
对象驱动的Linux内核crash分类技术研究
2024-04-22 02:30:42何林浩王允超郭志民
小型微型计算机系统 2024年4期
何林浩,魏 强,王允超,郭志民
1(信息工程大学 数学工程与先进计算国家重点实验室,郑州 450001) 2(国网河南省电力公司 电力科学研究院,郑州 450052)
0 引 言
内核是操作系统中最重要的软件组件,其安全性决定了整个操作系统和用户应用程序的安全性.由于内核程序的特权级别高,内核程序中的漏洞危害通常要比用户程序中的漏洞危害更为严重,所以内核一直是被攻击的目标,比较经典的例子有DirtyCow(脏牛漏洞)[1]、蓝牙出血漏洞[2]以及脏管道漏洞[3]等.为了主动检测和修复这些漏洞,安全社区不仅开发模糊测试工具来挖掘深层次的漏洞,同时组织安全分析人员和内核开发人员对报告的漏洞进行及时的修复.
前20年,内核漏洞挖掘的速度一直很慢.直到2016年前后谷歌发布了Syzkaller和Syzbot开源项目[4],内核漏洞挖掘的速度开始急剧增长.Syzbot是一个以Syzkaller为模糊测试引擎的持续化模糊测试平台.该平台持续地、自动化地模糊测试主要的 Linux 内核分支来发现 bug.Syzbot可以生成标准的崩溃报告和结构化信息字段,便于安全分析人员重现 bug 并分析根本原因.截至2022年9月,该系统发现了4980个内核 bug,超过了syzkaller出现之前20年所发现的内核bug总和.虽然 Syzbot的持续化模糊测试极大地提高了内核 bug发现的效率,但它也产生了大量的崩溃报告.自项目发布之日起,Syzbot已经产生了超过1000万个崩溃报告,其中绝大多数是由相同的错误触发的.安全分析人员需要手动分析这些报告来评估错误的严重性并查明根本原因,所以把由同一错误引起的崩溃报告分组会极大的减少修复人员的手工分析以及提高漏洞修复的效率.当 Syzbot 报告崩溃时,它会自动生成一个由崩溃函数和崩溃类型组成的错误标题.例如,标题“KASAN:slab-out-of-bounds Read in sctp_inq_pop”表示崩溃发生在“sctp_inq_pop”函数上,崩溃类型为“KASAN:slab-out-of-bounds Read”.持续化模糊测试会不断触发同一个错误,产生很多重复的crash.目前,Syzbot 使用一种简单的启发式方法进行crash分类:如果crash共享相同的崩溃函数和崩溃类型,那就将它们分组到相同的错误标题下.如图1所示,crash1-N共享相同的错误标题B.

图1 crash组、错误标题和crash之间的关系Fig.1 Relationship between crash groups,bug title and bug reports

图2 整体流程图Fig.2 Overall process
但是,这种基于启发式的crash分类方法并不准确.通过调研发现,在 Syzbot dashboard(错误报告平台)上由同一个根本原因引起的一些crash并没有被分组在一起(因为它们具有不同的崩溃功能或崩溃类型).如图1所示,错误标题A、B和C归属于同一个根本原因,但现有的方法并不能将其分到同一个crash组.这将导致同一个根本原因的不同crash被当作新的bug被分配给不同的安全分析人员.一方面,多组分析人员并行处理同一个bug缺乏互相交流会导致漏洞修复效率低下.另一方面,对同一个bug的错误行为的有限了解可能会导致补丁的不完整.据统计[5],2017年9月~2020年11月Syzbot上报告了2526个内核crash组和超过324万个崩溃报告,但根据它们的根本原因,实际可以分成1686个不同的内核crash组.在2526个内核crash组中,有840个(33.2%)crash组为冗余分组.慕冬亮等人[5]针对crash大量重复的问题选取了一部分bug进行实证研究,获得了Linux内核错误行为表现多样的原因,并提出了对应的消除重复策略,但仅仅通过提取PoC系统调用进行相似对比难以结合程序运行上下文进行分析,分类结果仍然存在假阳性的问题.所以,现有的Linux内核crash分类方法粒度较粗,在准确性上存在较大的问题,难以实现对漏洞的可利用性评估.
本文针对上述存在的问题,基于对Linux内核源码的基本了解和内核错误的基本观察,提出了一种对象驱动的Linux内核crash分类方法.基于Linux内核源码存在大量结构体来实现各种系统功能的基本事实,以及Linux内核错误大多与结构体成员变量的错误使用有关的基本观察,本文提取与错误相关的内核对象近似代替根本原因指导crash的分类.首先,本文通过后向污点分析技术提取错误相关内核对象,根据内核对象之间的调用关系进一步构造调用依赖图,度量内核对象与根本原因的相关性.最后,将内核crash与内核对象的关系抽象为二部图,通过比较提取出的内核对象的相似性来确定crash的相似性.本文以Syzbot dashboard平台报告的crash为数据集来评估crash分类方法的有效性.相较于之前的方法,分类的准确性有较大提升,自动化的分类方法显著提高了对漏洞的可利用性评估,节省了安全分析人员的手动分析时间.
1 相关工作
持续化模糊测试平台的出现,如谷歌的OSS Fuzz和微软的模糊测试服务,证明了自动化漏洞挖掘工具的有效性.准确的crash分类对于持续化模糊测试平台来说至关重要:
1)减少耗时的手动调试工作
2)描述自动化漏洞挖掘工具的有效性
3)对有趣的崩溃测试用例进行排序
然而,有效部署自动模糊测试技术的一个突出挑战是在crash分类过程中准确识别独特的缺陷.模糊测试工具通常会生成数千个崩溃输入,最终对应于同一个bug.crash的巨大数量使手工检查很困难,这是一个难题,同时也是一个研究的热点领域.
模糊测试工具,例如SmartFuzz[6]、Vuzzr[7]、FuzzSim[8]和Syzkaller[4]等,使用调用堆栈上的函数名、行号和文件名生成堆栈散列的方法进行crash分类.王晓鹏等人[9]通过计算重复数据的堆栈编辑距离和TF-IDF来进行错误报告分类.基于AFL的模糊测试工具考虑执行路径中的基本块转换.AURORA[10]、kAFL[11]等根据边覆盖的相似性来确定crash的唯一性.但是,Klees等人的研究[12]表明这种方法会产生过多的假阳性和假阴性.Pham等人[13]使用一种依赖于作为路径约束的输入的语义特征的聚类算法,特别适用于符号执行工具.但是此方法仅对bug本身的语义属性敏感,不能根据路径约束来分类crash.Chen等人[14]提出一种机器学习方法,对模糊测试工具输出的有趣测试用例进行排序,并使用补丁作为基础事实,将crash输入映射到独特的错误.Ton Der等人[15]使用补丁模板和来自程序的语义反馈来自动生成和应用错误的近似修复,从而代替补丁来精确地识别属于同一个根本原因的crash.慕冬亮等人[5]针对Linux内核crash提出了分类策略,但仍存在假阳性的情况.
2 设计原理与方法概述
与上述的分类方法不同,仅是利用现有的错误信息,如堆栈跟踪等可以保证分类的快速和高效,但并不能保证分类的准确性,本文的方法追求更加准确的分类.借鉴TonDer等人研究[15]的思想,追求一种近似修复来代替根本原因指导正确分类.本文则试图寻找另一种近似代替根本原因指导分类的方法,此方法基于一个基本事实:根本原因与内核对象之间存在映射关系.
根本原因是指导致二进制可执行文件崩溃的根源,通常不是崩溃点的位置,可能在更加前面的地方.内核对象是指Linux内核开发人员实现大量的设计模式以及抽象设备和功能的结构体.根本原因与内核对象存在的映射关系可从以下两个角度看出.
1)从操作系统源码的角度来看
由于结构体“高内聚、低耦合”的特性以及较快的内存访问速度,Linux操作系统的作者Linus及后续开发人员在实现操作系统时,大量地使用了结构体来存储信息以及实现对各种设备的抽象.所以从操作系统源码层次来看,内核中的错误必然会涉及到结构体,二者之间存在一定的映射关系.
2)从具体内核错误的角度来看
基于对很多Linux内核错误的观察,可以发现:一个内核错误的根本原因通常是由两种行为造成的.一种是对内核对象的不适当使用导致了内核错误,例如CVE-2022-0847脏管道漏洞(Dirty Pipe),该漏洞为变量未初始化漏洞.漏洞成因为 copy_page_to_iter_pipe()和 push_pipe()函数对pipe_buffer 结构的成员变量flag的不当使用(未初始化使用).由于没有清除 PIPE_BUF_FLAG_CAN_MERGE 属性,导致后续进行 pipe_write()时误以为write操作可合并,从而将非法数据写入了文件页面缓存,导致任意文件覆盖漏洞.另一种是由于内核对象计算错误,该值进一步传播到一个关键的内核操作,导致内核发生错误.例如CVE-2022-0185 File System Context 整数溢出漏洞,由syzkaller发现,可以实现提权和容器逃逸.其漏洞成因为ctx结构的成员变量ctx->data_size计算错误整数溢出进而导致堆溢出.
基于以上两点观察,可以发现内核错误根本原因与内核对象之间存在一定的映射关系,一个内核错误关联至少一个内核对象的不当使用或错误计算.林等人的研究[16]证明了错误相关的内核对象可能不止一个,与根本原因不表现出一一映射的关系.如图3所示,同一个根本原因的crash关联到一个内核对象的集合.林等人的研究[16]采用了提取内核对象的方法,旨在缩小根本原因相关的内核对象集合,寻找根本原因最相关的内核对象,从而指导内核模糊测试工具远离与错误无关的路径.但本文的目的在于尽可能挖掘与根本原因相关的所有内核对象,从而更准确的实现分类.

图3 根本原因与内核对象关系图Fig.3 Relationship between root cause and kernel object
为了实现上述想法,本文将技术方法设计为一个静态分析提取结构体和二部图结构建模对比crash相似性的过程.如图2所示,首先,本文将内核错误报告以及相应内核源码作为输入,执行后向污点分析提取内核错误中涉及到的所有内核对象.其次,根据内核对象与根本原因之间的映射关系,内核对象集合近似等价于根本原因,具有相同内核对象集合的crash应该为同一个根本原因.所以本文将crash的相似性对比问题转化为内核对象的相似性对比.但是仅比较内核对象集合成员之间的相似性缺少相关性度量(不同的内核对象与根本原因的的相关性程度不同),所以本文分析得到的所有内核结构体之间的调用关系,构造内核对象调用依赖图,以pagerank算法计算内核对象的被调用程度,以此作为内核结构与根本原因的相关性的度量.最后,本文将crash与内核对象之间的引用关系以及相关度抽象为一个二部图结构,并通过二部图相似性比较算法实现最终的分类.在下一节,本文将详细阐述这些技术细节.
3 技术细节
本节将详细阐述内核对象驱动的crash分类方法的技术细节.首先,本节将详细描述如何分析内核错误报告并提取错误相关的结构体.其次,本节描述如何对提取出的结构体应用pagerank算法进行相关度排序.最后,本节描述如何将crash的相似性转化为引用结构体的相似性比较并构建二部图模型进行分类.
3.1 提取内核对象
本文使用了后向污点分析技术来提取错误报告中涉及到的内核对象,下面详细说明如何编译Linux内核源码进行静态分析以及如何定义source点、sink点和污点传播的规则.
3.1.1 Linux内核源码编译
从9.0版本开始,LLVM支持对Linux内核的编译.LLVM 提供了完整的代码静态分析框架,包括编译器、中间语言表示和大量的静态分析和转换程序.为了防止编译优化对之后的静态分析造成影响,本文使用 LLVM 编译器框架提供的 Clang 编译器编译 Linux 内核源码为 Bitcode[17](字节码)形式的 IR(Intermediate Representation,中间表示).LLVM 的 IR 被设计用于编译器优化,即代码的静态分析和转换.LLVM采用静态单赋值(SSA,Static Single Assignment)形式表示代码中的变量,保留了变量的类型信息.这个特性使得自动静态分析变得更为简单.本文延续了之前工作的方法[16],对LLVM编译器clang进行补丁,以便输出编译优化之前的 Bitcode文件.另外,在编译内核时开启了KASAN选项,便于下一步source点规则的定义.同时,编译的Linux内核版本与错误报告对应的内核版本保持一致.
3.1.2 source点规则定义
本文使用Linux内核自带的错误检查机制定位错误变量从而确定source点.Linux 内核具有以不同方式实现的错误检查功能(例如,BUG、WARN 和 KASAN),其中大多数遵循相同的实现模式.即在内核执行期间执行检查,判断是否满足预定义的条件.如果条件不成立,那么内核将进入错误状态,并记录可能用于调试的关键信息.在记录了关键信息之后,内核可能会采取进一步的措施使自己死机或终止当前进程.这些调试特性可以分为两类,一类为在内核源码中开发者预先定义的宏,一类为编译器或者硬件完成的KASAN等错误检查机制,所以本文对source点的选取主要以这两类错误检查为依据.
1)宏定义检查
如表1所示,选取了CVE-2019-25045的错误报告进行分析.在第6行,内核检查&net->xfrm.state_all变量,如果不为空,则内核程序继续执行第7行,完成对sz的赋值操作.如果为空值,内核程序进入预先定义的WARN_ON宏中执行代码并记录错误行为.此例中,当且仅当!list_empty(&net->xfrm.state_all)为真时,内核程序进入错误状态,所以&net->xfrm.state_all变量为后向污点分析的起点.
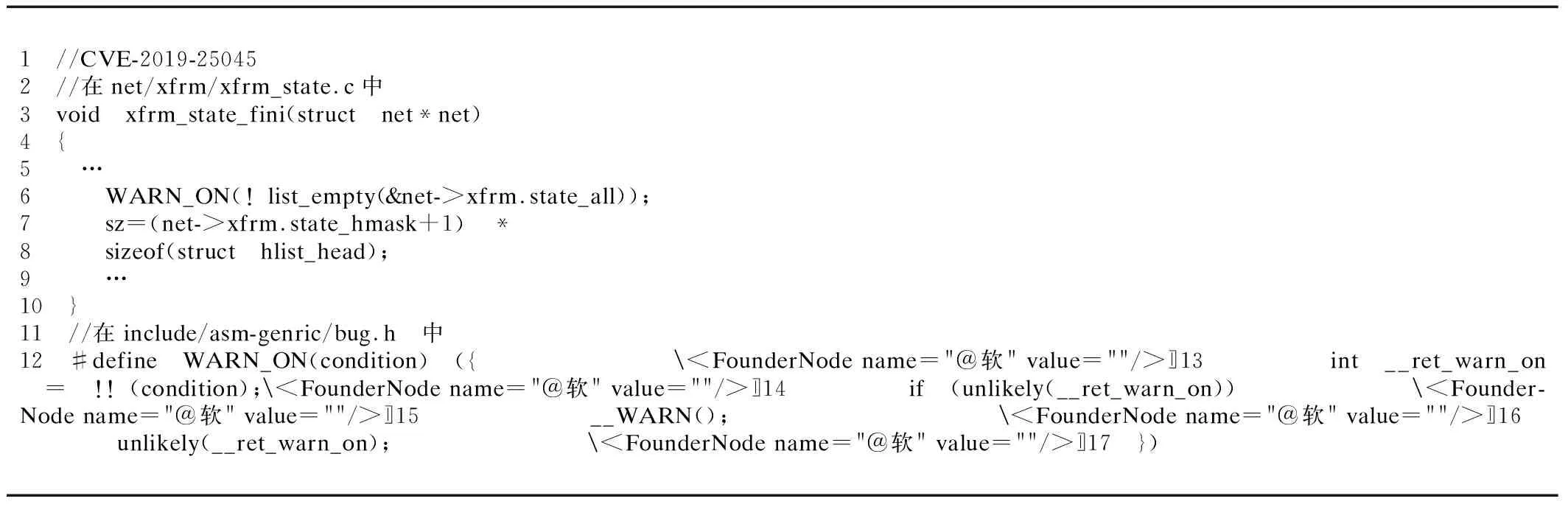
表1 宏定义错误检查Table 1 Macro definition error checking
2)KASAN检查
KASAN检测每个存储器的访问,以便内核可以检查对存储器地址的访问是否合法,KASAN 依赖影子内存来记录内存状态.例如,如果被检测的内核接触到被释放的内存区域,KASAN将生成一个错误报告,指出触发释放后使用错误的指令.从这些KASAN调试机制生成的错误报告中可以很容易地识别出执行无效内存访问的指令.本文在这些信息的基础上,进一步识别与无效内存访问相关的变量.由于报告中包含的二进制指令不包含类型信息,不便于定位污点变量,为了解决这个问题,本文从调试信息中将二进制指令与它们在源代码中对应的语句进行映射.如果映射的源代码只有一个加载或存储的简单语句,可以直接得出结论,该语句是导致非法内存访问的语句,并将操作数变量视为污染源.但如果所识别的指令涉及多个存储器加载和存储的复合语句,例如表2所示,data.pscan_rep_mode=info-> pscan_rep_mode语句同时涉及到了对一个变量的加载和对另一个变量的存储.本文检查错误报告并查明捕获内核错误的具体指令,然后将与错误捕获指令相关联的内存访问视为污点源.错误报告指出错误是由info->pscan_rep_mode关联的指令kasan_check_read(&info->bdaddr,sizeof(var))得到的,所以将变量info->pscan_rep_mode视为source点.

表2 KASAN错误检查Table 2 KASAN error checking
3.1.3 污点传播规则及sink点规则定义
错误报告中还包含了调用跟踪,本文以此为基础,构造错误的控制流图,在图上向后传播污点.在污点传播的过程中,本文进行了指针分析,以便将污点传播到变量的别名上.
1)污点传播规则
随着污点向后传播,本文使用以下策略来执行变量污染.如果被污染的变量是嵌套结构或联合变量的字段,那就进一步污染其父结构变量,并将父结构视为关键结构,这是由于嵌套结构或联合变量是内存中父结构变量的一部分.如果嵌套结构或联合变量的字段带有无效值,这可能是由于其父结构变量的使用不当造成的.
当后向污点传播遇到循环时,如果污点源在循环内被更新,污点也将被传播到循环计数器.这是由于存在这样一种情况,一些越界访问错误,其中循环计数器被破坏、意外扩大,并最终被用作到达无效内存区域的偏移量.通过将污点扩展到循环变量,可以找到损坏的变量,有助于进一步识别与损坏相关的其他结构变量.
2)Sink点定义
首先,如果污点传播到已污染过的变量就停止污点分析.其次,如果污点传播到系统调用的入口、中断处理程序或者或启动工作队列调度程序的函数的入口,这代表已经传播到这段内核程序的起始位置,也可以中止污点分析.本文将保存所有污点分析得到的结构体作为下一步进行内核crash分类的依据.
3.2 相关性计算
设计原理中已经提到,本文将crash与内核对象的关系建模为一个二部图.通过分析具体的内核错误得知,不同的内核对象与crash的关联程度也不同.所以构造的二部图的边需要赋予不同的权重,从而更准确的挖掘crash与内核对象的相关性.通过对内核错误的观察发现,越是常用的结构体与crash的相关性越低,越是不太常用的结构体相关性越高.所以本文通过构造一个内核对象引用关系图,进而应用pagerank算法计算内核对象节点所占的权重作为相关性的度量.
本节构建了描述内核结构之间的引用关系的图.图中的每个节点代表一个内核结构,节点之间的有向边表示引用关系.首先,本文分析内核源代码中定义的所有结构.给定一个结构,本文检查它的所有成员变量.如果变量是指向另一个结构的指针,那么将给定的结构链接到被引用的结构.如果成员变量是嵌套结构体或共用体,那将不断进入下一层进行识别,直到定义中不再有嵌套结构体或共用体.将给定的结构直接链接到最后一层结构体,忽略中间的过程以缩小图的大小.例如表3所示的cred结构体,user是一个结构体user_struct的指针,本文将cred与user_struct链接起来.本文进一步识别共用体中的成员变量,rcu是一个结构体rcu_head的指针,那将cred直接关联到rcu_head.

表3 Cred结构体定义Table 3 Cred structure definition
除了分析内核源码中的结构体定义,本文还考虑了类型转换问题.由于内核支持使用单一接口来描述不同设备和特性的多态,可以将一种抽象数据类型转换为更具体的类型.因此,本文对此类类型转换进行识别,对转换前后涉及到的结构体进行链接,进一步完善结构体调用依赖图.
在调用图的基础上,应用PageRank算法进行计算各个结构体的使用程度.基于对内核错误的观察,使用程度高的结构体与根本原因的相关性越小.所以进一步对得到的pr值进行处理,定义相关度为cor=1/pr,计算并保存结构体对应的相关度数据.
3.3 内核crash分类
设计原理中已经提到,将crash相似性对比转化为引用对象的相似性对比.针对此问题,本文将crash与内核对象的引用关系建模为一个二部图.然后,基于此二部图进行相似度的计算.
3.3.1 Crash与内核对象引用关系建模
二部图又称作二分图,是图论中的一种特殊模型.设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二部图.本文构造crash与内核对象引用关系图G={C,O,E,W},图中的节点可以分为两个集合,一个是crash集合C={c1,c2,…,cm},一个是内核对象集合O={o1,o2,…,om}.集合E表示边的集合,由3.1提取出的引用关系所决定.矩阵W表示边的权重,由3.2节得到的相关度决定.则二部图的邻接矩阵定义为:
(1)
3.3.2 分类算法
至此,本文将crash的相似性比较转化为相关内核对象的比较.SimRank是一种基于图的拓扑结构信息来衡量任意两个对象间相似程度的模型.算法的核心思想为:如果两个对象和被其相似的对象所引用(即它们有相似的入邻边结构),那么这两个对象也相似.因此,使用此算法可以比较内核对象的相似性确定crash的相似性从而实现分类.I(cp)表示所有指向节点cp的节点集合(即入邻点集合),I(cq)用表示所有指向节点cq的节点集合,用s(cp,cq)表示两个内核crash的相似度,则数学定义式表达如下:
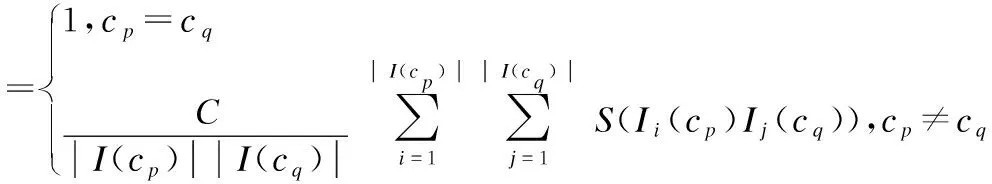
(2)
其中,C是一个阻尼系数(decay factor),通常取0.6~0.8.
算法1.crash分类算法
输入:crash和内核对象带权二部图,C:阻尼系数,k:迭代次数,V:证据矩阵,T:相似性阈值
输出:S:节点相似度矩阵,List:相似对列表,S1,…,Sn:相似的crash集合
1.S=In//计算相似度矩阵
2.For i=1:k,do
3.Temp=C PW SW //PW是转移概率矩阵W的转置矩阵
4.S=temp + In-Diag(diag(temp))
5.End
6.S=S×V
7.List={}
8.For sijin S do //筛选出相似度矩阵中的相似集合
9. If sij>T then
10. List=List + {(I,j)}
11.End
12.Union-Find(List) //并查集算法
13.End
14.Return S,List,S1,…,Sn
但是,由于相关程度的不同,朴素simrank算法由于没有考虑边的权重,并不能很好的实现分类.另外,关系越简单(相连边少)的节点更容易与其他节点相似,关系越复杂(相连边多)的节点更难与其他节点相似,朴素SimRank缺乏考虑节点的共同相邻点集的大小.本文进一步引入更加适合的simrank++算法,加入节点相似度证据和边的权重以度量相关程度.
对于节点cp和cq,相似度证据可以表示为:
(3)
带证据的相似度公式为:
Sevidence(cp,cq)=evidence(cp,cq)·s(cp,cq)
(4)
将相似度比较定义为运算⊕,若cp和cq相似,则cp⊕cq.⊕运算满足传递性,若cp⊕cr,则cq⊕cr,由此可以将相似性集合进一步合并.基于以上推导,crash分类算法具体实现如算法1所示,以构建的内核crash和内核对象的二分图以及simrank++算法相关的参数作为输入,输出相似的crash集合.首先使用simrank++算法计算出相似度矩阵,如算法1~6行所示.然后筛选出相似的crash集合,如算法7~11行所示.最后使用并查集算法合并具有相同元素的集合,如算法第12~14行所示.
4 评 估
本节首先介绍实验的配置以及数据集的选取等,然后介绍本文所采取的基线和评估指标.最后,本文进行对比实验验证方法的有效性,进行消融实验验证各个组件的作用,在未修复的错误上应用本文的分类方法验证可用性.
4.1 实验设计
数据集和评估指标:首先,本文从syzbot平台的已修复部分随机选取了10组重复的crash,组内crash数量从2~9个不等,共45个重复的crash.另外,随机选取了55个不存在重复的crash.总体来说,本文选取了100个crash.考虑到现有方法的输入是成对的crash作为输入的,所以本文将所选取的数据集分成104个重复对和4882个非重复对.评估指标设置为成功分类的重复crash和真实的重复crash的比率,即真阳性(TP),以及错误分类为非重复crash和真实非重复crash的比率,即假阳性(FP).
另外,除了与现有的方法对比分类的准确性之外,本文还从促进可利用性评估的角度进一步评估分类结果的有效性.如表4所示,本文根据crash的错误标题所表现出的危害性将可利用性分为3个等级.

表4 可利用性等级Table 4 Availability level
配置:本文进行实验所用的操作系统系统为 Ubuntu-18.04 LTS,服务器配置为256GB内存和英特尔至强6248 20核CPU@2.50GHz×2.
4.2 有效性验证
为了验证本文分类方法的有效性,选取了当前两种最先进的分类方法进行对比,均优于现有的方法.第1个方法为clusterfuzz使用的栈相似性对比算法[18],第2个方法为慕冬亮等人[5]使用的分类算法,这两种分法以成对的crash作为输入.分类效果如表5所示,本文提出的方法可以对104个重复crash对中的88个crash对成功进行分类,真阳性率为84.6%,高于前两种方法的49.0%和79.8%.并且,本文提出的方法在所使用的数据集中并没有产生误报,不会产生假阳性,证明了此算法的有效性和可靠性.相比于栈相似性对比算法仅对比调用栈信息,无法深入程序的执行路径.本文提出的算法执行后向污点分析,提取相关的内核对象更为接近程序崩溃的根本原因,更能指导crash的正确分类.相比于慕冬亮等人[5]提取的PoC中系统调用相似性对比方法需要crash提供PoC的局限性,本文的方法不需要PoC作为输入,仅需要错误报告作为输入,可以对一部分缺少PoC只有错误报告的crash对正确进行分类,例如表6中的crash实例68258ee和5b88fac.
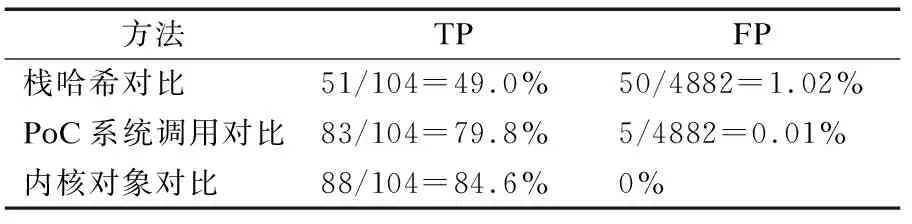
表5 分类效果Table 5 Classifying quality

表6 Crash实例分析表Table 6 Crash case analysis
此外,本文的分类结果不仅以重复对的形式展现,而且可以将重复的对合并分组,可以更好的体现分类的意义.如图4所示,本文所用的方法可以将9个分组分类成功,将100个crash分类为69个独特的crash组,极大的缩小了独特crash的数量,减少了分析人员的手工劳动,并且对同一个错误的不同崩溃路径的分析更有助于分析人员确定根本原因和确定其可利用性等级,以便对漏洞进行更全面的修复.例如表6中的crash实例68258ee和5b88fac,根据表5中展示的可利用性等级为低可利用性和高可利用性.通过分组,可以将此crash定义为高可利用性的crash组,从而提高修复的优先级.例如表6中的crash实例e4be308、84a6b6d、4fbc4bf、37e6f6b、129e6b9b,分析人员可以更加全面的掌握触发错误的不同路径,以便对漏洞进行全面的补丁修复.
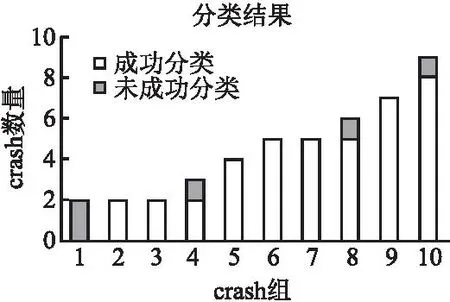
图4 分类结果Fig.4 Classification results
4.3 组件有效性验证
为了证明组件之间的有效性和必要性,本文进行了消融实验.实验设计为朴素分类法(不加入相关性度量和证据的算法)和加入相关性度量及证据的算法.
实验结果如图5所示,可以看出朴素分类算法分类准确率下降明显.分析其原因,例如表6中crash实例e4be308、84a6b6d、4fbc4bf、37e6f6b、129e6b9b、68258ee和5b88fac15等类型的crash对,使用朴素分类算法依然可以正确分类.但对于表6中的crash实例df62b81和146653c,由于内核对象权重一致,朴素分类法不能排除ipvhdr、inet_sock和rtable等无关内核对象的影响,而加入相关性度量和证据可以将和等关键内核对象的权重提高,更适应多内核对象的分类情况从而实现正确分类.

图5 组件效果对比Fig.5 Component effect comparison
4.4 未修复错误可用性验证
上述实验证实了本文方法的有效性,接下来将本文的方法应用于现实世界中的未修复错误,以检测之前未知的重复.本文对syzbot平台的未修复错误进行了分类,发现了8组重复的crash,包含25个错误标题,这些错误标题在正确的分类指导下可以成功合并到相同分组,以减少分析人员的手工劳动从而更快的确定的修复错误.其中一组例子展示在表6中,通过本文的方法将00b1cbe、d4ba8fd和aa3cd47正确分类后,分析人员将对此错误有一个更全面的认识.本文将所有检测出的错误分类标题提交给了项目开发者,得到了开发者的积极响应.
5 总 结
本文发现Linux内核crash存在大量重复,这可能会导致内核错误修复的延迟.为此,本文提出了一种内核驱动的Linux内核crash分类方法.通过实验结果分析,本文的方法优于现有的分类方法,且对真实世界的错误分类也有很好的效果.这项工作促进了漏洞的可利用性评估,未来将结合机器学习的方法进一步优化本文的算法,以更好的适应数量巨大crash的分类.
猜你喜欢
现代装饰(2022年4期)2022-08-31 01:41:24
网络安全与数据管理(2022年2期)2022-05-23 13:25:36
中国药学药品知识仓库(2022年7期)2022-05-10 12:26:14
今日农业(2021年9期)2021-07-28 07:08:36
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
山西省政法管理干部学院学报(2015年2期)2015-07-31 18:10:46
实用中西医结合临床(2015年7期)2015-02-28 16:30:41
江苏卫生事业管理(2014年3期)2014-02-28 02:00:02
