
一种基于随机森林和Light GBM 的房产估价模型∗
2024-04-17 07:29:02冯梓豪刘从军
计算机与数字工程 2024年1期
冯梓豪 刘从军,2
(1.江苏科技大学计算机学院 镇江 212000)(2.江苏科大汇峰科技有限公司 镇江 212000)
1 引言
随着房地产市场化和市场经济体制的发展,房产评估需求迅速增加,近年来国内外有大量学者对房地产评估问题展开了研究,例如:杨灿通过Light GBM 模型对二手房进行评估[15]。Lu等提出了一种基于Lasso和梯度提升回归的组合模型用于评估房价[19]。陈敏等建立了一种神经网络分级模型来对二手房价进行评估[7]。杨磊以特征价格为理论基础构建了二手房价格评估模型,在其中应用了地理信息技术系统技术实现了房产估价[13]。但上述方法在特征选择和运行效率方面还存在改进的空间。
本文的主要工作如下:基于学者Butler提出的房地产价格理论,提出时间特征作为房产价格评估的特征。通过随机森林算法对特征重要性进行排序,剔除对预测值影响较小的特征,再通过网格搜索对模型进行优化,最后使用训练好的模型对房产价值进行预测。
2 模型建立
2.1 随机森林特征选择算法
随机森林算法是在传统决策树算法的基础应用统计学采样原理上构建的一种聚合算法,常用于回归问题和分类问题。随机森林具有高精度的特性,并且具有良好的鲁棒性。它通过结合多个决策树来构建模型,每个决策树的建立都是基于独立抽取的样本。在分裂节点时,它依赖于不纯度指标和袋外数据错误率来做出决策。
传统的随机森林重要特征性度量方法是对每一个特征随即置换并由随机森林对特征置换后生成新的袋外数据进行测试,当特征的重要程度越高,随机森林的预测误差率的变化就会越大,现假设随机森林中的决策树目为Ttree,原始数据集由N个特征,单特征Xi(i=1,2,3…,N)的基于OOB 误差分析的特征重要性度量如下:
1)计算第i棵决策树相应的袋外数据的错误样本数ErrrorOOBi。

3)重复1)、2)步骤得到所有的错误样本以及随机调整顺序后的错误样本。
4)计算所有决策树特征簇Xji置换前后OOB分类误差率的平均变化量:

2.2 Light GBM模型
Light GBM 是由微软DMTK 团队开源发布的,是一个轻量级的GB框架,基于决策树的学习算法,支持分布式。其算法流程如下:
1)初始化n 课决策树,每个训练样例的权重为1/n。
2)训练弱分类器f(X)。
3)设置该弱分类器的话语权β。
4)更新权重。
5)得到最终分类器,表达式如下:
Light GBM 模型使用了直方图做差加速和Leaf-wise 生长策略,降低了模型的运算速度和内存消耗,直方图算法示意图如图1,Leaf-wise 生长策略如图2所示。
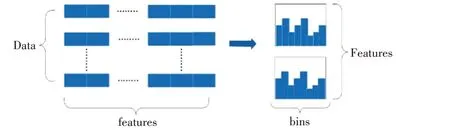
图1 直方图算法示意图

图2 Leaf-wise生长策略
2.3 RF_lightGBM模型
基于Light GBM 的高效率和高准确率以及低内存消耗,选择以Light GBM 建立房产价格预测模型,同时以混淆矩阵计算特征的准确度、精度等指标检验随机森林选择的特征是否有效,然后将经过特征选择之后的数据输入Light GBM 算法进行学习,采用网格搜索优化寻参过程,通过网格搜索得到模型的超参数,Python 提供的scikit-learn 库可帮助找到最合适的超参数。模型如图3所示。

图3 RF_Light预测模型流程图
3 特征选择与超参数调整
3.1 特征选择
特征价格理论是房地产评估领域的重要理论之一,由Ridker 首次引入。该理论认为,房地产作为一种商品,其价格不仅仅取决于其地理位置、建筑质量等单一因素,而是所有特征属性的效用之和。这些特征属性包括房屋的面积、房龄、装修程度、周边设施等等。每一个特征属性都会对房地产的总效用产生影响,从而影响其价格。学者Butler将影响房地产价格的因素进行了整合分类,提出了三类适用的特征变量,包括区位特征,结构特征以及邻里环境。根据Butler 的理论,房产价格可以描述为P=f(L,S,N)。
该方程在特征价格理论公式的基础上将变量分为三类,分别是L-区域特征,S-结构特征,N-邻里环境。
本文在Butler提出的价格理论上,提出假如T-时间特征,则房产价格可描述为P=f(L,S,N,T)。
本文共设定35 个量化指标,其中区域特征如表1所示。

表1 区域特征表
邻里环境如表2所示。

表2 邻里环境表
结构特征如表3所示。

表3 结构特征表
时间特征如表4所示。

表4 时间特征表
将上述特征使用随机森林进行重要度进行排序,得出的排序后的特征如图4所示。
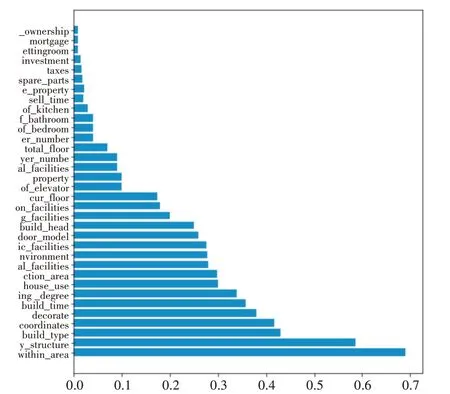
图4 排序后特征
3.2 Light GBM超参数调整
模型的超参数是通过网格搜索和五折交叉验证得到的,本文使用Python 库scikit-learn 中的GridSearchCV 方法来搜索最优超参数。优化了增强迭代次数、梯度增强算法的步长、最大树深、一棵树中最大叶子数、叶子中最小样本数、叶子中最小Hessian和。具体参数如表5所示。

表5 Ligh GBM超参数表
4 实验结果
为保证模型的普适性和在真实场景中的准确性,本次实验使用的数据为公开的房产数据集。
将数据进行数据清理后,共得到63725 条数据,将其按照70%为训练数据,30%为测试数据进行划分。
使用RF_LightGBM 模型对准备好的数据进行了预测,得到了预测价格和实际价格的平均值为2566.7 元,平均相对误差为4.28%。测试集中的大部分误差在0%~15%之间,占比为98.72%。具体的相对误差分布情况如表6所示。
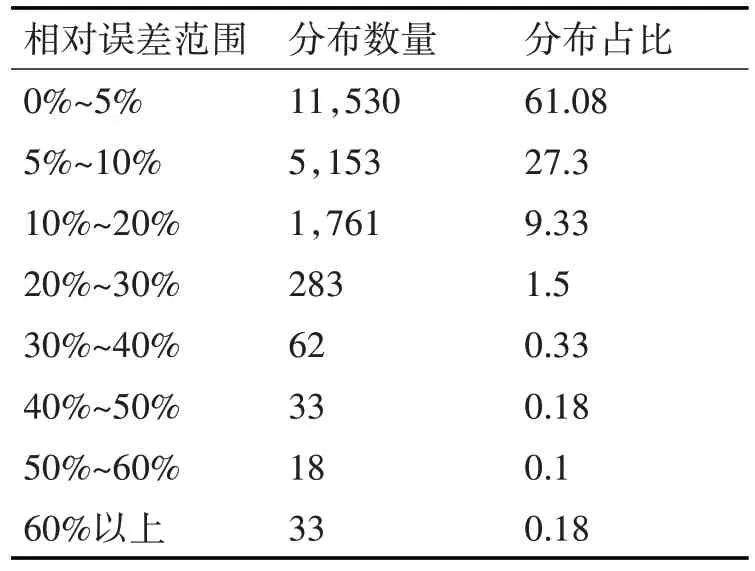
表6 相对误差分布情况表

表7 随机森林超参数表

表8 XGBoost超参数表
本文比较了RF_LightGBM 模型的房产价值评估模型与目前研究或行业中常用的评估方法。本文选取了两种方法进行比较,分别是随机森林模型和XGBoost模型,并给出了这两种模型的参数设定。
为了合理地评价模型的综合性能,本文以平均绝对误差(MALE)和队数均方根差(RMSLE)作为模型的评价指标。MALE 能更好地反映观测值误差的实际情况,而RMSLE 则是用来衡量观测值和真实值之间的偏差,其计算公式如下:
其中pi表示实际的房价,而pi表示模型预测的房价。各模型对比结果如表9所示。
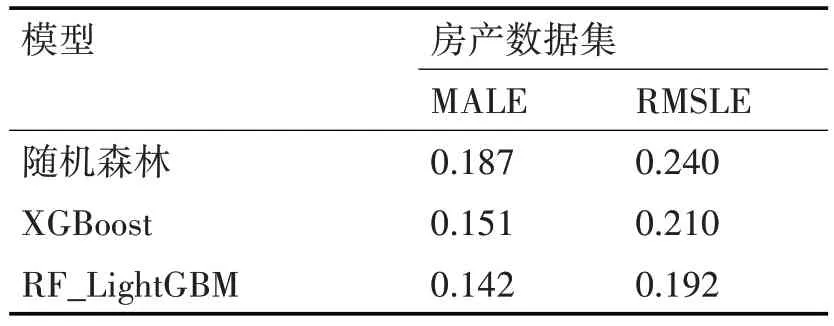
表9 模型结果比对表
三种预测模型得出的平均房价(元/m2)得出的柱状图如图5所示。
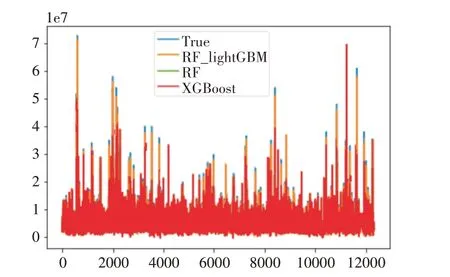
图5 预测房屋均价比较图
从表9 可以看出RF_LightGBM 模型性能明显优于随机森林,XGBoost 等深度学习模型。从图5可以看出RF_LightGBM 模型预测的房屋均价相对于随机森林和XGBoost 模型更加贴近真实数据,且存在偏差较小。
5 结语
随着信息技术的飞速发展,大数据、人工智能等技术为企业和社会带来了前所有的机遇,本文在传统的预测模型上,提出了RF_LightGBM 模型,使用随机森林对特征进行选取和重要度排序,将预测过后的特征数据使用Light GBM 模型进行预测。实验表明,所提模型准确率优于随机森林,XGBoost等学习模型,房产评估结果也更加贴近实际值。
在未来的工作中,结合我国基本国情与政策,通过人文因素,经济环境因素等进一步提取和细化对房产产生影响的因子,提高评估结果的精度和模型的普适性。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
电子制作(2017年23期)2017-02-02 07:17:06
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
西北工业大学学报(2015年4期)2016-01-19 03:31:47
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
