
融合多尺度CNN和CRF的通用细粒度事件检测
2024-04-22 02:30任永功何馨宇
小型微型计算机系统 2024年4期
任永功,阎 格,何馨宇,2,3
1(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116081) 2(大连理工大学 通信与工程博士后研究站,辽宁 大连 116081) 3(大连永佳电子技术有限公司博士后工作站,辽宁 大连 116081)
0 引 言
随着互联网的高速发展与普及,使得用户每天上网时会频繁面对大量的交互式行为,如何从爆炸式的信息中提取出有用的关键性信息已经成为人们重点关心的话题,因此信息以结构化的方式集中在一处呈现也成为了人们的必备需求之一,这样会使得人力与物力成本大大降低,这也是信息抽取的重要意义.
事件抽取任务是信息抽取领域的重要子任务,而事件抽取包含事件检测和元素检测两部分,在金融分析[1]、生物医学[2]、知识图谱[3]等各大领域都有广泛的探究与应用.对于开放域的事件抽取,主要采用无监督的方法进行抽取[4],由于涉及到的事件类型较为广泛,模型的泛化性得以保证,而抽取出的以结构化方式呈现的信息又可以在后续被进一步提取其事件关系,如共指关系[5]、因果关系[6]、时间序列[7]等,所以成为了近年来研究的热点领域.
事件检测指从特定的文本中提取出表达其对应事件发生的触发词,主要涉及对事件的触发词进行识别与分类两部分,触发词一般以动词词性或代表动作、状态的名词词性为主,如图1所示,给定一个文本中的句子,“earthquake”、“occurred”是句子中的两个触发词,分别触发“Catastrophe”、“Coming_to_be”事件类型.

图1 事件检测的例子Fig.1 Example of event detection
近年来,事件检测任务主要采取基于特征的网络模型和基于深度神经网络的模型,Nguyen等人[8]采用联合抽取模型来标注实体与事件之间的语义关系,但是忽略了事件之间存在的关联性,Liu等人[9]提出了门控多语言的注意力机制框架来进行事件检测.Li等人[10]通过构建全局特征来弥补局部特征提取所带来的信息缺失.Chen等人[11]用卷积神经网络(Convolutional Neural Networks,CNN)来对事件进行提取.Zhang等人[12]使用跳窗卷积神经网络以此来提取事件的全局特征.
在事件检测任务中面临的主要问题其一是触发词存在一词多义的现象,其二是在一句话中存在着多个事件触发词并存的情况,这样会因为特征提取不充分从而导致检测出一句话中全部事件的难度大大增加.针对上述问题,本文提出了BMCC模型来检测事件,它由BERT(B)、Multi-scale CNN(MC)、CRF(C)组成.综上所述,本文的主要贡献如下:
1)提出了BMCC模型.即融合了BERT预训练模型和多尺度CNN的神经网络,将BERT与不同尺度的卷积核在多卷积通道上的卷积信息相结合,充分地提取上下文语义特征,并且将BIO机制与CRF结合来进行序列标注,更好地识别多词触发词的情况,在通用细粒度事件检测任务中,该模型在MAVEN数据集上的总体性能良好.
2)设计了多尺度CNN模块(MCNN).通过不同大小的卷积核在3个不同卷积通道上进行卷积训练,提取更加全面的语义表征,通过实验表明该模块使得模型的特征提取能力有所提升,分类效果更优越.
3)在CRF进行序列标注时引入了BIO标注机制,解决了触发词为多词时分类不匹配的问题,同时缓解了触发词短语标签之间的强依赖性问题,从而提升模型的分类效果.
1 相关工作
事件检测是事件抽取中的重要任务之一,它旨在提取出目标文本中的触发词,并将其归类为指定的事件类型.常见的事件检测方法大致分为以下3类.
基于模式匹配的事件检测方法是通过构建模板对事件进行抽取的.Kim等人[13]将WordNet的语义信息融入其中,依赖于短语的模式结构和语义结构来检测事件.Yangarber等人[14]通过判断文本是否相关将语料库划分成种子模式集,并用相关模式对关联本文进行学习,从而达到事件检测的目的.这种方法对于特定领域有着良好的抽取能力,但是可移植性较差,人力成本较高,不具有普适性.
基于机器学习的事件检测方法是在大量的统计学习中将任务转化为分类的问题,Li等人[15]通过条件随机场和全局特征来提高抽取的性能.Chen等人[16]使用了隐马尔科夫模型以字符级的方式对触发词进行检测.这种方法虽然移植性更强但是其往往借助于特征工程和自然语言处理的辅助工具,处理过程繁琐且容易形成误差累计.
基于深度学习的事件检测方法是对文本中数据的语义表征进行学习的方法,这种方法普适性较强,是近年来研究的主要方向.Nguyen[17]等人提出了JRNN模型,通过双向循环神经网络对句子特征进行学习,并将记忆矩阵和记忆向量引入其中对模型进行预测.Ding等人[18]通过引用HowNet外部知识库和树形LSTM对特征进行融合,从而提出了TLNN模型,缓解了触发词歧义的现象.Xu等人[19]基于图形的方式将文本进行了转化,增强了事件与事件之间的联系.Pan等人[20]将注意力聚焦在要素上并与编码层融合从而来提高触发词的抽取能力.Lai等人[21]使用多模态信息来缓解样本值异常的情况,从而对事件进行检测.Cai等人[22]采用无监督算法,通过自扩展迭代的方法,在无需手动标注关键词的情况下对语句中的关键词进行抽取.Shen等人[23]通过级联解码的方式在同一框架中进行联合学习,实现了重叠事件的抽取.基于预训练处理的相关模型在NLP上也取得了重大的突破,Peters等人[24]提出了上下文相关的预训练模型,即Embedding from Language Models(ELMo)模型,此外,Radford等人[25]利用单向Transformer提出的Generative Pre-Training(GPT)模型,Devlin等人[26]利用大量无标注文本在无监督的情况下形成了双向Transformer的预训练模型,即为Bidirectional Encoder Representations from Transformers(BERT).
上述先进的方法在事件检测任务中都取得了优越的结果,但是对深层次的语义表征提取不充分,从而影响提取的精确度.对于大规模的通用数据来说,在细粒度的抽取上,需要通过特征去对语义信息进行判断,所以能否准确的提取语义特征信息成为了是否可以成功检测事件的必要条件,因此本文通过BERT预训练模型和多尺度CNN对特征进行深层次地提取,最后通过CRF标注序列对事件检测结果进行匹配.
2 方 法
本文提出了BMCC模型,首先采用BERT对文本进行编码生成词嵌入向量,接着通过BERT的Transformer模型对词嵌入向量进行预训练,进而得到特征信息.为了得到深层次的语义信息,采用多尺度卷积网络模块来进一步获取更加全面的相关特征.最后采用了基于BIO机制标注的CRF方法来预测出最优的序列标签.具体结构如图2所示.
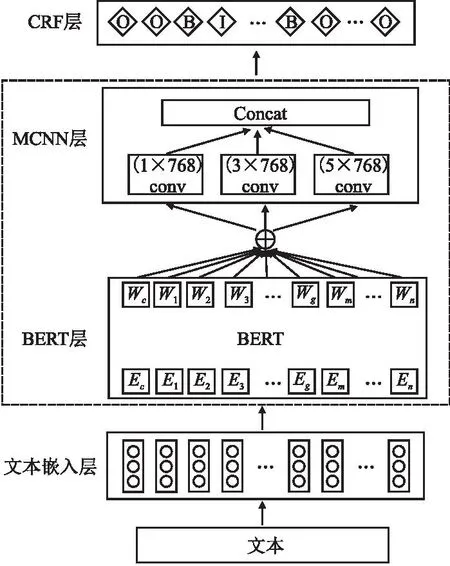
图2 BMCC模型结构图Fig.2 Structural model of BMCC
2.1 BERT层
本文采用BERT预训练模型对给定的文本进行词向量嵌入,相比于Word2Vec、Glove等传统的词向量表示,BERT则可以获取单词的动态表示,充分地考虑到了文本中的上下文关系,解决了语义多样性的问题.BERT的结构主要可以分为3层,分别是输入层、编码层以及输出层.在输入之前先将文本用WordPiece分词器进行分词操作,其次在每篇文章的句首添加[CLS]标记,在每句话的句末添加[SEP]标记,以便于句子的分割.如图3所示,BERT的输入由3个嵌入层累加所得,他们分别是将单词转化为词向量的标记嵌入层、用来分割不同句子的片段嵌入层和将文本句子中单词的位置信息进行编码的位置嵌入层.在编码层,BERT采用多维度的多头注意力机制来对句子进行编码操作,将不同的词向量进行权重组合,从而获得词与词之间的内在联系.BERT除了使用双向Transformer模型之外,还结合了掩码语言模型(Masked Language Model,MLM)和下一句预测任务(Next Sentence Prediction,NSP)这两个功能,使得模型可以更好地获取文本中的语义信息,增强模型的表征能力.因此,与基于特征表示的ELMo模型和基于单向Transformer的GPT模型相比,BERT拥有更好的词级分布式表示,更加体现全局性.
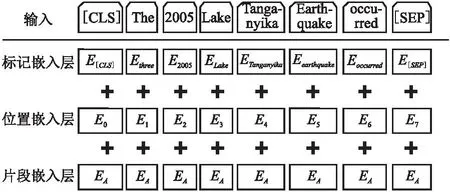
图3 词嵌入图Fig.3 Words embedding
2.2 MCNN层
卷积神经网络(CNN)具有局部相接、权值共享、下采样的特性,本文利用其特点,对BERT中输出的词向量进行更深层次的特征提取,以便提取出更全面的语义表征.卷积操作是利用卷积核在输入矩阵内进行水平滑动,对矩阵内所在的区域进行乘积累加的过程.CNN为了得到高纬度特征,通常采用更深层的卷积,但是会面临随着卷积网络的加深其性能会达到饱和的问题.为此,谷歌的Szegedy等人[27]提出了卷积模块,他们拓宽了网络模型,减少参数的个数,从而提取了更高维度的表征信息.本文参考了Inception V1的卷积思想,针对通用细粒度事件检测的文本特性,设计了多尺度卷积核模块(Multi-scale CNN,MCNN),将每个Token相应的多特征融合词向量Wn作为MCNN的输入,对其通过1×768、3×768、5×768这3种尺度的卷积核来学习文本中不同尺度的信息.
ci=f(v·Wi:i+l-1+b)
(1)
如公式(1)所示,ci是从词Wi:i+l-1的窗口中产生的局部特征,Wi:i+l-1表示Wi后l个单词的特征.v表示卷积核,v∈l×d.f为一个非线性函数,·为矩阵中的点乘运算,b为一个偏置项.对句子中的所有单词n进行卷积后得到了句子的特征图g,如公式(2)所示:
g=[c1、c2、…、cn-l+1]
(2)
本文将每个卷积通道都设置了256个卷积核来提取不同的特征,将3个不同通道的卷积核所得到的特征图设为Mk,其中k=1,3,5.如公式(3)所示,根据不同的卷积窗口大小,采用padding的方式将句子边界进行补齐,它们的padding值分别是0、1、2.
Mk=[g1、g2、…、g256]
(3)
最后将这3种尺度的特征进行拼接从而获得关键的语义特征M.
M=M1⊕M2⊕M3
(4)
传统的CNN网络会通过池化操作来获取特征信息,但是池化层会丢失一部分句子中的事件信息,所以本文不进行池化操作,以便保留事件所在句子的关键信息.
2.3 CRF层
在序列标注中,条件随机场(Conditional Random Field,CRF)可以同时聚焦到文本的上下文信息,它是一个特征灵活、全局最佳的标注框架,与此同时,本文将BIO机制融入到CRF中,以此对标签序列进行最终的序列标注,其中“B”代表事件触发词的首个单词,“I”表示事件触发词中间部分的单词,“O”表示非事件触发词.将上层的输出M=[m1、m2、…、mn]作为标签序列的输入,所对应的预测标签为Q=[q1、q2、…、qn],如公式(5)所示,可以得到预测序列各个标签的分数.
(5)
其中T为标签间对应在触发词上的转移分数,Pi,qi表示各个词所对应的qi标签的分数.最后对序列进行归一化处理,得到预测序列.
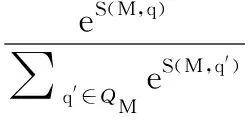
(6)
其中q′表示真实的标签值.在训练的过程中,采用对数似然函数来训练标签,如公式(7)所示:
ln(P(q|M))=score(M,q)-ln(∑q′∈QMeS(M,q′))
(7)
其中,QM代表所有可能的标签集合.在预测的过程中,由公式(8)可以得出概率值最高的一组序列.
(8)
3 实 验
3.1 数据集
本文在Wang等人[28]提出的MAVEN数据集上进行实验,该数据集规避了在原有的小规模数据集上存在的数据稀缺以及数据类型有限、覆盖率低的问题.MAVEN数据集一共包括4480篇文章,10万多个标注事件,所覆盖的事件类型为168种.它是一个规模较大的通用领域的英文数据集,其中,在41%的事件类型里,它们的标注实例超过500个,有82%的事件类型含有超过100个标注实例.在此数据集中,存在着一句话中同时出现多个事件的情况,这样可以考虑到在一个句子里不同事件类型之间的内在联系,更好地帮助模型进行事件类型的分类,从而得到通用性和广泛性更强的模型.MAVEN数据集在提供正面实例(即事件的触发词)的同时,同样提供了官方的负面实例(即事件的非触发词),使得测试的公平性得以保障,具体的数据分布如表1所示.

表1 MAVEN数据集(负面实例为非触发词的数量)Table 1 MAVEN dataset(Negative is the number of non-triggers)
3.2 参数设置
本文在Windows 10的操作系统下采用GPU的 CUDA 版本为11.3,在PyTorch框架上对程序进行设计,其中Python版本为3.8.12,Torch 版本为1.8.0以及BERT预训练语言模型为“BERT-base-uncased”,详细实验参数如表2所示.

表2 实验详细参数设置Table 2 Detailed experimental parameter setting
3.3 评价指标
本实验的评价指标为精确度P(Precision)、召回率R(Recall)和评价模型性能综合指标的F1值,如公式(9)~公式(11)所示:
(9)
(10)
4 实验结果与分析
事件检测任务可以分为对事件的触发词进行识别和分类两个部分.对事件触发词进行识别属于二分类工作,它旨在将识别出来的事件触发词与所给触发词位置进行对比,位置相同即为识别正确.而对事件的触发词进行分类是一个多分类工作,它旨在识别出触发词类型与所给触发词类型相同即为分类正确.
4.1 实验比较与分析
为了验证BMCC模型的有效性,本文将一些较为先进的模型与本实验模型进行比较,具体的结果如表3所示.
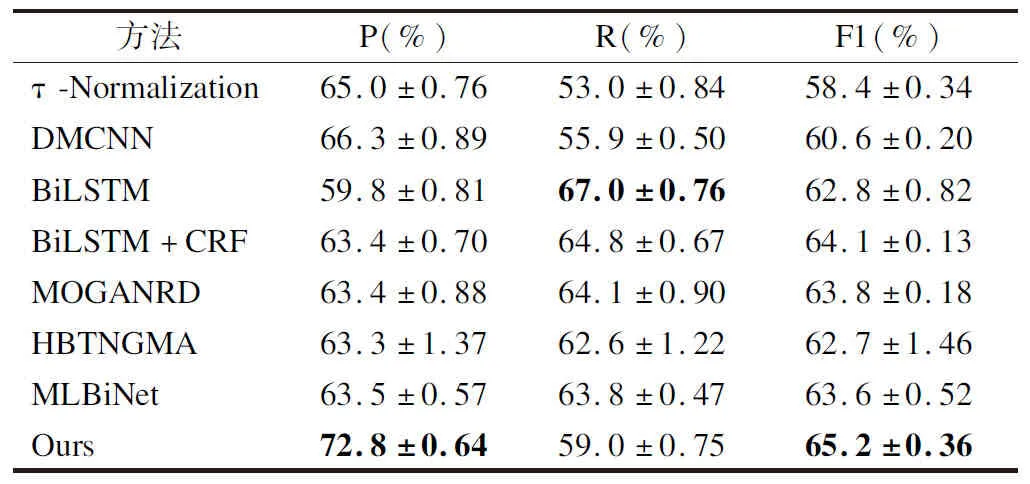
表3 MAVEN数据集上各个模型的整体性能比较Table 3 Overall trigger classification performance of various models on MAVEN
1)τ-Normalization:Kang等人[29]将以往的联合学习分解为表示学习和结果分类,并且利用多采样学习的策略来探索不同的表示之间的平衡策略,该模型在MAVEN数据集上的结果为58.4%.
2)DMCNN:Chen等人[11]将CNN设为基准,利用动态多池化与卷积神经网络结合提取特征,他们在事件检测任务中的F1值为60.6%.
3)BiLSTM:Hochreiter等人[30]利用BiLSTM,让信息前向和后向传递,以此来特征选择,他们的模型F1值为62.8%.
4)BiLSTM+CRF:Lafferty等人[31]将BiLSTM(Bi-directional Long-Short Term Memory)与CRF结合来处理序列标注问题,由于在模型中使用静态词向量,所获得特征信息有限,所以他们的F1值为64.1%.
5)MOGANED:Yan等人[32]通过句法依存树与GCN结合进行建模,并且通过注意力机制来聚合多阶句法信息,其F1值为63.8%.
6)HBTNGMA:Chen等人[33]将分层和偏执标签结合来共同检测句子中的事件,并且设计了带有门控的多层注意力机制以融合句子中动态的信息,他们的F1值为62.7%.
7)MLBiNet:Luo等人[34]通过编码-解码的框架设计了多层双向网络,以此来提取跨句语义信息和事件信息,他们的模型在MAVEN数据集上的F1值为63.6%.
结果表明,在MAVEN语料库上,BMCC模型的结果优于其他模型.本文模型的F1值比Kang高6.8%,比Chen等人高4.6%,比Hochreiter等人高2.4%,比Lafferty等人高1.1%,比Yan等人高1.4%,比Chen等人高2.5%,比Luo等人高1.6%,这也证明了BMCC模型的有效性.
4.2 交叉验证实验
为了进一步验证本文模型的泛化性能,本文对BMCC模型进行了交叉验证实验,将训练集中的数据以随机分配的方式平均分成10份进行10次交叉验证.在不重复选取的情况下,每一次选取其中的一份作为验证集,其余9份作为训练集对模型进行训练,以此来防止在实验的过程中模型所产生的过拟合现象.实验结果如图4所示,在交叉实验中模型具备较好的泛化能力,其平均F1值从原来的65.17%提升到65.28%,实验结果证明了模型的稳定性.

图4 交叉验证实验结果Fig.4 Results of the cross-validation experiment
4.3 模型的有效性分析
由于BERT是基于Transformer的编码来进行模型的预训练,使得模型层次加深,从而捕捉到词汇的语义表达.由于MCNN具有多个通道的卷积核,可以更加全面的提取文章的的卷积核,可以更加全面的提取文章的有效信息表征,并且CRF具有强大的推理能力,其有效地解决了模型中的标记偏执问题.所以,本文提出了融合BERT预训练模型和多尺度CNN的神经网络,以解决在事件检测任务中语义信息提取不充分的问题.本文采用BERT作为实验的基线模型,其F1值为61.66%,以下为BMCC模型的创新部分结果分析,如表4所示.
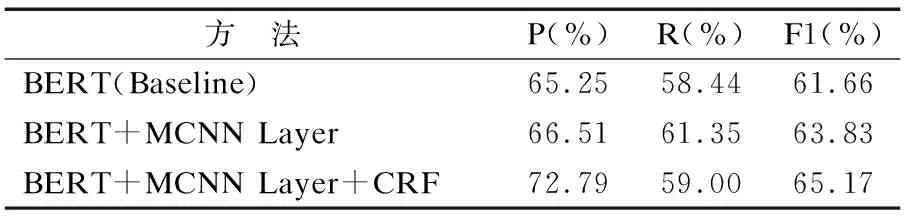
表4 实验模型的消融比较Table 4 Ablation comparison of our experimental model
4.3.1 MCNN模块的有效性
本文将BERT与多尺度的CNN结合,设计了3个不同尺度的卷积通道,其卷积核大小分别为1、3、5.由于不同大小的卷积核,所以感受的视野范围也不同,用尺度较小的1×768卷积核,使得较小的特征能够被提取.用3×768的卷积核能够提取一般长度句子间相关性的语义特征.用5×768尺度的卷积核,使得在较长的句子之间,它们的相关性特征可以被充分提取.通过设立多个卷积通道,让模型感受不同维度的文本信息,所提取的尺度特征也会增多,从而可以提取不同的语义信息,进一步丰富其语义表征,进而提高了模型的精确度和召回率,使得触发词的准确率F1值提高了2.17%.
4.3.2 CRF的有效性
传统的序列标注softmax分类器在进行标签分类时往往会将标签间的依存关系忽略,从而影响序列的分类结果,本实验将其替换成基于BIO机制的CRF方法对序列进行标注,使得语义特征在错综复杂、非独立却具有重复性的情况下,充分地利用上下文的特征信息,从而使模型获取的信息更为丰富.并且模型在每一个状态转移时都会进行归一化操作,充分地考虑到了触发词之间不匹配的问题,使得一句话中出现多个事件的准确率得以提高,从而将F1值提高了1.34%.
最终使得通用细粒度事件检测任务在MAVEN数据集上的F1值达到了65.17%的良好效果.
5 总 结
本文提出了融合BERT预训练模型和多尺度CNN的神经网络模型来进行通用细粒度事件检测.该模型首先通过BERT进行语义编码和模型的预训练来提取不同粒度的词义表征,而后采用MCNN模块进行多尺度的卷积,将词嵌入向量进行不同尺度的卷积从而提取出不同视野的语义特征,进而得到语义丰富的表征信息.最后通过条件随机场CRF对序列进行标注,实现多标签的分类.相比于传统的事件检测模型,BMCC模型在实验中效果更好,在MAVEN数据集上F1取得了65.17%的良好成绩.然而由于该模型未融入句义信息及句法特征,所以在句子与文档方面的语义信息提取不全面.在接下来的研究工作中,本文将考虑引入句子级和篇章级的语义特征,从而在模型中引入更多有效的语义特征,进一步提高通用细粒度事件检测的模型性能.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
