
面向司法文书的抽取-生成式自动摘要模型
2024-04-23 04:34:56陈炫言周炼赤
计算机工程与设计 2024年4期
陈炫言,安 娜,孙 宇,周炼赤
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
文本自动摘要领域主要分为两大类别:抽取式和生成式。抽取式摘要通过衡量基本句子成分的权重,通过各个成分之间的关联性及相似性进行排序,将排序前列的句子进行拼接;生成式摘要通过构建更复杂的算法模型,根据对原文段落理解(转义、缩写、替换)生成新的句子来获得文本摘要。抽取式摘要更直观,但不考虑词间关系,仅计算权重,生成的摘要可能存在语法不连贯的情况;生成式摘要通过语义表征和推理排序,有助于解决抽取式摘要的语法问题。由于生成式摘要未计算词间权重,导致段落成分关联性不如抽取式,针对该问题提出一种抽取式与生成式模型联合的改进模型,即面向司法文书的抽取-生成式自动摘要模型(BERTSUM-XNTL)。模型提出4个创新点:①使用BERTSUM[1]作为基础提出BEES抽取式摘要模型作为基线模型。采用Best-First Beam Search替换传统Beam Search;②基于XLNET[2]构建seq2 seq生成式摘要模型框架,融合Transformer-XL自回归模型优点对抽取式模型的输出进行处理。以XLNET作为Encoder、Transformer-XL作为Decoder提出生成式摘要模型XNTL(XLNET+Transformer-XL);③在生成式摘要模块添加序列预测YCN-Copy机制,克服传统copy机制无法复制连续片段问题;④在YCN-Copy机制进行分类任务时,使用Hierarchical Softmax[3]替代传统Softmax,提升训练速度。实验结果表明,该模型在司法领域可以有效改善摘要提取质量,并在ROUGE评价体系中取得较好成绩。
1 相关工作
自动文本摘要的目标是给定一个文本,获得该包含文本重要内容的简化版本。IBM科学家H.P.Luhn提出关于自动构建文献摘要,指出重要的句子应具有更多的关键词,即出现次数最多的词,并根据词频和分布导出的统计信息来计算该词的重要性度量。当前摘要模型重点分为两类:抽取式摘要和生成式摘要。极少数的研究邻域也涉及到了抽取-生成式自动摘要模型。
抽取式摘要模型本质是序列标注任务,将文本中重点语句标注为1,非重点语句标注为0,将标注为1的重点语句组合生成文本摘要。张翔等[4]在全局信息提取模块采用了基于方面抽取和神经主题模型两种全局信息提取技术。程琨等[5]提出了基于最大边缘相关的新闻摘要方法以及基于支持向量机和MMR相结合的新闻摘要方法。
生成式摘要模型基于seq2Seq框架,主要依赖于深度神经网络实现。Google团队首先提出的Seq2Seq网络结构[4]为生成式摘要奠定了基础,也是生成式摘要研究的开端。Seq2Seq包含了编码器-语义向量-解码器,编码器和解码器均由深度神经网络组成,其中在编码过程中为了更好地编码特征向量,可以穿插各种注意力机制或是通过不同网络模型构建为编码器、解码器,从而提升摘要效果,这也是近年来生成式摘要的主流研究方向。
本文提出的面向司法文书的抽取-生成式自动摘要模型结合了抽取式及生成式摘要模型的优点,在抽取式摘要模型中,通过将人工摘要与对应司法文书的每句话进行相似度打分,保留相似度高的句子,将其组合作为抽取式模型的输出。将源文本的标注摘要和抽取式模型的输出摘要作为训练数据传入生成式模型,进一步特征提取和语义挖掘,从而获得包含全文token信息且更符合语境的文本摘要。
2 面向司法文书的抽取-生成式自动摘要模型
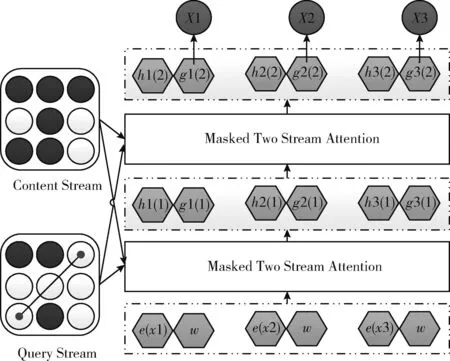
司法文书属于长文本数据类型,在对其进行语义向量表示,从而导致下游任务模型难以达到预期的学习目标。在生成式摘要任务之前对司法文书进行抽取式摘要,可以缓解因数据过长而无法获取更全语义信息问题。本文提出抽取-生成式自动摘要模型[7](BERTSUM-XNTL),由抽取式摘要模型和生成式摘要模型子任务组成,将抽取式模型摘要的输出作为生成式摘要模型的输入,对抽取模型摘要进行深层特征提取,进一步优化选择,生成更准确及更符合逻辑的文书摘要。其模型结构如图1所示。
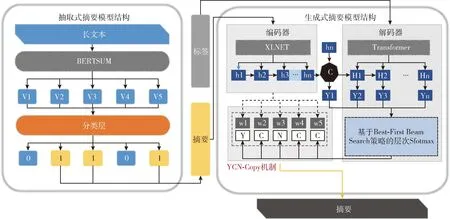
图1 面向司法文书的抽取-生成式自动摘要模型(BERTSUM-XNTL)
2.1 抽取式摘要模型
抽取式摘要模型BERTSUM(BERT-extractive summary)主要由句子向量表征和摘要分类模块组成,句子编码层基于BERT预训练语言模型对输入句子进行向量表征,提取文本上下文语义特征;摘要分类层对文书所有句子分类,并基于语义相似度计算选取与当前类别句子相似度得分较高的top-n对应的句子进行组合,作为抽取式模型的摘要。其模型结构如图2所示。
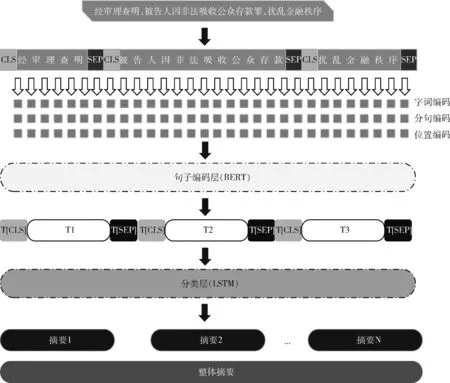
图2 抽取式摘要模型结构
2.1.1 句子编码层
首先对待抽取摘要的长文本序列进行数据预处理,得到模型的输入数据,以句号为分隔符对输入数据进行划分,得到待抽取摘要文本对应的句子集,分别获取输入句子对应的原始句编码、段落编码和位置编码,并将其累加作为Transformer层的输入,对句子上下文进行特征提取,生成具备上下文语义的句子表征向量。
与原BERT[8]不同,BERTSUM模型在句子编码层的输入模块有特殊处理:
(1)对于原始句编码,BERTSUM 模型在输入文本对应的所有句子前后插入[CLS]和[SEP]进行标记,见表1。

表1 切分前后对比
(2)对于段落编码,为区分多个句子,将奇数句和偶数句以标签(EA-EB)进行划分,见表2。

表2 段落编码
(3)对于位置编码,同BERT一样加入定位编码,以增强词汇的上下文关联性,见表3。

表3 位置编码
2.1.2 摘要分类层
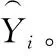
在BERT输出位置添加LSTM层,更进一步提取文档级特征。BERT的输出-句子表示Ti输入到LSTM,经过LSTM处理,输出隐藏状态Hi,并将该隐藏状态继续输入到sigmoid分类器中进行分类。
其中Fi,Ii,Oi,Gi分别代表LSTM中的遗忘门、输入门、输出门、隐藏向量、LNh和LNX分别代表不同层正则化,Ti表示上层BERT的输出向量,通过对权重和隐层向量的正则化,得到经过各个门的向量值
(Fi,Ii,Oi,Gi)=LNh(Whhi-1)+LNx(WxTi)
(1)
tanh函数用于产生新的候选值,sigmoid函数决定哪些值更新,起筛选作用,Ci表示记忆向量,将其结合用于更新隐藏向量Gi
Gi=sigmoid(Fi)⊙Ci-1+sigmoid(Ii)⊙tanh(Gi-1)
(2)
Ot表示输出门,LNc为正则化层,为更新最终输出向量,通过筛选出输出门的向量,并结合当前时刻t的记忆向量Ct产生新的候选值后更新输出向量Hi
Hi=sigmoid(Ot)⊙tanh(LNc(Ct))
(3)
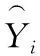
(4)
2.2 基于XNTL的生成式摘要模型
本文选择seq2seq框架,使用XLNET作为编码器,Transformer作为解码器,联合YCN-Copy机制及基于Best-First Beam Search[9]的层Softtmax构建抽取-生成式自动摘要生成模型XNTL。
基于XNTL的编码器模块,针对自回归语言模型(auto regressive,AR)[10]存在无法利用上下文信息,只能利用单项语义问题,以及自编码语言模型(auto embedding,AE)因引入了标签[MASK],导致预训练和微调过程不一致,出现在预测[MASK]时,忽略了连续[MASK]之间的关联问题,本文提出排列语言模型(permutation language model,PLM)对编码器模块进行改进,引入YCN-Copy[11]机制对抽取式模型的摘要结果进行优化提取,并联合基于Best-First Beam Search策略的层Softmax优化模型训练过程,从而生成最终司法文书摘要。
2.2.1 Permutation Language Model
基于XNTL的编码器模块,解决自回归模型(AR)和自编码模型(AE)缺陷,通过对序列重新排序的方式,使用排列语言模型(permutation language model,PLM),赋予单向模型的下文感知能力。例如,序列[经→审→理→查→明],通过序列改变,可以得到共N!种排列方式,N表示序列长度。
[经→审→理→查→明],[经→理→审→明→查]
[明→经→查→审→理],[理→查→明→经→审]
通过排列组合的方式,任何一个元素都可以成为最后一个元素,即使是单向自回归(AR)模型,也能够关联到上下文。
实现过程如图3所示。
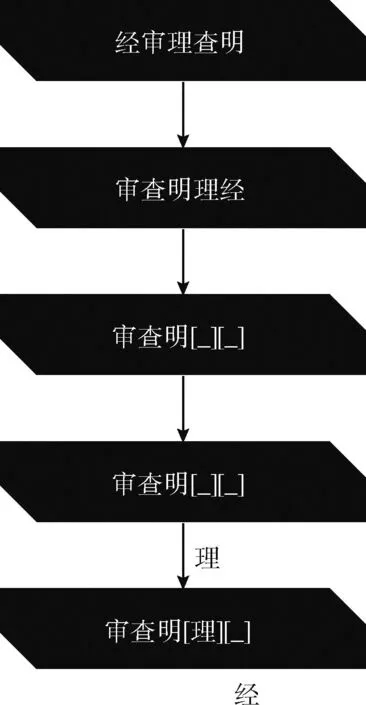
图3 排序语言模型
PLM语言模型优势在于通过重新排列的方式,采用自回归模型(AR)替代自编码模型(AE),从而避免AE模型中的[MASK]标签带来的负面影响,并同时可以规避AR模型仅只能单向预测的弊端。
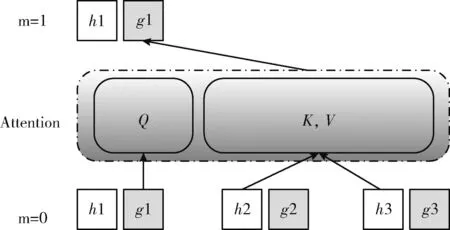
2.2.2 Two Stream Attention[12]
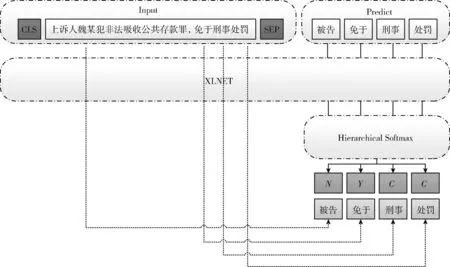
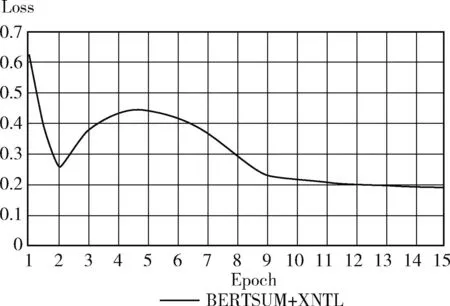
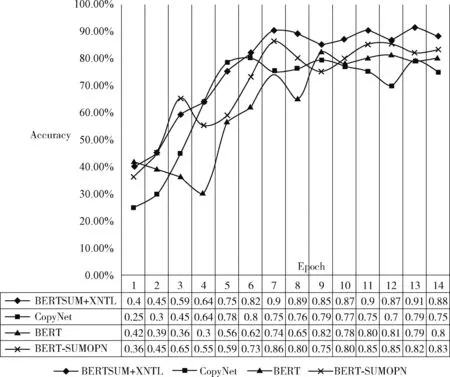
基于PLM机制,XLNET还使用了Two Stream Attention机制,包含Content Stream和Query Stream Attention机制。Content Stream机制采用传统Attention,仅包含token编码,但是由于XLNET采用PLM模型,为了避免待预测词可以看见自身问题,引入Query Stream机制将待预测词标记为其位置编码。由于PLM模型是对句子进行重新排列,打乱原文本序列顺序来获取上下文信息的,必须通过预测词的位置信息去准确获取预测词内容信息,因此输入序列就不能包含内容信息。XLNET基于Two Stream Attention机制将位置编码信息从输入编码中单独拆分出来,采用新的分布计算来实现目标位置感知,G(XL (5) (1)Content Stream,内容流注意力机制,同传统Self-Attention一致,其结构如图4所示。 图4 内容注意力机制原理 (6) 图5 查询注意力机制原理 (7) 图6 双流注意力机制模型结构 XLNET主要借鉴Transformer-XL中的段循环机制及相对编码机制融合了自编码模型和自回归模型的优势,解决了Transformer-XL中绝对位置编码无法区分文本片段导致信息流失问题。 在生成式摘要模型中使用基于指针网络的copy机制采用相应策略从原文中复制词语,不仅可以重现原文的重点细节,而且一定程度上缓解了未登陆词OOV问题。常规Copy机制每次只能复制一个token,无法复制一个连续片段,且Copy机制的实现较为复杂,无法直接简单加以使用。针对这些问题,本文提出一种YCN-Copy机制,其复制的是原文中的连续片段,不仅保存了句间关系,而且实现简单方便。其结构如图7所示。 图7 YCN-Copy机制 YCN-Copy机制在编码部分增加一个序列预测任务,原本的编码部分建模是针对每个token分布进行自回归建模,模型下一个token生成依赖于前n个token,形式化表示为 (8) 现在多一个序列预测建模,使用{Y,C,N}标签对预测的字进行打标,判断是否来源于原文。形式化表示见表4。 表4 双流注意力机制参数说明 (9) Zt∈{Y,C,N} (10) 其中,{Y,C,N} 含义为:Y表示该token为文本中复制而来;C表示该token为文本中复制而来,且跟之前token为连续片段;N表示该token不是复制而来。 YCN-Copy机制,通过计算目标摘要和输入原文的最长公共子序列,出现在最长公共子序列中的token就认为是文本中复制而来,记为Y;若该token不仅出现在公共子序列中,并且同时与之前token是一个连续片段,记为C;若该token未出现在公共子序列中,则记为N,表示该token不是复制而来。YCN-Copy的本质是在解码阶段多了一个序列预测任务,首先预测每个token的标签Zt∈{Y,C,N}, 如果Zt是N,则不做改变;如果Zt是Y,则在token分布使用mask标签替换掉所有不在原文的token;如果Zt是C,则使用mask标签替换掉无法组成原文对应N-gram的token。使得解码时通过时间序列一步步解码,保证YC位置对应的token是原文的片段,从而保证摘要和原始文本的紧密契合度。 在生成式模型的解码模块,采用Softmax作为输出层将多个标量映射为一个概率分布,Softmax采用贪心策略,每一时刻选择最优解,但由于每一步都是局部最优,所以可能得不到全局最优解。Beam Search对贪心策略进行改进,通过扩大搜索空间可以解决全局最优解问题。而Best-First Beam Search在Beam Search基础上通过减少得分函数的调用提升搜索效率,在更短的时间内可以得到和Beam Search相同的效果。每一步Beam Search都维护一个最大堆,然后用前一步得分最高的序列生成新的序列,放入最大堆中,选出当前序列得分最高的k个序列。x表示当前输入,y表示要生成的句子,n为生成句子的最大长度,得分函数一般是对数似然,计算公式如下 (11) 搜索过程中比较运算公式如下 (12) 公式表示,让那些长度更短,或是长度相同但是得分更高的句子被优先计算。 模型收敛条件计算公式如下 Stop(∂)⟺y.last()=END,∀y∈∂ (13) 公式表示为让所有的句子都能被搜索完。 在Beam Search中,如果有两个得分最大的序列,那么搜索更短的那个序列即可,直到生成终止符。通过修改停止搜索条件,可以得到Best-First Beam Search。 搜索过程中的比较运算公式如下 (14) 终止条件计算公式如下 Stop(∂)⟺∂.peek().last()=END (15) 得分函数设置为0。 Best-First Beam Search算法的优势在于,如果已经计算了长度为n的句子,那么就无需再计算长度小于n的句子,其得分在该长度上一定是更低的。 本文使用的数据集为国内第一个公开的长文本生成数据集。全部数据为面向法律领域裁判文书(摘要-长文本)数据对。数据总量为9484条,文本平均长度为2500字左右,最大字数13 009,最小字数868;摘要句的平均长度为350左右,最大字数522,最小字数68。对于超长文本的处理手段为:设置极限阈值2500,超出阈值的进行截断;对于短文本的处理手段:未达到设置长度(当前实验设置的长度为512)的进行padding。将长文本作为抽取式模型输入,生成的摘要同裁判文书数据对进行对齐,找到其对应标签,作为生成式模型输入。使用交叉验证方法。将标注数据分为n份,其中n-1份训练抽取模型,使用抽取模型预测剩下的那份数据的抽取摘要,如此重复n遍,就得到全部数据的抽取摘要,并且尽可能地减少了训练和预测阶段的不一致性。 本模型实验结果采用Rouge[14](recall-oriented understudy for gisting evaluation)评估指标进行评测,基本思想为将模型生成的摘要同训练集中的标准摘要进行对比,通过统计两者间重叠的基本单元(n-gram)的数目,衡量模型自动生成摘要和标准参考摘要之间的相似度。本文主要采用Rouge-1,Rouge-2及Rouge-L对生成结果进行评估。Rouge-N(N=1,2)的计算公式如下,分子表示人工摘要和自动摘要共有的n-gram个数,分母表示参考摘要的n-gram个数 (16) Rouge-1、Rouge-2用于直观地表达自动生成摘要所包含信息量,Rouge-L通过计算自动摘要和人工摘要的最长公共子序列的准确率和召回率来体现自动生成摘要的流畅性,Rouge-L计算公式中LCS(X,Y) 是X和Y的最长公共子序列长度,M表示参考摘要,S表示自动摘要,Rlcs为召回率,Plcs为准确率,Flcs即为Rouge-L得分。 Rouge-L(最长公共子序列重合率)数学表达式如下 (17) (18) (19) 本实验基于深度学习框架Tensorflow1.14,使用单个NVIDIA Tesla V100(GPU)训练。抽取式模型设置编码器层数共12层,解码器层数9层;生成式模型编码器层数24层,解码器层数12层,多头注意力机制设置参数为12,最大序列长度为512,学习率为1e-6,共计训练18个epoch。Drop为0.1,Batch size设置为8,训练时长总计35小时。 为更好反映出本模型在司法摘要上的效果,本文分别在抽取式摘要模型,生成式摘要模型以及抽取式+生成式摘要模型中选取了以下baseline进行了对比。 选取Pointer Generate Networks及BERT作为生成式摘要对比模型。Pointer Generate Networks模型采用编码-解码结构,利用指针生成器复制单词,可以准确复制信息。BERT模型通过修改输入数据的格式做摘要,目前取得不错效果。 选取TextRank和CopyNet作为抽取式摘要对比模型。TextRank利用文档内部的共现信息抽取关键词,可通过创建图来有效地对文档摘要进行排序。CopyNet[15]采用seq2 seq框架,同样采用copy机制,可以较好地处理OOV[16]问题。 选取BERT+SUMOPN抽取式+生成式对比模型[17]。该模型利用BERT先获取文本向量得到关键句子再输入到指针生成式网络[18]中获得摘要结果。最终模型评测对比结果见表5。 表5 摘要结果对比 由表5可以看出,实验中的抽取式+生成式摘要模型结构结果都较好于单独抽取式摘要模型或生成式摘要模型。本文提出BERTSUM+XNTL模型在ROUGE获得最高评分,在Rouge-1,Rouge-2,Rouge-L上,同次好模型比对,分别提升了5.8%、1.2%、5.6%;同模型平均得分比对,分别提升了6.5%、6.5%、2.3%可明显看出,本文通过将抽取式模型BERTSUM和提出的生成式模型XNTL结合的方式,在裁判文书数据集上均高于单一模型得分,可以显著提升模型的摘要效果。图8展示了不同模型在面向法律领域裁判文书数据集上的摘要结果。 图8 摘要结果对比 针对摘要结果而言,BERTSUM+XNTL(ours)生成的摘要包含了更多的关键性信息,且内容更具有概括性,对原文也更具有理解性,生成的摘要更流畅、更简洁、更准确、更丰富、更贴近人工摘要。 本文采用了7折交叉验证,然后对结果进行融合计算,性能见表6。 表6 交叉验证前后对模型性能的影响 本实验将数据输入到压缩模型中训练,图9展示了BERTSUM+XNTL模型对应模型训练的损失函数变化趋势,在前两个epoch中,呈现明显的下降趋势,在2~4个epoch略微上升后,下降较为迅速,一直到第9个epoch,loss逐渐趋于稳定,具体变化如图9所示。 图9 BERTSUM+XNTL损失函数 本实验针对同一数据集的,通过不同模型包含:CopyNet、BERT、BERT-SUMOPN,分别在抽取式模型,生成式模型以及抽取式+生成式模型上进行训练测试对比准确率,验证本文提出模型在司法文书邻域的摘要性能,各模型准确率变化如图10所示。经模型比对发现,在第6个epoch之前,BERTSUM+XNTL的准确率阶段性地存在略低于其余3个模型的情况,呈现逐步上升趋势,在第6个epoch之后,BERTSUM+XNTL的准确率均高于其余3个模型,最高值达到91%且波动在85%~90%区间趋于平稳。 图10 准确率对比 本研究结果表明在面向法律领域裁判文书数据集上通过结合抽取式及生成式摘要模型进行摘要任务优于单一模型摘要效果。基于BERTSUM及XLNET,运用BERTSUM模型作为抽取式摘要模型对原文进行抽取式摘要,以抽取式摘要模型的输入为模型输入,对摘要进行特征提取,从而生成更加准确的摘要结果。融合了抽取式摘要模型及生成式摘要模型优势,解决了抽取式模型文本序列过长时容易丢失信息导致摘要提取结果不准确,及生成式模型生成序列重组时语法不准问题。适用于法律领域文本摘要任务,后期工作将基于其它数据集对模型进行相应参数微调,探索在其它领域的摘要效果,完善文本摘要工作。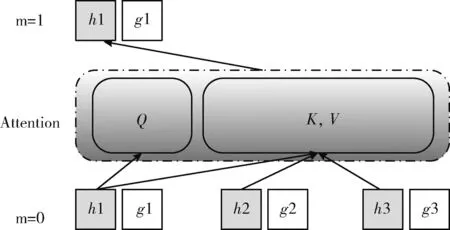
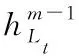
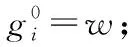
2.3 YCN-Copy机制

2.4 基于Best-First Beam Search策略的层次Softmax[13]

3 实验结果
3.1 数据集
3.2 评估指标
3.3 实验环境及参数
3.4 实验及结果分析


4 结束语
猜你喜欢
邯郸学院学报(2022年2期)2022-07-05 07:26:30
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
安徽警官职业学院学报(2020年6期)2020-07-21 01:38:56
电子制作(2019年22期)2020-01-14 03:16:24
西夏学(2019年1期)2019-02-10 06:22:40
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
