
图像去模糊研究综述
2024-04-22 00:47胡张颖周全陈明举崔景程吴晓富郑宝玉
中国图象图形学报 2024年4期
胡张颖,周全*,陈明举,崔景程,吴晓富,郑宝玉
1.南京邮电大学通信与信息工程学院,南京 210003;2.四川轻化工大学人工智能四川省重点实验室,宜宾 644000
0 引言
图像模糊是由于图像采集过程中的成像设备自身的散焦、抖动或图像物体运动等因素导致的(Joshi等,2008;Sun 等,2015)。例如,拍摄运动中的物体时,快门时间较长或手持相机不稳定,会导致图像模糊。而这种模糊会降低图像的质量,影响图像的视觉感受效果和有效信息提取。为了解决这个问题,图像去模糊技术应运而生。通过运用先进的算法和技术,可以将模糊的图像转化为清晰、锐利的图像,并重新展现其细节和质感。这种图像去模糊技术在医疗(Sharif 等,2023)、安防监控(马苏欣 等,2019)、图像分类(He 等,2016)和目标检测(Isola 等,2017)等领域具有重要的应用价值。因此,研究如何对这些图像进行去模糊成为底层计算机视觉领域的一项重要任务,并具有广泛的应用前景。
根据造成图像模糊的原因,模糊类型主要可以分为运动模糊(motion blur)、散焦模糊(out-of-focus blur)和高斯模糊(Gaussian blur)(Zhang 等,2022)。目前的研究主要关注解决图像运动模糊问题,因为相比于散焦模糊和高斯模糊,图像运动模糊更常见且较难处理。特别是在拍摄运动物体或快速移动场景时,图像容易受到运动模糊的影响。在进行图像去模糊后,需要对处理结果进行评价。常用的方法是图像质量评价(image quality assessment,IQA),IQA可以分为主观评价和客观评价两类(程茹秋 等,2022),而客观评价方法又可分为全参考(Wang 等,2017)、半参考(Liu 等,2018)和无参考(Mittal 等,2012;Kang 等,2014)3 类。鉴于主观评价方法需要耗费大量人力物力资源,在实际应用中更多采用客观评价方法。
传统图像去模糊方法可以视为反向求解图像模糊模型的问题。当整个图像模糊均匀时,模糊模型可以建模为模糊图像与模糊核的卷积过程(Fergus等,2006;Chen 等,2019)。在已知模糊核的情况下,可称之为非盲去模糊问题(Yuan 等,2008),早期采用图像先去噪后反卷积或迭代求解模糊过程两种算法来处理这些模糊图像。而在未知模糊核或清晰图像的情况下,则属于盲去模糊问题(Krishnan 等,2011),传统方法主要先通过估计模糊核,再转变为非盲图像去模糊问题。然而,传统方法更适用于均匀模糊,对于多物体运动和复杂环境下的非均匀模糊效果不佳。随着深度学习的发展,基于端到端的深度学习图像去模糊方法相继提出。相比于传统图像去模糊的方法,基于深度学习的方法能够自动学习图像模糊过程中的深度特征,避免模糊核估计过程。这些方法包括基于卷积神经网络(convolutional neural network,CNN)(Nah 等,2017;Cho 等,2021)、基于循环神经网络(recurrent neural network,RNN)(Zhang 等,2018;Gao 等,2019)、基于生成对抗网络(generative adversarial network,GAN)(Kupyn 等,2018)和基于Transformer(Wang等,2022)等。
本文结构如图1 所示。对图像去模糊领域的研究进展进行全面综述,分别从传统图像去模糊方法和基于深度学习的一些新兴方法两个方面展开论述。首先,回顾图像去模糊的发展历程,然后介绍不同类型的模糊和质量评价指标。接着,详细讨论图像去模糊的传统方法和基于深度学习模型的方法。在传统方法方面,根据模糊核是否已知对其进行分类;而在基于深度学习的方法方面,则根据网络模型架构进行细分,并阐述不同网络模型方法的应用。然后,介绍图像去模糊领域的公共基准数据集以及对具有代表性的算法进行全面评估分析。最后,分析图像去模糊领域所面临的挑战,并对存在的一些问题进行总结和展望。
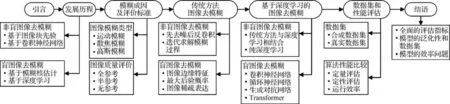
图1 本文架构Fig.1 The architecture of this paper
Zhang 等人(2022)的综述更多关注基于深度学习的图像和视频去模糊的方法,而本文综述深入探讨了图像去模糊领域传统方法和基于深度学习的方法之间的区别和联系,以及近期在图像去模糊任务中应用和研究的Transformer 方法。相较现有综述,本文更全面地梳理了图像去模糊领域的进展,并对相关领域起到借鉴和推动的作用。
1 图像去模糊方法的发展历程
图像去模糊领域自20世纪60年代发展至今,产生了许多具有影响力的工作。传统的图像去模糊方法大都采用线性模型进行建模,无法有效应对复杂先验分布下的图像去模糊问题。随着深度学习技术的日益发展,深度学习模型可以利用大量的训练数据自主选择特征,并借助其自身非线性特性广泛应用于图像去模糊问题。本文对图像去模糊自2005年以来的发展进行总结,图2 按时间轴在图像非盲去模糊和图像盲去模糊两个领域展示了一些传统方法和深度学习方法。其中黄色箭头表示被广泛认为较经典的算法;蓝色和紫色箭头分别表示非盲图像去模糊和盲图像去模糊中较具有代表性的算法。

图2 图像去模糊的发展历程Fig.2 Chronology of classical methods for image deblurring
1.1 非盲图像去模糊
1.1.1 基于图像块先验的非盲图像去模糊
Zoran 和Weiss(2011)采用高斯混合模型对图像块进行建模,并将学习到的图像特征作为去模糊的正则化项。该方法证明了使用小图像块时,可以有效地学习先验信息以进行图像恢复,引起了很多研究人员的广泛关注。其他代表性的工作包括:先去噪后反卷积(Chen 等,2010;Danielyan 等,2012)和迭代求解模糊过程(Yuan 等,2008;Kheradmand 和Milanfar,2014;Khetkeeree 和Liangrocapart,2019)的图像去模糊方法。
1.1.2 基于卷积神经网络的非盲图像去模糊
模型优化和判别式学习是解决底层视觉任务中逆问题的两种策略,Zhang等人(2017)将两种方法进行结合,训练快速有效的CNN去噪器,以解决非盲图像去模糊问题。随着深度学习的发展,其他具有代表性的工作还包括:传统方法与深度学习相结合的方法(Zhang等,2019b;Dong等,2022)和纯深度学习的方法(Vasu等,2018;Zhou等,2020;Eboli等,2020)。
1.2 盲图像去模糊
1.2.1 模糊核估计的盲去模糊方法
Fergus 等人(2006)的方法摒弃了以往盲去模糊方法对卷积核或图像的先验假设,实现了真正意义上的盲图像去模糊。这类方法重点集中在未知模糊核的估计上,因为一旦能够准确估计模糊核,任何非盲去模糊算法都可以用估计的模糊核对图像进行去模糊。传统盲图像去模糊具有代表性的工作还包括以下几种方法:基于图像边缘特征的方法(Joshi等,2008;Chen 等,2019);基于最大后验概率(maximum a posteriori,MAP)的方法(Shan 等,2008;Cho和Lee,2009;Levin 等,2011);基于图像稀疏表达的方 法(Krishnan 等,2011;Pan 等,2016;Yan 等,2017)。
1.2.2 基于深度学习的盲去模糊方法
Sun 等人(2015)首次将CNN 应用到图像去模糊领域,是图像去模糊领域的一个重要转折点。它利用图像块统计信息来建模非均匀运动模糊,并取得了显著效果。随着深度学习的发展,盲图像去模糊的代表性工作还包括:基于卷积神经网络的方法(Nah 等,2017;Zamir 等,2021);基于循环神经网络的SRN-DeblurNet(scale-recurrent network for deep image deblurring)(Tao 等,2018);基于生成对抗网络的DeblurGAN(Kupyn 等,2018)和在其改进DeblurGAN-v2(Kupyn 等,2019);基于Transformer 的Restormer(Zamir等,2022)和CTMS(CNN-Transformer multiscale structure)(Zhao 等,2023)。这些深度学习的方法要么估计模糊核再进行反卷积去模糊,要么采用端到端的方法,直接从模糊图像预测清晰图像。
2 图像模糊成因及评价标准
图像模糊是由多种原因引起的,主要包括运动模糊、散焦模糊和高斯模糊,使得图像中的细节不清晰、边缘模糊或整体呈现出模糊的效果(Zhang 等,2022)。在对图像进行去模糊处理后,需要评估图像的清晰度,通常采用一些图像质量评价标准来衡量图像的质量。这些评价标准能够确定恢复图像是否清晰,并提供一种客观的方式来比较不同图像处理算法的性能。下面分别从模糊成因和图像评价标准进行综述。
2.1 常见的模糊类型
图像在获取和存储过程中存在着许多不确定的因素,无论是拍摄时物体的快速移动或相机设备的抖动等形成的运动模糊,还是相机设备聚焦不当造成的散焦模糊,或是天气因素产生的高斯模糊。模糊类型错综复杂,但图像模糊过程可以统一建模为
式中,X为清晰图像,Y为模糊图像,K为模糊核或点扩散函数(point spread function,PSF),其中⊗为卷积操作,N为加性噪声。整个图像模糊过程可以表示为原始清晰图像X与模糊核K进行卷积运算,并加上噪声得到模糊图像Y。
2.1.1 运动模糊
根据模糊区域,可以将运动模糊划分为全局运动模糊和局部运动模糊两类(刘利平 等,2022)。全局运动模糊是指整个图像在同一方向上发生模糊,通常是由相机或物体的移动造成(Pan 和Su,2013;Yan 等,2017)。例如,当在拍摄运动车辆时,由于相机或车辆移动,图像中的车辆会变得模糊不清,这就属于全局运动模糊。局部运动模糊是指图像中只有某些区域发生模糊,通常是由物体的运动或相机焦距的变化造成(Dai和Wu,2008)。例如,当在拍摄一个人物时,如果他的手或头部移动了,这些区域就可能出现局部运动模糊。通常情况下,大多数运动模糊的模糊核是不清楚的,因此运动模糊大多是图像盲去模糊问题。
2.1.2 散焦模糊
散焦模糊通常是因为相机或镜头无法将图像的所有部分聚焦在同一平面上,导致图像变得模糊不清(Shen 等,2012;衡红军 等,2021;Quan 等,2023)。当相机或镜头无法正确对焦时,图像中的物体会失去清晰度,看起来模糊或者像是被涂上一层薄雾。散焦模糊的点扩散函数表示为
式中,F(x,y)表示模糊核在位置(x,y)处的像素值,R表示散焦模糊半径。
2.1.3 高斯模糊
对于每个像素,将其周围的像素按照高斯分布函数计算权重,然后将这些像素的值加权平均,得到一个新的像素值。这个过程在整幅图像上重复进行,从而得到一幅模糊的图像,这种模糊称为高斯模糊(Bar 等,2006;Chen 和Ma,2009;Wang 等,2010)。高斯模糊的点扩散函数表示为
式中,σ表示高斯模糊的标准差,也称为模糊半径,模糊半径越长,图像模糊程度越高。G(x,y)表示模糊核在位置(x,y)处的像素值。
2.2 图像质量评价
图像去模糊质量评价分为主观评价和客观评价两类(程茹秋 等,2022)。主观评价是指人们从感性认识的视觉和经验角度对图像质量进行主观判定。由于需要人为打分得到平均主观分数(mean opinion score,MOS)(Hoßfeld 等,2016)来评估图像质量,因而往往这种评价机制更加符合人眼视觉特性。但是主观打分容易受到主观影响,而且需要耗费大量的人力,成本高效率低。因此,大多图像质量评价以客观评价为主,再进一步划分为全参考(full-reference,FR)(Wang 等,2017)、半参考(reduced-reference,RR)(Liu等,2018)和无参考(no-reference,NR)(Mittal等,2012)图像质量评价。
2.2.1 全参考图像质量评价(FR-IQA)
FR-IQA 是基于原始图像和失真图像之间的差异来评估图像质量。广泛采用的评价指标包括均方误差(mean square error,MSE)(Haigh,1980)和峰值信噪比(peak signal to noise ratio,PSNR)(Huynh-Thu和Ghanbari,2008)。然而,这两种方法被认为与人类视觉系统(human visual system,HVS)不符。因此,先后提出了基于结构相似度(structual similarity,SSIM)(Wang等,2004)和基于HVS的评价方法。
SSIM通过比较原始图像X与复原图像Y之间的结构信息变化来衡量图像质量。然而,SSIM 在评估图像质量方面的效果并不理想,Chen 等人(2006)提出基于梯度的结构相似度(gradient-based structural similarity,GSSIM)方法,利用边缘信息作为重要的图像结构信息,并使用梯度代替结构相似度中的对比度和结构度量。因为图像模糊会减弱图像中包含的语义信息,为此Zhang 等人(2013)提出ESSIM(edge strength similarity-based image quality metric)方法,通过计算边缘强度相似性来衡量由语义感知导致的质量退化。
HVS 算法主要利用人眼的亮度适应性、边缘敏感性、多尺度和掩蔽效应等多种特性来衡量图像质量。Chandler 和Hemami(2007)提出基于小波的自然图像视觉信噪比方法,用于量化失真图像的视觉保真度。Larson 和Chandler(2010)认为用HVS 判断图像质量时采用单一的策略(如提取图像结构信息)往往是不够的,因此提倡HVS 使用多策略来衡量图像质量,对于高质量图像,采用局部亮度和对比度来感知失真;对于低质量图像,采用空间频率分量的局部统计变化来感知失真。Zhang 等人(2011)将相位一致性作为主要特征,图像梯度的幅度作为次要特征提出了基于HVS 底层特征的图像质量评价算法。
2.2.2 半参考图像质量评价(RR-IQA)
RR-IQA 一般基于图像的部分信息而非完整信息来进行质量评价。相比于FR-IQA,RR-IQA 具有灵活性、适用性强和传输数据量小等特点。RR-IQA的代表性工作是采用变换域方法进行质量评估(Wang 等,2006;Li 和Wang,2009)。Wang 等人(2006)提出一种基于小波变换域的自然图像统计模型。该模型使用小波系数对原始图像进行编码,并通过比较解码后的系数分布与原始图像系数分布的偏差来量化图像的质量。Li 和Wang(2009)将分裂归一化和小波变换结合,利用小波变换高斯混合模型计算图像的分裂归一化变换,在变换域提取特征进行质量评估。此外,另一类RR-IQA 方法采用稀疏表达进行质量评价(Liu 等,2018;Wan 等,2020)。Liu 等人(2018)利用稀疏表达分别预测参考图像和失真图像,然后通过预测误差熵之间的差值衡量图像质量。而Wan 等人(2020)提出使用稀疏表达和自然场景统计特性来模拟大脑视觉感知的RR-IQA。
2.2.3 无参考图像质量评价(NR-IQA)
FR-IQA 和RR-IQA 都需要借助原始清晰图像作为参考,并通过计算特征差异或统计度量来评估图像质量,但所得到的结果并不能很好地满足HVS。因此,NR-IQA 应运而生。NR-IQA 通过建立图像与主观质量评分之间的映射关系进行质量评价,从而更加符合人眼的主观性。在NR-IQA 模型中,当算法评价值与MOS 值越接近、相关性越强,说明评价越准确,反之亦然。
无参考方法中的自然场景统计(natural scene statistical,NSS)方法是指高质量图像的视觉特征(如亮度、梯度等)服从一定的分布规律,而不同类型或不同程度的失真会对这种分布产生影响(方玉明等,2021)。Moorthy 和Bovik(2011)以及Mittal 等人(2012)分别提出DIIVINE 和BRISQUE 方法。DIIVINE 使用两阶段框架,首先用提取的场景统计信息预测失真类型,然后利用预测结果评估图像质量。而BRISQUE 模型采用空间域中的NSS 模型提取图像特征进行图像质量评价。
尽管基于NSS 的方法对部分失真效果较好,但由于外界因素的复杂性,这些方法还不能有效应对各种失真。为此,Kang等人(2014)提出将CNN 应用到NR-IQA,利用CNN 网络架构对图像块进行特征提取,然后建模图像特征和评价分数之间的映射关系。Li 等人(2016)提出了端到端CNN 模型,直接以原始图像作为输入并输出图像质量分数。受无监督预训练方法启发,Madhusudana 等人(2022)将图像质量评价从一个回归问题转化为分类问题,设计了一种基于对比学习的IQA训练框架。使用失真类型和失真程度作为辅助任务,从未标记的数据集中学习特征,进行正确的归类。对辅助任务训练得到的模型进行图像评估,从而得到质量分数。
3 传统方法图像去模糊
如图1 所示,2017 年之前图像去模糊主要采用传统方法,下面从非盲去模糊和盲去模糊两个方面回顾经典工作。
3.1 非盲图像去模糊
传统的非盲图像去模糊算法主要关注如何在噪声干扰的情况下,能够有效地恢复出清晰图像(杨航,2022)。因此,非盲图像去模糊主要从以下两类方法进行考虑:先去噪后反卷积(Chen 等,2010;Danielyan 等,2012)和迭代求解模糊过程(Zoran 和Weiss,2011)。
3.1.1 先去噪后反卷积
在图像去模糊领域,早期的研究包括Wiener(1964)提出的自适应方差最小化滤波器,也称为维纳滤波。该方法通过信号和噪声的统计特性来计算滤波器的权重,然后将这些权重应用于原始信号以滤除噪声的干扰,再进行反卷积实现去模糊。Kalifa等人(2003)将小波技术融合到反卷积中,提出了一种能匹配卷积核频域性质的镜像小波,通过阈值收缩来达到抑制噪声的目的。由于非局部均值滤波具有较强的纹理保持和滤波能力,Chen 等人(2010)使用非局部均值滤波来减少彩色噪声,从而在去模糊过程中更好地捕捉了模糊图像中细腻的纹理信息。Danielyan 等人(2012)借鉴了三维图像块匹配滤波(block matching 3D filtering,BM3D)(Dabov 等,2007)的思想,将其应用于图像去模糊来滤除噪声。
3.1.2 迭代求解模糊过程
尽管滤除噪声有益于后续反卷积操作,但在没有足够先验信息的情况下可能会出现振铃效应(Mosleh 等,2018)或者噪声滤波不完全的问题。因此,许多学者从迭代优化的角度改善非盲图像恢复效果。Lucy(1974)基于贝叶斯理论提出了Richardson-Lucy 迭代算法,利用最大似然估计对模糊图像进行非线性迭代,不断优化去模糊图像结果。Yuan 等人(2008)提出了一种由粗到细的渐进式反卷积方法。通过在每个尺度上迭代应用双边正则化,可以恢复图像的细节和边缘,同时避免振铃效应。Krishnan 和Fergus(2009)通过迭代优化图像的稀疏表达来估计图像的梯度分布,从而达到去模糊的效果。
迭代方法在很大程度上受正则化项的选择影响,因此选择适当的正则化项可以更好地解决去模糊问题。Zoran和Weiss(2011)采用高斯混合模型对图像块进行建模,利用学习得到的图像特征作为正则项进行非盲去模糊。Kheradmand 和Milanfar(2014)提出一种基于核相似度的图像去模糊方法,通过估计相似度的权重来调整拉普拉斯正则化项和数据保真项组成的损失函数。Lanza 等人(2016)提出一种变分正则化模型,通过使用参数化正则化项来稀疏表达图像梯度值,以恢复因加性高斯噪声而损坏的图像。Khetkeeree 和Liangrocapart(2019)设计一种基于维纳滤波的正则项,减轻了对先验信息的依赖,提高了去模糊图像的质量。
3.2 盲图像去模糊
虽然非盲去模糊方法取得了一系列进展,但在实际场景中,图像的模糊核通常难以估计,因此这类方法对于解决实际图像去模糊问题存在一定局限性。传统的盲去模糊方法先通过模糊核估计,再转变为非盲图像去模糊问题。这两个过程也可以迭代进行,交替估计模糊核和清晰图像,直到优化到满意的结果为止。估计模糊核常见方法有基于图像边缘特征(Xu 和Jia,2010;Chen 等,2019)、最大后验概率(Shan 等,2008;Levin 等,2011)和图像稀疏表达(Xu等,2013)的方法。
3.2.1 基于图像边缘特征的方法
图像边缘特征是指图像中明显的亮度变化或颜色变化所形成的边界或轮廓。Joshi 等人(2008)用高斯边缘检测器检测到的边缘特征来预测模糊核。然而过度强调边缘并非总是有利于核估计,Xu和Jia(2010)引入了一个新的指标来衡量图像边缘在去模糊中的有用性,并基于该指标对边缘进行梯度选择,提高了模糊核估计的准确性。Yang和Ji(2019)从变分贝叶斯推理的角度重新解释了边缘选择的重要性,开发了一种内置自适应边缘选择的变分期望最大化算法,以去除图像模糊。Chen 等人(2019)则提出了一种基于局部最大梯度先验的盲去模糊框架,用图像的梯度信息来检测边缘,从而解决了图像模糊处理后,局部块最大梯度值减小的问题。
3.2.2 基于最大后验概率的方法
最大后验概率估计是一种基于贝叶斯统计思想的参数估计方法,通过最大化后验概率来选择参数值。它结合了观测数据和先验知识,提供了对未知量的估计。Fergus 等人(2006)提出了在已知观测图像情况下,最大化原始图像和模糊核的联合后验概率,实现同时进行模糊核估计和去模糊过程。Jia(2007)从物体边界透明度与图像运动模糊之间的关系出发,提出了用透明度信息求解MAP 问题来估计模糊核。Shan 等人(2008)则基于MAP 准则,对图像的平滑区域和纹理区域进行约束,通过引入逐块连接函数来解决图像梯度的长尾分布问题,并将连接函数与局部先验联合进行图像去模糊。而Cho 和Lee(2009)提出一种对模糊核进行MAP 估计,对模糊图像采用稀疏表达的方法来实现图像去模糊。Levin 等人(2011)在Fergus 等人(2006)的基础上,对MAP 算法进行优化,并结合变分正则化算法对模糊图像进行反卷积。
3.2.3 基于图像稀疏表达的方法
图像稀疏表达是通过选择适当的变换,将图像转换到一个稀疏表达的域中。通过稀疏表达,可以将图像的高频和低频部分有效地分离,并减少噪声和伪影的产生(Donoho,2006)。Krishnan 等人(2011)在图像的高频上进行核估计,因为他们发现图像的高频部分具有稀疏性,可以用来区分清晰和模糊图像。而Xu 等人(2013)提出一个可以用于均匀或非均匀模糊的统一去模糊框架,通过图像的高稀疏性来约束由损失函数组成的正则化项,从而实现了去模糊过程。谭海鹏等人(2015)对遥感图像进行去模糊研究,首先用滤波器进行预处理,再结合模糊核的稀疏特性,使用正则化求解模糊核。Pan 等人(2016)用数学方法证明模糊过程会增加暗通道像素的值,因此可以利用暗通道的稀疏性来进行盲去模糊。Yan 等人(2017)引入明通道的定义,并利用明暗通道各自的优点,更有效地去除图像模糊。
4 基于深度学习的图像去模糊
如图1 所示,2017 年之后图像去模糊主要采用深度学习方法,以下同样也从非盲去模糊和盲去模糊两方面进行综述。
4.1 非盲图像去模糊
如3.1 节所述,传统的非盲图像去模糊方法(Danielyan 等,2012;Khetkeeree 和Liangrocapart,2019)大多采用线性模型进行建模,不能很好地处理复杂先验分布下的图像非盲去模糊问题。与传统非盲去模糊方法不同,深度学习方法具有更强的非线性建模能力,能够提取更丰富的特征表示,从而提高去模糊效果。现有方法可以分为传统方法与深度学习相结合(Schuler 等,2013)和纯深度学习方法(Zhang等,2017;Eboli等,2020)。
4.1.1 传统方法与深度学习结合的方法
与深度学习结合的首要方式是正则化。Schmidt 等人(2013)通过分析半二次正则化(half quadratic regularization,HQR)和稀疏图像先验,推导出判别级联的回归树模型建模图像去模糊问题。Schuler 等人(2013)则提出采用傅里叶域的正则化方法来恢复清晰图像,并结合多层感知器去除伪影。Xie等人(2019)构建一个基于全变分的深度网络,该网络能够自适应学习正则化的最佳参数,从而实现更好的图像去模糊效果。
然而,选择合适的正则化项并非易事。因此,研究人员也尝试从其他的角度来解决图像非盲去模糊问题。Schmidt 和Roth(2014)将卷积层和傅里叶变换相结合,提出一种适用于图像恢复的新型随机场模型,提高了计算效率和图像恢复质量。Zhang 等人(2019b)设计一种深度图像超分辨率双立方退化模型(bicubic degradation model,BDM),通过可变分方法推导出即插即用算法,实现可以处理任意模糊核的模糊图像。基于MAP 框架非盲去模糊方法需要定义合适的数据和正则化项,但先前工作大多都集中推进两种关键成分之一。而Dong 等人(2021)提出在MAP 框架内联合学习空间变化数据和正则化项,预测每像素的空间变化特征,而不是常用的空间均匀特征,从而改善了图像细节的恢复。Dong 等人(2022)在多尺度级联特征细化模块中将维纳滤波和深层卷积特征相结合,端到端训练图像去模糊模型。
4.1.2 纯深度学习的方法
将传统方法和深度学习结合在一定程度上可以提升图像去模糊的性能,但这类方法一般需要人工的提取特征和预处理。为了缓解这种情况,Zhang等人(2017)直接采用CNN 模型进行端到端去模糊,取得了较好的效果。Vasu 等人(2018)利用深度CNN 去除核估计中存在的伪影,并增强图像细节,实现了非盲图像去模糊。受传统的从粗到细的方法启发,Zhou 等人(2020)采取多尺度策略对输入图像进行处理,将低级信息和高级语义信息集成,有效提取了图像特征,从而提高了图像去模糊性能。而Eboli 等人(2020)将模糊和清晰图像先验核的逆滤波器作为预训练条件,并将其嵌入到CNN 模型中来学习定点迭代算法中的参数,解决了图像去模糊过程中出现的最小二乘问题。Kim 等人(2022)采用多尺度失真先验模型,在恢复图像过程中利用参考模糊图像的空间信息去模糊。Quan 等人(2023)利用不同大小的散焦核之间的强相关性,提出一种处理散焦模糊的去模糊算法。
4.2 盲图像去模糊
近年来,基于深度学习的图像盲去模糊技术在计算机视觉领域得到了广泛的关注(Sun 等,2015;Zhang 等,2020a)。相比传统方法,基于深度学习的方法直接对模糊图像进行去模糊处理,无需对模糊程度进行估计。下面分别从CNN(Nah 等,2017;Cho等,2021)、RNN(Zhang 等,2018;Gao 等,2019)、GAN(Kupyn 等,2018)和Transformer(Wang 等,2022;Zamir 等,2022)等4 个方面对盲图像去模糊进行介绍。
4.2.1 基于卷积神经网络的方法
基于卷积神经网络的盲去模糊方法,通过多层卷积和池化操作,能够自动学习图像或模糊核的特征,生成清晰图像(Schuler 等,2016)。Sun 等人(2015)首次将CNN 引入到盲去模糊领域,采用CNN来预测图像块水平运动模糊核的概率分布。Schuler等人(2016)则利用由粗到细的建模思想,在CNN 中设计可学习层来提取局部图像特征进行核估计。然而,在未知的模糊核很大的情况下,上述方法表现并不理想。Chakrabarti(2016)采用多分辨率频率分解方法来编码输入块。他们通过频率的局部性调整初始网络层的连接方式,使得训练得到的网络能够估计较大的模糊核。Gong 等人(2017)利用图像上下文信息,训练了一个全卷积深度神经网络来直接估计模糊核的运动流。Xu 等人(2018)受到模糊图像边缘预测方法的启发,提出用CNN 模型对模糊图像提取主要结构信息,并对其进行增强处理,来估计模糊核。Nan 和Ji(2020)使用最小二乘估计器来优化模糊核估计中的误差问题,提高了模糊核估计的准确率。传统的基于MAP 方法对于先验知识的依赖性较强,不能很好表征出原始图像信息。为此,Ren等人(2020)将MAP 和深度模型结合,用具有跳跃连接的非对称自编码器网络生成潜在清晰图像,而用全连接网络生成模糊核。Tang 等人(2023)利用未经训练的深度神经网络来表达模糊核的残差,提出了一种无监督的半盲去模糊模型。Fang 等人(2023)提出一种基于隐空间先验非均匀模糊核估计方法,利用标准化流动模型将运动模糊核空间映射为高斯分布空间,在图像隐空间内估计模糊核。
上述方法主要通过模糊核估计再进行去模糊,而CNN 可通过大量的模糊图像和对应的清晰图像,学习到模糊图像和清晰图像之间的映射关系,从而避免了模糊核估计带来的误差。Nah 等人(2017)和Nimish等人(2017)采用端到端方式训练了一个深层的CNN 模型,可直接从模糊的输入中重建高质量的图像。Dong 等人(2019)利用自然图像的多尺度冗余特性,设计了一种基于CNN 模型的去噪器,去除图像模糊。通过在多个尺度上进行去模糊处理,可以更好地保留图像的细节和结构信息。针对此问题,Zhang等人(2019a)设计一个多尺度损失函数,并采用空间金字塔从粗到精地逐步恢复清晰图像。Cho 等人(2021)则重新审视从粗到细的结构,提出了多输入多输出网络(multi-input multi-output UNet,MIMO-UNet)。该网络利用单个编码器接受多尺度输入图像,并使用单个解码器输出不同比例的去模糊图像。通过引入非对称特征融合机制改进了去模糊效果。Zamir 等人(2021)采用编解码网络架构学习多尺度上下文信息,并利用解码端输出具有高分辨率的特点,恢复了更多图像细节信息,进一步提高了去模糊效果。
4.2.2 基于循环神经网络的方法
循环神经网络是一种能够处理序列数据的神经网络模型。在图像盲去模糊中,RNN 通过对区块特征信息进行递归循环操作,将之前区块的状态信息传递给当前区块,从而学习不同区块数据之间的关系,实现去模糊过程(Zhang 等,2018)。Zhang 等人(2018)利用RNN 的空间可变性隐式模拟去模糊过程,RNN 模型在时间和空间维度上进行循环计算,逐步恢复图像的细节和结构。Tao 等人(2018)提出多尺度循环去模糊网络,在不同尺度上共享网络权重,显著降低了训练复杂度。同时,通过循环模块的状态传递从而获得各尺度上的有用信息,有助于图像恢复。Gao 等人(2019)关注到图像特征的尺度变化特性,在Tao 等人(2018)的基础上提出参数选择性共享方法来恢复图像细节。因为多尺度提取图像特征参数量较大,Park 等人(2020)采用多时态代替多尺度的方法,通过将图像分成多个小块模糊块,逐步处理原始尺度中这些模糊块来进行图像去模糊,从而减少了模型参数量。而Zhang 等人(2020b)则提出一种两阶段混合去模糊网络,用于去除真实的运动模糊。在第1 阶段,使用循环编解码网络来生成循环事件。在第2 阶段,将模糊图像与此循环事件连接起来作为输入,从精到粗的逐步恢复模糊图像。
4.2.3 基于生成对抗网络的方法
生成对抗网络是一种由两个神经网络组成的框架,包括生成器网络和判别器网络。在图像去模糊任务中,生成器网络将模糊图像作为输入,清晰图像作为输出。判别器网络则用来判断生成器网络输出的图像是否与真实图像一致。整个训练过程通过生成器网络和判别器网络相互对抗来优化模型参数(Kupyn等,2018)。Kupyn等人(2018)设计了一种基于生成对抗网络的单尺度去模糊网络Deblur-GAN。其中生成器网络采用残差模块和卷积网络进行去模糊,而判别器网络则采用马尔可夫判别器进行鉴别生成图像。然而,该方法可能会出现梯度消失或爆炸的情况。Kupyn 等人(2019)提出了DeblurGANv2,将特征金字塔引入到生成器网络,而判别器网络采用可以评估图像全局和局部特征的相对论判别器,从而避免了梯度消失或爆炸的问题。Lu 等人(2020)所采用的生成器网络包含两个编码器,其中内容编码器提取清晰和模糊图像的内容特征,而模糊编码器提取模糊信息。通过对抗性损失和周期一致性损失作为正则化器,来帮助生成器网络产生清晰图像。Zhang 等人(2020a)结合了两种GAN 模型,即模糊GAN 和去模糊GAN,旨在减少真实模糊和合成模糊之间的差异。他们通过学习图像模糊过程来实现图像去模糊。Yang 等人(2021)利用深度神经网络的深层和浅层特征来生成GAN 的潜空间映射特征和噪声,以恢复模糊图像的全局结构和局部细节。大多数现有方法都是直接端到端生成清晰图像,并没有进行模糊核估计。而Li 等人(2021)训练了一个模糊核判别器网络,用于分析生成的模糊核图像,并检测生成器提供不正确模糊核时可能出现的错误情况。
4.2.4 基于Transformer的方法
Transformer 模型是一种基于自注意力机制和前馈神经网络的神经网络架构。自注意力机制有助于模型在处理序列时学习到不同位置之间的依赖关系,而前馈神经网络结构能够有效地捕捉到局部信息和非线性关系(Liu 等,2021)。Zamir 等人(2022)提出了Restormer 模型,将Transformer 应用到图像去模糊任务。他们通过编解码网络实现对图像多尺度的局部和全局特征学习,更高效地处理图像的去模糊问题。Wang 等人(2022)认为全局自注意力机制会增加计算复杂度,因此提出了局部增强窗口(locally-enhanced window,LeWin)Transformer 模块,更好地捕获局部上下文。同时,将LeWin 模块应用在图像多尺度恢复框架中,利用获得的全局和局部信息来进行图像恢复。Kong 等人(2023)利用频率前馈网络来确定保留图像中低频还是高频部分,从而解决了Transformer中使用前馈网络去模糊效果不佳的问题。Yan 等人(2023)提出Sharpformer 模型,通过Transformer模块直接学习图像全局特征和自适应局部特征,实现去除运动模糊。因为卷积操作有利于提取局部信息,而自注意力机制更侧重于提取全局信息。因此Zhao(2023)设计并行的CNN 和Transformer 网络架构,同时提取全局和局部图像特征进行图像去模糊。
5 图像去模糊的数据集和性能评估
5.1 数据集
图像去模糊算法使用的数据集主要分为合成数据集和真实数据集。合成数据集是通过人工定义的模糊过程来生成模糊图像(Levin 等,2009;Nah 等,2017)。模糊过程可以是模糊核与清晰图像进行卷积或者其他模糊方式。这些数据集通常可以提供模糊图像和对应的清晰图像对,方便用于训练和评估算法的性能。而真实数据集包含真实世界中的模糊图像(Rim 等,2020;Jiang 等,2020)。这些图像通常是由于相机晃动、手持拍摄或其他因素导致的模糊图像。这些数据集能够更好地模拟实际场景中的图像模糊情况,对算法的鲁棒性提出更高的要求。表1详细列出了图像去模糊数据集的信息。
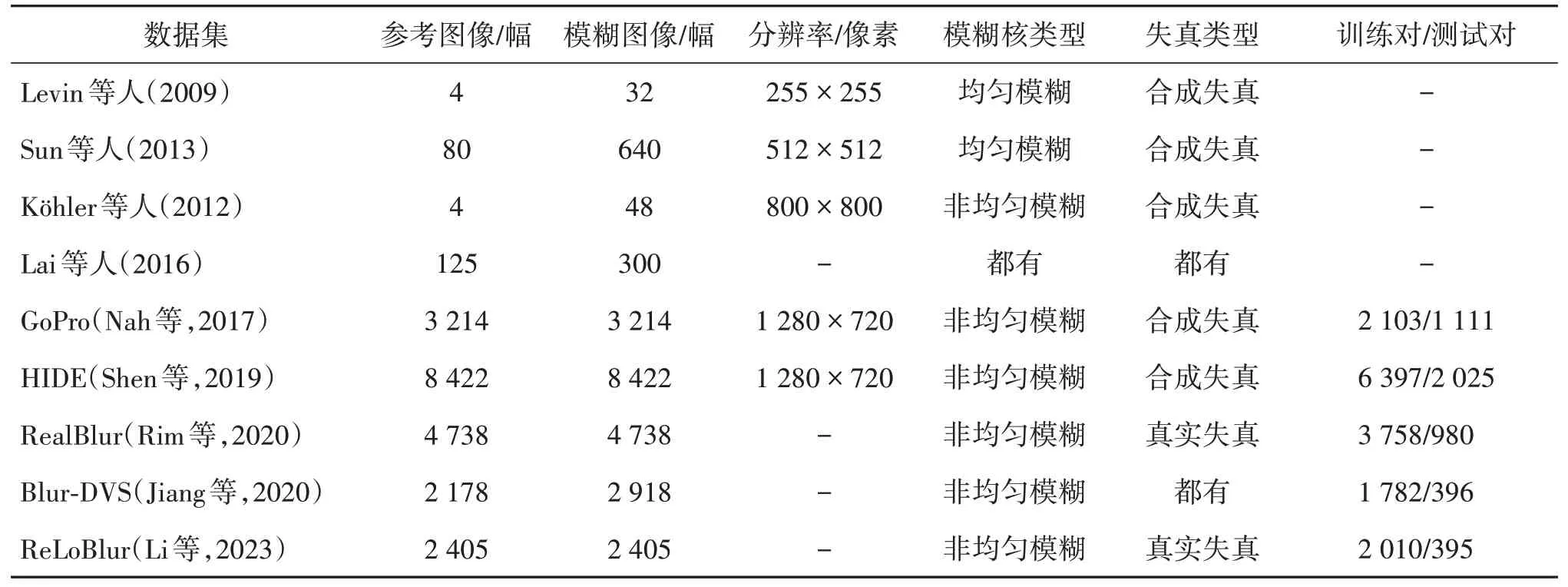
表1 图像去模糊数据集Table 1 Image deblurring datasets
5.1.1 合成数据集
较早提出的合成数据集主要采用清晰图像与模糊核卷积的方法生成模糊图像。Levin 等人(2009)使用4 幅 255×255 像素的清晰图像和8 个均匀模糊核进行卷积,构建一个包含32 幅模糊图像的数据集。但是Levin 等人(2009)的测试图像分辨率固定在 255×255 像素,且由于图像数据较少而缺乏多样性。Sun 等人(2013)通过将Sun 和Hays(2012)的80 幅高质量自然图像和Levin 等人(2009)的8 个均匀模糊核进行卷积,最终生成640 幅模糊图像。然而,上述数据集都假设模糊核为均匀模糊,因此在该数据集上训练得到的去模糊模型难以有效解决非均匀模糊核的去模糊问题。为了模拟非均匀模糊效果,Köhler 等人(2012)记录了6D 相机随时间的变化轨迹,并通过在机器人平台上重新播放相机的运动来生成模糊图像。他们使用4幅清晰图像和12幅摄像机运动轨迹图像进行合成,构建了一个包含48 幅非均匀模糊图像的数据集。Lai 等人(2016)提供两个大型数据集。其中一个数据集是在不同场景下拍摄的100 幅真实模糊图像;另外一个数据集则包含了200 幅合成的模糊图像,其中包括非均匀模糊图像和均匀模糊图像。
为了生成更真实的模糊图像,Nah 等人(2017)使用高速摄像头GOPRO 来快速拍摄一系列清晰图像,通过对这些间隔时间极短的图像进行求平均的方式来得到模糊图像,最终得到GoPro 数据集。该数据集包含2 103 对训练图像和1 111 对测试图像。Shen 等人(2019)建立一个运动模糊数据集HIDE(human-aware motion deblurring)。该数据集通过平均视频中的11 个连续帧来合成模糊图像,并将中心帧作为清晰图像。HIDE 数据集包含8 422 幅图像对,分为6 397对训练图像和2 025对测试图像。
5.1.2 真实数据集
上述数据集的图像主要通过人工合成而形成的模糊图像,对于去模糊模型在实际生活中的应用存在一定的局限性。Rim等人(2020)提出一个真实世界模糊图像数据集RealBlur。该数据集由两个子集组成,一个子集是RealBlur-R,它由相机原始图像组成;另一个子集是RealBlur-J,它由相机处理后的JPEG 图像组成。该数据集共包含9 476 对图像。Jiang 等人(2020)使用DAVIS240C 相机捕获一个大型户外数据集Blur-DVS,包含1 782 对训练图像和396 对测试图像,同时还提供740 幅真实的模糊图像。另外,Li 等人(2023)创建一个真实世界局部运动模糊数据集ReLoBlur(real-world local motion deblurring),该数据集真实地展示了局部运动物体自身和背景产生的混叠效应,其中包含2 010对训练图像和395对测试图像。
5.2 定量评估
为了更准确地评估和分析图像去模糊任务中具有代表性的算法模型的性能,采用了第2.2.1 节中所介绍的PSNR 和SSIM 两个评价指标进行衡量。PSNR 通过计算原始图像与重建图像之间的均方差来衡量图像之间的差异。而SSIM 通过加权平均图像的亮度、对比度和结构相似度来衡量图像之间的相似性。
PSNR 越高,表示去模糊图像的质量越好。SSIM的取值范围为0到1之间,越接近1表示图像结构相似度越高,重建图像质量越好。通过综合考虑PSNR 和SSIM 这两个评价指标,能够全面评估图像的清晰度、细节保留能力和对比度等方面的表现。表2和表3中的实验结果是从调研的论文中获取。
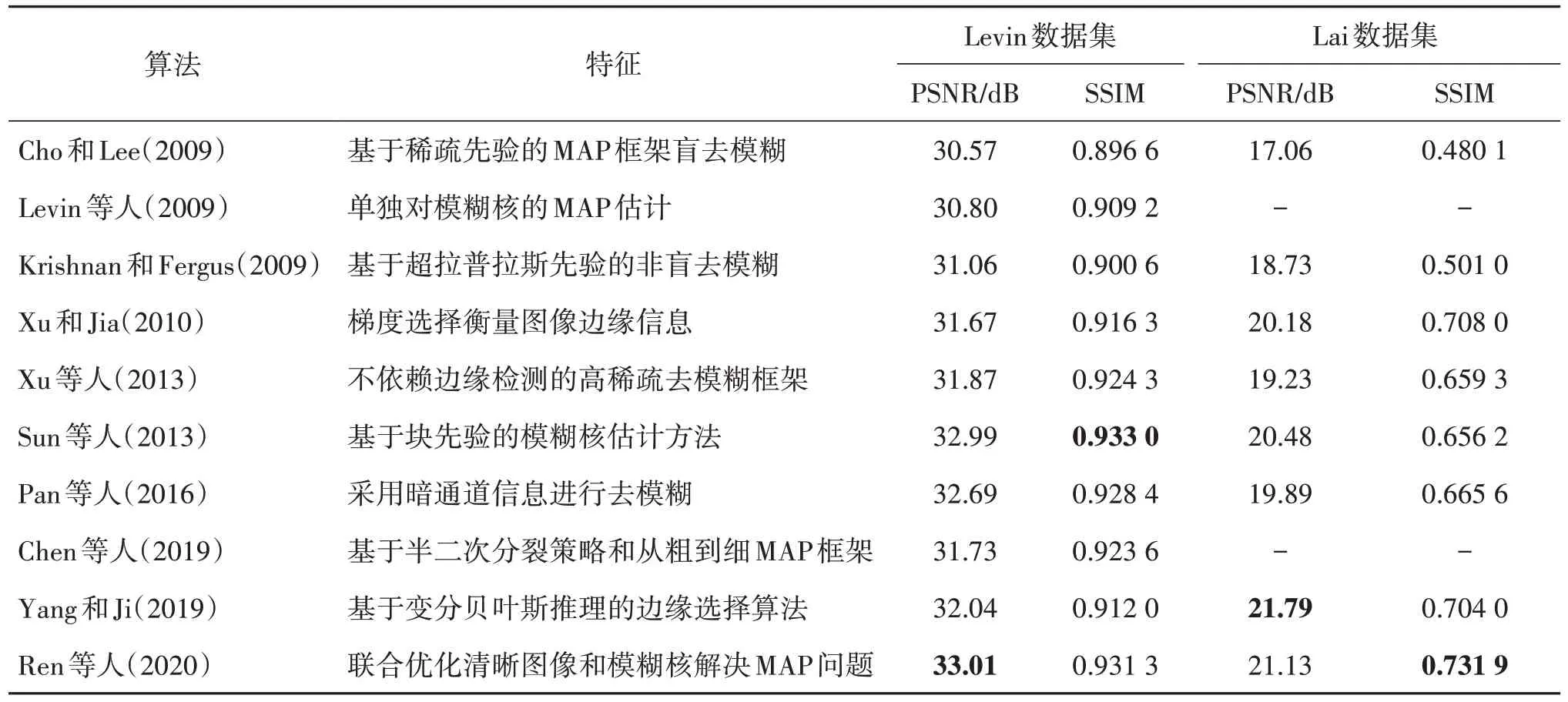
表2 传统图像去模糊方法在Levin和Lai数据集上的性能Table 2 Performance of traditional image deblurring methods on Levin and Lai datasets

表3 基于深度学习图像去模糊方法在GoPro和HIDE数据集上的性能Table 3 Performance of some deep learning-based image deblurring methods on GoPro and HIDE datasets
5.2.1 传统图像去模糊算法性能分析
由于传统的图像非盲去模糊大多针对单个标准图像进行定性分析,而不是在数据集上进行定量分析。实验主要在早期被广泛认同的Levin 数据集(Levin 等,2009)和Lai 数据集(Lai 等,2016)上开展。Levin 数据集是一个模糊核为均匀模糊的合成数据集,而Lai数据集则包含真实图像和合成图像两种类型的数据集,实验结果如表2所示。
从表2 可以看出,非盲去模糊算法(Krishnan和Fergus,2009)在PSNR 和SSIM 值上高于传统盲去模糊算法(Cho 和Lee,2009;Levin 等,2009)。这是因为非盲去模糊假设模糊核已知,而盲去模糊需要对模糊核进行估计。一旦对模糊核估计不准确,将导致最终去模糊效果较差。为改善此问题,研究人员发现图像边缘信息有利于模糊核估计。Xu 和Jia(2010)提出对图像边缘信息进行梯度选择,提高了模糊核估计准确性。在两个数据集上都取得明显的性能提升,表明边缘特征提取有益于图像去模糊。基于边缘特征提取的一系列改进算法(Sun 等,2013;Yang 和Ji,2019),从表2 中可以看出,其性能均有不同程度的提升。其中Sun 等人(2013)的方法在Levin 数据集上达到了传统方法的最优效果。
基于MAP 的方法(Chen 等,2019;Ren 等,2020)通过最大化原始图像和模糊核的联合后验概率,对模糊图像进行估计。两个算法在Levin 数据集上的PSNR 和SSIM 与Sun 等人(2013)方法不相上下,但在Lai数据集上明显优于Sun等人(2013)方法。
基于图像稀疏表达的方法(Xu等,2013;Pan 等,2016)将图像的高频和低频部分分离,可以有效地减少噪声和伪影的产生。虽然其性能指标略差于Sun等人(2013)方法,但比之前的方法有一定程度的提升。
因为Levin 数据集中的模糊图像都是经过均匀模糊处理后的合成图像,而Lai数据集则包含真实图像和合成图像。因此,在表2 的实验结果中可以看出,所有方法在Levin 数据集上的表现优于在Lai 数据集上的表现。尽管在Levin 数据集上能够呈现较好的实验效果,但实际情况下,图像模糊往往是非均匀的,因此模型的实用性存在一定局限性。此外,现有传统方法大多主要针对特定失真,无法解决Lai数据集中的多种失真情况,这导致模型的泛化能力受到限制。
5.2.2 基于深度学习的图像去模糊算法性能分析
基于深度学习的方法通常需要数据集具有多样性,以确保模型能够处理各种不同的模糊情况,并展现出更好的泛化能力。实验主要在合成数据集GoPro 数据集(Nah 等,2017)、HIDE 数据集(Shen 等,2019)以及真实数据集RealBlur 数据集(Rim 等,2020)上开展。GoPro 数据集和HIDE 数据集是常见的图像去模糊合成数据集,它们通过平均视频中连续帧来合成模糊。RealBlur 数据集包含由相机原始图像组成RealBlur-R 和相机处理后的JPEG 图像组成RealBlur-J。实验结果如表3所示。
Sun 等人(2015)较早将CNN 应用在图像去模糊领域。尽管其在GoPro 和HIDE 数据上的效果并不突出,但展现了深度学习在图像去模糊领域的巨大潜力。后续研究中,DeepDeblur和DMPHN对骨干网络进行改进。与Sun 等人(2015)方法相比,它们在合成数据集上的PSNR 和SSIM 都取得了显著提升,尤其是DMPHN 在HIDE 数据集上显示出较好的性能。随着深度学习快速发展,端到端的去模糊方法MPRNet(multi-stage progressive image restoration network)和MIMO-Unet 在合成数据集上表现出色,其PSNR 超过了30 dB。此外,在真实数据集RealBlur上也展现出令人满意的效果。
从表3 可以看出,基于RNN 的SRN 和DSD(dynamic scene deblurring)方法相比同一时段提出的方法,在合成模糊和真实模糊上都表现出非常好的性能,其PSNR和SSIM指标都高于其他方法。
基于GAN 设计的DeblurGan 方法虽然在合成数据集上的性能指标略逊于DeepDeblur,但在Real-Blur 数据集上表现更优。而且其改进算法DeblurGan-v2和DBGAN(DeBlur GAN)的性能在2个合成数据集上的PSNR 和SSIM 与基于RNN 的方法不相上下,但在RealBlur数据集上表现欠缺。
Transformer 模型能够建立全局依赖关系,并有效地捕捉到整个图像的上下文信息。因此,近期提出的Restormer、FSAS(frequency-domain-based selfattention solver)和CTMS 等算法都是基于Transformer 模型。在GoPro 数据集上,它们的PSNR 和SSIM指标都分别达到了32 dB和0.96,在HIDE数据集上,也远超其他算法。即便在真实数据集Real-Blur 上,也表现出优秀的实验效果,进一步展现了Transformer模型在图像去模糊领域具有巨大潜力。
5.3 定性评估
图3 和图4 分别展示了传统方法和基于深度学习方法在图像去模糊任务上的可视化结果,并选择了两个代表性的场景以展示不同去模糊算法之间的差异。

图3 传统方法定性比较结果(Yang和Ji,2019)Fig.3 Qualitative comparisons of traditional methods(Yang and Ji,2019)((a)blurred images;(b)Cho and Lee(2009);(c)Xu and Jia(2010);(d)Xu et al.(2013);(e)Yang and Ji(2019))

图4 深度学习方法定性比较结果(Zhao等,2023)Fig.4 Qualitative comparisons of deep learning methods(Zhao et al.,2023)((a)blurred images;(b)reference images;(c)DeepDeblur;(d)SRN;(e)DBGAN;(f)MPRNet;(g)CTMS)
图3 展示了传统图像去模糊方法的可视化结果(Yang 和Ji,2019)。尽管各个算法采用了不同的方法,但在图像去模糊上均呈现出令人满意的效果。其中,基于图像边缘特征去除图像模糊的方法(Xu和Jia,2010;Yang 和Ji,2019)更注重保留图像的纹理细节;基于最大后验概率的方法(Cho 和Lee,2009)通过引入正则化项成功地避免了图像过度锐化和噪声放大等问题;而基于图像稀疏表达的方法(Xu 等,2013)能有效地分离图像的高频和低频部分,从而减少了噪声和伪影的产生。
基于深度学习的图像去模糊方法可视化结果如图4 所示(Zhao 等,2023)。通过对比以下几种不同的方法:基于CNN 的Deepdeblur(Nah 等,2017)和MPRNet(Zamir等,2021)方法,基于RNN的SRN(Tao等,2018)方法,基于GAN 的DBGAN(Zhang 等,2020a)方法和基于Transformer 的CTMS(Zhao 等,2023)方法,可以观察到,不仅模型架构不同对去模糊结果会产生影响,即使采用相似网络结构的方法,如Deepdeblur 和MPRNet,也会产生不同的结果。值得特别关注的是,基于Transformer 的CTMS 方法在图像去模糊的效果上表现最为出色。
5.4 运行效率
在基于深度学习的图像去模糊算法中,通常选取平均运行时间和模型参数量作为衡量模型效率的重要指标(Cho 等,2021)。选取了不同网络架构中具有代表性的算法,并统计它们在GoPro 数据集测试集上完成图像去模糊所需的平均运行时间和模型参数量,结果如表4 所示。结果表明,大部分算法的平均运行时间都在1 s内,但部分模型的参数量相对较大。因此,选择算法时需要综合考虑这两个指标,以确保模型在实际应用中能够取得良好的性能表现并满足资源消耗的限制。但是如何平衡平均运行时间和模型参数量仍需要进一步的研究和探索,以提高图像去模糊算法的效率和性能。
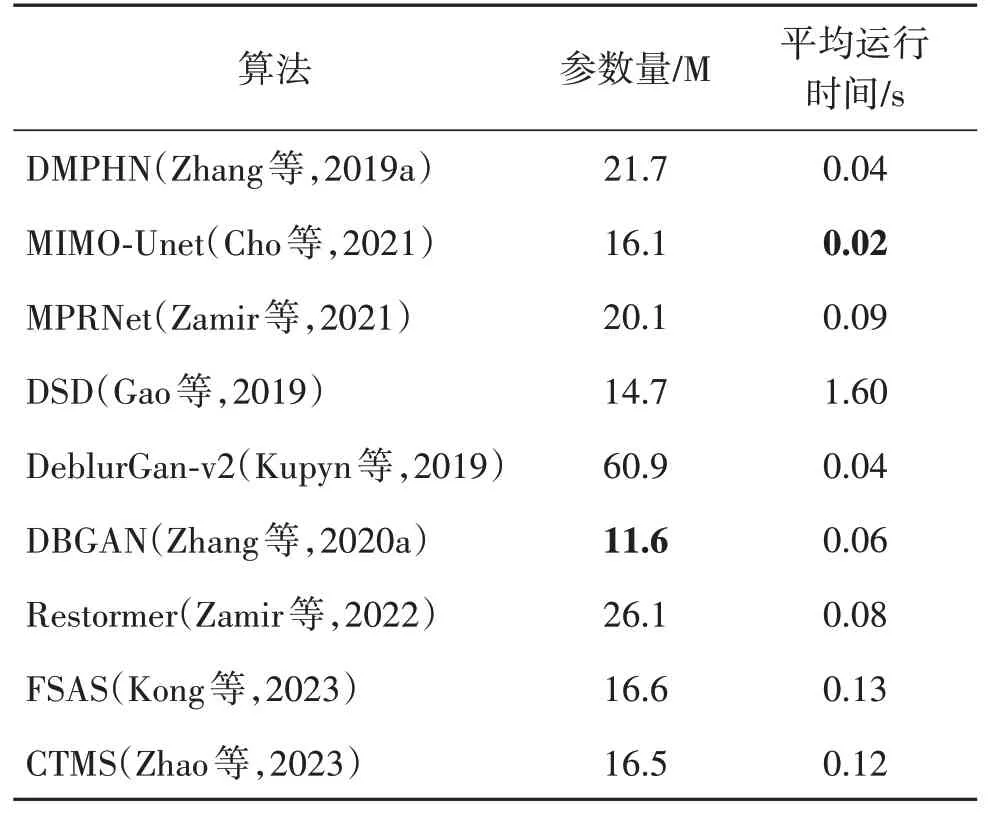
表4 不同算法的运行效率Table 4 Running efficiency of representative methods
6 结语
传统的图像去模糊方法从去噪、迭代优化、图像边缘信息和稀疏表达等方面展开研究,提出了许多优秀的算法。然而,这些传统方法需要人工选择特征,并且大多针对某种情况下的模糊,因此其泛化能力受到一定限制。而随着深度学习技术的不断进步,基于深度学习的各类图像去模糊算法不断涌现,不仅在性能上逐渐超越了传统方法,而且能够更好地适应各种模糊环境。
尽管深度学习方法在图像去模糊领域取得了巨大进展,但仍存在一些严峻挑战和难题:
1)全面的评估指标。目前在图像去模糊领域中最广泛使用的评价指标是PSNR 和SSIM。PNSR 仅衡量恢复图像和原始图像之间的均方误差,无法反映图像细节和清晰度等方面的质量。同时,PSNR对于人眼感知不敏感,可能导致PSNR 高但视觉效果差的情况。而SSIM 虽然可以反映图像的结构信息和视觉质量,但对于图像亮度和对比度的变化并不敏感。因此,在评估模型时,需要考虑基于人眼视觉特性的感知质量评价指标。然而,这需要大量的主观评价数据和人力资源,并且还会受评价者个体差异影响。因此,要获得与人眼视觉特性相一致的评价指标仍面临挑战。
2)模型的泛化性和数据集。在图像去模糊领域,模型需要具备处理各种复杂模糊情况的能力,包括散焦模糊、高斯模糊和运动模糊等。但是,由于这些模糊成因的复杂性,训练出能够应对所有情况的模型是一项具有挑战性的任务。同时,去模糊数据集通常需要大量的真实图像和对应的模糊图像,以便训练出能够对各种不同模糊情况进行处理的模型。但是,由于获取真实图像和对应的模糊图像需要大量的时间和人力成本。因此,构建大量高质量的数据集也是一项重要且具有挑战性的任务。
3)模型的效率问题。由于现在移动拍摄设备捕获的图像具有超高分辨率,但很多图像去模糊模型在处理高分辨率图像时表现不佳或者需要长时间的计算,使得在实际应用中带来了困扰。尽管基于深度学习的图像去模糊方法相对传统方法有更好的性能,但也伴随着参数量大的问题。因此,如何开发出高效的轻量化去模糊算法还需要付出大量的努力。
图像去模糊技术至今仍面临众多挑战,需要不断研究与改进,从而提升其质量和应用领域的广度。同时,综合考虑评估指标、模型的泛化能力、数据的多样性和数量等因素,能更好地在实际中应用图像去模糊技术。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
电视技术(2014年19期)2014-03-11
