的影响。这种双向注意力机制有助于获取包含双向语义信息的文本语义表示,从而提高了关系抽取的准确性。
双向注意力机制的输入由query、key、value组成,其中,query为输入图像的语义表示,key和value为输入文本的语义表示。为方便计算,将query、key和value的特征维度均设置为da,双向注意力机制计算过程如图2所示。
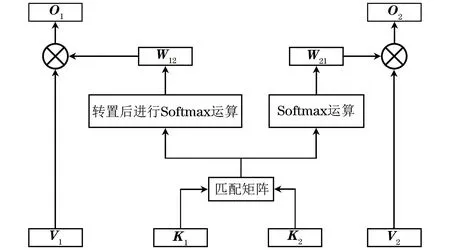
图2 双向注意力机制计算过程Fig.2 Calculation process of bidirectional attention mechanism
在图2中,K1和V1为query矩阵Q∈m×da,K2为key矩阵K∈n×da,V2为value矩阵V∈n×da,m为图像中检测到的视觉对象的最大数量,n为文本最大长度。
首先,计算匹配矩阵A∈n×m,Ai,j表示输入文本中第i个字与输入图像中第j个视觉对象间的相似性,匹配矩阵计算公式如式(6)所示:
A=Q×KT
(6)
通过匹配矩阵A计算图像到文本方向与文本到图像方向2个方向的注意力权重。图像到文本方向的注意力权重W12的计算如式(7)所示:
W12=Softmax(A)
(7)
文本到图像方向的注意力权重W21的计算如式(8)所示:
W21=Softmax(AT)
(8)
然后,计算得到图像到文本方向上对齐后的文本语义表示O1和文本到图像方向上对齐后的图像语义表示O2,如式(9)所示:
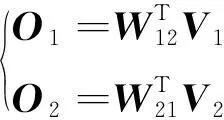
(9)
其中:O1∈n×da;O2∈m×da。
最后,通过式(10)计算得到对齐后的语义权重β。
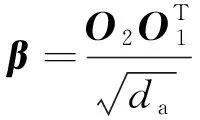
(10)
其中:da为文本语义表示O1与图像语义表示O2的特征维度。
相较于现有的单向对齐机制,所提出的双向对齐机制能够增强文本语义表示的准确性,从而提升模型的性能。
2.2.2 图结构对齐
利用节点信息来提取用于结构对齐的多模态图表示的结构相似性。从2个图集合G1(V1,E1)与G2(V2,E2)中提取节点集合V1与V2,通过计算2个图集合间的节点相似性以获取2个图的结构相似性。具体计算步骤如下:
1)令集合U为节点集合V1、V2的并集,如式(11)所示:
U=V1∪V2
(11)
2)为提取节点间的结构相似性,对集合U中的每个节点u,计算其k跳邻居的出度和入度,如式(12)、式(13)所示:
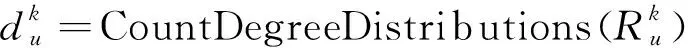
(12)
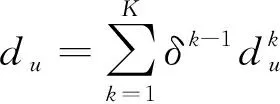
(13)
其中:k∈[1,K],K是图直径;δ∈(0,1]是折扣因子。
3)通过式(14)计算集合U中节点m∈V1和节点n∈V2之间的相似性:
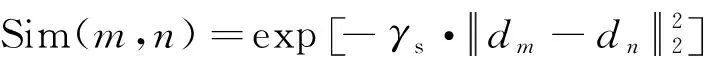
(14)
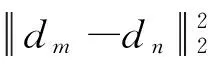
4)计算2个图之间的节点相似度,如式(15)所示,在计算完成后得到包含了结构相似性特征的矩阵α。
α=(αi,j)V1×V2
(15)
其中:αi,j表示文本中第i个词与图片中第j个视觉对象间的结构相似性。
采用图结构对齐方法来捕捉文本与图像之间的结构相似性。通过计算2个图集合间的节点相似性,能够获取2个图的结构相似性。这种方法有助于模型更好地捕捉多模态数据中的关系信息。
2.3 多模态特征融合层
为充分利用对齐的语义信息β与结构信息α,首先,利用式(16)整合对齐信息,以获取对齐后的视觉特征Y*。
Y*=(αT+β)V=αTV+YS
(16)
其中:V是视觉特征表示,通过整合语义对齐信息与结构对齐信息,由文本引导的视觉特征最终表示为矩阵Y*∈m×da;YS代表经过语义对齐处理后得到的视觉特征。
然后,将视觉对象特征整合为向量表示,作为多模态信息融合的视觉信息表示,如式(17)所示:
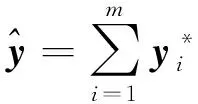
(17)



(18)
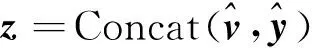
(19)
在多模态特征融合层中,通过整合对齐的语义信息与结构信息,得到了对齐后的视觉特征表示。将视觉对象特征整合为向量表示,并与文本中的实体表示拼接,以获取最终的多模态特征表示。这种融合方法有效地将视觉信息和文本信息相结合,有助于捕捉多模态数据中的关联信息,进而提高关系抽取的准确性和模型性能。
2.4 输出层
如式(20)所示,输出层使用一个多层感知机(MLP)作为分类器来预测关系类别,并输出各个关系对应的分类概率。
poutput=Softmax(MLP(z))
(20)
其中:poutput∈nr表示nr个预定义关系的分类概率。
3 实验与结果分析
3.1 实验设置
实验通过BERT模型初始化文本语义表示,特征维度dx为768,该取值是基于BERT预训练模型的标准设置,已被证明在各种自然语言处理任务中能够有效地学习文本特征。在场景图中提取的视觉对象的特征维度dy为4 096,该取值是基于Faster R-CNN模型的设置,已被证明在各种视觉任务中能够有效地检测和提取目标对象的特征。语义对齐维度da为1 536,该维度是对文本和视觉特征进行整合的需要,使得多模态特征能够在相同的语义空间中进行对齐和融合。通过对数据集的观察和实验效果的权衡,将token序列的最大长度n设置为128,经实验验证,将场景图视觉对象最大数量m设置为10能够取得较好的效果。模型采用AdamW优化器训练目标函数,经实验验证,将初始学习率设置为0.000 02和批量大小设置为10能够在训练速度和模型性能之间达到较好的平衡。本文模型在NVIDIA RTX 3060显卡上进行训练。
3.2 数据集
目前,关于多模态关系抽取任务的相关研究较少,完全公开的数据集仅有MNRE数据集,本文所有实验均在MNRE数据集上进行。MNRE数据集原始数据来源于多模态命名实体识别数据集Twitter15[19]与Twitter17[20],以及一些从推特上爬取的数据。ZHENG等[1]通过人工标记实体对间的关系并滤除原始数据中的部分错误样本,构建了MNRE数据集。MNRE数据集包括音乐、运动、社会事件等主题,包含15 848个样本、9 201张图片与23种预定义的关系。
3.3 评价指标
关系抽取工作的最终效果评价体系是在自动内容抽取(ACE)会议上提出的,以精确率(P)、召回率(R)及F1值(F1)为衡量指标,其计算公式如下:
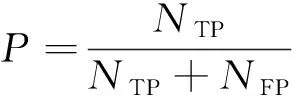
(21)
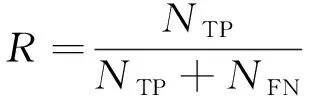
(22)
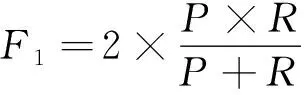
(23)
其中:NTP表示被正确预测为关系r的样本数;NFP表示被错误预测为关系r的样本数;NFN表示被错误预测为其他关系的样本数。
3.4 对比模型
为验证所提模型的有效性,与一些经典的单模态关系抽取模型和主流多模态关系抽取模型进行对比实验,对比模型介绍如下:
1)分段卷积神经网络(PCNN)模型[7]:是一种远程监督关系抽取模型,利用外部知识图自动标记包含相同实体的句子,利用文本信息进行关系抽取。
2)MTB模型[9]:是一种基于BERT的预训练关系抽取模型,利用文本信息进行关系抽取。
3)统一多模态Transformer(UMT)模型[21]:将Transformer应用于多模态场景,利用图文信息进行关系抽取。
4)统一多模态图融合(UMGF)模型[22]:利用图文信息进行关系抽取。
5)自适应共同注意力的预训练关系抽取模型(AdapCoAtt-BERT)[23]:设计多模态场景下的共同注意力网络,利用图文信息进行关系抽取。
6)视觉预训练关系抽取模型(VisualBERT)[24]:是基于BERT预训练的多模态模型,利用图文信息进行关系抽取。
7)视觉-语言预训练关系抽取模型(ViLBERT)[25]:扩展了BERT以联合表示图像和文本,利用图文信息进行关系抽取。
8)基于高效图对齐的多模态关系抽取(MEGA)模型[1]:利用图文信息进行关系抽取。
3.5 结果分析
将所提模型与8个基准模型进行对比实验,实验结果如表1所示,其中最优指标值用加粗字体标示。
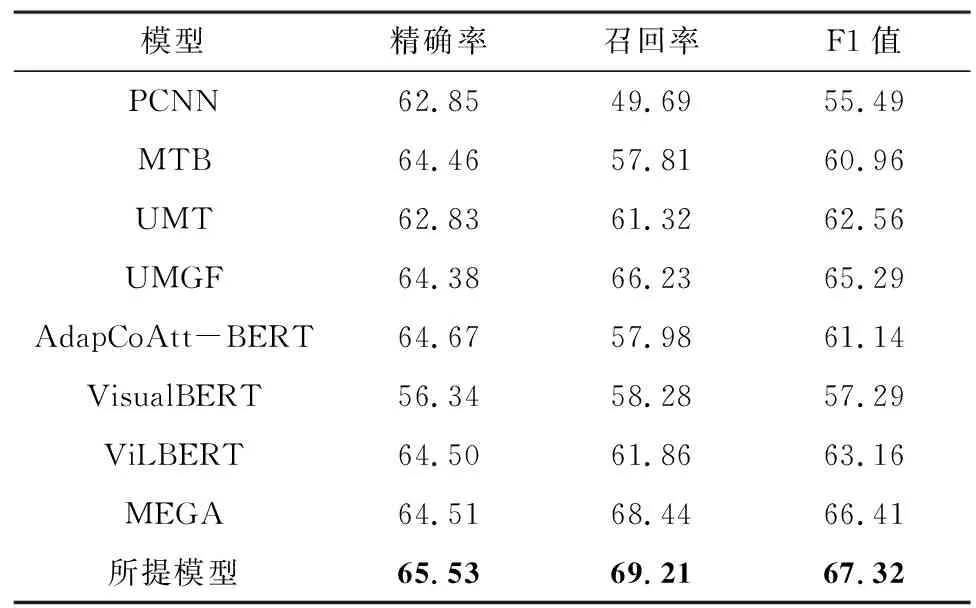
表1 在MNRE数据集上的实验结果Table 1 Experimental results on the MNRE dataset %
由表1的实验结果可以看出,多模态关系抽取模型一般优于单模态模型,这是因为多模态模型可以利用图像信息作为文本信息的补充,得到更丰富的语义信息再进行关系抽取。通过表1中标注的最优指标值可以得知:所提模型较单模态关系抽取模型MTB的F1值提升了6.36个百分点;所提模型较表现最好的多模态关系抽取模型MEGA的F1值提升了0.91个百分点,这一提升归功于所提模型采用双向注意力机制来对齐多模态语义特征,使得模型能够更有效地捕捉文本和图像之间的相互依赖关系,从而提高关系抽取的准确性;所提模型相较于其他多模态关系抽取模型,在捕捉图像和文本间关联信息方面更加准确和高效。
3.6 消融实验
为了进一步验证双向注意力机制的有效性,在MNRE数据集上进行了消融实验,其中,-Biatt表示将所提模型中的双向注意力机制替换为普通的单向注意力机制,-Att表示不使用注意力机制对齐图像文本特征,只将图像特征与文本特征直接相连作为语义特征。消融实验结果如表2所示,在将双向注意力机制替换为单向注意力机制后模型表现明显下降,在去掉注意力机制之后,模型表现进一步下降,从而验证了双向注意力机制能够有效地捕捉图像和文本间的关联信息。

表2 消融实验结果Table 2 Results of ablation experiment %
4 结束语
本文提出基于双向注意力机制的多模态关系抽取模型,将双向注意力机制应用于多模态关系抽取任务,利用双向注意力机制降低了图像中冗余信息对关系抽取的影响,进一步提升了关系抽取效果。实验结果表明,与一些经典的单模态关系抽取模型和主流多模态关系抽取模型相比,所提模型在精确率、召回率、F1值3项指标上均表现出明显的优势,验证了所提模型的有效性。在未来的工作中,将考虑把一些传统关系抽取模型引入多模态关系抽取任务以更充分地挖掘多模态语义信息,以不断提升多模态关系抽取的性能,为相关领域的研究和应用提供有力支持。
猜你喜欢
出版人(2022年11期)2022-11-15
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
通信电源技术(2016年5期)2016-03-22
电源技术(2015年9期)2015-06-05
大连民族大学学报(2015年2期)2015-02-27
河南科技(2014年19期)2014-02-27
