
基于星地数据与GA-DNN算法河北省径流格点数据降尺度研究
2024-04-20 06:13:56张常清
水利科技与经济 2024年3期
张常清
(河北省衡水水文勘测研究中心,河北 衡水 053000)
0 引 言
地表径流是陆地生态过程中多元物质与能量流动的关键驱动要素,径流量时空分布对经济社会发展、生态环境变化具有重要影响[1]。目前,GOU等[1]开发了我国为数不多的径流量格点产品,但其空间分布仅为0.25°(约25km),导致在流域尺度水文模拟、水资源管理中缺乏有效应用。因此,降尺度技术为改善其空间分辨率和数值精度提供了潜在可能。降尺度过程依赖于解释地表径流过程的地形、土地利用、人为活动、土壤含水率等环境变量,但各变量之间可能存在线性、冗余关系,导致模型过拟合。遗传算法(Genetic Algorithm,GA)可以不考虑线性相关性而侧重于构建最小变量集,以使模型拟合精度最优。随机森林(Random forest, RF)是经典机器学习技术之一,相比于其他神经网络、机器学习等非线性方法,其参数优化简易、收敛性佳,因此善于解决高维、非线性问题。
本文以江苏省为案例,运用GA-RF算法,先利用GA算法对降尺度因子进行优化,再结合RF技术建立径流格点数据降尺度模型,进而重构省域尺度径流量精细化分布式的栅格面。
1 研究区与方法
1.1 河北省概况
河北省地处我国阴山-太行山向渤海中段延伸地带,经纬度在E113°27′-E119°50′、N36°05′-N42°40′之间,省域陆地面积18.85×104km2。全省地势西高东低、北高南低,形成坝上高原、土石山地、华北平原、前海湿地等折叠地貌景观,海拔0~2 882m,见图1。河北省属温带季风性气候向温带大陆性气候过渡区,具有季候差异明显、水热同期、年内温差大的特点,多年平均气温8℃~14℃,平均降水量531.7mm,年日照时数2 303.1h,各地无霜期介于81~204d。主要河流为海河、滦河等,多年平均水资源总量204.69×108m3,仅占全国水资源总的0.72%。其中,地表水资源量约120.17×108m3,全省人均水资源量仅约为300m3,不足全国平均水平的1/9。总体而言,河北省地表水资源相对匮乏,以径流量格点数据降尺度为研究目标,对半湿润半干旱区水资源优化配置具有积极意义。
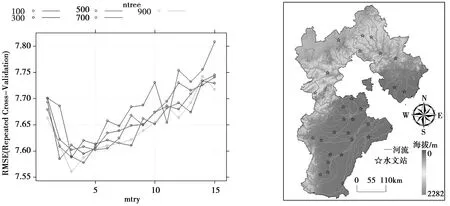
图1 研究区及主要河流分布
1.2 数据来源与变量提取
本文综合再分析产品、卫星遥感数据、地面水文观测资料,具体描述如下:
1)使用的降尺度目标数据为《中国天然径流量格点数据集CNRD v1.0(1961-2018)》,其由GOU等基于VIC(The Variable Infiltration Capacity)分布式水文模型结合地面径流观测资料生成,并证明在全国尺度上的数值精度优于其他开源产品,且保持了空间分布连续性(https://poles.tpdc.ac.cn/zh-hans/news/1f6a8d07-b413-4a3b-875e-32dadca3196b)。
2)水文观测资料。从水文水资源局收集到研究区28个水文站的2018年径流量资料,并以此作为真值。
3)DEM数据。DEM数据由美国联邦地质调查局(USGS)提供的STRM数字高程(DEM)V3.0产品,其空间分辨率为30m,以DEM数据为基础,据此使用SAGAGIS软件平台(https://www.pcsoft.com.cn/soft/205412.html)提取相关地形因子,见表1。

表1 径流量格点降尺度的环境变量
4)Landsat-8 OLI数据。本研究从United States Geological Survey (USGS) Earth Explorer website (https://earthexplorer.usgs.gov)获得2018年遥感影像。先利用ENVI5.6软件中Mosaic工具进行镶嵌处理,再利用(Exelis Visual Information Solutions, Boulder, Colorado)基于24个地面控制点进行几何校正,使每个控制点的均方根误差小于0.5个像素,然后使用FLAASH模块进行了辐射到反射率的转换与大气校。最后,利用Spectral indices extraction工具提取相关植被指数,见表1。
5)土壤和土壤是地表水源涵养的主要控制因素之一,将土壤砂砾、粉砂、黏粒、有机质、平均降水量、气温纳入环境变量集,进而预测潜在水分。该数据由中国科学院资源环境科学数据中心(http://www.resdc.cn/)获得,其空间分辨率为1km,另收集Global-land2020数据(LUCC)。
除站点观测资料外,将其他栅格数据使用ArcGIS工具进行空间提取、投影转换、归一化处理。
1.3 遗传算法
GA是借鉴达尔文自然选择进化论发展而来的最优解搜索算法。GA首先按一定比例选择现有的种群进行新一代繁殖,然后利用交叉、变异等操作产生第二代种群,在此过程中,淘汰适应度( Fitness )低的个体,保留适应度高的个体,并不断重复选择、交叉、变异等操作,直至进化出具有最大适应度的个体作为最优解输出,则终止进化。Scrucca(2013)利用R软件的caret包构建基于GA算法的最优集。
1.4 随机森林模型
随机森林(RF)是基于Boostrap抽样和bagging理论的一种组合器算法,由许多决策树组成,每棵树依赖于独立采样的随机向量值,并且数据中所有树的分布相同。RF建模使用boostrap采样允许袋外数据用于估计一般误差,预测结果是所有聚合预测的平均输出。RF建模需优化两个关键参数:用于生长每棵树的变量数量(mtry)、林中树数量(ntree)和终端节点的最小数量。mtry参数确定每棵树的强度和树之间的相关性,增加mtry还会增加每棵树的强度和树之间的相关性。RF模型性能通过增加树木强度和降低树木之间的相关性而得到改善。在本研究中,RF模型构建与参数优化通过caret包实现。
1.5 降尺度模型检验
为了客观评估GA-RF在粗糙集径流量格点数据降尺度中的应用性,以降尺度前后格点数值与实际水文观测站点值为基本输入,运用纳西系数(NSE)、平均绝对误差(MAE)、均方根误差(RMSE)作为评价指标,两个模型性能,相关计算公式如下:
(1)
(2)
(3)
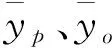
2 结果与分析
2.1 原径流量格点数据统计特征
图2为研究区原径流量格点数据。由图2可知,其空间分辨率粗糙,对局部细节信息刻画不足。利用站点数据进行验证发现,该产品与28个地面观测站点数据具有良好一致性,见图3,其NSE为0.70,MAE和RMSE分别为34.48、48.05mm,该误差在可接受范围内,因此在研究区具有一定可替代性。

图2 河北省原径流格点数据空间分布
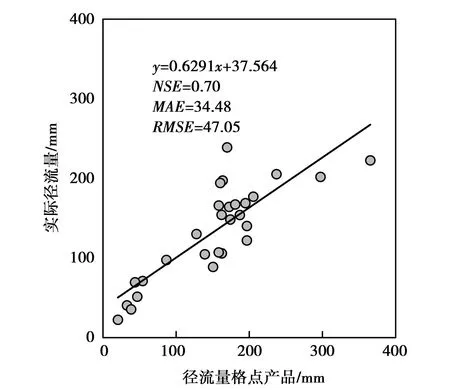
图3 研究区原径流量格点数据与实测径流量散点图
2.2 基于GA算法降尺度因子选择结果
将GA全局变量选择技术应用于28×29的样本矩阵,矩阵值因变量为站点尺度径流量,其他均为自变量,进而检索出径流量格点降尺度模型所需的最优变量。图4中,横坐标为协变量数目或迭代次数,纵坐标为训练精度的度量。由图4可知,当变量数为11时,模型的RMSE达到最小,次数的精度最具可靠性。相应地,此时确定了11个环境变量如下:径流量格点、降水量、气温、海拔、距河流距离、LUCC、地形湿度指数、NDVI、EVI、土壤粉粒、有机质。
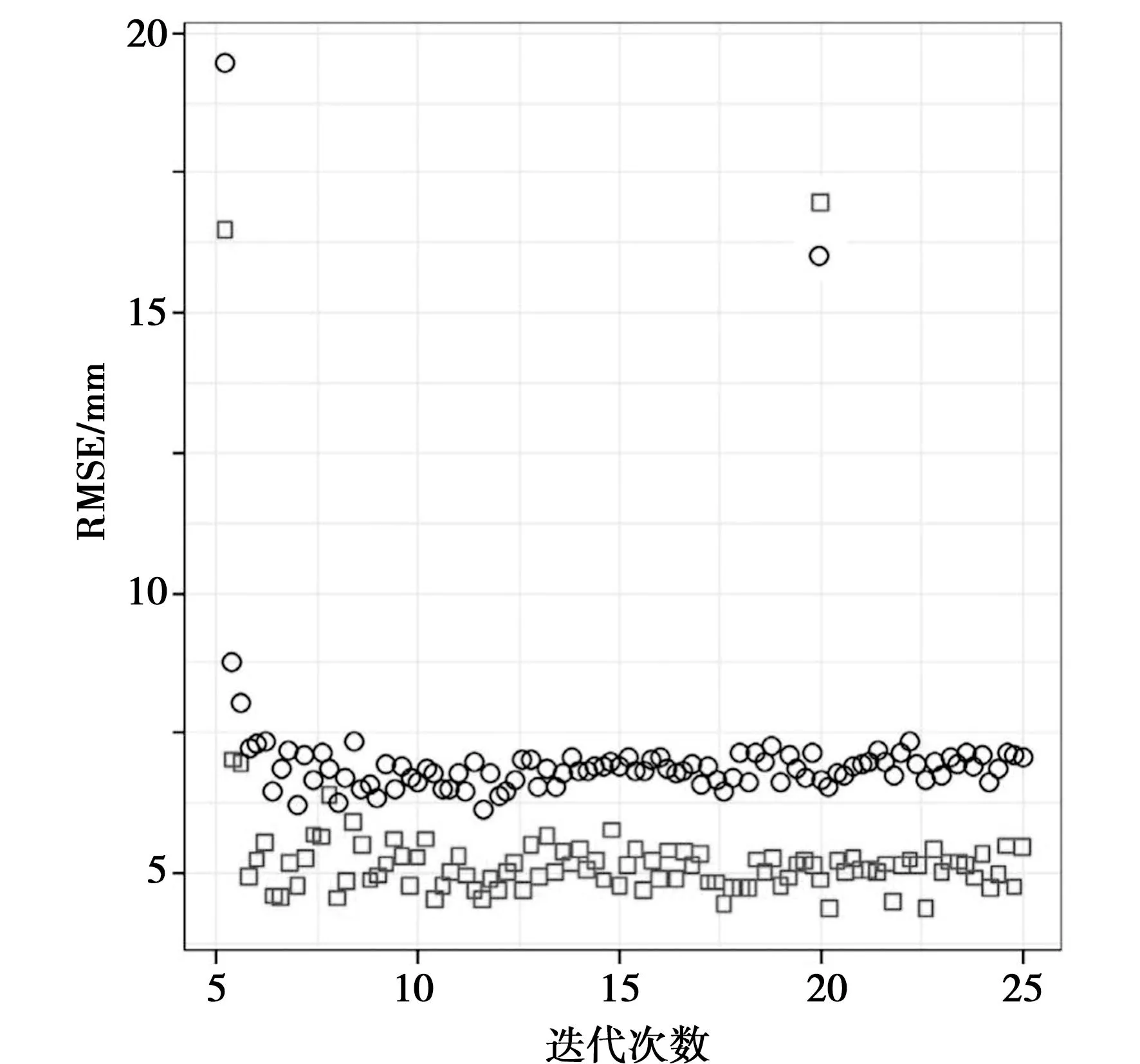
图4 GA算法变量选择迭代图
2.3 RF模型参数优化
尽管相关研究认为RF算法对超参数配置并不敏感,但为了确保模型稳健,使用网格搜索法,对其关键参数进行优化。利用随机抽样方法,将28×29个输入样本随机划分为10份,其中9份作为训练样本,剩余1份为测试样本,进而构建RF模型进行非线性拟合。图5为不同mtry、ntree配置下,RF模型训练精度RMSE的变化特征。由图5可知,这两个参数互相影响且单调性并不同步,最终确认当mtry=3、ntree=700时,模型训练的拟合性能达到最优状态,此时RMSE仅为0.6mm。
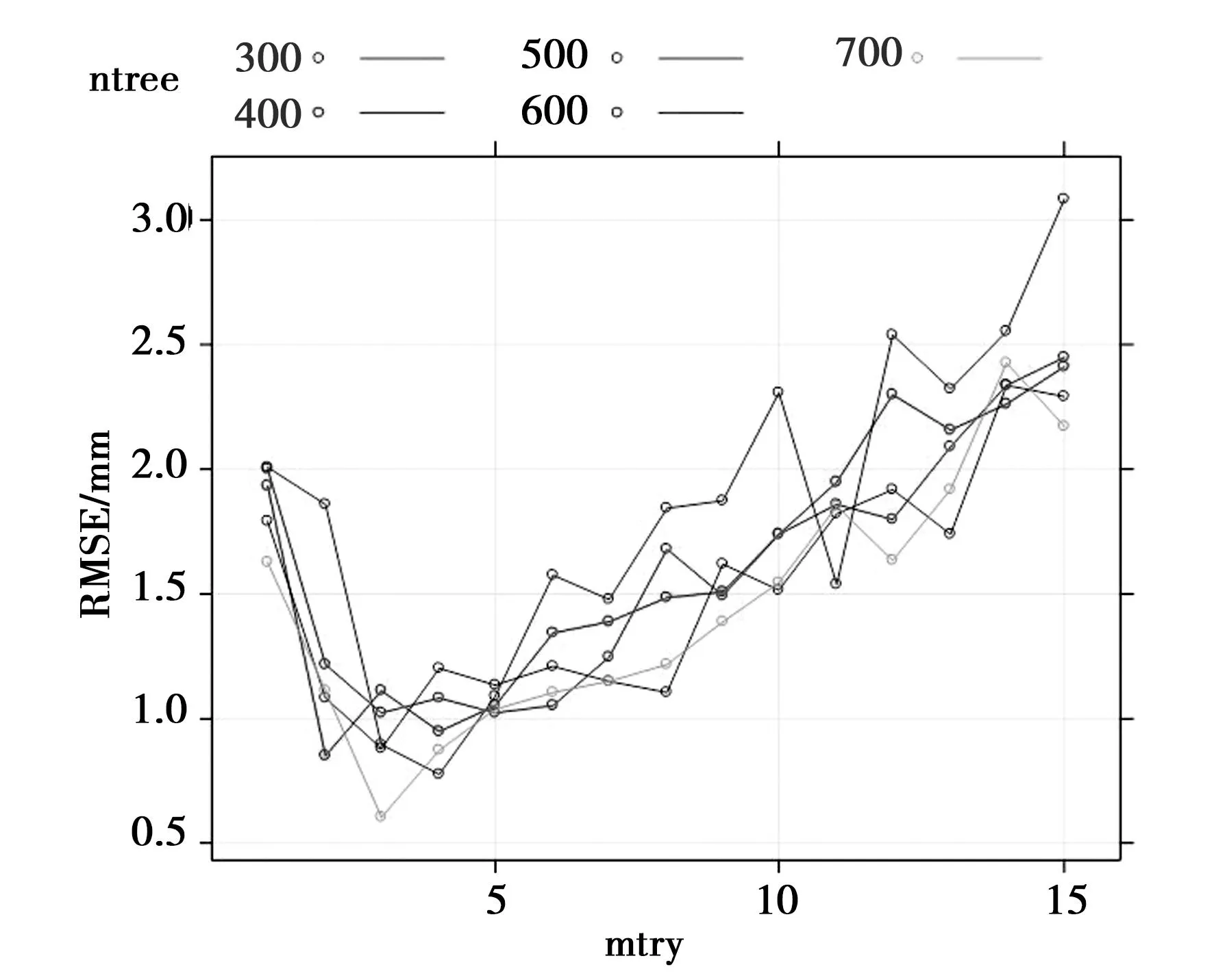
图5 RF模型参数的网格搜索结果
2.4 径流量格点降尺度及其精度检验
将优化后的RF模型代入由11项环境变量组成栅格集,然后进行降尺度空间预测,得到研究区精细化的径流量格点空间分布,见图6。由图6可知,降尺度后,其径流量数值范围介于24~303mm之间,空间栅格统计平均值为223mm,与图2的原数据数值特征一致,表明降尺度的结果集成其表征功能。降水量呈现东多西少、南多北少的格局,以衡水、沧州、邯郸东南部、唐山东南局部地区径流量相对较大,可达250~300mm;石家庄、承德、唐山北部、廊坊、保定等地径流量次之,在150~250mm之间;阴山和燕山地区的张家口、承德北部径流量最少,仅在150mm以下。另外,与原径流量格点数据相比,降尺度后的径流量分布图呈现了细节分布,避免了粗糙集格点锯齿状特征,反映了地形、河流对地表径流深的影响。
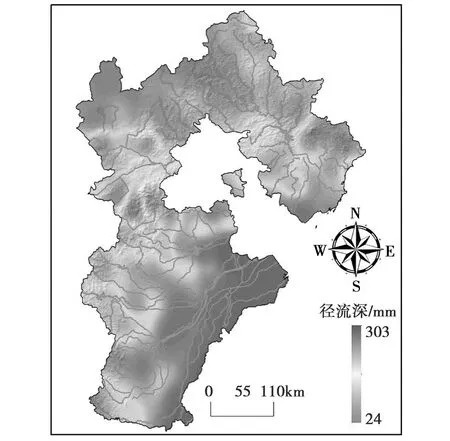
图6 河北省径流量降尺度结果
为了评估降尺度精度,利用站点进行验证,其结果显示降尺度后的精度NSE为0.76,MAE和RMSE 分别为28.39、37.97mm。相对于原始径流量格点数据精度,降尺度后的NSE提升了8.57%,MAE和RMSE 依次减小21.44%、23.92%。见图7。
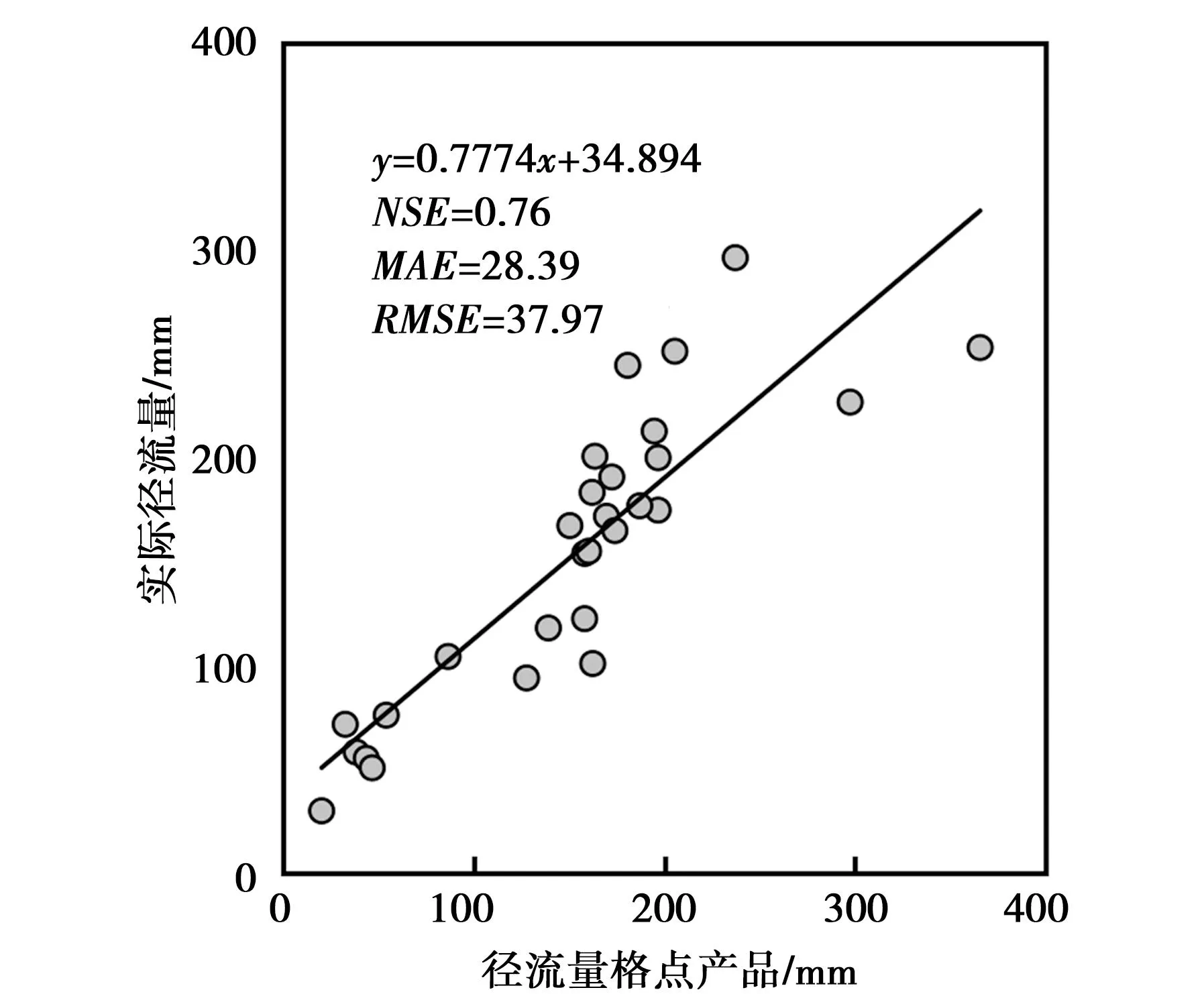
图7 降尺度后径流量格点与地面观测数据之间一致性
3 结 论
粗糙集径流量产品的降尺度研究是水文工作研究的重点方向之一。本文运用GA算法,从高维数据集里选择最小变量集,进而采用RF拟合径流量与环境变量之间复杂非线性关系。结果显示,GA-RF算法将0.25°分辨率的径流量产品降尺度至30m,且不牺牲其本源精度,表明所提出的GA-DNN降尺度方案具有移植性,可为其他区域和类似粗糙水文气象数据的分辨率重构提供新方案。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:58:02
空间科学学报(2021年4期)2021-08-30 08:31:16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
数学物理学报(2018年5期)2018-11-16 05:49:54
水利规划与设计(2017年5期)2017-06-09 08:56:23
太空探索(2016年5期)2016-07-12 15:17:55
新高考·高二数学(2016年3期)2016-05-20 23:47:43
时代英语·高三(2014年5期)2014-08-26 17:01:17
水土保持通报(2014年5期)2014-06-09 08:27:00
湖南水利水电(2014年3期)2014-02-27 14:46:05
