
基于XGBoost的自动驾驶汽车事故风险预测研究
2024-04-22 11:41朱小平张丽英刘静向健龙
时代汽车 2024年6期
朱小平 张丽英 刘静 向健龙
摘 要:自动驾驶汽车风险具有复杂性和隐蔽性,不易被人为地发现和预防。为了更好地预测这些风险,利用美国加州自动驾驶事故数据集,从时间、地点、人员参与、天气等多维度提取数据,数据经过预处理从而构建自动驾驶事故数据库。然后,将XGBOOST算法与数据相结合,建立自动驾驶汽车事故风险预测分类模型。将XGBOOST算法与多种算法进行比较分析,结果表明,XGBOOST算法为较优,其训练和测试预测精度分别超过 92.27%和97.06%,能够有效地识别出高风险和低风险的自动驾驶汽车事故情况。
关键词:自动驾驶汽车 XGBoost算法 风险预测
1 引言
自动驾驶有很多优点,比如可以提高交通效率、减少人为错误、节省能源等。但是,自动驾驶也存在一些风险,如政策风险、事故风险、系统风险等等。因此,对自动驾驶风险进行预测分析是非常必要的。预测分析可以帮助我们了解自动驾驶的潜在风险,评估风险的可能性和严重程度,制定风险的应对措施和预案。
王浩旭[1]利用Carsim仿真软件验证信控交叉口自动驾驶汽车风险控制措施的有效性及合理性。薛松[2]提出了一种基于自动驾驶场景的预期功能安全危害分析评估方法。王明[3]根据周边车辆信息,提出一种融合风险的自动驾驶汽车规划方法。Subasish[4]对美国加州的2014-2019年的数据应用贝叶斯潜类模型来识别碰撞模式。Siying[5]通过成本敏感分类和回归(CART)模型開发了一个包含可能影响因素的自动驾驶汽车碰撞严重程度分类树,该模型可以处理自动驾驶汽车碰撞数据集中引发的类不平衡问题。自动驾驶汽车风险多数采用仿真方法,较少以定量的方法进行研究,且定量风险评估需考虑多个维度因素。本文综合考虑人-车-路-环境因素基于XGBoost算法对数据进行全面综合评估。
2 数据源介绍
2.1 数据源梗概
DMV[6]是Department of Motor Vehicles(机动车辆管理局)的缩写,它是负责管理公共道路上的机动车辆和驾驶员的政府机构。DMV的数据包括以下几个方面:机动车辆登记、驾驶员许可、自动驾驶测试。
2.2 数据预处理和实验数据
本文采用的是自动驾驶测试中的碰撞报告,包括事故的时间、地点、原因、结果、参与者、车辆、伤害、损失等。
通过在DMV官网上搜集2014-2023年7月的数据,数据集变量是数据原始的变量定义,中文变量名称是本文自定义解释,变量解释是本文对变量进行批次分类的再定义。
3 预测方法
XGBoost[7]在处理大数据时,精度高且可避免过拟合,有效处理缺失值。具体模型[8]如下:
其中,为独立树结构;F为树空间。
其中,为目标函数;l为损失函数;为模型惩罚项,且:
其中,G为叶的数量;为第i片叶的分数;为节点切分的难度;为正则化系数。
求解式(1)~(3),得到:
4 实验结果
利用pycharm软件使用XGBoost机器学习算法对DMV数据进行训练和测试,对自动驾驶事故数据集进行等级分类预测,得到以下结果:
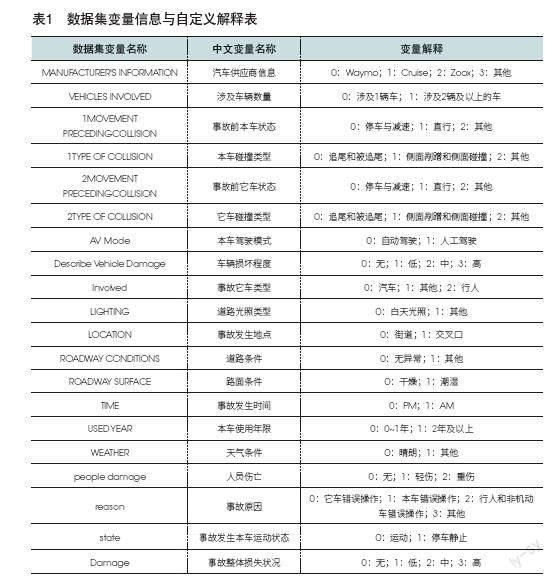
由于截止到2023年7月,DMV事故数据集只有620条数据,为了保持数据的有效性,采用数据交叉验证的方式,如图1,横坐标为交叉验证的折次数,纵坐标为预测精度,由图可知,当交叉验证折数为9时,训练预测精度为92.27%,此时测试预测精度为97.06%。
5 有效性分析
在机器学习分类模型中,Gradient Boosting和LightGBM[9]、CatBoost[10]、Stochastic Gradient Descent[11]、Passive Aggressive Classifier[12]、Perceptron Classifier[13]以及SVM[14]都是备受青睐的算法。
首先,XGBoost算法展现了在特定交叉验证折叠下的鲁棒性和高度的预测精度。它在许多情况下表现出良好的性能,尤其是在数据模式复杂或特征维度高的情况下。然而,与其他算法相比,其表现可能略显中庸。
相较之下,LightGBM以其基于梯度提升框架的高效性和低内存占用而著称,在处理大规模数据时表现出色。CatBoost则专注于处理类别型特征和自动处理缺失值,这使得它在某些数据集上表现突出。Stochastic Gradient Descent和Passive Aggressive Classifier则适用于在线学习和大规模数据流,其快速的更新速度使其在这些场景下具备优势。Perceptron Classifier和SVM则在处理线性可分数据和复杂核函数映射时表现出色。
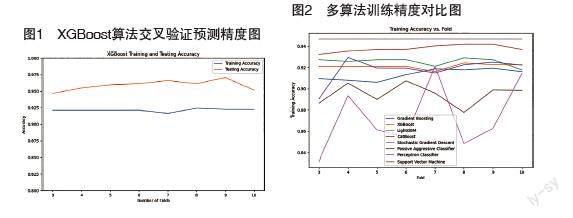
综上所述,每种算法都有其独特的优势和适用领域。XGBoost在稳定性和普适性上表现良好,而其他算法则在特定场景下可能更具优势。因此,在选择适用于特定问题的机器学习模型时,需要根据数据特征、规模和问题本身的要求来进行综合考量,并结合交叉验证等方法来充分评估模型的性能和适用性。它们各自具有独特的特点和适用场景,因此在比较它们与XGBoost在预测精度上的表现时,通过使用交叉验证来训练和测试模型,得到了如下结果:
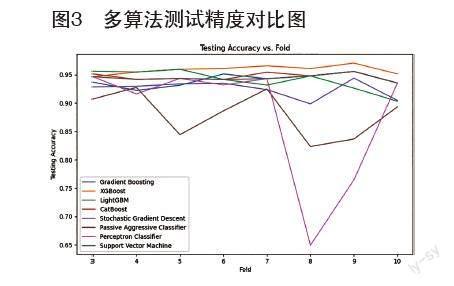
图2展示了训练结果的概貌,横坐标为交叉验证折数,纵坐标则反映了训练精度。尽管XGBoost算法在该图中处于中间水平,但是从下图3中的观察可以发现,在第三折到第十折之间,XGBoost算法表现出了相当稳定的趋势。实际上,在这段时间内,绝大部分情况下XGBoost算法都展现出最高水平的预测精度。尤其值得注意的是,第9折所达到的精度最为显著,其训练和测试的精度分别达到了92.27%和97.06%。
这种模式可能反映了XGBoost在特定数据折叠下的优势,尤其是在这种交叉验证的框架下。这样的结果可能表明XGBoost算法在特定折叠中能更好地捕捉数据的模式,并在模型的学习过程中更准确地推广到新数据上。这也突显了算法的鲁棒性和有效性,尤其是在处理这个特定数据集时。
除了图2和图3中呈现的训练结果外,还值得注意的是XGBoost算法在训练和测试阶段之间的差距。这种差距可能暗示着一些潜在的过拟合或者模型在新数据上泛化能力的限制,需要进一步的探索和分析。
总的来说,尽管XGBoost算法在图2中的表现未必最为突出,但是深入研究后我们发现其在特定交叉验证折叠中的稳定性和高精度表现。这种发现为我们对该算法的性能和优势提供了更深入的认识,并为未来进一步优化模型或探索其他算法提供了有益的参考。
6 结论
自动驾驶风险预测是一个极具复杂性的领域,需要全面考虑事故发生的多种影响因素和指标。这项研究利用了美国加州DMV自动驾驶事故集中的数据,并通过定义和分析对其进行了深入研究。同时,多种分类模型在该数据集上进行了比较和分析,以确定最契合的模型和分类预测精度。最终,选择了XGBoost算法,并通过交叉验证的方式对数据集进行训练和预测。结果显示,XGBoost算法表现出色,其预测结果优异,训练和预测的分类精度分别高达92.27%和97.06%。
未来,这项研究可能有助于改进自动驾驶系统的安全性。通过深入理解事故发生的因素,并使用高精度的预测模型,我们有望进一步提高自动驾驶车辆的安全性能。此外,该研究还为未来开展更多实证研究提供了有价值的数据和方法,以持续改进自动驾驶技术,并推动其在道路安全方面的进步。
项目基金:桂林电子科技大学研究生教育创新计划项目(2023YCXS192)。
参考文献:
[1]王浩旭.基于信控路口先验事故的自动驾驶汽车安全风险分析及仿真测试[D].重庆:重庆交通大学,2022.DOI:10.27671/d.cnki.gcjtc.2022.000844.
[2]薛松.基于自动驾驶场景的预期功能安全危害分析评估方法设计与实现[D].上海:华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.001538.
[3]王明,唐小林,杨凯,等.考虑预测风险的自动驾驶车辆运动规划方法[J].汽车工程,2023,45(08):1362-1372+1407.DOI:10.19562/j.chinasae.qcgc.2023.08.007.
[4]Das S ,Dutta A ,Tsapakis I .Automated vehicle collisions in California: Applying Bayesian latent class model[J].IATSS Research,2020,44(4):300-308.
[5]Siying Z ,Qiang M .What can we learn from autonomous vehicle collision data on crash severity? A cost-sensitive CART approach[J].Accident Analysis and Prevention,2022,174106769-106769.
[6]刘通.2021加州DMV自动驾驶榜,中企班行秀出[J].汽车纵横,2022,(03):80-82.
[7]张利斌,吴宗文.基于XGBoost机器学习模型的信用评分卡与基于逻辑回归模型的对比[J].中南民族大学学报(自然科学版),2023,42(06):846-852.DOI:10.20056/j.cnki.ZNMDZK.20230616.
[8]胡江,苏荟.水工结构变形预测模型构建与解释[J/OL].水利水运工程学报,1-12[2023-11-10]http://kns.cnki.net/kcms/detail/32.1613.TV.20231107.1706.014.html.
[9]梁晓霞,谢东海,韩宗甫,等.基于梯度提升算法的近地面臭氧浓度估算比较[J].中国环境科学,2023,43(08):3886-3899.DOI:10.19674/j.cnki.issn1000-6923.2023.0128.
[10]李宁,杨镇华,马伟中,等.基于CatBoost算法的SAP混凝土抗压强度预测[J].内蒙古公路与运输,2023,(05):1-6.DOI:10.19332/j.cnki.1005-0574.2023.05.001.
[11]王福胜,甄娜,李晓桐.R-线性收敛的重要样本抽样随机梯度下降算法[J].工程数学学报,2023,40(05):833-842.
[12]周林寰.一类支持向量机在线算法及其应用[D].大连:大连理工大学,2021.DOI:10.26991/d.cnki.gdllu.2021.001233.
[13]王新偉,张漓黎,莫德科,等.基于信息量和多层感知机分类器模型耦合的平果市斜坡类地质灾害易发性评价[J].中国岩溶,2023,42(02):370-381.
[14]林明松,杨晓梅,杨志霞.结构化最大间隔双支持向量机在股票预测中的应用[J/OL].计算机工程与应用,1-11[2023-11-10]http://kns.cnki.net/kcms/detail/11.2127.TP.20231109.1443.008.html.
