
融合双图卷积与门控线性单元的方面级情感分析模型
2024-04-23 10:03杨春霞吴亚雷闫晗黄昱锟
计算机工程 2024年4期
杨春霞,吴亚雷,闫晗,黄昱锟
(1.南京信息工程大学自动化学院,江苏 南京 210044;2.江苏省大数据分析技术重点实验室,江苏 南京 210044;3.江苏省大气环境与装备技术协同创新中心,江苏 南京 210044)
0 引言
情感分析已成为自然语言处理中的热门话题。方面级情感分析旨在确定句子中给定方面的情感极性。例如:“great food but the service was dreadful”给定2个方面词food和service,目标是推断方面词的情感极性:food为正面,service为负面。方面级情感分析可以让用户对特定方面的意见进行细粒度分析,是许多自然语言处理任务的基础,近年来引起了广泛的关注。
方面级情感分析的早期研究大多使用机器学习算法来构建情感分类器。后来,研究者针对这项任务提出了各种神经网络模型,包括长短期记忆(LSTM)[1]网络、卷积神经网络(CNN)[2]和深度记忆网络(MemNet)[3]。以上模型将句子表示为一个词序列,忽略了词与词之间的句法关系,因此它们很难找到远离方面词的意见词。为了解决这个问题,人们开始利用基于图的模型来整合句子的句法结构,并显示出比不考虑句法关系的模型更好的性能。但仅基于语法的方法忽略了语料库中的词共现信息,而这些信息又是大量存在且不可忽视的[4]。例如,在句子“food was okay, nothing special”中,词对nothing special在SemEval训练集中出现了5次,表示负极性。如果没有这样的全局信息来抵消okay的积极影响,基于语法的方法将对food做出错误的情感预测。因此,为了能够充分利用到语料库中的词共现信息,本文首先使用全局词汇图对语料库中的词共现信息进行编码,然后在词共现图和语法图上分别进行双层卷积。这样,在考虑句子语法信息的同时,也能有效地利用语料库中的词共现信息,从而达到更好的分类效果。
此外,当前对提取出的特征的处理方法主要是直接屏蔽掉非方面词,然而,这样有可能会遗漏与方面词有关的情感信息。门控线性单元(GLU)是卷积神经网络中的一种门控机制,与循环神经网络的门控循环单元(GRU)相比,门控线性单元更容易进行梯度传播,不易造成梯度消失或者梯度爆炸,且能大幅度减少计算时间。此外,门控机制控制信息在网络中流动的路径已被证明对神经网络有很好的效果。
基于以上分析,本文提出一种融合双图卷积与门控线性单元的方面级情感分析模型(BGGCN),主要贡献如下:
1)采用2种图结构获取句子的词汇信息与语法信息,使用卷积模块进行建模,并将2种建模后的结果进行交互,有效地利用了语料库中的词共现信息,弥补了单独使用句法结构的缺陷。
2)使用门控线性单元控制模型提取的情感信息,帮助模型更加精确地对方面词进行情感分类。
3)使用4个SemEval数据集进行广泛的实验,实验结果表明所提模型较对比模型取得了显著的性能提升。
1 相关工作
当前方面级情感分类的研究主要集中在如何准确地利用语法信息,因为语法信息可以提供特定方面与情感表达之间的关系信息。因此,研究者采用基于图的模型来整合句法结构,基本思想是将依存树转换为图,然后使用图卷积网络(GCN)或图注意网络(GAT)将信息从语法邻域意见词传播到方面词。ZHANG等[5]提出在句子的依存树上使用GCN,以利用上下文的句法信息和方面的单词依存关系。HUANG等[6]提出了一个目标依存图注意力网络,通过探索上下文词之间的依存关系来学习每个方面的情感信息。SUN等[7]在LSTM上堆叠了GCN层来完成方面级情感分类的任务,利用双向LSTM(Bi-LSTM)模型来学习句子的上下文特征,并进一步在依存树上执行卷积操作以提取丰富的方面级情感表示。尽管这些方法很有效,但基于语法的方法忽略了语料库中的词共现信息,而这些信息又是大量存在且不可忽视的。AF-LSTM方法[8]通过计算方面和上下文之间的循环相关性或循环卷积并将它们输入到关注层,来利用方面和上下文间的单词共现。然而,它的性能并不总是优于其他经典方法。由此可推断出,通过关注层直接整合单词关联信息不足以利用词汇关系。
门控机制控制信息在网络中流动的路径,并已被证明可用于递归神经网络[9]。LSTM通过由输入和遗忘门控制的独立单元实现长期记忆,这允许信息在可能的许多时间步骤中畅通无阻地流动。如果没有这些门,信息很容易通过每个时间步的转换而消失。相反,卷积网络不受相同类型的消失梯度的影响,研究者通过实验发现它们不需要遗忘门。门控线性单元是一种基于DAUPHIN等[10]的非确定性门工作的简化选通机制,通过将线性单元耦合到门来缓解消失梯度问题,其保留了层的非线性能力,同时允许梯度通过线性单元传播而不缩放。
以上相关工作表明,句法结构信息与词共现信息的交互对情感分析都有不可或缺的作用。本文模型利用句法图和词汇图来捕获句子中的依存关系和训练语料库中的单词共现关系,利用分类概括结构将具有相似用途或含义的关系分组在一起,并减少噪声。同时本文引入门控线性单元,这有助于模型控制情感信息流向给定方面。
2 准备工作
2.1 问题定义
给定一个由n个词和一个从a+1位置开始且长度为m的方面词组成的句子S=[w1,w2,…,wa+1,…,wa+m,…,wn],方面级情感分析的目标是通过从上下文中提取与方面相关的情感信息来检测给定方面的情感极性。
2.2 句法分类图
句法图中有一个节点集Vs和一个边集Es。Vs中的每个节点v是句子中的一个词,Es中的每条边e表示2个词在句法上是相关的。
现有的语法集成方法没有在其句法图中利用各种类型的依存关系和边,只是简单地表示2个词之间存在依存关系。正如上文在引言中提到的,每个依存关系代表一个单词在句子中所起的特定语法功能,并且应该以自己的方式使用。然而,由于解析树中存在大量关系,因此直接使用一个依存关系作为图中的一种边可能会产生解析错误等噪声。
为了解决这个问题,在依存关系上添加一个句法分类结构Rs。具体来说,本文将36个依存关系分为5种关系类型,包括“名词”、“动词”、“副词”、“形容词”和“其他”,在Rs中分别表示为s1,s2,…,s5。由于大多数方面词和意见词分别是名词和形容词,因此“名词”和“形容词”成为2种主要类型;由于动词表示动作、事件或状态,副词修饰动词和形容词,因此分为“动词”和“副词”2种类型;其余所有关系类型构成“其他”类型。
然后基于句法分类结构构造一个句法分类图,记为{Vs,Es,Rs},其中,Vs、Es、Rs分别是节点集、边集、句法关系类型集。Es中的每条边都附有一个标签,表示Rs中的依存关系类型。句法分类图示例如图1所示。
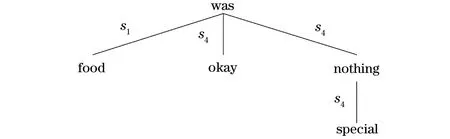
图1 句法分类图Fig.1 Syntactic classification graph
2.3 词共现图
为了使模型能考虑到语料库中的词共现信息,本文构造了词汇图来完成这一任务。全局词汇图中有一个节点集VT和一个边集ET。VT中的每个节点v表示一个词,ET中的每条边e表示词汇量为N的训练语料库中2个单词之间的词共现频率。然后,本文为每个句子构造一个局部词汇图,其中每个节点代表句子中的一个单词,每条边表示句子中同时出现的2个单词。但是,这个边与全局词汇图中2个相同单词之间的边具有相同的权重,其基本原理是将全局词汇图中的全局词分布信息转移到局部词汇图中。
语料库中词的共现频率高度倾斜,其中多数词对出现1~2次,少数词对出现频率较高。显然,应该区别对待频繁词对和罕见词对。因此,本文在词共现关系上添加了一个频率分类结构Rf,根据对数正态分布对词对的频率进行分组。具体来说,用d1和d2表示频率为20和21的词对关系,用d3,d4,…,d7表示频率落在[2k+1,2k+1](1≤k≤5)区间的词对关系,用d8表示所有出现频率大于26的词对的词汇关系。词共现图示例如图2所示。
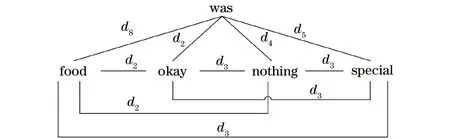
图2 词共现图Fig.2 Word co-occurrence graph
3 模型实现
在本节中将介绍本文提出的BGGCN模型。首先在图3中展示其架构。从图中可以看出,BGGCN主要由嵌入层、卷积交互层和门控输出层组成。首先以频率全局词汇图和词序列为输入得到初始句子表示,然后经过交叉网络,用以深度融合GCN嵌入和Bi-LSTM嵌入。在频率局部词汇图和句法图上执行双层卷积后,使用交互模块改进句子表示。最后,通过门控线性单元获得面向方面的表示,以更好地预测句子中特定方面的情感极性。

图3 BGGCN模型框架Fig.3 Framework of BGGCN model
3.1 嵌入层
GloVe通过利用全局词频统计信息来学习词嵌入,这种方法能够捕捉到更全面的语言信息。相比之下,Word2Vec基于局部的上下文窗口来学习词向量,可能会忽略一些词的全局信息[11]。因此,本文采用已预训练好的GloVe嵌入获得每个词向量。预训练的词嵌入表示为Ew∈|V|×d。其中:|V|是词汇量;d是词嵌入的维度;Ew用于将包含n个词的评论序列S映射到词向量空间[e1,e2,…,ea+1,…,ea+m,…,en]∈n×d。然后,本文提出了2种类型的文本表示来改进句子嵌入:一种是基于频率全局词汇图的GCN嵌入,另一种是Bi-LSTM嵌入。
3.1.1 GCN嵌入
首先,将特定语料库的词汇信息编码到评论表示中。对于这个目标,本文首先构建一个嵌入矩阵Ewt∈N×d用来作为训练语料库的特征矩阵,其中,N是训练语料库的词汇量。
然后,在频率全局词汇图上执行标准GCN,并得到一个新的嵌入矩阵Egcn∈N×d。频率全局词汇图可以提供所有单词之间的关系信息,即使单词之间的距离很远,也能够捕捉到它们之间的关系。这样可以在模型中考虑更多的上下文信息,提高模型的准确性。此外,频率全局词汇图根据整个语料库中的单词共现情况进行构建,可以更好地反映单词之间的相关性。
最后,再使用Egcn即可形成输入评论序列S的GCN嵌入,即[x1,x2,…,xa+1,…,xa+m,…,xn]∈n×d,在图3中表示为x。
3.1.2 Bi-LSTM嵌入
本文按照之前的大多数研究将序列信息编码到评论表示中。此外,由于更接近方面词的词向量可能对判断方面词的情感贡献更大,因此计算每个上下文词wt到对应方面词的绝对距离,并且得到S的位置序列。令Ep∈n×d为随机初始化的位置嵌入查找表,然后将位置序列映射到位置嵌入查找表[p1,p2,…,pa1,…,pam,…,pn]。
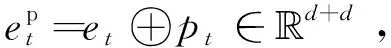
3.2 卷积交互层
从图3中可以看出,卷积交互层由3个模块组成,分别是交叉网络模块、Bi-GCN模块和信息交互模块。以GCN嵌入x和Bi-LSTM嵌入y作为初始句子表示,使用交叉网络融合GCN嵌入和Bi-LSTM嵌入,然后利用Bi-GCN在频率局部词汇图和句法图上进行卷积,用来更好地表示句子S。频率局部词汇图可以更好地捕捉单词之间的相对位置信息,并帮助模型更好地识别出每个方面的情感倾向,这对于情感分析任务来说非常重要。例如,一个单词可能在某个特定方面具有不同的情感倾向,而这取决于它在句子中的位置。此外,为了使2个图可以进行交互,本文引入了BiAffine模块,这有助于更好地改进句子表示。
3.2.1 交叉网络
为了深度融合GCN嵌入x和Bi-LSTM嵌入y,本文采用了简单而有效的交叉网络结构[9]。首先连接x和y以形成固定组合h0∈d,即h0=x⊕y。然后在交叉网络的每一层中,使用下式来更新融合嵌入:
hl=h0(hl-1)Twl+bl+hl-1
(1)
其中:l表示层数(l=1,2,…,|L|);wl,bl∈d是权重和偏差参数。然后将第l层中的融合嵌入hl从原始连接位置分离为xl和yl,这将用作双层GCN中2个图的输入节点表示。
3.2.2 Bi-GCN
本文的句法图和词汇图包含分类概括结构,而普通GCN不能在带有标记边的图上进行卷积。为了解决这个问题,本文使用用于聚合不同关系类型的Bi-GCN,即给定一个句子,使用2个聚合操作来执行双层卷积。

第2个聚合将所有虚拟节点及其特定关系聚合在一起。使用不同关系类型上的平均聚合函数更新目标词m的表示:
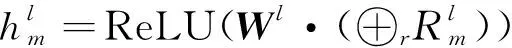
(2)
其中:⊕r表示不同关系类型的表示的串联;Wl是第l层的权重矩阵。
3.2.3 信息交互
为了在频率局部词汇图和句法分类图之间有效地交换相关特征,本文采用相互BiAffine变换作为桥梁。具体如下:

(3)
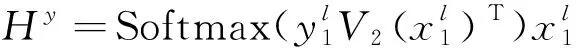
(4)
其中:V1和V2是可训练的参数。
在模块最后,将Hx和Hy组合在一起形成聚合嵌入Hl=Hx⊕Hy。
3.3 门控输出层
为了更好地预测一个方面的情感极性,本文使用门控线性单元来控制情感信息流向给定方面。该机制依照LSTM中的门机制,利用多层的CNN结构,为每层CNN都加上一个输出门控,运算过程如下所示:
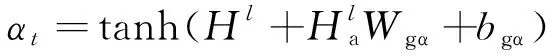
(5)
HL=Hl*αt
(6)
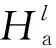
在使用LSTM进行情感分析时,因为在LSTM的最终隐藏状态中,模型已经将输入文本中的所有上下文信息整合到一个固定长度的向量表示中,这个向量表示可以看作是整个文本的“语义向量”。在情感分析任务中,需要将这个“语义向量”作为输入传递到输出层,以进行情感分析预测[12]。最后,检索与方面词语义相关的重要特征,并为每个上下文词设置基于检索的注意力权重。句子的最终表示为:
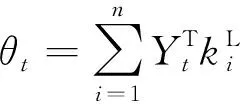
(7)

(8)

(9)
其中:yt∈d是Bi-LSTM嵌入;通过一个全连接层从方面词嵌入转换得到,以保持与yt相同的维度。
3.4 模型训练
在获得面向方面的表示Z后,将其输入一个全连接层和一个Softmax层以投影到预测空间中:
U=Softmax(Wuz+bu)
(10)
其中:U是预测结果;Wu和bu分别是权重矩阵和偏差。然后将最高概率的标签设置为最终预测U。
本文使用基于L2正则化的交叉熵损失函数作为模型的损失函数。交叉熵损失函数是一种常用的用于分类任务的损失函数,它衡量了模型的预测结果与真实标签之间的差异,并且可以通过最小化该损失函数来优化模型的参数。在损失函数中添加L2正则化项,用于约束模型的复杂度,可以使模型的权重参数趋向于较小的值,从而减小过拟合的风险。损失函数表示为:

(11)

4 实验
4.1 实验数据与实验平台
本文在4个公开数据集上进行实验,分别是Twitter[13]、SemEval-2014[14]、SemEval-2015[15]和SemEval-2016[16]评论集。以上数据集中标注了每句句子的方面词以及方面词的情感极性,分别为“积极”、“中性”和“消极”3种不同的情感极性,具体分布情况如表1所示。本文的实验平台及实验环境如表2所示。
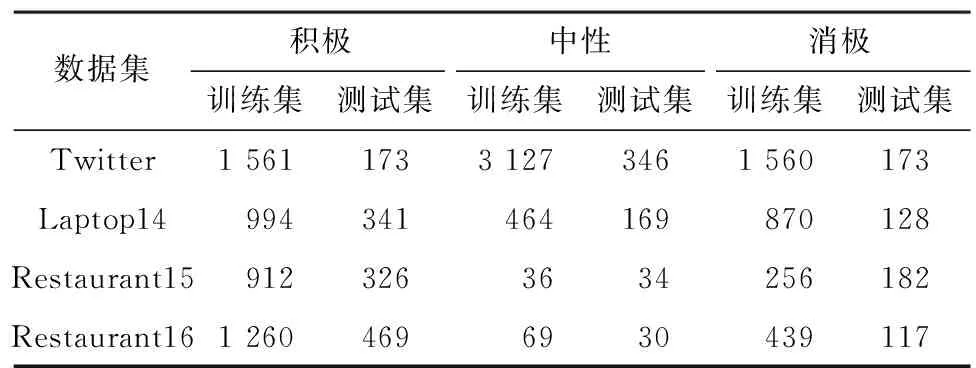
表1 数据集中情感极性分布Table 1 Distribution of emotional polarities in datasets 单位:个

表2 实验平台及实验环境Table 2 Experimental platform and environment
4.2 参数设置与评价指标
本文使用嵌入维度为300的预训练GloVe来获得初始词嵌入,使用spaCy工具包来获取依存关系。具体参数设置如表3所示。
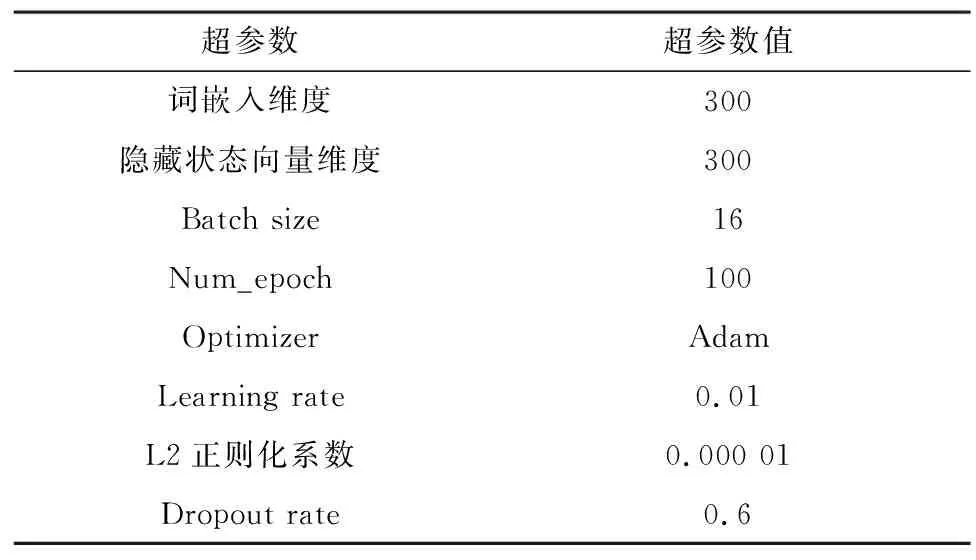
表3 参数设置Table 3 Parameters setting
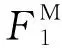
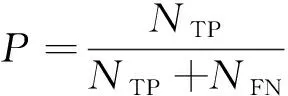
(12)
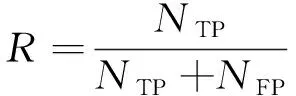
(13)
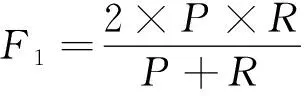
(14)
对于dp个类别,准确率与宏平均F1值的计算公式分别为:
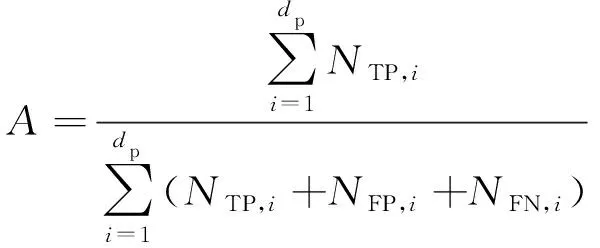
(15)
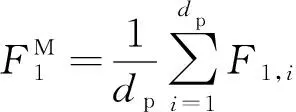
(16)
其中:宏平均F1值是指所有类别的F1值的平均值,模型重复运行3次,取最高的一次作为最终结果。
4.3 对比模型
将本文模型与以下基线模型进行比较:
1)LSTM[17],是一种目标相关的模型,该模型在生成句子表示时可以捕捉目标词与其上下文之间的联系,用于目标相关的情感分类。
2)MemNet[3],是一种基于记忆的模型,该模型将神经注意力模型与外部记忆相结合,计算每个上下文词对某个方面的重要性。
3)AF-LSTM[8],是一个方面融合LSTM模型,该模型学习句子单词和方面之间的关联关系。
4)RAM[18],该模型使用多跳的注意力层,并将输出与循环神经网络(RNN)相结合用于句子表示。
5)AOA[19],该模型学习方面词和上下文词之间的相互作用,并通过注意力模型关注句子中的重要部分。
6)IAN[20],该模型使用2个LSTM和1个交互式注意力机制来生成方面词和句子的表示。
7)ASGCN[5],该模型在依存树上为每个句子构建有向图,然后通过GCN提取句法信息和单词依存关系。
8)CDT[7],该模型在句子的依存树上利用GCN模型来提取上下文词和方面词之间的依存关系。
9)kumaGCN[21],该模型使用潜在的图形结构来补充句法特征。
在上述模型中,前6种模型是具有典型神经结构的经典模型,后3种模型是基于图形和语法集成的模型。
4.4 结果与分析
所有模型的比较结果如表4所示,可以看出:本文提出的BGGCN模型在4个不同的公开数据集上准确率和宏平均F1值均有一定的提升。与表现较好的kumaGCN相比,准确率分别提高了2.37、1.49、1.6和0.42个百分点,宏平均F1值分别提高了2.2、1.1、1.73和0.18个百分点。LSTM仅仅对句子进行建模,忽略了方面词的影响,最终得到的是句子的全局情感,因此效果最差。基于注意力机制的模型如MemNet、RAM、IAN和AOA性能均优于LSTM模型,这表明注意力机制在情感分析任务中是有效的。IAN将方面词和上下文词进行交互获取句子的准确表达,并且考虑到方面词可能有多个单词组成,另外添加了一层对于方面词的注意力操作用于计算权重。AOA与IAN思路相似,也是利用方面词与上下文之间的信息交互从而获取语义。因此,IAN与AOA的效果较好。基于图和语法的集成方法ASGCN、CDT和kumaGCN比不考虑语法的前5种方法要好,表明依存关系有利于识别情感极性,这与以往的研究一致。但是,它们只考虑到句子的语法信息,忽略了语料库中的词共现信息,因此与本文提出的 BGGCN模型相比,显现出明显的不足。AF-LSTM通过关注层直接整合单词关联信息,未能充分地利用到词汇信息,与基于注意力机制的模型相比都不能取得更好的效果。BGGCN在考虑到句法信息的同时,也考虑到语料库级别的词共现信息,并将词汇信息与语法信息进行有效的交互。此外,其又利用了门控线性单元,避免了对特征表示进行平均池化可能会缺失重要的情感信息的问题,因此,在与上述模型的对比实验中,取得了最为优异的结果。

表4 不同模型的实验结果Table 4 Experimental results of different models %
4.5 消融研究
为了观察BGGCN模型中每个组件的影响,本文进行了消融研究,并将结果列在表5中。其中:w/o sy表示只保留词汇图的模型;w/o wc表示只保留句法图的模型;w/o mu表示2个GCN模块没有交互的模型;w/o ga表示去掉门控线性单元的模型;w/o sy+ga和w/o wc+ga 表示在使用门控线性单元下分别去掉句法图和词汇图的模型。

表5 消融实验结果Table 5 Results of ablation experiment %
首先研究词汇图和句法图的影响。与完整的BGGCN模型相比,去掉词汇图或者句法图的模型性能均有所下降。因为仅使用词汇图会忽略句法信息,而仅使用句法图会忽略词共现信息。从表中还可看出,即使只使用单个图却已然取得了有效的结果,表明无论是词汇图还是句法图都有本身的贡献存在。本文还研究句法图和词汇图上的信息未交互时的情况,可以看出,由于在2个图上孤立地提取特征,因此未能取得比BGGCN模型更好的结果。
此外,本文还研究了门控线性单元对模型的影响。从表5中可以看出,当去掉门控线性单元时,由于无法保证输出的情感信息流向指定方面,导致预测性能指标明显降低。而当只用句法信息或词共现信息时,使用门控线性单元依然取得了良好的效果。由此可以看出本文所添加模块的必要性及有效性。
5 结束语
为了解决词共现信息缺失以及不能控制情感信息流向的问题,本文提出了BGGCN模型,利用基于图的方法进行方面级情感分类。该模型使用词汇图来捕获训练语料库中的全局单词共现信息,在每个词汇图和句法图上建立一个分类概括结构,分别处理图中不同类型的关系;使用卷积交互层以使词汇图和句法图协同工作,有效融合句法信息和词汇信息;使用门控线性单元来控制情感信息流向指定方面,用于更有效地预测一个方面的情感极性。本文在4个公开的数据集上进行了实验,BGGCN模型均取得了优秀的分类效果。
BGGCN模型仍存在一些不足之处。例如,本文主要针对英文文本进行情感分析,而对于跨语言和多模态的情感分析任务,该模型可能无法直接适用。此外,该模型在大规模数据集上存在计算效率较低的问题,导致训练和推断时间较长。下一步将把该模型扩展到跨语言和多模态情感分析领域,并优化模型结构和算法,提高计算效率,以适应更大规模的数据集。
猜你喜欢
中华诗词(2021年3期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
大连民族大学学报(2021年2期)2021-07-16
天津外国语大学学报(2020年1期)2020-03-25
电子制作(2019年11期)2019-07-04
中华诗词(2018年3期)2018-08-01
北京航空航天大学学报(2018年1期)2018-04-20
中华诗词(2018年11期)2018-03-26
语言与翻译(2015年4期)2015-07-18
电视技术(2014年19期)2014-03-11
