
大数据发展与区域创新耦合协调的时空演变特征分析
2024-04-13 02:10袁嫚
区域金融研究 2024年1期
袁 嫚
(南京理工大学紫金学院,江苏 南京 210023)
一、引言
随着现代信息技术的不断进步,大数据已从纯粹的技术话题演变为经济发展和社会治理的核心议题。2014 年“大数据”首次出现在我国《政府工作报告》中,2016年“十三五”规划提出实施国家大数据战略。据《中国大数据产业发展报告》显示,2019 年我国大数据产业规模达到8000 亿元,2021 年大数据产业规模已突破1.3万亿。国家大数据战略等重大举措在促进创新方面的效应也逐渐显现,大数据已成为驱动社会发展与区域创新的重要动力。
在现实环境下,大数据发展与区域创新之间可能存在着明显的“期望缺口”,即二者的协调程度可能远低于现实期望的水平。在此背景下,本文从大数据发展与区域创新的耦合机制出发,通过选取相关指标,利用熵权法测算2011—2021年30个省份大数据发展综合指数和区域创新综合指数,并对其耦合协调等级进行评价,探究耦合协调关系的空间集聚特征及其空间分异的影响因素,旨在揭示我国大数据发展与区域创新协调发展的现状特征和演变趋势,明确二者协调发展的驱动因素,并据此提出优化策略,为理性认识二者的协调关系、促进二者实现有效耦合提供科学参考,同时也启发更多的研究者和实践者关注这一领域,共同为我国在全球大数据应用和区域创新领域的持续健康发展做出贡献。
二、文献综述
随着大数据发展研究的深入,学者们从不同角度对其内涵进行了界定。大数据发展是指互联网、数字平台等数据基础设施产生的数据资源通过大数据分析手段实现价值增值(谢康等,2020;王欣亮等,2023)。大数据产业是指与大数据有关的数据采集、存储、价值提炼等经济活动的集合,属于新型电子信息产业(刘倩,2019)。目前,关于大数据发展的相关研究主要涉及三个方面。一是大数据发展与实体经济、技术创新等方面的实证研究,如李成刚(2020)利用面板数据模型分析大数据发展对实体经济的提升效果;李远刚(2021)利用主成分分析法和熵权法对我国中部6 省区域大数据与实体经济的融合水平进行测度分析;金芳等(2021)利用固定效应和中介效应模型研究大数据对绿色技术创新的影响和机制;戴艳娟等(2023)基于国家大数据综合试验区的准自然实验研究大数据发展对企业数字技术创新的影响。二是关于大数据发展方面的理论研究,如李娜(2015)基于大数据内涵,从理论层面探讨大数据对经济社会发展的影响以及大数据推动经济社会发展创新的路径;李涛和高良谋(2016)主要对大数据时代下开放式创新发展的趋势进行理论分析。三是大数据产业的相关研究,如大数据产业对区域科技创新发展的作用机制分析(刘倩,2019);中国省域大数据产业与金融集聚耦合协调研究(庞路静和张目,2020);大数据产业与高技术制造业耦合协调及影响因素研究(蔡志强和朱紫娟,2023)。关于大数据发展与区域创新二者相结合的研究甚少,在相似研究中,刘倩(2019)主要从理论层面阐述大数据产业对区域科技创新发展的作用机制,金芳等(2021)则主要侧重于大数据影响绿色技术创新的效应及机制分析,均未涉及大数据发展与区域创新的耦合协调关系。
综上,相关研究主要涉及大数据发展对实体经济、科技创新等社会经济指标的效应研究,在耦合协调研究方面也主要以大数据产业为研究主体,较少涉及大数据发展为研究主体的耦合协调研究。实际上,大数据发展与区域创新可能存在相互作用关系:一方面,大数据为区域创新提供了基础和保障,能够驱动产业变革和核心技术创新(刘倩,2019),另一方面,产业结构转型升级的迫切性能够推动以大数据为代表的新知识、新技术的进步与发展,而国内学术界缺少关于二者的耦合协调机制和耦合协调现状、演化特征、驱动因素等方面的系统化分析。
鉴于此,本文的创新主要体现在研究视角和研究方法等方面。在研究视角上,将大数据发展与区域创新相结合,从综合性视角系统分析二者的耦合协调机制、耦合协调的分布特征和演变趋势,为理性认识二者的协调关系、促进二者实现有效耦合提供科学参考。在研究方法上,借鉴“耦合”的概念,建立二者的耦合协调度模型,并将空间自相关模型应用于耦合协调度的空间分布特征研究,从时间和空间两个角度,探讨二者的耦合协调关系、时空分布格局及其动态演进特征,为二者的协同发展研究提供方法借鉴。
三、大数据发展与区域创新耦合机理
在当前信息时代的背景下,大数据发展与区域创新具备良好的耦合协调优势,并呈现出互动融合发展的趋势。一方面,大数据发展能够促进区域创新,具体表现在大数据资源、大数据平台和大数据技术能够为区域创新提供创新要素、创新载体和创新空间。另一方面,区域创新能够驱动大数据发展,具体表现在区域创新环境、区域创新人才和区域创新产业为大数据发展找准战略定位、输送核心科技人才,使大数据技术开发出更多的应用场景,进而为大数据技术拓宽发展平台、推动大数据核心技术研发、拓展大数据发展空间。
(一)大数据发展促进区域创新
大数据资源为区域创新提供创新要素。不同于劳动力、资本等生产要素,大数据的低扩散成本、高扩散速度使其具备天然的流动属性,同一数据可供不同空间的使用者使用,并且使用者越多,数据的利用效率越高。高效率的数据共享加快了创新主体获取创新资源的速度,提高了创新主体整合数据资源的便捷性,使得信息共享和实时交互成为可能,有助于创新主体在创新活动中提高创新效率。
大数据平台为区域创新提供创新载体。一方面,以大数据技术为基础搭建的大数据平台能够连接企业的产品设计、生产、销售等环节,使企业内部形成高度互联互通的网状结构。企业通过与外部及时进行数据交流,获取更多的决策信息和创新数据,挖掘和利用大数据的潜在价值,降低内部创新的成本和风险(李涛和高良谋,2016)。另一方面,企业将高层次创新人才通过大数据平台汇聚到同一个开放式环境中,促进了不同领域的创新合作,为区域创新奠定了智力基础。
大数据技术为区域创新提供新的发展空间。一方面,数据的泛化能够弱化企业的边界,不同企业或组织通过互联网聚集在一起,利用多样的数据技术共同推动某个创新项目,使不同企业或组织之间的交互更加强烈,为区域开放式创新带来了新的发展空间(李涛和高良谋,2016)。另一方面,不同于农业技术、工业技术等生产技术,大数据技术的扩散速度更快、迭代周期更短(Nambisan,2017),数字技术加速向传统产业领域融合渗透,加快产品、工艺、服务等的数字化和智能化,推动产业价值链持续向高端迈进(Kumaraswamy et al.,2018),加速了产业的转型改造,使得区域创新突破新的发展空间。
(二)区域创新驱动大数据发展
区域创新环境为大数据技术提供发展平台。区域内的创新环境,如技术创新、政策创新可以为大数据发展提供更加有利的发展环境,帮助大数据发展找准战略定位,避免大数据战略成果的低效建设和盲目发展。目前我国大数据战略处于从追随者到引领者的过渡期,地方大数据战略实施存在建设失当的倾向(李后卿等,2019),区域创新政策为地方大数据战略的发展方向提供指引,使大数据技术发展精准服务地方经济,进而引领大数据精准高效发展。
区域创新人才推动核心数据技术的研发与进展。区域创新人才的流动可以为大数据技术提供各个领域的专业人才,为大数据产业发展输送高科技人才,推动核心数据技术的精准开发与深度挖掘。政府、企业等主体的相关科技部门往往集聚了大量高技术创新创业人才,这部分人才主要为业务部门提供技术服务,熟悉大数据技术的开发与应用,间接增加了大数据产业产出规模,提高了大数据发展水平。
区域创新产业能够拓展大数据的发展空间。一方面,创新产业的发展,如元宇宙、高端制造等新兴产业为大数据技术开发出更多的应用场景,拓宽了大数据技术的发展空间。另一方面,传统产业的转型升级需要大数据资源作为基础和保障,也需要大数据技术的助力和支撑,这反向驱动了面向多产业多需求的大数据技术的开发,为大数据发展拓展空间。综上,二者的耦合机理如图1所示。

图1 大数据发展与区域创新耦合机理
四、指标体系构建与模型设定
(一)指标体系构建
学者从不同角度对大数据发展的内涵进行剖析,其所构建的大数据发展指标评价体系也不同。李成刚(2020)、金芳等(2021)主要依据我国2015年《中国信息化发展水平评估报告》对信息化发展水平进行测度,选取网络就绪度、信息通信技术应用指数和大数据应用效益指数等维度构建大数据发展指标体系;王欣亮等(2023)将大数据发展的内涵界定为以互联网等数据基础设施产生数据资源,通过数据挖掘和分析为政府、商业和居民提供应用价值,并从数据基础设施和数据应用能力两个维度构建大数据发展指标体系。本文主要参考王欣亮等(2023)对大数据发展内涵的界定,选取数据基础设施和数据技术应用两个维度作为一级指标。在二级指标的选取上,综合相关研究对指标选取的经验,分别从传统网络设施和新型数字设施、大数据产业投入和大数据业务价值两个层面评价数据基础设施和数据技术应用,依据客观性、可比性、可获取性等原则选定二级指标作为数据基础设施和数据技术应用的具体衡量指标,最终构建的大数据发展指标体系如表1所示。
根据经济学理论,区域创新是指特定地域范围内发生的所有创新活动和创新成果的总称,包括创新环境、创新主体、创新网络、创新活动等。在区域创新指标体系的构建上,主要参考刘倩(2019)、杨光明等(2023)的研究,选取创新投入和创新产出两个维度作为一级指标,同时遵循客观性、可比性、可获取性等原则,选取相应的二级指标作为创新投入和创新产出的具体衡量指标。构建的区域创新指标体系如表1所示。
国内大数据技术的发展主要从2011 年开始(蔡志强和朱紫娟,2023),因此本文选取2011—2021 年我国30个省份(由于西藏和港澳台数据较难获取,因此未涵盖西藏和港澳台数据)作为研究样本。二级指标的数据主要来源于2012—2022 年各年份《中国统计年鉴》和《中国高技术产业统计年鉴》,个别指标缺失值利用相邻3 年的平均增长率计算得到的估计值来代替。
(二)模型设定
1.综合评价指数模型。依据所构造的综合评价体系测算2011—2021年30个省份的大数据发展和区域创新综合评价指数。以大数据发展指标测算为例,由于所选取的二级指标较多,本文利用熵权法确定各项二级指标的权重,在此基础上采用线性加权法计算得到2011—2021年各省份的大数据发展指标的综合得分,计算步骤如下:
第一步,构建原始矩阵xij,并将原始数据进行标准化。由于各指标的量纲不同,需要对原始数据进行标准化处理以消除量纲的影响,对于正向指标的标准化处理方法如下:
其中,xij表示第i个指标在j省份的原始数值;min(xi)和max(xi)分别表示第i个指标在所有省份中指标值的最小值和最大值;xij'表示xij经过标准化之后的矩阵。
第二步,将标准化后的数据进行平移得到xij''。由于标准化的各项指标数值中均有一项为0,为保证后续的计算,进一步将标准化之后的各个数值xij'增加0.0001,平移得到xij''。
第三步,计算第i个指标下j省份指标值所占的比重pij,并计算第i项指标的信息熵ei。
第四步,计算各二级指标的权重ωi。
第五步,利用线性加权法计算大数据发展指标的综合得分f(x)。根据计算得到的二级指标权重ωi,对各个原始指标值xij进行加权,得到第i项指标在各省份的评分值ωixij,然后将各项指标的评分值进行加总,得到各省份大数据发展指标的综合得分f(x)。
同理,利用熵权法计算得到区域创新的二级指标权重,并利用线性加权法得到各省份区域创新指标的综合得分g(y)。
2.耦合协调度模型。“耦合”是指不同系统间相互影响的现象,耦合协调度能够反映系统之间的协调发展程度。本文在对大数据发展和区域创新指标体系进行测度的基础上,引入耦合协调度模型分析两系统之间的协调发展水平。模型构建如下:
其中,C为大数据和区域创新的耦合度,f(x)和g(y)分别为大数据和区域创新的综合评价指数,C的取值范围为[0,1],越接近1 说明系统耦合越好。为深入研究两系统之间耦合协调状态的动态演化特征,本文进一步构建耦合协调度模型:
其中,D为大数据和区域创新的耦合协调度;T为二者的耦合协调系数,α和β分别为二者对耦合协调度的贡献水平(α+β=1),本文认为大数据和区域创新在耦合系统中发挥相同的作用,因此令α=β=0.5。借鉴庞路静和张目(2020)的做法,将大数据和区域创新的耦合协调等级进行划分,划分标准见表2。

表2 耦合协调度的等级划分
3.空间自相关模型。为探究我国大数据与区域创新耦合协调关系的空间演化特征,本文采用空间自相关方法,建立全局空间自相关模型,即全局莫兰指数(Global Moran's I)考察两系统之间的耦合协调关系在整个空间上的空间集聚情况。具体公式如下:
其中,I表示全局莫兰指数,衡量样本省份的耦合协调度是否存在空间相关性以及存在何种相关性,I的取值范围为[-1,1],I>0表示两系统间的耦合协调度在空间上呈现正相关性,I<0 则表示存在空间负相关。n表示省份数量;xi表示第i个省份的大数据与区域创新耦合协调度;xˉ表示所有省份耦合协调度的平均值;Wij为空间权重矩阵,表示省份i与j的邻域关系,两省份相邻时Wij=1,否则取0。
为进一步考察各省份附近的空间集聚情况,采用局部莫兰指数(Local Moran's I)分析各省份的耦合协调度在空间上的具体集聚类型。具体公式如下:
其中,Ii表示局部莫兰指数,衡量i省份的耦合协调度与邻省耦合协调度的相似程度,Ii>0 表示省份i与其耦合协调度相似的邻省集聚,Ii<0 表示省份i与其耦合协调度不相似的邻省集聚,其他变量的含义同公式(9)。
4.地理探测器模型。地理探测器模型是探测空间分异性的统计学方法,可以用来检测空间变化的差异性并解释因素的驱动作用(王劲峰和徐成东,2017)。本文利用地理探测器中的因子探测模型确定耦合协调度演化过程中的影响因素,以及各因素的解释程度。因子探测模型如下:
其中,q表示探测因子对耦合协调度的解释力,h代表因子i的分层,Nh和分别为层h的单元数和方差,N和σ2分别为整体的单元数和方差。q的取值范围为0~1,q值越大表示因子i对耦合协调度的解释力越强,反之则越弱。
五、大数据发展与区域创新耦合协调分析
(一)大数据发展与区域创新指标测度
运用熵权法对两系统的二级指标进行赋权,各指标的权重见表1,进而采用线性加权法测算得到2011—2021年30个省份的大数据发展和区域创新综合评价指标值,同时测算两个指标在考察期内的平均增长率,以反映二者在考察期内的增长情况,鉴于篇幅限制,仅报告起止年份的数据,结果如表3所示。
整体来看,大部分省份的大数据发展和区域创新指数处于较低水平,相对于2011年,2021年全国大数据发展和区域创新水平呈上升趋势。东西部差异较大,广东、北京、江苏等东部地区的大数据发展和区域创新水平处于全国前列,而宁夏、青海、甘肃等西部地区相对滞后。具体而言,2011 年各省份大数据发展与区域创新的指标值普遍不高,分别处于[0.010,0.216]和[0.0004,0.212],相比于2011 年,2021 年各省份大数据发展和区域创新指标值均有所提高,指标值所处的区间变化为[0.031,0.734]和[0.003,0.925]。2021 年大数据发展水平排名前五的省份分别为广东、北京、江苏、浙江和上海,平均增长率排名前五的省份包括重庆、上海、海南、北京和安徽;2021年区域创新水平排名前五的省份分别为广东、江苏、浙江、北京和山东,平均增长率排名前五的省份包括江西、宁夏、青海、海南和安徽。
(二)大数据发展与区域创新耦合协调度的时空演变分析
通过耦合协调度模型测算得到2011—2021年我国30 个省份大数据和区域创新耦合协调度,并划分耦合协调等级。为考察各省份耦合协调等级的空间分布及其演变特征,选取起止年份和中间年份作为代表,表4 呈现了各省份协调等级在不同年份的变化情况。
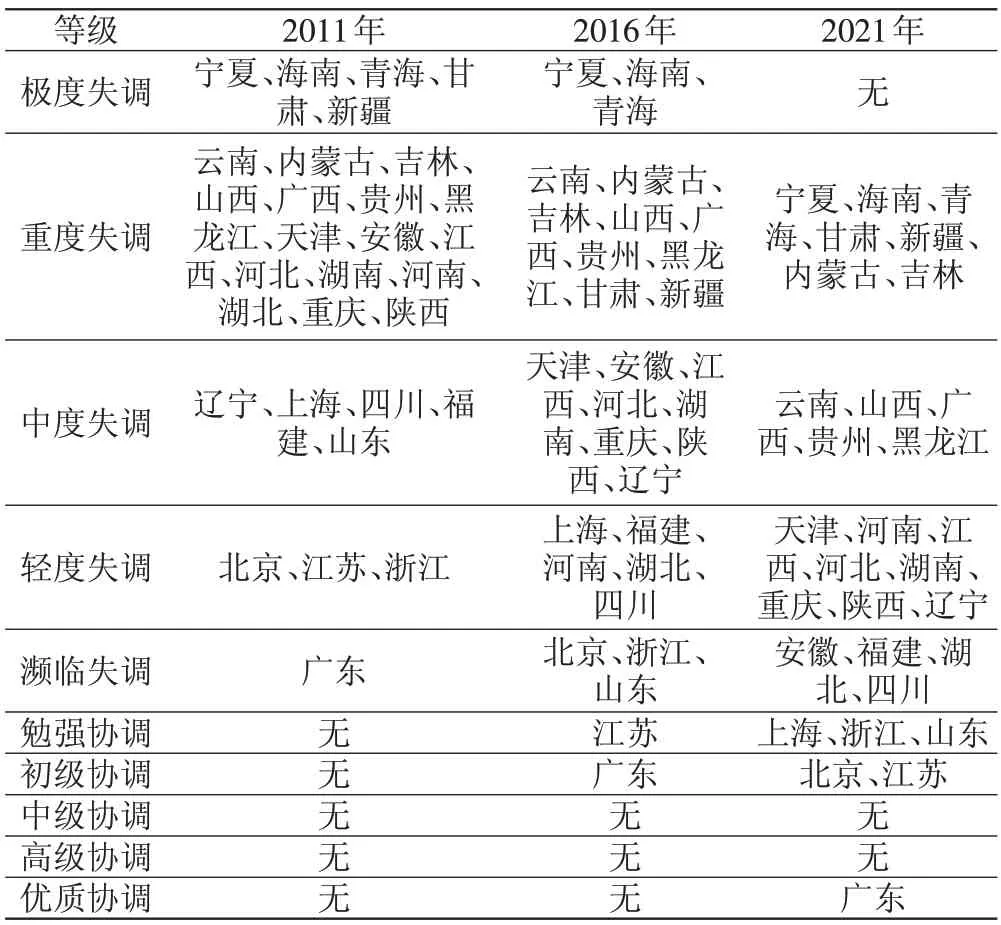
表4 不同耦合协调等级的空间分布情况
从耦合协调等级的演变来看,整体上各省份的耦合协调等级随着时间的推移而不断提高,呈现出从较低等级向较高等级演化的趋势,全国耦合协调发展状况逐渐向好。具体而言,极度失调和重度失调等级的省份数量逐年减少,2021 年全国范围内已无极度失调省份;轻度失调至初级协调的省份逐年增加,2021年上海、浙江、山东由失调进入勉强协调,北京、江苏进入初级协调,表明这些城市的大数据发展与区域创新融合程度有所提高,开始走向良性协调阶段;广东则率先进入优质协调,表明广东已形成良性共振协同的有序结构。
从空间分布格局来看,各年份东部省份的耦合协调等级普遍高于中西部地区,东西部耦合协调程度差异较大。具体而言,耦合协调等级较高的省份主要集中在东部地区,以广东、江苏、北京为代表;而耦合协调等级较低的省份主要集中在西部地区,以宁夏、青海、甘肃、新疆为代表;中部地区则主要处于轻度失调和濒临失调等级,以安徽、河南、江西、湖北为代表;大部分省份的协调程度还存在较大的提升空间。这反映了在现实环境下,大数据与区域创新之间确实存在着明显的“期望缺口”,虽然这两者在理论上具有较高的互补性,但在实际运行中往往由于区域差异、现实限制等,二者的耦合程度低于期望水平。
(三)大数据发展与区域创新耦合协调度的空间相关性分析
1.全局空间自相关。基于地理相邻关系的空间权重矩阵,利用Stata 软件输出2011—2021 年我国大数据和区域创新耦合协调度的全局Moran's I。如表5 所示,2011—2021 年全局Moran's I 均大于0,由2011年的0.096稳步增加至2021年的0.173。分阶段看,2011—2014年未通过显著性检验,而2015年及之后年份(除2017 年)均通过10%的显著性检验,这表明2011—2014年大数据和区域创新的耦合关系尚未形成空间集聚,可能是由于该时期内大数据仍处于初始发展阶段,随着时间的推移,大数据发展逐渐成熟,2015年之后与区域创新的耦合关系在空间上趋于集聚,呈现出显著的正向空间自相关性,并且空间集聚程度不断增强。

表5 耦合协调度的全局莫兰指数
2.局部空间自相关。通过局部空间自相关分析法,进一步探讨大数据发展与区域创新的耦合协调关系在局部空间上的集聚特征。利用Stata 软件输出2011年、2016年和2021年的局部莫兰指数散点图,并依据各省份所在象限划分其所属的集聚类型。
表6 报告了各省份耦合协调度的集聚情况。从2021年集聚类型的整体分布来看,处于低-低集聚区(LL)的省份数量在集聚类型中占据主导地位,高-高集聚区(HH)的省份数量次之,而低-高集聚(LH)和高-低集聚(HL)省份相对较少,说明大部分省份的耦合协调程度与其邻省具有空间同质性。低-低集聚区的省份主要分布在青海、宁夏、新疆等西部地区,这些省份的大数据与区域创新耦合协调程度与其邻省均较低;高-高集聚区的省份主要分布在江苏、浙江、安徽、山东等东部和中部地区,表明这些省份与其邻省的耦合协调程度均较高;低-高集聚的省份主要包括海南、广西、江西、天津、河北,分布较为分散;高-低集聚区的省份主要包括广东、北京、四川、湖北,分布也较为分散。
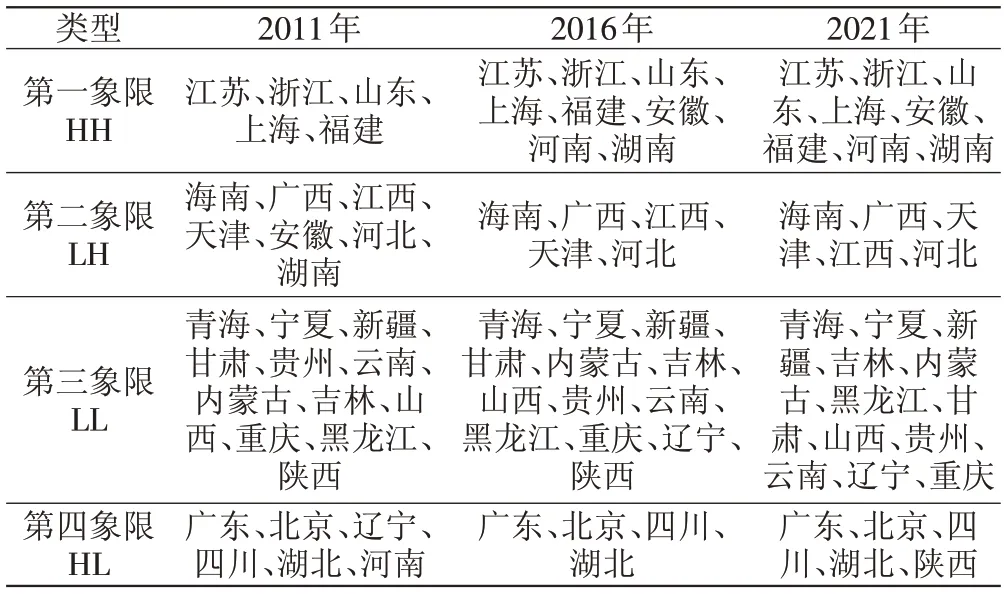
表6 不同年份耦合协调度的集聚类型及分布
从集聚类型的演化趋势来看,处于高-高集聚区的省份数量由2011年的5个增加至2016年的8个,新增的省份包括安徽、湖南和河南,安徽、湖南和河南由2011 年的低-高或高-低集聚演化为2021 年的高-高集聚,这反映了3 个省份的耦合协调等级有所提高,并且对邻省形成了良好的辐射带动效应。2021年处于低-低集聚区的省份,相比于2011 年新增了辽宁、减少了陕西,辽宁由2011年的高-低集聚演化为2016年及2021 年的低-低集聚,陕西则由2011 年及2016年的低-低集聚演化为2021 年的高-低集聚,说明辽宁的耦合协调等级有所降低,可能是受周围省份的影响,而陕西省的耦合协调程度有所提高,但尚未形成对邻省的带动作用。值得关注的是,广东和北京两个相对发达地区在考察期内均处于高-低集聚区,说明两地区自身的耦合协调状况较好,但尚未形成对邻域的辐射带动效应,因此要特别关注广东和北京地区大数据与区域创新的耦合协调发展情况,增强其对于邻省的拉动作用。
(四)大数据发展与区域创新耦合协调度的驱动因素分析
进一步利用地理探测器分析耦合协调演化的驱动因素。选取表1中所有二级指标作为因子变量,根据地理探测器模型的要求,首先采用SPSS 的K 均值聚类法将所有因子变量处理为离散型变量,然后将耦合协调度以及处理后的因子变量导入地理探测器,分别得到2011 年、2016 年和2021 年的因子探测结果。结果显示,在22个因子变量中,各年份通过显著性检验的因子数分别为16、15 和17 个,约占总数的70%,解释力达到80%以上的因子数量占75%,表明大部分指标对于耦合协调度的空间分异影响显著,并且解释力较好。
根据解释力大小选取前6 位因子变量作为核心影响因子,表7报告了2011年、2016年和2021年核心影响因子的q值。从核心因子的整体解释力来看,所有核心因子的解释力均超过80%,不同年份核心因子及其解释力具有差异,表明各省份耦合协调的空间分异受多种因素共同作用,并呈现时间差异特征。从核心因子的类别和影响力变化来看,2021 年与2016 年的共同核心因子包括两个创新投入指标和两个创新产出指标,即R&D 经费支出和高技术产业新产品开发经费支出、国内专利授权量和规模以上工业企业有效发明专利数,并且这4类核心因子在2021年的解释力均有所下降,说明各影响因子对耦合协调度空间分异的驱动力有所减缓。三个不同时段的共同核心因子包括R&D经费支出和高技术产业新产品开发经费支出,说明这两个创新投入指标是影响耦合协调度空间分布的主要核心因素。因此,未来大数据与区域创新的融合发展需要重点关注以研究与开发、高技术产业为主的创新活动。

表7 耦合协调度驱动因子探测结果
六、结论及启示
(一)主要结论
本文主要利用2011—2021年我国30个省域面板数据研究大数据发展与区域创新的耦合协调关系。首先从理论层面剖析大数据发展与区域创新的耦合机理,通过构建大数据发展与区域创新指标体系测算大数据发展与区域创新综合评价指数,其次利用耦合协调度模型、空间自相关模型和地理探测器模型,对二者耦合协调的演化特征和驱动因素进行分析,最后得出如下结论:
第一,相对于2011年,2021年全国大数据发展指数和区域创新指数呈上升趋势,但大部分省份仍然处于较低水平,大数据发展水平和区域创新能力有待进一步提高。分地区看,广东、北京、江苏等东部地区的大数据和区域创新水平处于全国前列,而宁夏、青海、甘肃等西部地区相对滞后,东西部差异仍然较大。
第二,各省份的耦合协调等级随时间的推移不断提高,呈现出从较低等级向较高等级演化的趋势,全国耦合协调发展状况逐渐向好。分地区看,东部地区的耦合协调等级普遍高于中西部地区,大数据与区域创新协调发展尚不平衡,协调程度还存在较大的提升空间。
第三,大数据与区域创新耦合关系的整体空间集聚程度随时间推进而不断增强,空间集聚类型则以低-低集聚和高-高集聚为主,反映了大部分省份的耦合协调程度与其邻省具有空间同质性。当前处于低-低集聚区的省份数量仍然占据主导地位,主要分布在西部地区,还需要继续加强该区域自身的大数据发展水平和区域创新能力,提高二者耦合协调程度。除此之外,要特别关注高-低集聚区和低-高集聚区,增强该区省份与邻省的互动,充分发挥高值区对低值区的辐射带动作用,加快形成高-高集聚为主导的良好局面。
第四,22个因子变量中,近70%的因子变量对于耦合协调度的空间分异影响显著,并且解释力较好,说明各省份耦合协调的空间分布差异受多种因素共同作用。不同年份的核心因子及其解释力具有差异,并呈现阶段性差异特征。R&D经费支出和高技术产业新产品开发经费支出是驱动耦合协调度形成空间差异特征的主要核心因素。
(二)启示建议
基于我国大数据发展与区域创新耦合协调的发展现状及演化特征,对于提高二者耦合协调水平、促进二者融合发展提出如下建议:
首先,制定差异化发展政策,全方位提高大数据发展和区域创新整体水平。当前我国大数据发展与区域创新整体水平不高,西部地区相对滞后,因此应综合考虑地区差异因素,全方位提高大数据发展与区域创新水平。对于东部地区,持续加大大数据发展战略和区域创新政策的实施力度,优化大数据发展模式,提升区域创新效率。对于西部地区,积极引进大数据技术与大数据人才,加大对区域创新活动的扶持力度,缩小东中西不同地区大数据发展与区域创新的差异,加强东部高值区对中西部低值区的引领示范作用。
其次,完善协调发展机制,全面提升大数据发展与区域创新耦合协调质量。从实现全局发展的角度完善大数据发展与区域创新的耦合协调机制,思考提高耦合协调质量的路径,如制定相关激励措施,全面营造提升大数据发展水平和区域技术创新能力的环境氛围;加强省域间大数据资源和创新经验的共享,畅通区域创新合作互助渠道,引导耦合协调朝均衡态势发展;发挥优质协调省份(如广东)对其他省份的引领示范作用,提高协调水平较高省份(如北京、江苏)对于邻省的辐射带动效应,形成二者协同发展的良好局面。
最后,合理布局数据资源和创新要素,引导耦合协调关系合理、有效推进。综合考虑耦合协调空间分异的驱动因素,合理布局大数据基础设施和创新投入等要素结构,引导耦合协调关系向合理化、有效化方向推进。搭建区域内的数据中心和创新实验室,引进先进的大数据处理与应用技术,创建更丰富的数据应用场景,拓宽区域创新的视野,同时制定包括数据集中化、数据安全和数据隐私等方面的规章制度和标准,为实现大数据发展与区域创新有效共性协调提供良好的法律保障。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
数学物理学报(2021年4期)2021-08-30
中等数学(2020年1期)2020-08-24
文化创新比较研究(2020年8期)2020-01-02
当代水产(2019年11期)2019-12-23
特别健康(2018年3期)2018-07-04
大型铸锻件(2015年5期)2015-12-16
中国土地科学(2014年4期)2014-03-01
湖南理工学院学报(自然科学版)(2014年1期)2014-02-28
济宁学院学报(2014年6期)2014-02-28
