
融合事件相机的视觉场景识别
2024-04-22 00:46刘熠晨余磊余淮杨文
中国图象图形学报 2024年4期
刘熠晨,余磊,余淮,杨文
武汉大学电子信息学院,武汉 430072
0 引言
视觉场景识别(visual place recognition,VPR)算法(Lowry 等,2016)是视觉同步定位与建图(visual simultaneous localization and mapping,VSLAM)算法(Saputra 等,2018)中闭环检测模块的重要组成部分,是移动机器人与AR/VR(augmented reality/virtual reality)等领域的关键算法,对于消除视觉里程计算法的累积误差、维持位姿估计与建图的全局一致性以及无GPS(global positioning system)环境下的快速重定位具有重要作用(Campos 等,2021)。
传统视觉场景识别算法通过对光学相机图像进行图像匹配以实现场景识别。图像匹配通常分为以下几个步骤:首先通过SIFT(scale-invariant feature transform)(Ng 和Henikoff,2003)与ORB(oriented fast and rotated brief)(Rublee 等,2011)等人工设计的算子提取图像的局部特征,再通过BoW(bag of words)(Galvez-López 和Tardos,2012)及VLAD(vector of locally aggregated descriptors)(Jegou 等,2010)等局部描述符聚合方法获得图像的全局特征,并根据全局特征在向量空间的相似度进行匹配。随着深度学习的兴起,卷积神经网络作为可训练的多通道特征提取器替代了传统的人工设计的局部特征提取器。对于局部特征的聚合,DenseVLAD(Torii 等,2015)和NetVLAD(Arandjelovic 等,2016)使用神经网络重构了VLAD 计算过程,首先通过卷积神经网络提取图像的多通道特征,然后通过聚合网络将多通道特征聚合为全局描述符向量作为图像的表示。图像的检索与匹配方法中,SeqSLAM(Milford 和Wyeth,2012)通过短序列搜索提高了场景识别性能。然而,光学相机存在时间分辨率较低、动态范围较小的问题:1)高速运动场景下,相机难以连续捕捉到场景在成像平面中位置的快速变化,导致输出图像存在运动模糊;2)高动态范围场景下,光学相机输出图像会出现欠曝光与过曝光等退化现象。上述问题使得图像纹理与结构信息缺失,导致传统视觉场景识别方法在高速和高动态范围场景下识别性能不佳(Lowry等,2016)。
事件相机是受生物视觉启发的一类新型视觉传感器(Gallego 等,2022)。与光学相机曝光一段时间内的像素阵列图像不同,事件相机感知场景亮度的变化,各像素输出异步事件数据,具有低时延、高动态范围的特性(Gallego 等,2022)。事件相机的低时延(<1 μs)的特性使其能够避免在高速运动场景下产生运动模糊(付婧祎 等,2023),高动态范围(约130 dB)的特性使其可以捕获更大的场景亮度范围信息(余磊 等,2023)。因此,利用事件相机低时延与高动态范围的特性可以有效提升视觉场景识别算法在高速和高动态范围场景等极端场景下的性能。Milford等人(2015)首次提出基于事件的视觉场景识别方法,将事件流在时间窗口内累积计数为灰度图像,并通过基于图像序列的SeqSLAM 进行检索与匹配。Fischer 和Milford(2020)提出了基于事件重建的视觉场景识别方法,通过事件重建方法(Rebecq等,2021;Scheerlinck等,2020)对等时间间隔划分的事件进行亮度图像重建,然后再基于重建出的图像序列完成场景识别。Lee 和Kim(2021)通过事件信息重建场景边缘图像,再利用NetVLAD 进行特征生成及匹配,实现了从事件到事件的视觉场景识别。Kong 等人(2022)提出了从事件到事件的端到端匹配的视觉场景识别方法。然而,现有基于事件相机的视觉场景识别方法都仅利用事件与事件进行同模态匹配或仅利用事件与参考图像数据库进行跨模态匹配。而事件具有极低的信噪比,且仅包含稀疏的边缘特征(Gallego 等,2022),限制了上述方法的场景识别性能。
综上,融合图像与事件的信息,同时利用事件的低延时、高动态范围的性质以及图像丰富的纹理细节与亮度信息,可以有效提升视觉场景识别算法的性能。本文提出了融合事件相机的视觉场景识别算法,如图1 所示。该方法将查询图像和其曝光期间内的事件信息与参考图像数据库中的图像进行比较,最终筛选出与查询图像场景最相似的参考图像作为查询结果图像。为了对不同模态信息进行比较,本文方法首先将参考图像数据库中质量良好的图像输入图像特征提取模块得到参考图像特征;然后,将查询图像及其曝光时间区间内的事件信息输入多模态特征融合模块(multimodal feature fusion module,MFF)得到融合特征;最后,通过特征匹配查找与查询图像最相似的参考图像。

图1 融合事件相机的视觉场景识别示意Fig.1 Illustration of VPR with fusion event cameras
本文的主要贡献如下:1)提出了一种融合事件相机的视觉场景识别方法,结合光学图像信息和事件信息的优势,解决了高速、高动态范围场景下传统场景识别算法识别性能下降的问题;2)提出了多尺度特征融合模块,在不同尺度融合了图像和事件两种不同模态的信息,解决了多模态信息有效融合的问题;3)在不同数据集上,对本文方法与现有视觉场景识别算法在高速、高动态范围场景下进行了召回率与识别精度的评估与比较,验证了提出方法在高速、高动态范围场景下相对于现有视觉场景识别算法具有更好的场景识别性能。
1 融合事件相机的视觉场景识别
1.1 任务描述
基于光学图像的视觉场景识别算法通过图像信息查询参考图像数据库,从而获得与查询图像最相似的参考图像。然而,高速、高动态范围场景会导致查询图像出现运动模糊、曝光不足或过曝光现象,进而导致这类算法的性能下降。基于事件的视觉场景识别算法通过事件信息查询参考图像数据库并获取与查询事件信息所处场景一致的参考图像。然而,事件信息缺少场景的光照强度与纹理信息,并且需要场景变化才能够产生有效的事件,这也限制了这类算法的场景识别性能。
本文提出融合事件相机的视觉场景识别算法解决上述问题。该算法通过光学图像B及其曝光时间区间T内的事件集合ε,从参考图像数据库J 中检索与查询图像B所对应的场景最匹配的参考图像Im。由于输入的查询信息是多模态信息,与参考图像不能直接比较,因此,要对多模态查询信息进行有效地融合,并且将多模态查询信息与参考图像信息映射到同一特征空间内进行比较。
1.2 方案
本文方案的网络架构如图2 所示。对于质量良好的参考图像输入,通过图像特征提取模块(image feature enhance module,IFE)提取图像的特征FI;对于多模态查询信息输入,首先将事件集合ε通过事件预处理模块(event to frame module,EFM)转换为固定张量Tε,然后与查询图像B一同输入多尺度特征融合模块(multi scale fusion module,MSF)以生成融合特征Fp。参考图像和查询图像的场景越相近,参考图像特征与查询信息的融合特征的向量相似度越高,反之越低,从而能够通过向量相似度检索与查询图像场景最相似的参考图像。
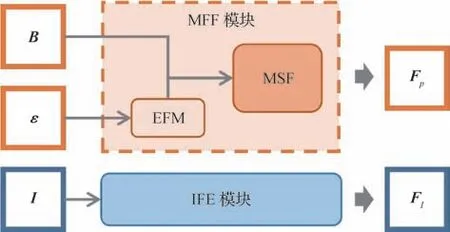
图2 提出方案的网络架构示意Fig.2 Illustration of the architecture of the proposed method
1.2.1 事件预处理模块EFM
不同于光学相机定时曝光图像,事件相机受外界环境变化驱动,各像素异步且独立地根据该像素捕获到的亮度变化输出事件(Gallego 等,2022)。事件相机在像素位置x处连续检测对数域的光强变化,当t时刻的光强相较该像素上一次产生事件的时刻tref记录的光强在对数域变化超过阈值C(C>0)时,事件相机在该像素处输出一个事件,具体为
式中,I(x,t)与I(x,tref)分别表示t时刻与tref时刻在像素x处的瞬时光强,ΔI是两时刻光强在对数域的变化值。事件的极性p定义为
事件被定义为e={x,t,p},其中,x是事件触发的像素坐标,t是触发事件时对应的时间戳,极性p∈{-1,+1}反映该像素是变亮(p=+1)还是变暗(p=-1)。
由于事件集合是三元组的集合,与图像的固定张量表示不同,不利于通过通用卷积神经网络架构对图像信息与事件信息进行融合。本文方法通过事件预处理模块EFM将事件集合ε转换为固定张量Tε以解决该问题。
如图3 所示,本文将事件集合对应的时间区间切片平均为K份以更充分地利用事件的高时间分辨率特性。切片得到若干个事件子集合,并按照事件极性分别进行事件累积计数(Maqueda 等,2018),从而得到2K×H×W的张量。其中,2K表示K份时间切片两种不同极性的累积。本文取时间切片数K=48,H×W表示事件相机的空间分辨率。

图3 事件集合时间区间切片示意Fig.3 Illustration of event stream time interval slice
1.2.2 多尺度特征融合模块MSF
高速、高动态范围场景下的光学相机捕获的图像会产生运动模糊、欠曝光或过曝光等现象,而利用事件的低时延与高动态范围特性能够对其进行增强。
本文提出多尺度特征融合模块MSF,在不同尺度对图像与事件信息进行特征融合,并通过空间通道注意力模块CBAM(convolutional block attention module)(Woo 等,2018)筛选特征图中位置和通道两个层面上的有效信息,以充分利用事件信息增强图像特征。
如图4 所示,图像B和事件张量Tε输入到MSF模块并最终生成融合特征。MSF模块由Pre-Fusion、Fusion 和Final-Fusion 子模块组成,在不同尺度对多模态的输入信息进行融合并最终得到多模态融合特征。

图4 网络模块架构与网络细节示意Fig.4 Schematic diagram of network module architecture and network details
Pre-Fusion 模块输入图像B和事件张量Tε,通过Conv 与DConv 子模块,分别生成图像与事件张量特征FB0,Fε0,并将特征连接后通过ResBlock 子模块生成最初尺度下的融合特征FF0。
Fusion 模块输入第n个尺度下的图像特征FBn、事件张量特征FEn及融合特征FFn,通过DConv 子模块生成第n+1 个尺度下图像特征FB(n+1)及事件张量特征Fε(n+1),然后将融合特征FFn通过DConv 子模块后与上述特征一并连接,并通过ResBlock 子模块生成第n+1个尺度下的融合特征FF(n+1)。
Final-Fusion 模块输入第N个尺度下的图像特征FBN、事件张量特征FεN及融合特征FFN,首先将上述特征连接后通过ResBlock子模块得到初始多尺度融合特征FP0;然后通过CBAM 模块筛选特征图位置与通道两个层面上的有效信息,得到融合特征图;最终将特征图展开为向量并进行L2 归一化得到融合特征向量Fp。
其中,Conv 是步长为1 的单层卷积层,DConv 是步长为2 的下采样卷积层与步长为1 的卷积层的组合,ResBlock 是含残差连接的卷积层(He 等,2016)。所有卷积层的卷积核大小为3×3,其后连接的激活函数为ReLU(rectified linear unit)。
1.2.3 图像特征提取模块IFE
图像特征提取模块IFE 的目标是将参考图像数据库中质量良好的图像映射到特征向量空间中。
如图4 所示,图像特征提取IFE 模块由Conv、DConv 和ResBlock 子模块组成。各子模块与1.2.2节中的定义一致。通过IFE 模块可以将输入参考图像I通过多尺度卷积映射为特征图。然后将特征图展开为向量并进行L2 归一化即得到参考图像特征向量FI。
1.2.4 网络训练方法
本文通过三元组损失(Schroff 等,2015)端到端监督多模态特征融合模块MFF 和图像特征提取模块IFE 的参数学习,使得上述两模块生成的特征向量的相似度能够反映其输入视觉信息的场景相似程度。
如图5 所示,网络训练首先构造查询、正例与负例三元组。其中,查询是光学图像B及其曝光时间区间内的事件集合ε,正例Ip是与查询图像B场景相似的图像,负例In是与查询图像B场景不同的图像。然后,将三元组通过对应的网络映射为特征向量Fp,,并通过三元组损失约束各特征向量间的关系,具体为

图5 网络训练方法示意Fig.5 Schematic diagram of network training method
式中,函数max 取两输入中的较大值,d求输入两向量间的L2距离,M是相似度距离常数。
三元组损失驱动网络向查询特征Fp与正例特征距离(记为正例距离)更小、与负例特征距离(记为负例距离)更大的方向学习,直到负例距离与正例距离的差值不小于相似度距离常数M,从而能够根据在特征向量空间的相似度区分与查询图像视场相似以及视场不同的参考图像,并进一步完成视觉场景识别任务。
2 实验与分析
2.1 实验数据集
2.1.1 实验数据集介绍
实验数据集需要同时满足:1)包含质量良好的参考图像集合及其曝光区间内的事件集合;2)包含与参考图像视场一致的、高速高动态范围场景下的光学图像及其曝光区间内的事件集合。然而目前暂未有满足上述条件的数据集,因此本文通过质量良好的参考图像集合及其曝光区间内的事件集合仿真高速高动态范围场景下与参考数据对应的数据。
为了便于仿真数据集的构造与网络训练三元组的构造,本文选择MVSEC(multi vehicle stereo event camera dataset)数据集(Zhu 等,2018)和RobotCar 数据集(Maddern 等,2017)进行实验。两数据集原始数据不存在运动模糊、曝光适中且记录的场景是连续的。
MVSEC 数据集使用DAVIS346 事件相机同时记录时间连续且时空对齐的图像序列及事件信息,空间分辨率为260×346像素,帧率约为45 帧/s。实验选择两个图像质量良好且视场不重复的时间序列,且两序列记录的场景有明显差异。数据集两序列包含共36 000 幅图像及其曝光时间区间内的事件集合。
RobotCar 数据集使用光学相机记录时间连续且视场不重复的图像序列,空间分辨率为960×1 280像素,帧率约为16 帧/s。实验选择了图像质量良好的日间阴天序列,首先将其空间分辨率通过双三次插值下采样为240×320 像素,然后通过RIFE(realtime intermediate flow estimation)(Huang 等,2022)将图像时间分辨率上采样16 倍并输入ESIM 事件生成器(Gehrig 等,2020)生成模拟事件流,并添加30%的均匀随机分布噪声(Wang等,2020)模拟真实场景的事件。最后将序列均分为两个视场不重合且有明显差异的序列,每个序列包含10 000 幅图像及其曝光时间区间内的模拟事件集合。
2.1.2 仿真数据集生成
1)高速高动态范围场景下的图像生成流程。根据模糊图像产生的物理过程仿真模糊图像,通过将原始图像Ii前后连续S幅清晰图像集合平均得到模糊图像(Zhang 和Yu,2022),具体为
式中,Iis是Ii前后连续S幅清晰图像集合中的第s幅清晰图像,本文实验中S=7。
通过动态范围的裁剪模拟低动态范围图像的产生过程(Liu 等,2020)。首先将模糊图像与变换参数α相乘完成线性光度变换,然后fclip将线性光度变换的结果限制在区间[Ll,Lh]中并对光度值取整。该过程生成高速高动态范围场景下的图像Bi,具体为
式中,本文实验取Ll=10,Lh=255。对MVSEC 数据集,光度变换参数α在模拟低光强与高光强条件时分别设置为0.25 和4。而RobotCar 数据集原始数据亮度均值较MVSEC 数据集更高,因此对RobotCar 光度变换参数α在模拟低光强与高光强条件时分别设置为0.15和2。得到的图像Bi的曝光区间是M幅清晰图像曝光区间的并集,并且记曝光区间内的事件集合为εi;Bi的时间戳与曝光中心时刻图像Ii保持一致。
2)高速高动态范围场景下的事件仿真。在高速场景下事件触发率增大,事件相机会产生数据阻塞进而导致时间戳偏移(Gallego 等,2022),因此实验对每一事件流εi添加参数为100 μs 均匀分布的时间戳随机噪声以仿真高速条件下的事件流。低光照强度场景下,事件相机输出的背景噪声事件会增多(Gallego 等,2022),实验通过对每一事件流εi添加10%背景噪声事件仿真低光强条件下的事件流。高光照强度场景下,事件相机输出的背景噪声事件会减少(Gallego 等,2022),实验通过对每一事件流εi进行背景噪声滤波仿真高光强条件下的事件流,滤波过程滤除近邻的5×5 像素都无事件触发的像素激发的事件。
由前述仿真方法,可以由参考图像数据库及其曝光区间内的事件集合仿真生成高速高动态范围场景下与参考数据对应的数据。
2.2 实施细节
本实验使用PyTorch 深度学习框架通过1.2.4节的网络训练方法对网络进行端到端的训练,网络使用SGD(stochastic gradient descent)优化器(Bottou,2010)进行训练,学习率的初始值为10-4,并采用余弦学习率衰减策略,当迭代次数达到最大值100时学习率衰减到0。
实验数据集的各个序列按照60%、20%和20%划分为训练集、验证集与测试集。此外,对实验数据集中所有的空间分辨率为260×346 像素及240×320 像素的张量随机裁剪为224×224 像素的张量以进行数据增强,并将裁剪后的张量作为网络的输入。
对高速高动态场景下的查询图像B及其曝光区间内的事件集合ε,由于本文两个数据集记录时间连续的视频,因此可以随机在查询所在序列选择图像时间戳与B的时间戳差值在1 s 以内的图像Ip作为与查询视场相近的图像,即正例;又由于本文实验的两个数据集都被分为两组视场有明显差异的序列,因此,一序列的查询可以直接在另一序列中随机选择图像In作为视场不同的图像,即负例。查询、正例与负例三元组的示例可视化如图6 所示。此外,训练过程中高速高动态范围场景下的查询随机从仿真的高速低光强与高速高光强数据中挑选,以平衡网络对低光强与高光强场景的处理能力。

图6 训练三元组的可视化Fig.6 Visualization of training triples
由于数据集的时间连续特性,与三元组挑选的规则类似,若用于查询的光学图像B的时间戳与查询结果图像Im的时间戳差值小于1 s时,则认为两者场景相似,匹配成功。实验评估指标为召回率Recall@1 与识别精度Acc@10。召回率Recall@1 记为测试数据集上的匹配成功率。Acc@10 记为测试数据集上所有查询图像识别精度的平均值。其中,每幅查询图像的识别精度定义为
式中,k是每幅查询图像检索结果的前10 幅图像中满足上述匹配成功条件的数量。
2.3 高速高动态范围场景下的场景识别实验
为了验证本文方法在高速高动态范围场景下的识别性能,实验在2.1.2 节构建的包含高速高动态范围场景下的图像与事件以及与之对应的参考图像的仿真数据集上进行。并分别与基于图像、基于事件以及同时利用图像与事件的视觉场景识别方法进行比较。
2.3.1 实验对比方法
基于图像的视觉场景识别对比方法为NetVLAD(Arandjelovic 等,2016)。此外,由于存在基于图像的动态范围增强算法和图像去模糊算法,因此实验还构造了对比方法HDR-MIMO。HDR-MIMO由图像动态范围增强算法HDRUNet(Chen 等,2021)与图像去模糊算法MIMO-UNet(Cho 等,2021)及视觉场景识别算法NetVLAD 级联,该方法首先增强高速高动态范围场景下的图像质量,再进行视觉场景识别。
基于事件的视觉场景识别对比方法为E2VIDVPR,该方法首先通过事件强度图像重建方法E2VID(Rebecq 等,2021)由事件生成强度图像,然后根据该强度图像利用基于图像的NetVLAD 进行视觉场景识别。
由于暂未有同时利用图像和事件的视觉场景识别方法及融合事件的图像动态范围增强的开源方法,因此实验构造了HDR-eSL 方法作为同时利用图像和事件的对比方法。HDR-eSL由图像动态范围增强算法HDRUNet(Chen 等,2021)与事件增强的图像去模糊算法eSL-Net(Wang 等,2020)及NetVLAD级联,该方法同时利用图像和事件信息,增强高速高动态范围场景下的图像质量,再进行视觉场景识别。
由于HDRUNet 与MIMO-UNet 的预训练场景与本文数据集的驾驶场景区别较大,因此对其在本文训练数据集上进行了微调。除此之外,上述提到的其余网络均使用其预训练模型进行测试。
2.3.2 实验结果与分析
在MVSEC 与RobotCar 数据集上的定量实验结果分别如表1 与表2 所示,其中01 与02 表示各数据集的序列编号,高速低光强和高速高光强表示测试数据集查询数据的场景条件。本文方法在两个数据集不同场景下的测试示例的可视化如图7 所示,其中B,ε分别是查询图像及其曝光区间内的事件,I是参考图像,Im是本文算法得到的与参考图像最匹配的图像。

表1 高速高动态范围场景下各算法在MVSEC数据集的召回率与识别精度Table 1 Recall rates and precision of each algorithm in MVSEC dataset under high-speed and high-dynamic scenarios/%
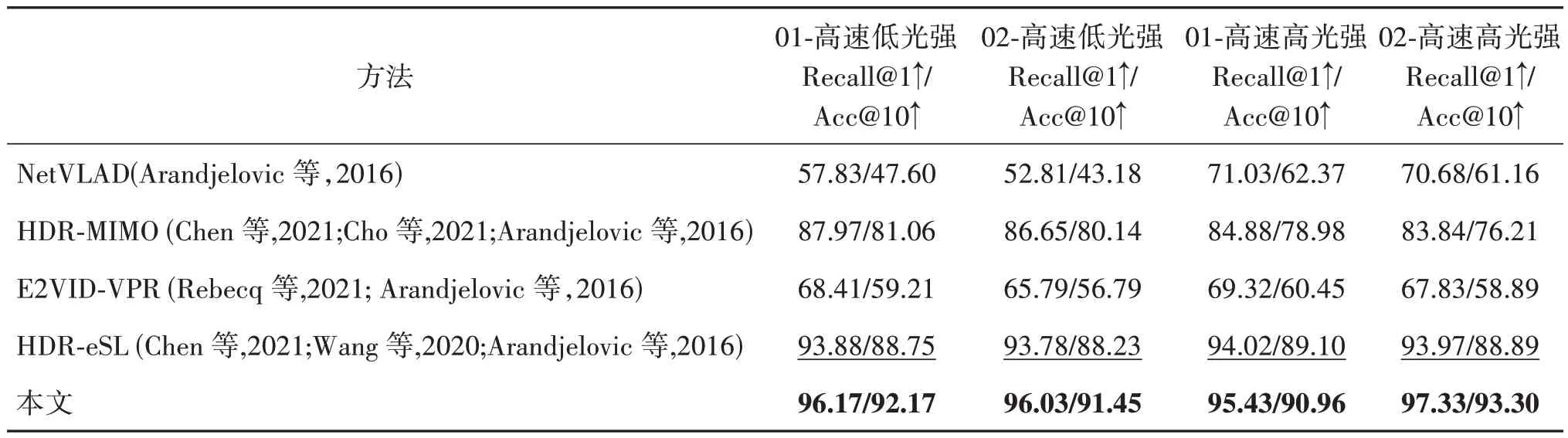
表2 高速高动态范围场景下各算法在RobotCar数据集的召回率与识别精度Table 2 Recall rates and precision of each algorithm in RobotCar dataset under high-speed and high-dynamic scenarios/%

图7 实验数据集测试示例的可视化Fig.7 Visualization of experimental dataset test examples((a)MVSEC dataset;(b)RobotCar dataset)
基于图像的方法中,NetVLAD 直接将高速高动态场景下的图像输入网络得到特征并用于查询。然而,如图8(b)所示,当图像模糊且曝光不佳时损失了结构纹理与光度信息,进而导致该方法识别性能不佳。HDR-MIMO 通过对输入图像进行动态范围增强以及去模糊提升了图像质量后再通过NetVLAD 方法进行匹配与识别,该方法恢复的图像如图8(c)所示。由表3 可知,该方法恢复的图像相对查询图像在峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)两个指标上均有较大的提升。得益于图像质量的提升,该方法性能优于NetVLAD 方法,然而单幅图像盲去模糊的不适定性会限制其去模糊的性能(Zhang和Yu,2022)。此外,多级网络级联的误差累积也限制了其识别性能。E2VID-VPR 方法仅利用事件信息,在事件充足且持续一定的时间后才能得到纹理与结构信息较为丰富的重建图像。此外,事件重建图像的过程缺乏亮度信息的引导,因此重建图像与参考图像的亮度有明显差异,如图8(e)所示。由表3可知,其图像质量指标峰值信噪比PSNR 和结构相似度SSIM 极低。上述问题导致该方法的识别性能不佳。HDR-eSL 方法同时利用图像和事件信息,首先将原始图像动态范围增强后通过基于事件的去模糊网络得到质量较好的图像,再通过NetVLAD 方法进行匹配与识别。该方法恢复的图像如图8(d)所示,得益于事件相机的高时间分辨率,HDR-eSL方法恢复的图像较HDR-MIMO 的结果更清晰。由表3可知,该方法恢复的图像在PSNR 和SSIM 两个定量指标上均优于HDR-MIMO 方法。然而,其没有利用事件的高动态特性对图像进行动态范围增强,且多级网络级联的误差累积也限制了其识别性能。本文方法利用事件信息的低延时与高动态范围特性对图像进行隐式增强,使得生成的融合特征能够隐式表示清晰且曝光良好的场景图像。为了验证该论述,首先固定本文多模态特征融合模块的网络权重,然后在后续添加上采样网络将融合特征解码为图像,记该级联网络为HD(HDR-Deblur)。训练采用参考图像作为监督信号,以完成上采样网络的训练。通过HD 网络恢复的图像如图8(f)所示,相对其他算法,HD网络恢复的图像更清晰且曝光良好。定量指标如表3 所示,该方法在PSNR 与SSIM 两个指标上均优于对比方法。该实验表明本文方法生成的融合特征能够隐式表示清晰且曝光良好的场景,且恢复图像质量高于对比方法。
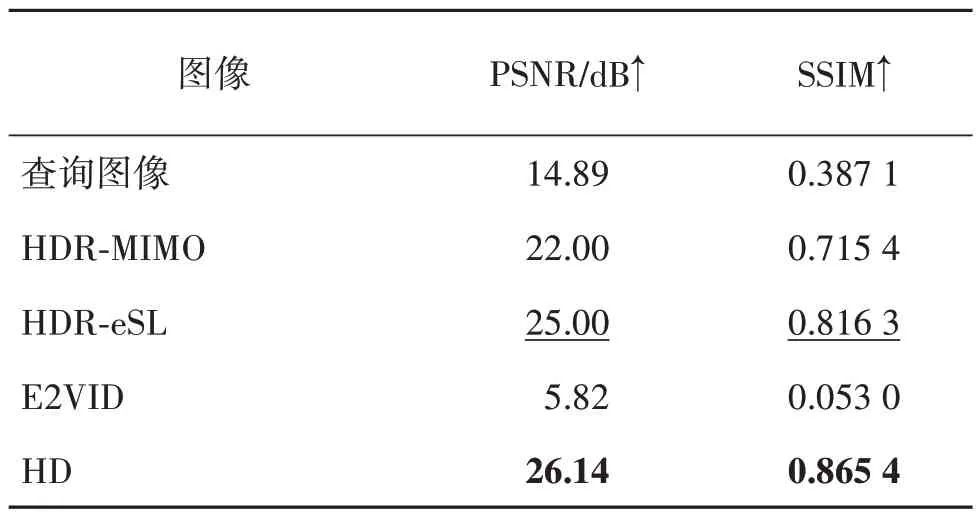
表3 各方法所得图像的定量指标(真值为参考图像)Table 3 Quantitative indicators of the images obtained by each method(the ground truth is the reference image)

图8 对比方法的可视化Fig.8 Visualization of comparison methods((a)reference image;(b)query image;(c)image reconstructed by HDR-MIMO;(d)image reconstructed by HDR-eSL;(e)image reconstructed by E2VID;(f)image reconstructed by HD)
测试数据集的特征距离矩阵如图9 所示。其中横纵轴都为时间,该矩阵中坐标为(t1,t2)的值表示在t1时刻记录的高速高动态范围场景下的图像及其对应事件集合生成的融合特征与在t2时刻记录的参考图像生成的图像特征之间的向量欧氏距离。由图9可知,总体来说,多模态查询信息与图像信息的时间差越小,也即拍摄位置的物理距离越近、场景越相似,通过本文方法生成的特征距离就越小,反之亦然。这说明通过本文方法生成的特征的向量相似度能够有效地表示场景的相似度。
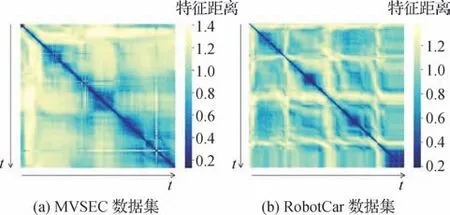
图9 测试数据集的特征距离矩阵Fig.9 The feature distance matrix of the test dataset((a)MVSEC dataset;(b)RobotCar dataset)
由于本文方法结合了光学相机图像纹理与结构信息丰富的特点以及事件信息低时延、高动态范围的优势,且端到端的特征生成过程也避免了多级级联带来的误差累积,因此本文方法在两个实验数据集上均取得了所有方法中最优的识别性能。
2.4 消融实验
本节对提出的网络模块与场景运动模糊程度进行消融实验,以进一步说明本文提出模块的作用,并证明本文方法在不同运动模糊程度下的场景具有较好的鲁棒性。
2.4.1 网络模块消融实验
现有事件相机信息和图像信息融合的图像增强算法往往直接将图像与事件的通道合并,再进行多层卷积(Wang 等,2020),或是在单一尺度下将图像特征与事件特征融合(Shang等,2021)。本文提出的多尺度特征融合模块MSF 和最终融合模块CBAM,与现有方法不同,多尺度特征融合模块在不同尺度对图像与事件两种不同模态的信息进行了多模态融合,最终融合模块CBAM 对输出特征图进行了空间和通道两个层面上的信息筛选。本节将对上述两个模块进行消融实验。
对于多尺度融合策略的消融,采用仅在最终尺度下将多模态信息融合作为对比;对于最终融合模块CBAM,考虑将其去除作为对比。记仅最终尺度融合且去除CBAM 模块的方法为w/o all,仅最终尺度融合但保留CBAM 的方法为w/o MSF,仅去除CBAM模块的方法为w/o CBAM,完整方法为 w/all。
消融实验在MVSEC 数据集上进行并统计两个序列召回率与识别精度的加权均值。高速低光强和高速高光强表示测试数据集的场景条件。定量结果如表4 所示。从定量结果可以看出,相对于仅在最终尺度进行多模态特征融合,多尺度特征融合模块MSF在不同尺度多次对两种模态信息进行多模态融合,有助于充分融合图像与事件信息,提升融合特征隐式表示场景的能力。最终融合模块CBAM 有助于筛选生成融合特征的有效信息。两个模块均使得方法的场景识别性能得到提高。
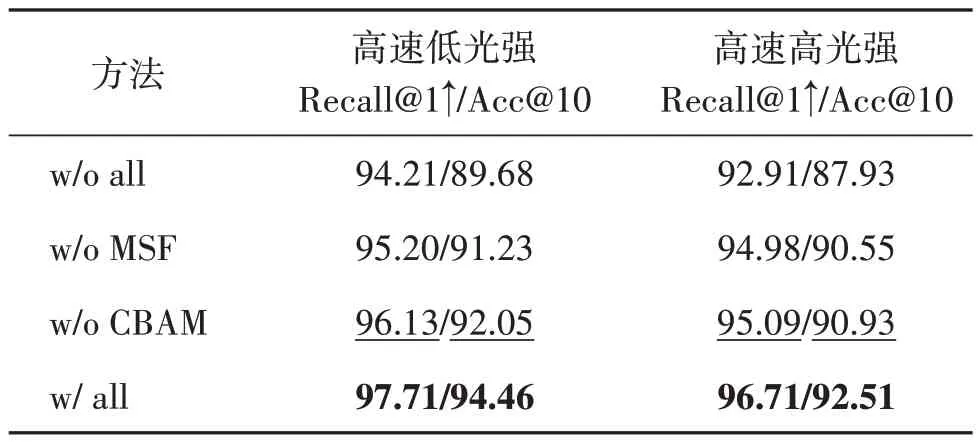
表4 不同模块策略下本文方法在MVSEC数据集上的召回率与识别精度Table 4 Recall rates and precision of proposed method on MVSEC dataset under different module strategies/%
2.4.2 不同运动模糊程度下的场景识别实验
本文在2.1.2 节介绍了高动态范围运动模糊图像的仿真方法,前述实验中控制模糊图像生成的参数M设置为7,现将参数M分别设置为3,7,13,以仿真不同程度的模糊图像。高动态范围生成过程与2.1.2节的生成过程一致。实验在MVSEC数据集上进行并统计两个序列的召回率和识别精度的加权均值。定量结果如表5所示。

表5 不同运动模糊程度场景下本文方法在MVSEC数据集的召回率与识别精度Table 5 Recall rates and precision of proposed method on MVSEC dataset under different motion blur scenarios/%
从定量结果可以看出,得益于事件信息低延时的特性,对于不同模糊程度下的场景,本文方法的召回率与识别精度波动较小,且均能够得到较好的视觉场景识别性能。该实验说明本文方法在不同运动模糊程度下的场景具有较好的鲁棒性。
3 结论
针对传统视觉场景识别算法在高速、高动态范围等场景条件下存在由于图像质量下降而导致算法性能下降的问题,本文提出融合事件相机的视觉场景识别算法,通过多模态特征融合模块将光学图像亮度与纹理信息丰富的优势以及事件相机低时延与高动态范围的优势结合,以在高速高动态场景条件下取得良好的识别性能。实验结果表明,本文方法相对现有视觉场景识别方法在MVSEC 与RobotCar数据集上召回率分别最高有5.39%与3.36%的提升,精度分别最高有8.55%与4.41%的提升。
尽管本文方法在高速高动态范围场景条件下具有较好的场景识别性能,但仍具有一些局限。由于事件相机的事件由场景变化驱动,当场景速度较慢或静止且场景动态范围较广时,事件相机的事件触发率低,使得提出方法难以利用事件信息增强图像动态范围而导致性能下降。因此,在今后的研究中,可以在当前方法的基础上融合红外相机等不依赖光度的视觉传感器,从而在不同速度的高动态场景下都能取得较好的场景识别性能。
猜你喜欢
卫星应用(2022年7期)2022-09-05
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
疯狂英语·新策略(2019年10期)2019-12-13
环球慈善(2019年6期)2019-09-25
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
河南科技(2014年23期)2014-02-27
