
基于多特征神经网络的日前光伏功率预测
2024-04-13 06:54王志宝吴柏铮孟令哲
电子设计工程 2024年7期
王志宝,吴柏铮,孟令哲
(上海电力大学电子与信息工程学院,上海 201306)
伴随着世界能源危机的加速演变和人们环保意识的增强,新能源发电,特别是光伏发电在世界范围内获得了广泛的应用[1]。然而,由于区域内负荷类型复杂,且光伏出力随机性大[2],给电网的稳定运行带来了严重的挑战。太阳辐照度、天气状况以及周围环境温湿度等因素是影响光伏发电的主要原因[3]。为了提高光伏发电的有效性和稳定性,使得电网安全稳定运行避免遭受冲击,有效的光伏发电功率预测方法一直是电网建设的研究热点[4]。
光伏发电功率预测是一个非线性的随机问题,神经网络、支持向量机、粒子群等机器学习智能算法被广泛应用[5]。研究关注点在于提高日前光伏功率预测精度,如文献[6]提出粒子群算法和支持向量机结合的预测方法。现阶段的研究专注于提高单一预测方法的预测精度,对于预测共性的研究较少。为了提高各种预测模型下的预测精度,提出衍生和基础神经网络特征融合(DBDeepFF)架构,该架构利用计算的衍生数据特征显著改善了光伏功率的预测结果。
1 特征融合架构
1.1 神经网络架构
深度学习解决方案,特别是顺序模型,如LSTM、RNN 和GRU 等模型,正在成为序列预测的流行选择[7]。RNN 是递归神经网络的一种,它以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接[8]。它的本质是像人一样拥有记忆的能力。因此,其输出依赖于当前的输入和记忆。RNN 展开结构如图1 所示。

图1 RNN展开结构
典型的LSTM 通过三个门的基本结构来实现信息的保护和控制,这三个门分别为输入门、遗忘门和输出门[9]。详细的LSTM 模型的内部计算结构如图2所示。
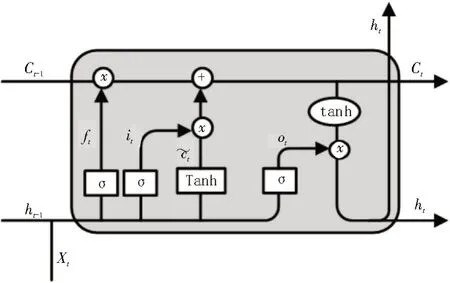
图2 LSTM模型中单个细胞的内部结构
LSTM 内部的具体计算方法可以表示为:
同时,LSTM、RNN 和GRU 也有相应的双向序模型。双向模型的优点是可以从正向和反向两个方向观察输入特征[10],这三种双向序列结构类似。其中,LSTM 单元双向序列结构如图3 所示。
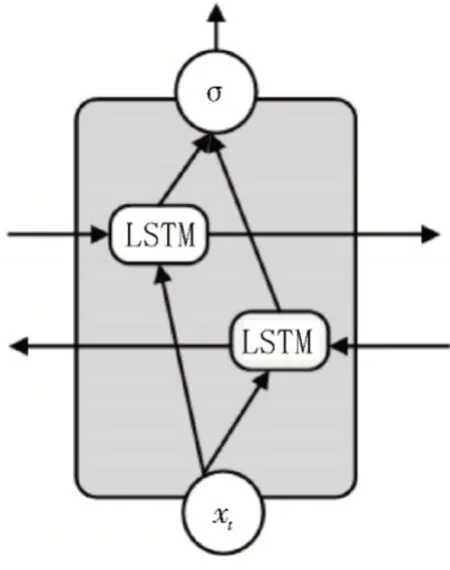
图3 LSTM单元双向序列模型
1.2 基础数据和衍生数据
对于光伏输入数据而言,温度T和辐照度R对光伏发电数据影响非常大,特别是辐照度,其趋势与光伏功率的趋势非常相似[11]。考虑到深度学习模型处理非线性数据的能力[12],数据必须转换成一个序列,以便它可以输入到所提出的架构,以预测下一个时间间隔的功率数据[13]。顺序模型,如LSTM 和BLSTM等,需要输入过去时间步长的数据来提取它们的特征和时间信息,以预测下一个时间步长[14]。为了使数据可用于训练这样的模型,数据只能转化为特定的序列。如以天为单位,用K天功率预测一天的发电功率数据。
除了考虑上述已有的基础特征外,还考虑了额外的衍生特征。基础特征为上述的功率、太阳辐照度等;而衍生的特征是从基础特征中计算出来的,这两种特征在功率预测中都很重要。基本特征提供了不同参数的绝对值,而衍生特征利用了不同值之间的相关性,帮助深度学习模型学习更多特征。衍生特征主要包括:
1)过去K天步长发电的平均功率;
2)过去K天步长发电的平均功率的标准差;
3)过去一天步长发电的平均功率;
4)过去一天步长发电的平均功率的标准差。
其中,平均数能较好地反映一组数据的整体情况,标准差能反映一组数据集的离散程度。
2 Y序列神经网络预测架构
DBDeepFF 是一种Y 序列模型架构,它将基础数据和衍生特征输入到单独的层中,提取学习到的特征。对基础序列和衍生序列使用单独的输入层的目的是允许顺序层独立地从两个输入序列中学习,为的是利用基础序列和衍生序列与预测功率的相关性。DBDeepFF 架构如图4 所示。
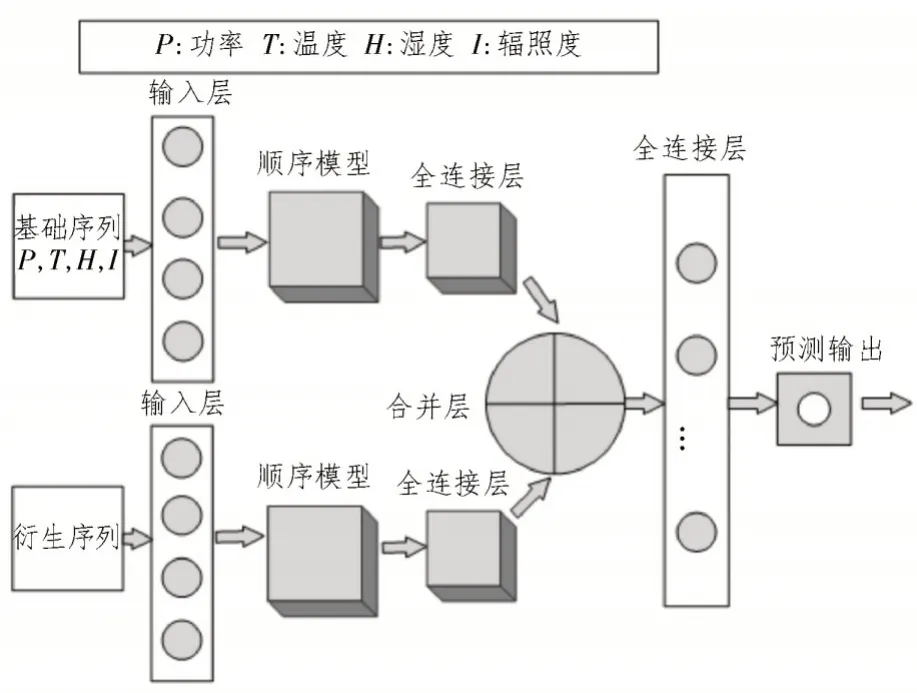
图4 DBDeepFF架构
在特征输入之前需要计算好需要输入的衍生序列,同时基础序列和衍生序列的维度有所不同,要对数据的维度进行处理。由图4 可知,基础特征如光伏功率和太阳辐照度和衍生特征数据会被合并输入到一个密集的层。全连接层由n个节点组成,通过校正线性单元(ReLU)激活[15],通过实验确定n的最佳值。全连接层的作用是将从基础特征和衍生特征中提取的信息进行非线性合并[16]。将全连接层的输出通过线性激活输出层进行处理,对想要预测的功率进行最终预测。DBDeepFF 模型算法基本流程图如图5 所示。
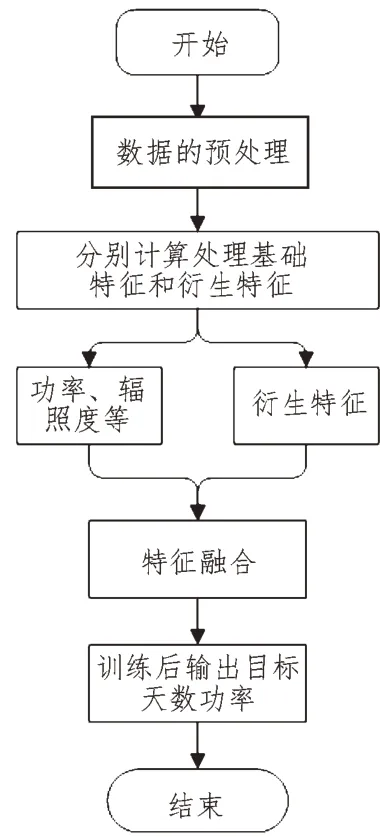
图5 DBDeepFF模型算法流程图
3 实验结果与分析
以澳大利亚DKASC 光伏系统公开数据集为实验数据,选取了四年光伏发电数据。该数据包含发电功率、温度等重要信息,时间间隔为5 min。为了满足基本的提前一天调度需求标准,在实验中以15 min 的时间分辨率对数据进行采样。这些数据下载之后并不是完全完整的,需对异常点进行删除,少部分的缺失数据可以前后时间的数据进行了平均。由于数据量较为庞大,因此删除异常点不会带来负面影响。数据的处理过程如图6 所示。

图6 数据的处理过程
同时,实验中划分测试集和训练集比例如图7所示。
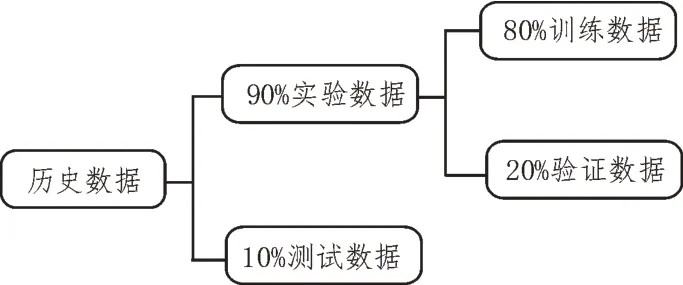
图7 数据集划分
3.1 评价指标
为了评价提出的模型的预测性能,预测实验中选择了三个精度估计指标,分别为均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)[17],计算方法如下:
式中,y(i)为实际的光伏功率,y′(i)为预测值,N为y(i)值的个数。但是需要注意的是,夜晚的发电数据为大多为0,无法计算MAPE 的值或算出来的值无穷大,因此在计算MAPE 时需要剔除掉这些点,否则,结果会存在很大偏差。
3.2 实验结果
文中对短期负荷预测框架在开放数据集上进行大量严格实验。将DBDeepFF 架构(所有六个衍生结构)的结果与来自文献[18]中提出顺序模型和其他顺序模型进行了比较。将该数据集与序列模型的其他基本模型(RNN、LSTM、GRU、BRNN、BLSTM、BGRU)进行了不含衍生特征的测试,即单一的顺序模型。在基础架构下的预测结果如表1 所示。
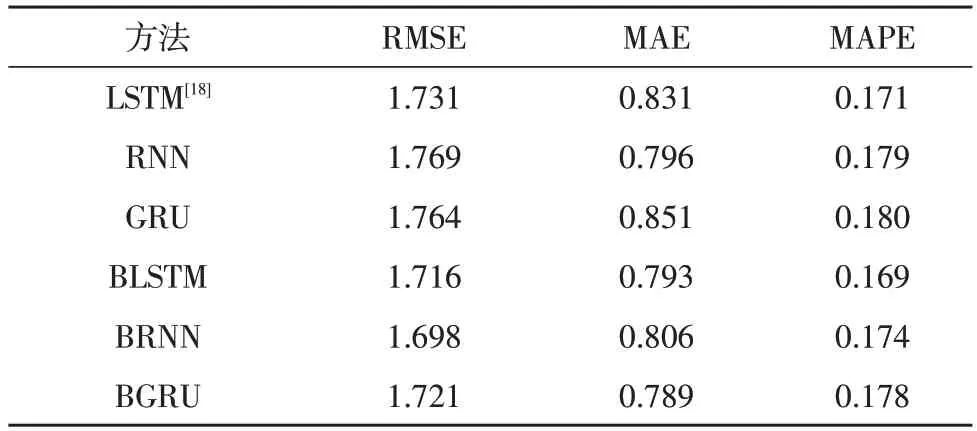
表1 基础架构下的预测结果
表1 中的六个基础数据序列在总体架构上是相同的,它们之间的唯一区别是在顺序层中使用不同的单元(RNN、LSTM 或GRU)和它们的双向对应单元(BRNN、BLSTM 或BGRU)。将表1 中的六种结构改成如图4 所示的Y 序列,从而验证DBDeepFF 架构的作用。DBDeepFF 架构下的预测结果如表2 所示。

表2 DBDeepFF架构下的预测结果
从表2 中可以看出,六个基础数据序列模型与使用DBDeepFF 架构后的预测结果相比,MAPE 均提高了4%以上。文中提出的架构可以使预测模型获得更多的数据特征,从而提高预测精度。具体原因是DBDeepFF 架构增加了一个学习维度。在基础序列输入的同时,将计算特征加入到网络中,使得模型能够充分学习隐形的数据特征。临近的时间在大多数情况下外部环境相似,同时平均值和标准差本身就是反映数据的平均水平和离散程度。因此,计算特征的输入将预测数据限制在与真实值接近的区间内。柱状图清楚地显示了MAPE 在DBDeepFF 架构引入前后的变化,如图8 所示。

图8 改进架构前后MAPE对比
4 结论
为了提高现存的多种预测神经网络的预测精度,提出了一种基于序列层的深度学习体系结构,并在深度学习模型中引入衍生数据特征,得到了DBDeepFF 架构。通过这种端到端的学习模型的预处理方法,用于日前光伏功率预测。通过严格的实验证明,进行了大量的检验和验证,给出了三个统计指标的统计结果。统计结果表明,改进后的模型性能良好,其MAPE 至少降低了4%。针对现有的基础模型架构缺乏对数据特征的学习,预测结果表现力稍差,提出的新模型体系结构确实提高了预测精度,符合预期结果。
总而言之,该架构使神经网络能够提升学习单独处理的数据特征的能力,取得了良好的效果。接下来,可能需要增加模型类型的研究,比如引入混合模型,看看是否能得到更好的结果。其他光伏电站的数据也可以加入到数据集中进行验证。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
环球时报(2022-06-15)2022-06-15
成都信息工程大学学报(2021年5期)2021-12-30
科学大众(2021年9期)2021-07-16
汽车工程(2021年12期)2021-03-08
电信科学(2017年6期)2017-07-01
下一代英才(酷炫少年)(2017年3期)2017-06-15
学与玩(2017年4期)2017-02-16
电测与仪表(2015年22期)2015-04-09
河北科技大学学报(2015年5期)2015-03-11
