
基于时空分布的基站异常能耗分析方法
2024-04-16 11:36陈志文黄琰奕严展鸿赵永红陈志明
通信电源技术 2024年3期
陈志文,黄琰奕,严展鸿,赵永红,陈志明
(中国移动通信集团设计院有限公司广东分公司,广东 广州 510623)
0 引 言
随着移动通信网络的快速发展,移动业务需求不断增加,无线基站作为网络覆盖和信号传输的基础设施,其能耗问题不仅关系到网络运行的成本,而且直接影响着环境的可持续发展。因此,对基站能耗进行科学、准确的分析和管理尤为重要。如果基站存在异常能耗问题,可能导致网络设备损坏、通信质量下降,甚至影响网络稳定运行。目前,对于基站异常能耗的分析仍缺乏系统的方法,因此文章旨在研究一种有效的基站异常能耗分析方法,以便及时发现并解决异常能耗问题,提高网络运行效率和稳定性[1]。
1 基站异常能耗分析现状
现有的基站主设备能耗数据按天输出,并通过节能任务对基站进行节能操作。与基站网络性能和节电量等已有的多种指标分析相比,对基站设备能耗,特别是基于时间和地理场景的能耗管控,尚未有相关的指标统计。此外,如果能耗管控使用全网统一的标准,可能会放大不同能耗规律和不同场景下的基站异常问题[2-3]。因此,需要利用能耗数据,结合基站相关属性信息,建立合适的基站能耗异常标准,分析基站能耗是否符合标准,以补充基站能耗异常分析的部分空白。
2 基站异常能耗分析方法研究
2.1 基站异常能耗分析方法概述
基站在空间上的场景属性与工作日、休息日的能耗存在一定规律。由于不同场景下的时间属性有所不同,因此文章以某月能耗数据统计各场景的平均能耗,结果如图1 所示。

图1 某月各通信场景平均能耗
文章提出的基站异常能耗分析方法,通过关联基站远端射频单元(Remote Radio Unit,RRU)的能耗数据与基站场景,并增加时间属性,按照一定规律对基站能耗数据进行状态标签标注。同时,使用支持向量机算法训练数据,构建基站异常能耗模型。该模型以历史全年能耗数据作为输入,输出基站的能耗状态,统计模型中各场景的基站状态异常率,并将其作为异常标准值。当新数据输入模型时,模型会输出相应的能耗状态。同时,统计新数据的异常率,并与模型场景异常标准值进行对比,如果新数据的异常率超出标准,则认为该场景的能耗存在异常。此时,模型会输出该场景异常能耗的基站信息,以辅助运营商分析异常原因。为增强模型的适应性,加入场景异常标准值修正机制。根据修正规则,定期或按需更新异常标准值,使其能够不断适应网络结构的变化。
2.2 能耗数据处理及状态标签标注规则
提取某地市某年1 月、4 月、7 月以及10 月的基站主设备的天粒度能耗数据,增加时间属性,并关联工作场景,以统计不同时间属性下的平均能耗和能耗偏离值[4]。
状态标签标注规则为:第一,RRU 能耗为空或为0 时,标为异常;第二,计算每个基站在不同时间属性下的平均能耗和能耗偏离值,以确定能耗偏移度,并判断数据是否异常;第三,引入正态分布,基于能耗偏移度的绝对值,用标签标注不同RRU 平均能耗梯度下的数据,且随机变量x服从一个位置参数为μ、尺度参数为σ的概率分布,概率密度函数为
经分析,单站在天粒度下的RRU 平均能耗均保持在200kW·H 以内,而基站月平均能耗主要分布在20 ~30 kW·H 的范围内。可以将这些基站的平均能耗划分为4 个区间,即平均能耗小于10 kW·H、大于10 kW·H 且小于20 kW·H、大于20 kW·H 且小于40 kW·H 以及大于40 kW·H,4 个区间站点数量平均分布。基于此,将能耗数据划分为4 个梯度,并对每个梯度进行正态分布分析,结果如图2 所示。

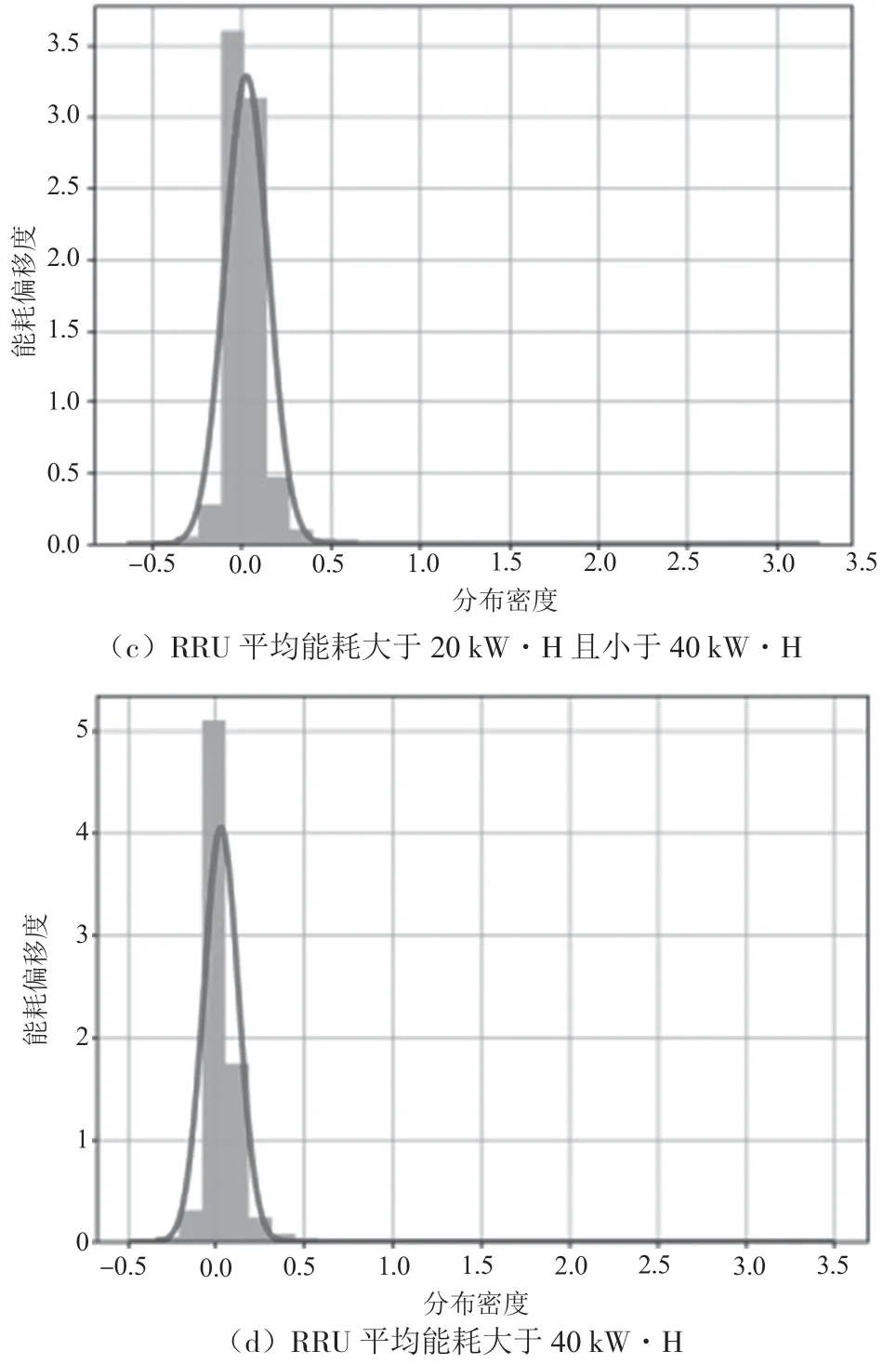
图2 能耗偏移度正态分布曲线
为使模型训练得到尽可能贴合的结果且不过拟合,以能耗偏移度的平均值为对称轴,计算出其95.44%面积,即两个标准差区间两侧横轴上的能耗偏移值,并将其作为判断RRU 平均能耗是否异常的临界值。不同平均能耗梯度下两个标准差的数据如表1 所示,超出能耗偏移度绝对值的标注为异常,能耗数据标注标签示例如表2 所示。

表1 不同平均能耗梯度下两个标准差的数据

表2 能耗数据标注标签示例
2.3 基于支持向量机算法建立基站异常能耗模型
文章构建模型的目标是输出基站异常能耗状态,即判断能耗数据是否异常,属于二分类,因此使用支持向量机算法训练模型[5]。在训练过程中,使用了34 810 条数据,其中标签为正常的数据有28 655 条,标签为异常的数据有6 155 条。为训练模型,采取了一系列的处理措施,包括数据预处理,将自定义函数向量化,对数组中的每个元素进行编码、归一化、拼接数据及特征标准化等。完成数据处理后,建立支持向量机模型,并对模型进行训练、预测,以计算模型准确率。
2.4 统计场景异常标准值
将上年的能耗数据输入基站异常能耗模型,输出全年基站能耗异常状态,统计各场景基站异常状态比例,并将其作为异常标准值,以判断测试数据运用模型的输出结果。例如,经模型输出的状态统计,城区道路场景下的平均基站数为55 342 个,工作日平均异常基站数为6 642 个,休息日平均异常基站数为2350 个,即工作日异常标准值为12.00,休息日异常标准值为4.25。
2.5 异常能耗检测与定位
将某地市某月的数据作为测试集,增加时间属性、场景、平均能耗以及能耗偏离值4 个指标。能耗数据输入模型后,输出测试数据的状态结果,如表3 所示。
由表1 可知,输出异常的并不是基于原训练集的规则,而是根据模型的规律自动输出,即非人为制定的规则,异常值为0,正常值为1。
根据模型输出的状态结果统计不同时间属性下的异常基站数、异常率等数据。从工作日异常率超出异常标准值的场景中,输出了具体的异常站点。通过对这些异常基站的分析可知,出现异常次数最多的基站为基站C,高达28 次,基站整月异常率高达93%。与历史月份相比,该基站最低异常次数为2 次。同时,对比历史月份的平均能耗值发现,基站C 的能耗增加了一半以上。因此,基站C 异常率的突增可能是导致该场景超出异常标准值的主要原因。通过查看基站C 的能耗数据发现,在月中某日该基站的能耗突然翻倍增加,导致整个月的平均能耗值升高,能耗偏离绝对值也相应增大,故模型识别为异常。由此可见,基站异常能耗模型能够在实际生产能耗数据中识别出异常场景,为实际的能耗监控管理提供了辅助手段。
2.6 场景异常标准值的修正
由于网络环境和能耗情况会不断变化,场景异常标准值不能一成不变。为更准确地反映基站异常能耗情况,需要按实际网络和能耗情况修正模型。文章提出一种以一年为时间单位的修正方法,首先利用场景异常标准值与月粒度的异常率绘制曲线,并建立曲线的趋势线;其次通过计算二次多项式,得到趋势曲线的二次函数表达式,并对该函数进行一阶求导,得到异常率浮动的幅度;最后将该导数作为场景异常标准值的修正系数,用原异常标准值乘以(1+修正系数),即可更新成为未来一年的异常标准值。
3 结 论
文章通过建立基站异常能耗模型,统计场景异常标准值,并将其与新数据中的场景机房异常率进行比对,从而判定异常能耗场景,输出场景中的异常基站清单。该方法不仅为需要重点保障的通信场景提供了数据基础,还可帮助操作人员查明基站能耗异常的原因,核实异常情况。同时,通过修正机制不断更新异常标准值,以适应不断变化的网络环境。在判断异常率是否异常时,允许在可接受的范围内存在异常能耗,但模型只会关注超出制定标准的异常率。此外,训练集的能耗数据时间、基站区域范围、规则制定都可根据应用方的需求和经验进行动态调整,以确保模型适用于应用方的真实情况。
猜你喜欢
家庭医药·快乐养生(2023年4期)2023-04-16
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
大经贸(2019年9期)2019-11-27
华人时刊(2018年15期)2018-11-10
探索科学(2017年4期)2017-05-04
中国交通信息化(2016年8期)2016-06-06
移动通信(2015年17期)2015-08-24
经济与管理(2015年4期)2015-03-20
