
边缘计算下配网暂态数据缓存冲突规避方法
2024-04-13 06:54杨婧付卿卿唐贤敏
电子设计工程 2024年7期
杨婧,付卿卿,唐贤敏
(贵州电网有限责任公司计量中心,贵州贵阳 550000)
城市配电网暂态数据库系统近年来应用广泛,其采用的暂态数据储存与缓存功能,提高了城市配电网数据储存的稳定性,由于配网暂态数据库缓存过程中的随机性,使得配网暂态数据库缓存冲突概率增大,随机分布的缓存数据冲突时,导致暂态数据库稳定性降低。因此,为了提升暂态数据缓存的输出稳定性以及自动调整能力,对于配网暂态数据缓存冲突规避方法的研究至关重要。
为此,相关领域学者对其展开了研究,文献[1]设计了一种应用于配网暂态数据的高阶逆过程方案,完成对暂态数据缓存冲突的规避,但该方法采用的最小二乘法计算量较大,求导运算时间缓慢。文献[2]提出了配电网接地故障暂态数据模型的构建及应用,收集小电流接地选线装置的暂态录波数据,开展接地跳闸的整定计算、故障分析和安全策略、动作评估、录波和反演等共性技术的研究,以此完成对暂态数据模型的构建。通过模型对暂态数据冲突进行规避,但此方法在收集小电流接地选线途中具有危险性,操作不当容易出现事故,不适合普及使用。
上述方法进行暂态数据库缓存冲突规避过程中都存在一定的问题,为此,该文在边缘计算下提出一种配网暂态数据缓存冲突规避方法。
1 边缘计算下配网暂态数据压缩
1.1 压缩存储
在边缘计算算法中,通过建立稀疏字典原子对配网内的暂态数据进行压缩,每个节点的暂态数据都是同一个字典原子。假设每个节点的平均长度是n,上传字典的原子数目是r,结果如式(1)所示:
式中,Y为各节点的测量数据;X为各节点的原始信息;D为稀疏字典原子;i表示边缘计算系数。通过调低测量节点数据的n值与上传配网字典原子数量r的差值,使上传配网的所有测量数据与字典原子数量所占用的存贮数减少[3-4]。
为了保证在实际应用过程中能正确、快速地使用暂态数据,配网将各字典原子加载到一起,形成一个完整的字典dk,其中,k是整个字典的全部原子序列[5-6]。在使用此区域资料时,必须先求出该区域资料所对应的稀疏度表示系数θ:
通过恢复得出各分区的初始信息,再利用配电网暂态数据完善字典的构建过程,在每个边缘区域,只要再上传一次测量结果,就可以进行数据的压缩和存储,这就有效降低了暂态数据的存储容量,建立完整字典。
1.2 动态分区
该文通过傅里叶正交矩阵对边缘计算中所产生的稀疏字典问题进行分析,对暂态数据进行动态分区。采用边缘计算算法[7-8],得到各节点所对应的稀疏系数,通过系数可反映出配网暂态中对不同频率元素所产生的谐波变化的能力,并进一步研究各节点间稀疏函数的相关性,将该问题转化为对配网暂态数据中各次谐波含有率的互相关联数的研究,该文采用的配电网边缘计算分区法,有效地反映出各节点间暂态数据中所包含谐波的传递情况,并在配电网上更有针对性地避免冲突。
在配电网边缘计算和划分过程中,采用的划分阈值选择对划分效果产生较大的影响。由于配电网边缘计算的暂态数据是随时变动的,在暂态数据的谐波传递过程中,采用固定的阈值会造成高频谐波污染划分的不确定。当划分阈值设置过大时,划分种类过多,划分没有效果;当划分阈值设置过小时,划分种类过少,划分效率低,同时人为限制阈值也难以实现[9-10]。为此,采用边缘分析模式,采取双阈值动态划分方法,界定划分数量的规模,通过计算各节点暂态信息稀疏特性之间的相对影响数,在配电网的边缘计算中,确定划分动态阈值。为了避免划分结果不稳定,以及过于频繁地划分数据变化,需要限定划分阈值[11-12]。
基于边缘计算的阈值划分流程如图1 所示。

图1 基于边缘计算的阈值划分流程
第一步:建立分区参数后,注入各节点暂态数的稀疏系数。在此基础上,确定了分区阈值和数目的区间,其中,a是分区数目的最大值,b是分区数目的最小值;
第二步:计算各个节点暂态数据的稀疏系数之间的互相关度,如式(3)所示:
其中,θa,θb∈[1,n];R为稀疏系数;
第三步:随机生成阈值并重新划分,如果分区数量数值超过阈值,系统将采用二分法对区域阈值的数值进行调整,直到达到区域数量要求;
第四步:若阈值大于分区数量,则确定分区,反之则保持现有分区状态;
第五步:输出配电网区域大小和各个区域的所有节点信息[13-14]。
2 配网暂态数据缓存冲突规避
2.1 特征提取
建立暂态数据库系统缓存疏导模式,通过负载均衡调整技术,实现了暂态数据库系统中高速缓存的均衡分配,暂态数据库系统高速缓存冲突的特征分配模型如式(4)所示:
其中,u代表通过特征分析后的负荷强度;e代表突发损失率;t代表资源的竞争矛盾力度;c代表暂态数据资源使用率;V代表数据库冲突距离,υ代表数据库缓存的数据容量[15]。
通过多元数据融合与更多数据的整合技术,可以实现暂态数据库缓存冲突的自适应调节,并实现数据缓存冲突调节的条件分布p可表示为式(5):
其中,d代表数据库数据压缩量;U代表数据库表空间利用率,ϖ代表数据库系统缓存信元被调整量;wf代表数据库系统缓存信元之差,f代表数据库系统冲突信元总量。
采用模糊粗糙集特征提取算法,实现对暂态数据库系统中缓存数据的挖掘。设定高速缓存空间为U,根据缓存置换函数对每个缓存信元代表的缓存空间系数进行求解,得到在暂态数据库缓存中冲突最大的对象集合,表示如下:
其中,f(x)为数据库规避过程得到的冲突函数;f(y)代表了外界干扰数据量。采用多重数据融合技术与多信息的整合技术,实现对暂态数据库系统高速缓存冲突的自适应调度。
2.2 冲突均衡处理
利用边缘计算映射表可以实现对暂态数据库系统缓存的冲突输出调整,根据粗糙集映射算法,得出对暂态数据库系统缓存冲突的置换函数,而通过对置换函数的计算,得出的高速缓存集可以描述为O={O1,O2,…,On},其中,O为高速缓存集,On为缓存对象。以T(x)为控制函数,对暂态的缓存冲突控制[16],所得到的参数类型为:
其中,x为自然数,并检查On的返回值,以构建暂态数据库系统缓存冲突自动处理模式,并利用粗糙集的分布式属性,进行暂态数据库系统缓存冲突自动规避。
3 实验分析
为了验证提出的边缘计算下配网暂态数据缓存冲突规避方法的实际应用效果,选用文献[1]基于高阶求导的冲突规避方法和文献[2]基于故障暂态模型的冲突规避方法进行对比实验。
设定冲突的延时时间为0.5 s,实验数据量为600 bit,冲突字节长度设定为1 200 kB,对数据进行缓存处理,设置带宽为150 dB,建立实验环境如图2所示。

图2 实验环境
利用图2 的实验环境进行冲突规避实验,实验步骤如下:
第一步:统计边缘节点新上传的字典原子r,以及配网的稀疏字典D的第k个原子的相关度,如果新生成的相关度的绝对值均小于某一阈值,则说明新提交至配网的字典原子r与稀疏字典D的关联性很弱,可将该字典原子扩充成配网稀疏字典的原子;
第二步:将各区域上传的字典分子之间合并成一个过完备字典稀疏空间,再加以正则化,使各字典分子间具有高相干性;
第三步:将过完备字典进行归一化处理,处理后的字典原子处于更新状态;
第四步:结合过完备稀疏字典,利用分布式压缩感知计算从上传的测试值中还原出初始资料,并检验数据存储的可恢复性,从而获取各节点相应的稀疏关系;
第五步:将各节点对暂态数据的测试值作为存储数据进行压缩保存,实现冲突规避检测。
得到的冲突缓存处理时间实验结果如图3所示。
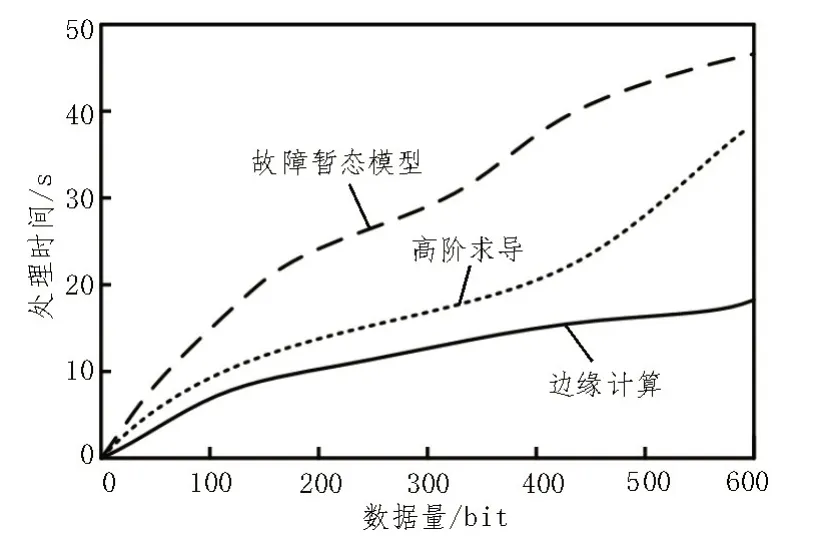
图3 冲突缓存处理时间实验结果
观察图3 可知,随着数据量不断增加,三种方法对于冲突缓存的处理时间也在不断增加,但是边缘计算方法的冲突缓存处理时间最短。当冲突缓存数据量达到最大600 bit时,文献[2]基于故障暂态模型的冲突规避方法的冲突缓存处理时间达到45 s,而文献[1]基于高阶求导的冲突规避方法的处理时间达到38 s,提出的边缘计算处理方法处理时间仅为18 s。由此可知,提出的边缘计算冲突规避方法处理时间较短。
在完成冲突缓存处理后,检测不同处理方法的死亡节点数量,得到的实验结果如表1 所示。

表1 死亡节点数量实验结果
根据表1 可知,文献[1]基于故障暂态模型的冲突规避方法的处理能力最弱,死亡节点数量最多,当冲突缓存数据量达到最大600 bit时,死亡节点高达190个,配电网的工作状态受到严重限制,不适合实际应用;文献[2]基于高阶求导的冲突规避方法具有相对较强的处理能力,死亡节点低于30 个;而提出的边缘计算冲突规避方法死亡节点低于11 个。由此可知,提出的边缘计算下配网暂态数据缓存冲突规避方法的实际应用效果最好,能够在短时间内实现冲突规避,具有极好的应用效果。
4 结束语
配网暂态数据缓存冲突的规避对配网正常运行具有重要意义。为此,文中提出了一种在边缘计算下的配网暂态数据缓存冲突规避方法,压缩配网暂态数据,并对其进行分区处理。利用边缘计算得到特征分配模型,结合粗糙集映射方法,通过冲突均衡处理,实现暂态数据缓存冲突规避。经实验验证表明,提出的边缘计算下的配网暂态数据缓存冲突规避方法能够在短时间内实现冲突规避,具有极好的规避效果。但该文在稳定性方面仍有不足之处,后续将围绕此方面进行研究。
猜你喜欢
家教世界(2023年28期)2023-11-14
家教世界(2023年25期)2023-10-09
大电机技术(2021年5期)2021-11-04
电子测试(2018年14期)2018-09-26
电子制作(2018年14期)2018-08-21
制造技术与机床(2017年4期)2017-06-22
电子测试(2017年23期)2017-04-04
电信科学(2016年10期)2016-11-23
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
