
基于视觉人体姿态识别的人机交互机器人课程教学研究
2024-04-16 10:10李宪华徐玉杰朱延松
湖北第二师范学院学报 2024年2期
李宪华,徐玉杰,胡 坤,朱延松
(安徽理工大学 a.人工智能学院;b.机械工程学院,安徽 淮南 232001)
机器人是一种高度复杂的机械系统,它在人类控制下或能够自主地执行任务。机器人的类型功能具有多样性,从日常自动化作业到在人类难以企及的环境中执行复杂和危险的任务。机器人部署在制造业、医疗、农业等诸多行业。[1]经过精心设计,机器人的执行行动可有高精度、长时间持续运行和高效率的特性,从而协助增强人类的能力,拓展人类可以涵盖的领域。在当今机器人教育领域,人们正在积极合作,共同打造一个综合性的且涵盖多学科的研究领域,试图将理论基础与实践经验结合起来,使学生具备更全面的知识技能。这涉及到机械工程、计算机科学、人工智能和控制系统等多个知识领域的交汇和融合,通过建立一个有凝聚力的机器人学学科,实现培养出既具有理论见解又具有实践才能的毕业生的目标。
目前机器人教学尚存在一些障碍。其中一个关键的障碍是理论概念和机器人实操所需的实际技能之间的差距。学生在从理解抽象理论过渡到在现实场景中运用这些理论时,经常会遇到困难。这一差距显示了将实践练习、模拟和互动学习方法纳入机器人课程的重要性。[2]此外,机器人技术快速发展也给课程开发带来了挑战。随着机器人技术的发展,教育工作者必须不断更新课程材料,以反映最新的趋势和创新,他们需要在提供基础知识和了解前沿发展之间取得平衡。
本文提出了一种以人体姿态检测算法为基础的人机交互教学方案。通过这种教学方法,提高学生的参与度,它可以弥合理论与实践之间的鸿沟,鼓励学生深入探究机器人学领域中人机交互的动态和不断演化的模式。这一方法激发了学生对机器人技术的学术兴趣,为他们在塑造科技和自动化领域未来的卓越表现做好了准备。
1 姿态检测算法
本文所运用的人体姿态检测算法属于计算机视觉领域,它的主要目标是从图像或者视频流中精确检测到人体关键点位置。目前这一技术在多个领域中发挥重要作用,徐广等用人体姿态估计模型分析评估太极拳运动过程,改进现有运动问题、激发练习者的兴趣,提升他们的体质健康。[3]Fu等人提出用人体姿态检测算法解决各种场景下健身动作的识别问题,同时评估用户的运动姿势,提升用户的运动训练质量。[4]
人体姿态检测算法根据所检测的关键点维度分类,可以分为2D和3D检测两大类。2D姿态检测专注于获取图像或者视频流中的二维人体关键点坐标,而3D姿态的检测则在2D姿态的基础上增加了深度信息,进而获取人体关节的三维关键点坐标。根据算法的检测对象还可以分为单人姿态检测与策略更加复杂的多人姿态检测。根据算法策略又可以分为基于关键点检测与基于关键点回归两类。[5]
在2D多人姿态检测中,算法可以根据工作方式分为自上而下和自下而上两大类。自上而下的方法首先检图像或者视频中人体的存在和大致位置,这相当于目标检测,一旦检测到人体,算法将使用包围框或者掩膜将检测目标覆盖,在此基础上估计人体的关键点和具体姿态。在3D单人姿态检测中,算法可分为单阶段和两阶段两种方法。单阶段方法通常将人体姿态检测视为一个端到端的任务,从输入图像中估计3D姿态信息直接回归3D姿态;两阶段方法是指采用两个独立的模型或模块,一个用于2D关键点检测,另一个用于3D姿态估计。这种方法的基本思想是首先在输入图像中检测2D关键点的位置,然后将这些2D关键点的信息用于估计3D姿态。如图1所示为人体姿态检测算法的分类。
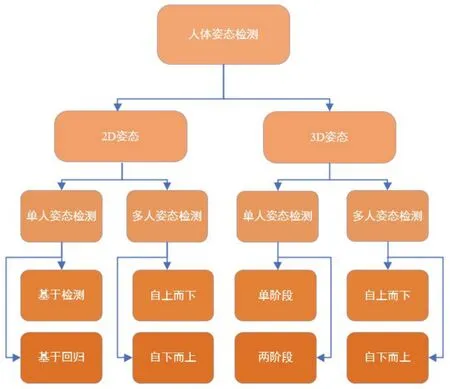
图1 人体姿态检测算法的分类
在人机教学交互领域,满足实时性要求是至关重要的。为实现这一目标,通常采用自下而上的人体姿态检测算法,这些算法专注于直接检测人体关键点,以便在多人场景中提供实时的学生与计算机之间的互动和反馈。不同类型的人体姿态检测算法根据其在不同任务中对准确性和实时性的侧重点及平衡而进行分类,提供了多种策略选择。
2 获取姿态数据
本文运用的人体姿态检测算法是依靠训练精心搭建的神经网络模型来实现所要完成的目标任务,即检测人体关键点。而模型的训练离不开大规模人体姿态数据集。目前有许多可供模型训练、验证和测试的2D人体姿态数据集,且每张图片都标注了丰富的信息,例如人体关键点的位置,关键点个数,是否存在关键点遮挡等。而大多数现有的3D人体姿势数据集都是使用MoCap系统在实验室环境中捕获的,由于捕获数据环境的背景,捕获图像的视点以及光照情况受到限制,会对模型的泛化性能造成一定的影响。
2.1 人体姿态数据集
MSCOCO数据集是微软开发维护的大型图像数据集,数据集标注类型对应任务包括物体检测、关键点检测、实例分割、stuff分割,全景分割人体关键点,人体密度检测等。它包含对25万个人体的关键点标注,提供的注释呈现了二维人体的17关键点。如图2所示,这些图像说明了各种人体姿势、不受约束的环境、不同的身体尺度和遮挡模式。MSCOCO系列中的大多数人都是中型和大型的。

图2 MSCOCO数据集图片展示
Human3.6 M数据集是目前最大的公开3D人体姿态估计数据集。它包含360万张3D 人体姿态和对应图像,涉及11名受试者(5名女性和6名男性),执行7项日常活动,例如吃饭、坐着、走路、打电话和拍照等。使用RGB摄像机从17个不同的视角拍摄视频。2D姿势可以通过使用已知的内在和外在相机参数投影来获得,数据集标注的人体骨骼模型共有16个关键点。图3显示了Human3.6 M 数据采集过程。

图3 Human3.6 M数据采集过程
2.2 采集设备MoCap系统
MoCap(Motion Capture)系统是一种用于捕捉和记录三维运动的技术系统,能够用于人体姿态数据的采集。[6]系统工作的时候,传感器以特定频率(fps 60-1000)定位空间中运动的反光点,并在时间轴上连续记录下反光点3D坐标。在空间定位采集点坐标,理论上只要三个摄像头同时捕获到采集点即可,但常见MOCAP摄像头数量组合为8,12,16,24,32。因为实际工作中情况会复杂一些,比如采集点在被动态连续追踪过程中,会存在半遮挡或全遮挡的情况,摄像机数量的增加可以增大有效动作采集空间,提高动作数据质量。图4所示是MoCap系统采集点坐标过程。

图4 MoCap系统采集点坐标
3 数据预处理
3.1 去噪和平滑处理
数据平滑处理在模型训练前是一个常见的数据预处理步骤,有助于提高数据的质量和稳定性,从而改善模型的性能和泛化能力。[7]一些平滑滤波器可以帮助模糊图像,从而减少噪声的影响。图5中a图所示是在图像中添加噪声点以模拟实际场景中的图像干扰,图5中b图所示是图像经过中值滤波处理后的结果,中值滤波是一种非线性滤波方法,它可以有效地去除图像中的噪声点,而又不损害图像中的边缘信息。

图5 图像去噪和平滑处理
3.2 对比度增强
在图像获取过程中,由于过曝、欠曝、遮光或者散射等原因,影响图像的亮度和对比度,进而可能会影响网络模型对于局部细节的捕捉提取,调整RGB图像三通道的像素直方图呈均匀分布,能够显著增强图像的对比度,使细节更清晰可见。[8]它有助于将不同亮度级别的区域更好地分离开来,从而提高图像质量。图6中b图所示是a图上RGB图像的像素直方图,d图是经过均衡处理后RGB图像的像素分布直方图,c图是均衡处理后的图像效果,由图上对比可见,直方图均衡处理后,图像的对比度有了明显提高。

图6 图像对比度增强
3.3 去除遮挡和背景
在一些特定任务中,为了使算法可以更容易地关注主要的对象部分,在将图像数据喂入网络前,去除目标对象以外的遮挡和背景减少干扰,这有助于提高计算机视觉系统的对象识别准确性。如图7中a图所示,在人脸识别、表情分析和面部检测等应用中,可以使用肤色分割算法辅助识别图像中的人脸区域,达到b图的视觉效果,通过在图像中检测肤色区域,可以更容易地定位人脸。

图7 去除图像背景
4 姿态估计算法
在人机交互机器人课程教学中运用人体姿态检测算法,为了方便搭建平台,使用单个相机获取视频流,进行2D姿态估计,考虑到交互人员较多,故所选算法需要能够进行多人姿态检测,并且人机交互的实时性也十分重要,而自上而下的算法在多人检测中需要先确定人物区域,然后在这些区域中进行关键点识别和拼接。这种方法需要更多地计算资源和时间,会对实时性产生一定影响。自下而上的姿态检测算法通常相对于自上而下的方法在实时性方面更有优势,因为它可以在不需要明确定位人物位置的情况下,直接从图像中提取所有关键点信息。综上所述我们选用Openpose,一种非常受欢迎的2D多人姿态检测算法,它使用卷积神经网络(CNN)来检测人体的关键点。如图8所示,在主干网络提取浅层特征后,分别将提取到的特征流入两条支路网络中,进行多阶段回归关键点。每个阶段结束,将两条支路上的特征与浅层特征融合,以便提取更多潜在有用的特征信息。最后将输出特征图,映射到原图尺寸大小,通过非极大值抑制的方法归回关键点,再通过部分亲和场计算有拼接关系的两类关键点的拼接置信度,通过匈牙利算法完成关节点的配对拼接选择,最终获得完整的2D人体姿态骨架。[9]

图8 Openpose网络框架
5 人机交互教学
5.1 人体关节角度的获取
模型训练完成后,可在笔记本电脑上运行,图像采集设备与电脑相连,将捕捉到的实时图像画面传输给训练好的模型即可实时监测出人体关键点,以便进一步获取相关数据。如图9所示,人体姿态被相机采集获取关键点,其中相机坐标系被设为固定坐标系,肩部被设为基坐标系,采集数据过程中,需要保持相机与人体正对,确保采集到所需的计算参数。首先,通过模型的实时监测,可以输出肩部、肘部和腕部在图像坐标系下的二维像素坐标,再结合捕获图像的尺寸大小推算人体上臂和前臂的实际长度,肩部坐标系下肘部的二维坐标值以及肘部坐标系下腕部的二维坐标值。根据这两组坐标值和捕获图像的尺寸大小,计算出上臂和前臂的投影长度,根据所推算的肢体实际长度和投影长度,即可通过肩部坐标系和肘部坐标系还原肘部和腕部的第三维度坐标,最终根据已求得的信息计算出肩部外收、内展角度,肩部前屈、后伸角度以及肘部弯曲角度。
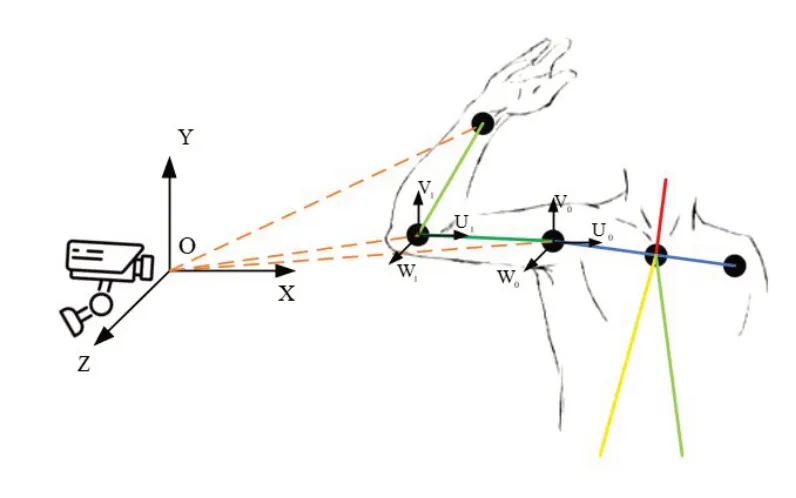
图9 关节角度的获取
5.2 人机交互的实现
模型的实时运行能够实施检测出人体运动的上述关节角度,通过TCP发送关节角信息到机械臂,完成对人体姿态的高度复现,从而实现人机交互。在学生与机器人互动的过程中,姿态数据被不断地捕获和分析,如图10 所示,模型输出的姿态信息被用于控制机器人的动作。[10]这种互动性的教学方法具有多方面的优势。首先,它使学生能够将抽象的理论知识转化为具体的实际操作。透过实际操控机器人,学生得以亲身体验姿态和控制的概念,进一步加深对这些概念的重要性和应用的理解。
其次,互动性的提升使学生能够实时观察自身动作如何对机器人的行为产生影响。这种直观的反馈机制激发了学生的学习兴趣和积极性,因为他们能够迅速察觉到自己的付出所带来的效果。学生可以尝试不同的姿态和控制方式,观察机器人产生的不同反应,从而更深入地理解姿态和控制的概念。
最后,通过编写代码来实现不同的机器人行为,学生进一步巩固了他们的编程和控制能力。他们可以编写程序来指导机器人执行特定的任务或动作,这不仅提高了他们的计算机编程技能,还培养了解决实际问题的能力。总的流程如图11所示。
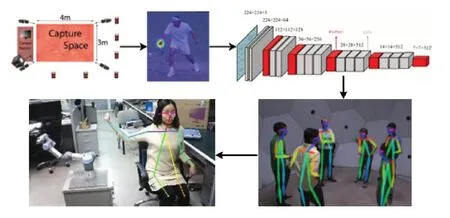
图11 人机交互总流程图
通过参与项目设计和展示,学生将姿态识别技术应用于实际的机器人任务中,培养了他们的创造力和实际应用能力,使他们更具竞争力。虚拟人体姿态识别技术的引入还激发了多学科交叉的学习氛围。学生不仅学习机器人学的原理,还能了解深度学习、传感技术等多个领域的知识,拓展了他们的学科视野。
5.3 人机交互教学的优点
这种方法有助于促进实践性教学与概念转化的融合。通过利用深度摄像头和传感器捕获学生的姿态数据,将那些抽象的理论概念转变为具体的操作和实际体验,从而实现了理论与实践的紧密结合。这种实际操作有助于学生更深入地理解复杂的概念,并将课堂学习与实际应用相互融合。
人机交互互动性的增强能够激发学生的积极性和兴趣。学生通过自己的姿态变化实时影响机器人的动作,直观地看到其动作如何对机器人产生影响。这种实时的视觉反馈激发了学生的好奇心,使他们更愿意参与课堂活动,提高了学习的主动性,且有利于强化学生的编程和控制能力。学生将自己编写的控制代码与实际目标动作进行比较,进一步强化了他们的编程和理解能力。这种对照的编码练习不仅巩固了理论知识,还提供了实际检验的机会,让学生更加直观地理解机械臂的控制。
基于视觉人体姿态识别技术的人机交互教学具备跨学科综合能力培养的潜力。人机交互教学涉足多个学科领域,包括但不限于机器人学、人工智能、深度学习等。通过参与这种高度综合性的学习,不仅有助于学生深刻理解特定领域的知识,还能够培养其跨学科思维和综合能力,为未来解决复杂问题做好充分准备。
6 结论
综上所述,基于视觉人体姿态识别的人机交互教学不仅为机器人学教育带来了创新,同时也为学生提供了理论与实践相结合的学习方式。当前,国内教育体系相对滞后,适应技术变革能力有待提升。这表现在机器人领域的发展速度迅猛,但教材和课程往往滞后于最新进展,从而限制了学生对最新技术的熟练掌握上。此外,机器人教育过于偏重传统工程技术,相对较少涵盖人工智能等前沿领域。学生的跨学科背景和实践经验有限,这也影响了教育质量的提升。为了解决这些问题,需要加强教师的培训,不断更新教材,优化资源配置,并引入创新的教学方法和多元的评估手段,以更好地培养具备前沿知识和实践能力的机器人人才。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
中学生数理化·中考版(2022年12期)2022-02-16
大科技·百科新说(2021年10期)2021-12-31
今日农业(2021年8期)2021-11-28
基层中医药(2021年5期)2021-07-31
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
特别健康(2018年3期)2018-07-04
中国卫生(2014年2期)2014-11-12
