
改进YOLOv5s的铁路异物入侵检测算法
2024-04-22 02:30:40孟彩霞王兆楠高宇飞
小型微型计算机系统 2024年4期
孟彩霞,王兆楠,石 磊,高宇飞,卫 琳
1(郑州大学 计算机与人工智能学院,郑州 450001) 2(郑州大学 网络空间安全学院,郑州 450002) 3(铁道警察学院 图像与网络侦查系,郑州 450053)
0 引 言
铁路是国家经济大动脉、国家重要基础设施和大众运输工具,铁路沿线的安全环境直接关系到铁路运输的安全和顺畅运行.随着铁路的快速发展,铁路覆盖地形不断增加,形成了复杂的列车运行环境,列车运行速度的不断提高使得制动距离越来越大,铁路沿线行人非法进入、机动车越过道口等异物的入侵会对列车安全行驶造成严重威胁.随着铁路交通行业对列车的行驶安全要求逐渐的提高,对异物的入侵检测一直是研究人员的研究重点[1],有效的入侵检测方法对铁路运营的安全具有重要意义.
目前铁路入侵检测主要有接触式检测和非接触式检测两类方法[2].接触式检测需要大量硬件的支持,安装麻烦,不适合大规模使用,并且当设备检测到异物入侵时不能进行及时的处置,会严重影响列车的正常行驶.计算机视觉是一种有效的非接触式入侵检测方法,广泛应用于铁路环境,具有易于维护和结果直观的优点,但铁路环境的复杂多变性以及恶劣天气的干扰会导致误报问题.随着深度学习算法的发展,可以一定程度上实现高检测精度和低误报率,然而深度学习算法速度慢,占用内存大,需要高性能计算机的支持.铁路上的摄像头很多,但铁路入侵现象比较稀少,大量使用高性能计算机并不经济.在复杂的铁路场景中需要一种高效的铁路入侵检测方法.
为了解决这些问题,本文提出了一种基于改进YOLOv5s算法的铁路异物入侵检测方法,称为SD-YOLO,可以有效地检测复杂铁路场景中的异物入侵.该方法准确率高、误报率低、速度快.本文的主要贡献如下:
1)提出一种Spartial空间注意力与SENet通道注意力串联的SSA混合注意力机制.有效提高局部表征能力,融合了多感受野,信息更加丰富,使特征覆盖到待识别物体的更多部位,更好地拟合相关特征信息,增强对小目标的关注程度,提高模型对小目标识别的效果;
2)提出一种DW-Decoupled Head解耦检测头,采用混合通道策略来构建更高效的解耦头部.相比较于非解耦的端到端方式,DW-Decoupled Head解耦检测能加快网络收敛速度,降低了计算成本,实现更快的推理速度;
3)引入一种更平衡的回归损失函数SIoU,考虑真实框与预测检测框之间不匹配的方向,加快模型收敛速度;另外使用转置卷积作为采样方法,采样更适合铁路轨道侵限障碍物特征的尺寸和比例;
4)提出RS铁路入侵异物数据集.目前没有公开的铁路入侵异物数据集,因此本文提出并公开RS铁路入侵异物数据集,选择行人、汽车、自行车作为主要异物进行研究实验.
1 相关工作
入侵检测是铁路安全的一个活跃研究课题.目前对列车异物侵入的检测方法分为两类:接触型和非接触型.其中,接触型主要采用传感技术,通过设置传感器来判定异物是否侵入,此类方法实现了物理防护,但易受到外部环境的干扰、安装成本高.
基于卷积神经网络的目标检测算法是一种有效的非接触式入侵检测方法,广泛应用于铁路环境,分为单阶段算法和双阶段算法[3].常见的单阶段算法包括YOLO系列[4-6]、SSD[7]、RetinaNet[8]等等.One-stage算法将定位和分类视为一个回归问题,实现了端到端的检测,检测速度较快,但其基于Anchor机制的方法会生成大量矩形候选框,而且检测到目标的候选框数量较少,造成了候选框冗余现象,降低了算法检测性能.常见的双阶段算法包括 R-CNN[9]、Fast R-CNN[10]、Faster R-CNN[11]等等.双阶段算法首先筛选出所有正样本,生成感兴趣区域(Region of Interest,ROI),然后在第2阶段对前一阶段生成的感兴趣区域进行区域分类和位置细化,进而调整边界框.整个过程需要进行重复检测、分类和位置细化,导致检测速度较慢,但检测精度较高.
传统的卷积神经网络的目标检测算法在实际应用中参数量较大,运行速度慢.目前有很多学者采用深度学习的方法对铁路异物入侵检测进行了研究.He和Ren等人[12]提出了一种基于改进R-CNN的列车障碍物检测方法,通过在 R-CNN 的架构中引入新的上采样并行结构和上下文提取模块,达到了90.6%的精度;He等人[13]使用改进Mask R-CNN轨道交通障碍物检测方法,提出新的特征提取网络并综合多种多尺度增强方法,提高小目标物体的检测能力.以上这些方法都是基于双阶段检测方法,增加感受野,结合浅层特征与深层特征进行多尺度特征融合的方式,提高了目标检测的能力,但Region Proposal网络存在无法实时检测的问题.张等人[14]提出一种基于YOLOv3网络改进的高铁异物入侵的检测算法,该算法通过改进FPN结构,增强提取特征的能力,减少了目标检测的误报,但FPS较低,满足不了实时检测的要求;文献[15]提出一种基于YOLOv3的轻量级自适应多尺度特征融合对象检测网络,采取轻量级特征提取模块和增强自适应特征融合模块,提高了复杂环境下的目标检测性能,尤其是对小物体具有较高的检测精度,但这项工作基于YOLOv3网络结构进行,目前有性能更好、速度更快、被工业界广泛使用的YOLOv5算法,可以基于YOLOv5网络结构继续研究,不断得到最适合复杂环境下的铁路入侵检测算法,提升检测性能.
为满足铁路异物入侵检测实时性与准确性的需求,本文以同时具有良好的准确性和实时性的YOLOv5作为基本网络,提出一种基于 YOLOv5s 网络改进的铁路异物入侵检测方法.YOLOv5网络模型分为输入端,Backbone骨干网络,Neck特征融合和检测输出端.输入端采用Mosaic数据增强方法,随机选取4张图片进行裁剪,然后拼接成一张指定分辨率的图像;Backbone骨干网络采用跨阶段局部网络(Cross Stage Partial Network,CSPNet)[16]架构网络进行特征提取,显著减少参数和计算量,并提升速度;Neck特征融合部分采用特征金字塔网络和路径聚合网络(Path Aggregation Network,PANet)[17],将主干网络提取到的深层特征上采样,与浅层信息逐元素地相加,构建尺寸不同的特征金字塔结构,获取到丰富的特征信息;YOLO检测头部分的3个检测层分别负责预测大目标、中目标和小目标,检测结果包括目标的定位信息、对象信息和类别信息.本文针对YOLOv5网络架构的输出特征方式、上采样方式、边框回归损失函数等进行改进,提升算法对远且小的入侵异物的特征提取能力,进一步降低铁路侵限检测的误报率和漏检率.
2 SD-YOLO算法
SD-YOLO算法在YOLOv5s网络基础上通过加入一种通道注意力与空间注意力串联的SSA混合注意力机制,提取全局上下文信息来增强对小目标特征的挖掘,从而提高对图像中小目标的识别;加入更加高效的DW-Decoupled Head解耦检测头来提取有用的位置信息,采用混合通道策略来构建更高效的解耦头部,加快网络收敛速度;加入更平衡的边界框回归损失函数SIoU,考虑真实框与预测检测框之间不匹配的方向,加快模型收敛速度;另外使用转置卷积作为采样方法,采样更适合铁路入侵异物特征的尺寸和比例.SD-YOLO算法模型如图1所示.
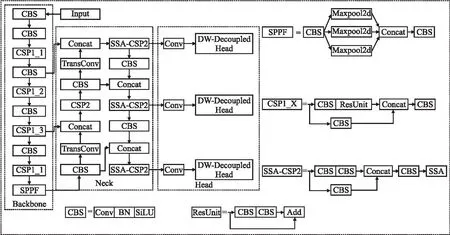
图1 SD-YOLO算法模型Fig.1 SD-YOLO algorithm model
2.1 SSA混合注意力机制
在YOLOv5特征融合路径聚合网络中,卷积层的通道数多达上百层,会导致重要特征不明显.为了兼顾网络模型的轻量化、模型精度问题以及小目标的误检、漏检问题,本文提出了SSA混合注意力模块.在YOLOv5模型的Neck网络中加入SSA混合注意力,通过学习不同通道的重要性、目标的空间位置信息与类别信息,为特征图的通道、空间位置添加权重信息,使特征覆盖到待识别物体的更多部位,增强对小目标的关注程度,提高小目标的识别效果.混合注意力模块可分为两个部分,空间注意力模块(Spartial Attention Module,SAM)与通道注意力模块(Squeeze-and-Excitation Networks,SENet)[18],分别在特征图的空间维度与通道维度实现注意力机制.本文所使用的SSA混合注意力模块如图2所示,其中SAM与SENet模块如图2(a)、图2(b)所示.

图2 SSA混合注意力模块Fig.2 SSA hybrid attention module
其中,Ftr表示卷积操作,Fex表示激励映射,Ssq表示压缩映射,Fscale表示通过乘法逐通道加权到先前的特征上.
如图2(a)所示,卷积层输出的结果先通过SAM空间注意力模块,首先在对特征图进行最大池化和平均池化操作,将C×W×H的特征图压缩成1×W×H的信息,然后通过带有注意力权重的卷积来提取注意力信息,最后把得到的空间注意力矩阵对应相乘原特征图得到新的特征图.
如图2(b)所示,得到空间注意力加权结果之后,再经过一个SENet通道注意力模块,输入一个特征通道数为C的特征图,通过一系列卷积变换后得到一个特征通道数为C′的特征,最终进行加权得到最终提取的特征信息.卷积变换依次为Squeeze 操作、Excitation 操作、Reweight 操作.首先将特征图沿通道维度划分为若干个区域,然后通过卷积压缩和激励分配通道权重,可以显式地建模特征通道间的相关性最后以残差的形式输出聚合特征.区域划分的目的是综合利用特征图的区域信息为通道分配权重.
如图2(c)所示,SSA混合注意力由通道注意力与空间注意力串联组成,使全局信息充分发挥作用,更好的拟合相关特征信息,提高模型对小目标识别的效果.
2.2 DW-Decoupled Head解耦头
在铁路复杂背景和多类别目标的干扰下,目标的识别任务更具有挑战性.互相遮挡的目标需要精确的定位信息来确定各自的位置.为了提高定位和分类的精确度,本文提出DW-Decoupled Head解耦检测头对目标进行预测,为定位与分类任务解耦出单独的特征通道,用于边界框坐标回归和对象分类.
如图3所示,DW-Decoupled Head解耦检测头对输入特征图使用1×1卷积降低通道维数,以减少参数量的产生.然后特征图输出分为两条支路,一条支路负责分类任务,通过3×3的Depthwise Convolution提取特征,再使用1×1的卷积将特征图的通道维数调整至预测目标的类别数量,在该特征图上完成分类任务;另一条支路负责定位任务,使用3×3 Depthwise Convolution提取特征,提取特征后将特征图分为两个,一个预测边界框的中心坐标以及框的高度和宽度,另一个则获取目标的置信度分数判断该点真实目标框与预测框的交并比.
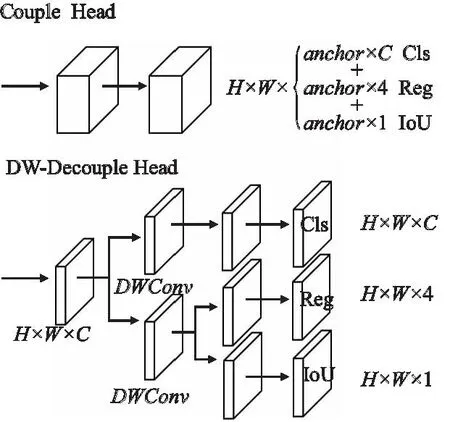
图3 耦合头与 DW-Decoupled HeadFig.3 Couple Head and DW-Decoupled Head
相比耦合检测头直接将多种信息集成在一个特征图,本文提出的DW-Decoupled Head解耦头能够有效的避免不同任务需求不同特征信息的冲突,加强定位和分类的能力;同时解耦头通过深度以及广度的操作能很好的保留各个通道信息,降低计算开销,能加快网络收敛速度,实现更快的推理速度.
2.3 边界框回归损失函数SIoU
YOLOv5模型中边界框回归损失函数为CIoU:
(1)
(2)
(3)
其中IoU是预测框和真实框之间的交集和并集之比,b是预测的中心点,bgt是真实框的中心点,ρ表示的是欧氏距离,c表示预测框和真实框所构成的外接矩形对角线长度,α表示权重系数, v表示预测框和真实框之间的长宽比差异.
CIoU没有考虑真实框与预测检测框之间不匹配的方向,导致收敛速度较慢且效率较低.因此引入一种更为均衡的损失函数SIoU[19],加入了回归之间的向量角度,重新定义了惩罚指标,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度.SIoU由4个Cost函数组成.
1) 角度损失Angle_Cost最大限度地减少与距离相关的变量数量.公式为:
(4)
其中σ为真实框和预测框中心点的距离,ch为真实框和预测框中心点的高度差.
2) 距离损失Distance_Cost尽可能探索不同的边界框在不同中心的距离.公式为:
(5)
(6)

3) 形状损失Shape_Cost代表预测框的中心位置相对于真实框中心的偏差,努力取得最优的预测框.公式为:
(7)
(8)
其中w,h,wgt,hgt分别为预测框和真实框的宽和高,θ控制对形状损失的关注程度.
4) IoU_Cost是预测框和真实框之间的交集和并集之比.公式为:
(9)
最后,回归损失函数SIoU为:
(10)
2.4 上采样的优化
YOLOv5的上采样使用最邻近插值法,该方法选用单像素点的灰度值代替源图像中与其最邻近像素的灰度值,算法简单、易于实现且速度较快,但是在上采样时会产生色块现象,从而导致特征丢失,会降低小目标的检测精度[20].与最邻近插值法相比,转置卷积的上采样方式具有可学习的参数,可通过网络学习来获取最优的上采样方式,得到的特征图更加细腻,细节的损失更少,采样到更适合铁路轨道侵限障碍物特征的尺寸和比例,于是本文将上采样方法改为转置卷积.卷积操作与转置卷积操作如图4所示.
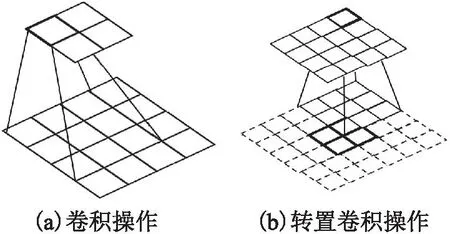
图4 卷积操作与转置卷积操作Fig.4 Convolution operation and transposed convolution operation
图4(a)为卷积操作过程的示意图.输入尺寸为4×4的特征图在经过卷积操作之后输出尺寸为2×2的特征图,卷积操作的卷积核尺寸为3×3,移动步长为1.
卷积操作公式为:
(11)
其中,w1表示输入尺寸,f表示卷积核尺寸,s表示步长,p表示卷积过程中的填充值,⎣·」表示向下取整操作.
图4(b)为转置卷积操作过程的示意图.表示输出尺寸为2×2的特征图,经过转置卷积操作得到与卷积输入相同尺寸的特征图实现上采样.
转置卷积操作公式为:
(12)
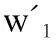
3 实验结果与分析
3.1 实验环境与参数设置
具体实验环境如表1所示.

表1 实验环境Table 1 Experimental environment
在模型训练过程中,为减小模型陷入局部最优的可能性,使用随机梯度下降(Stochastic GradientDescent,SGD)优化器,同时为了加速网络收敛,使用官方提供的基于COCO数据集训练的预训练权重作为初始权重,将网络训练的初始学习率设为0.01,动量因子设为0.937,权重衰减设为0.0005,超参数使用hyp.scratch-low,批次大小batch-size设为16,共训练250轮.
3.2 实验数据集
为了评估本文改进的目标检测算法的优越性,本研究使用RS铁路入侵异物数据集进行主要实验,并使用公开的PASCAL VOC 2012数据集[21]辅助实验验证.
当前没有公开的铁路入侵异物数据集,因此自制铁路入侵异物数据集RS.数据集来源为互联网和铁路监控真实图片.行人、汽车、自行车3类目标是在铁路异物入侵事件中最常发生的,所以本文以行人、汽车和自行车3类目标研究实验.RS数据集共6000张图片,其中训练集4000 张,验证集1000张,测试集 1000 张,大小尺寸基本与600×800一致.同时人为挑选数据集中含有3类目标的图片,使样本数量均衡.其中训练集与验证集的图片来自于互联网,测试集的图片来自于真实铁路监控下的异物入侵场景,测试集中的各个类别也保持相对均衡.RS数据集示例如图5所示.PASCAL VOC 2012数据集是一个包含类别丰富的数据集,包含4个大类和20个小类,共17125张图片,其中训练集13700张,验证集1713张,测试集1712张.PASCAL VOC 2012数据集示例如图6所示.本文提出的SD-YOLO算法模型分别在RS数据集和PASCAL VOC 2012数据集的训练集和验证集上进行训练,在测试集上测得最终的平均精度和检测速度.

图5 RS数据集示例Fig.5 RS dataset example

图6 PASCAL VOC 2012数据集示例Fig.6 PASCAL VOC 2012 dataset example
3.3 评价指标
实验采用精度(Precision,P)、召回率(Recall,R)、所有类别平均精度值(mean Average Precision,mAP)、参数量(Parameters)、浮点运算次数(Giga Floating-point Operations Per Second,GFLOPS)、每张图片的推理时间(Inference)、每秒检测帧数(Frames Per Second,FPS)性能指标评估本文所提算法的性能.公式分别表示为:
(13)
(14)
(15)
(16)
其中:TP表示模型预测的结果积极是准确的,FP表示模型预测的结果积极是错误的,FN表示模型预测的结果消极是错误的.平均精度AP(Average Precision)为PR曲线下的面积,平均精度平均值(Mean Average Precision)衡量全部类别下的AP的均值.mAP@0.5表示IoU设为0.5时的平均精确度,mAP@0.5∶.95表示IoU从0.5到0.95,步长为0.05时的平均精确度.FPS表示网络模型每秒能检测的图片数量,即网络检测速度.
3.4 SSA混合注意力模块实验分析
混合注意力模块由Spatial空间注意力子模块与SENet通道注意力子模块串联组成,使全局信息充分发挥作用,更好的拟合相关特征信息,提高模型对小目标识别的效果.为了探究SSA混合注意力子模块中通道注意力和空间注意力两个模块的不同组成以及不同串行顺序的效果,本文在RS数据集上进行实验对比.实验结果如表2所示.
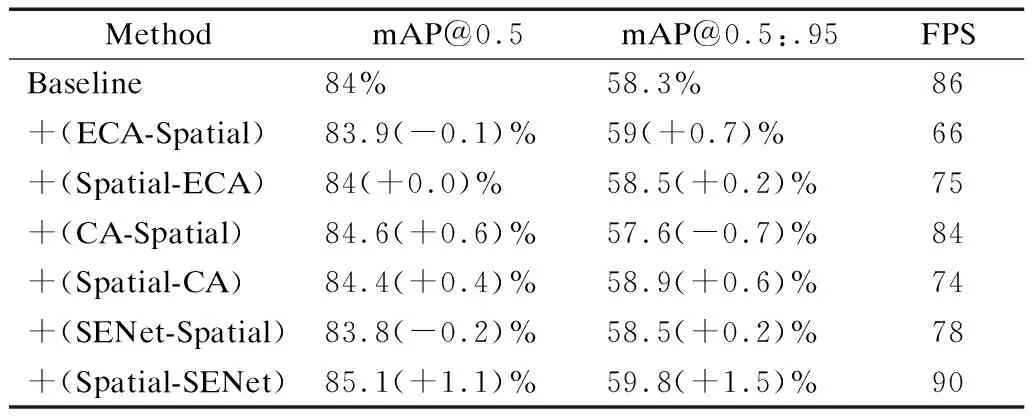
表2 注意力子模块中不同组成和串行顺序的实验Table 2 Experiments on different compositions and serial sequences in attention sub-modules
从实验中可以看出空间注意力Spatial与通道注意力SENet顺序串行表现的效果最好,平均精度mAP@0.5与mAP@0.5∶.95分别提升了1.1%和1.5%,并且处理每张图片的速度也有所提升,达到了90 FPS,证明了所提出的混合注意力模块对网络提取特征的有效性.因此将空间注意力Spatial与通道注意力SENet串联组成的混合注意力命名为SSA混合注意力机制.
为了对比验证提出的SSA混合注意力模块的有效性与泛化性,本文在RS数据集与PASCAL VOC 2012数据集上分别设置5组对比试验实验,对比提出SSA混合注意力与4种主流使用的注意力模块的效果.实验结果如表3和表4所示,在两个数据集中平均精度mAP@0.5分别提升了1.1%和0.6%,mAP@0.5∶.95分别提升了1.5%与0.6%,同时还保持了良好的检测速度,保证了实时检测的性能,证明了本文提出的SSA混合注意力模块具有有效性与广泛适用性.

表3 不同注意力机制在RS数据集上的对比实验Table 3 Comparative experiment of different attention mechanisms on RS dataset
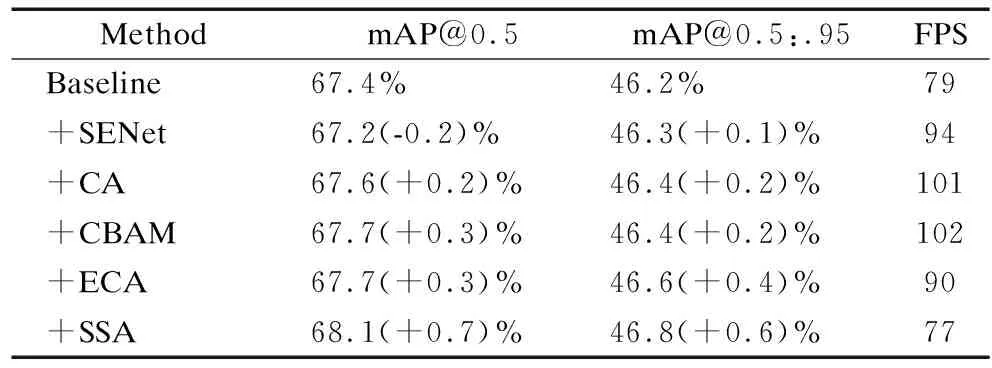
表4 不同注意力机制在PASCAL VOC 2012数据集上的对比实验Table 4 Comparative experiment of different attention mechanisms on PASCAL VOC 2012 dataset
为了更加直观的说明本文所提出的SSA混合注意力模块的效果,采用Grad-CAM(Gradient-weighted Class Activation Map)[22]对本文提出的SD-YOLO网络模型的训练权重进行视觉可视化,其输出网格的每个位置表示该类别的重要程度.通过Grad-CAM绘制不同注意力模块的热力图,呈现图片中每个位置与该类别的相似程度,与之相似程大特征就显的越集中.如图7所示,对本文提出的SSA混合注意力机制与主流注意力机制进行热力图效果对比,明显可以看出SSA混合注意力机制的对人这个目标的关注区域中热力特征更为集中,并且对不相关特征的关注度更低,没有过多的非相关特征区域,证明SSA混合注意力真正地提取出了积极有效的特征.

图7 各种注意力机制热力对比效果图Fig.7 Thermal contrast effect diagram of various attention mechanisms
3.5 消融实验
SD-YOLO对YOLOv5s网络模型的注意力机制、输出特征方式和上采样方式进行了改进,同时引入了更加平衡的边界框回归损失函数SIoU.为评估本文提出的模块或引入的模块和不同模块的组合顺序对于算法性能优化的程度,设计了一系列消融实验.同时为了证明本文所提算法在不同数据集场景下的泛化性能,本文的消融实验在自制的铁路入侵检测数据集RS和PASCAL VOC 2012数据集上分别进行,两组消融实验结果分别如表5、表6所示.
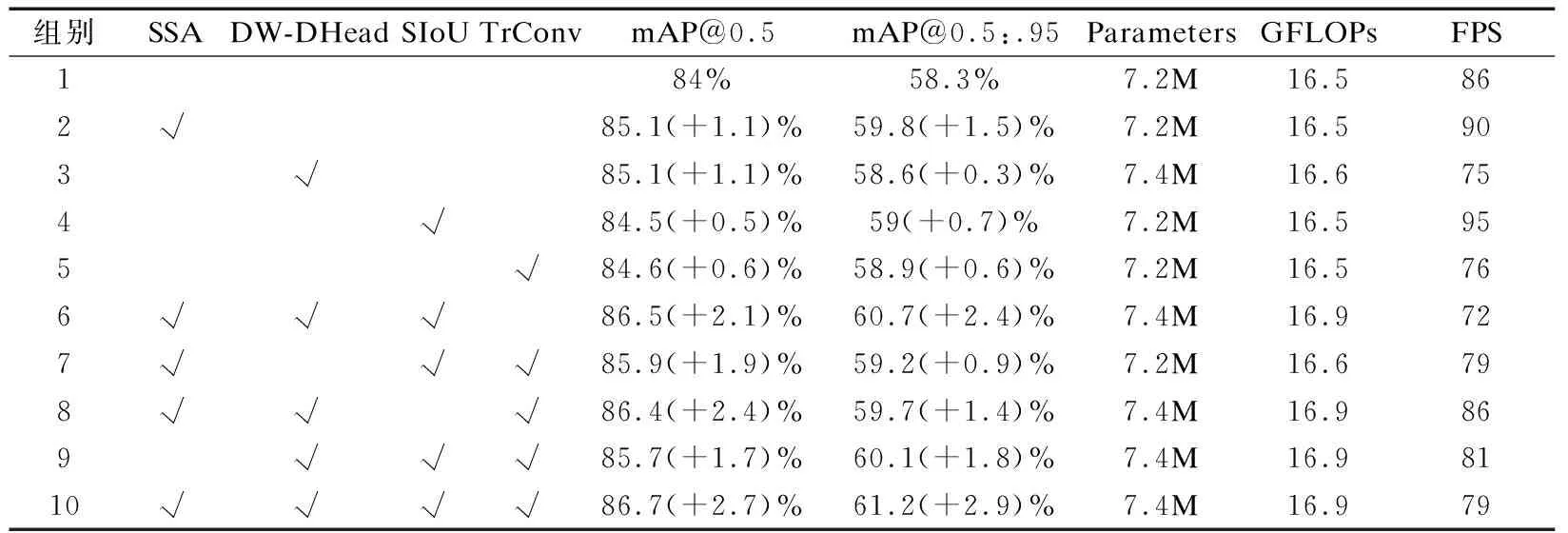
表5 SD-YOLO在RS数据集上的消融实验Table 5 Ablation experiment of SD-YOLO on RS dataset

表6 SD-YOLO在PASCAL VOC 2012数据集上的消融实验Table 6 Ablation experiment of SD-YOLO on PASCAL VOC 2012 dataset
“√”表示在YOLOv5s网络模型的基础上加入该方法,从两个表中可以看出,本文所提出的4个改进方法在RS数据集和PASCAL VOC 2012数据集上检测精度都有不同程度的提升.通过设置的10组消融实验,每次增加一种改进方法都分别提升了检测精度,证明了本文所提出的不同改进方法组合的有效性.本文提出的SD-YOLO算法相较于原始 YOLOv5s,在RS数据集和 PASCAL VOC 2012数据集上平均检测精度mAP@0.5分别提高了2.7%、1.8%,mAP@.5:.95分别提高了2.9%、2.1%,检测速度分别达到79 FPS和78 FPS,在耗费极少参数量与浮点运算次数的条件下有着更高的检测精度,同时能够很好地保持算法实时性.通过在两个数据集上的实验证明了本文所提算法在通用检测领域具有较好的泛化性和有效性,也进一步证明了本文所提算法能够更好地处理复杂铁路背景下的异物入侵检测问题.
3.6 对比实验
为了评估本文所提算法模型SD-YOLO的先进性与有效性,本文将最终提出的算法与原YOLOv5s算法、SSD、Faster R-CNN、YOLOv3、YOLOv4-tiny[23]、YOLOv4[24]、YOLOv5m、YOLOX-tiny[25]、YOLOX-S[25]、YOLOv6-tiny[26]、YOLOv7-tiny[27]算法在RS数据集上进行实验对比,实验结果如表7所示.
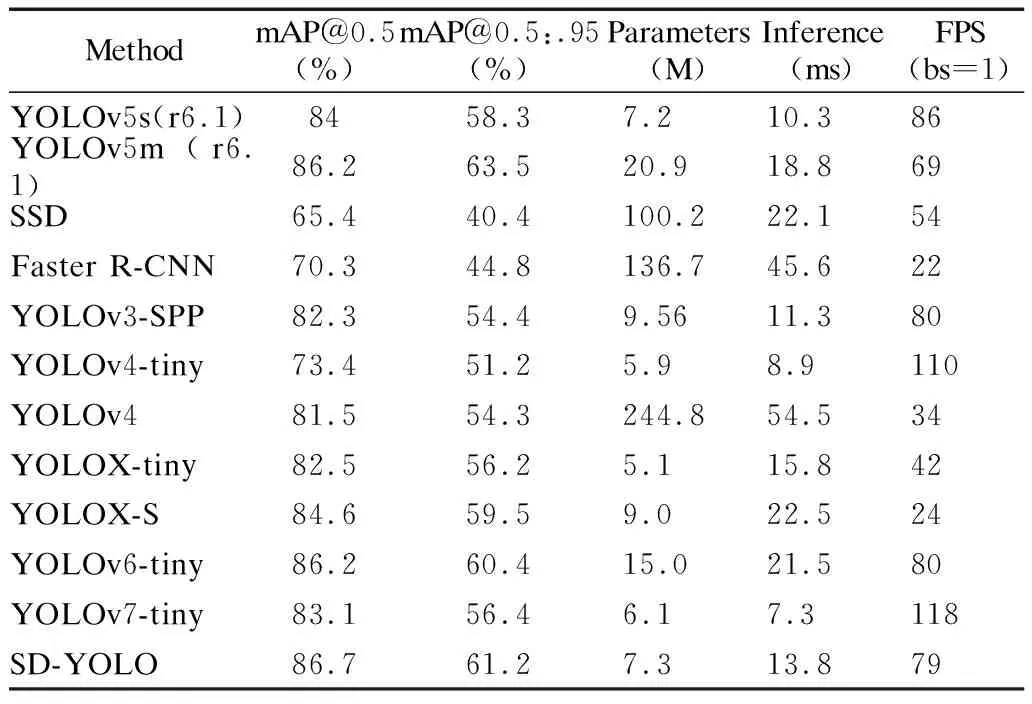
表7 不同目标检测算法在RS数据集上的对比实验Table 7 Comparative experiment of different target detection algorithms on RS dataset
从表7不同目标检测算法在RS数据集上的对比实验结果可以看出,本文提出的SD-YOLO算法相较于其他主流的算法模型,有着最高的检测精度.其中相较于同一个网络结构的YOLOv5m网络,本文所提算法比YOLOv5m参数少130%,检测精度高了0.5%;相较于检测速度较为相近的YOLOv5s算法以及YOLOv3算法,本文所提算法的检测精度优势明显,比 YOLOv5s高2.7%,比YOLOv3高4.4%,而YOLOv4-tiny与YOLOv7-tiny虽然有着较高的检测速度,达到110 FPS和118 FPS,但是检测精度却相对较低,只有73.4%和83.1%,无法在复杂铁路背景下应用;相较于参数较为相似的YOLOv5s、YOLOv4-tiny、YOLOX-S、YOLOX-tiny以及YOLOv6-tiny算法,本文所提算法的检测精度分别高了2.7%、13.3%、2.1%、4.2%、0.5%.综上所述,本文提出的SD-YOLO算法有着最高的检测精度,并且保持着较好的实时性,整体表现较为突出,证明了本文所提算法的优越性.
为了更加直观地进行评价本文所提算法的性能,本文对改进前后的检测效果对比进行了展示,如图8所示.对比检测结果表明,SD-YOLO在两组图片中表现出了优秀的检测性能,检测到了更多小目标,并识别出被遮挡目标,且不存在误检问题,表明在复杂的铁路背景下,本文提出的SD-YOLO算法,相比于原始的YOLOv5s算法,对遮挡目标以及小目标检测时存在的误检和漏检问题都有所改进,并且FPS达到79,保持着实时的检测速度,能够在很好地保持算法实时性的同时有着更高的检测精度,满足铁路复杂场景下实时性与精确性的需求.

图8 YOLOv5s和SD-YOLO检测效果对比Fig.8 Comparison of detection effects between YOLOv5s and SD-YOLO
4 结 论
针对复杂铁路背景下异物入侵检测方法中精度低、时效性差等问题,本文提出SSD-YOLO算法模型进行复杂铁路背景下的异物入侵检测.在YOLOv5基础上加入提出的SSA混合注意力、DW-Decoupled Head解耦头,并利用回归损失函数SIoU、转置卷积方法,在保持算法速度和体量优势的同时获得了更高的检测精度,相比其他主流目标检测算法模型,本文提出的算法检测精度更高且对遮挡目标以及小目标检测存在的误检和漏检问题都有所改进,检测速度也具有实时性,更适用于复杂铁路背景下的异物入侵检测.本文接下来的工作是对网络进行轻量化处理,更利于部署在嵌入式GPU平台应用于真实场景.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中老年保健(2021年9期)2021-08-24 03:49:56
昆明医科大学学报(2020年12期)2021-01-26 00:43:52
电子制作(2019年11期)2019-07-04 00:34:38
兽医导刊(2019年1期)2019-02-21 01:14:26
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
