
基于分布式缓存的科技文献信息动态检索系统设计
2024-04-13 06:54邓彬
电子设计工程 2024年7期
邓彬
(中国科学技术信息研究所,北京 100000)
科技文献信息是科研人员研究科学技术及创新的基础[1-3]。以往查询科技文献信息时,依据索引卡片查询文献资料位置并获取资料。随着信息技术及互联网技术的发展与普及,信息检索技术应运而生[4-6]。当前信息检索技术虽已为用户提供便利,但仍然有改进空间,用户在使用搜索引擎时,如何迅速将用户所需信息及其隐式需求排列在搜索结果前排,已成为研究人员所研究的热门话题。杜瑞忠等人提出利用双向索引查询关键字方式,在简化搜索动态更新过程的同时对信息进行加密,该方案虽然提升了搜索速度及信息安全性,但未考虑用户隐式需求导致搜索结果关联度不够[7];包翔等人提出以图像内容为基础创建检索系统框架,通过提取图像特征包组成视觉字典,并由直方图形式描述图像特征获取检索结果,该系统检索结果精准度及关联度较高,但由于局限性强等原因只适用于图像检索,无法满足用户对文字类需求信息的检索需求[8]。
分布式缓存是利用分布式网络存储技术,将热门信息存储至离系统用户最近的应用或设备中,可提升用户访问信息速度[9-10],因此,设计了基于分布式缓存的科技文献信息动态检索系统。
1 科技文献信息动态检索系统
1.1 检索系统总体结构
科技文献信息动态检索系统能够分解科技文献网页信息为结构化数据信息,并将该信息存储至系统数据库内,通过系统软件运行实现数据库内数据统计、关联及排序等工作,为用户提供最需要的科技文献信息。科技文献信息动态检索系统总体结构如图1 所示。科技文献信息动态检索系统的检索流程为:用户在用户层输入检索需求后传输至处理层数据采集模块,该模块将采集到的信息通过网络层通信模块传输至数据层科技文献信息数据库存储,采用分布式缓存方法对用户以往检索需求进行处理,并建立分布式存储模块内的热数据库及冷数据库;将科技文献信息数据库内的信息通过网络层传输至处理层检索处理模块,利用该模块内科技文献信息动态检索方法对数据库内信息进行检索处理,并与数据层分布式存储模块内关联数据进行排序重组,获取检索结果后输出至用户层展示检索结果。

图1 检索系统总体结构
1.2 检索系统硬件设计
1.2.1 通信模块
通信模块由Web 服务技术组成,结合Web 服务技术采用Java EE 应用程序搭建分层模型,完成检索系统中各层数据的传输。通信模块Web 服务技术结构如图2 所示。

图2 通信模块Web服务技术结构
Web 服务技术的网络层主要是对处理层与数据层的信息进行交互处理,同时处理接收请求或返回信息等;处理层主要为数据采集模块提供服务,通过对各大搜索网站内的网页信息进行解析处理,并将处理后的数据存储至数据层,同时向数据库发出检索服务请求,整理数据库及分布式存储模块与用户请求相关联的数据;用户层的用户界面显示由JSP动态网页开发技术完成。通信模块Web 服务技术结构可以降低各模块间的耦合程度,还可以分离业务间处理逻辑与数据显示情况,便于日后修改或扩充用户层与处理层。
1.2.2 分布式存储模块
分布式存储模块内置控制器,模块内数据的分布式缓存均由控制器控制。控制器采用CPLD技术实现读写缓存数据、加载模式寄存器以及数据刷新等操作[11]。该控制器为通用型,适用于控制所有存储芯片,且控制器参数可通过系统程序设置,初步设置控制器突发长度为1、2、4、8 字及全页;刷新时间为自动刷新,可依据实际情况进行调整;CAS 延迟时间为2 或3 个时钟周期;支持的数据宽度为8位、16位、32位及64位;支持存储芯片读写缓存数据等全部命令操作。控制器结构如图3 所示。
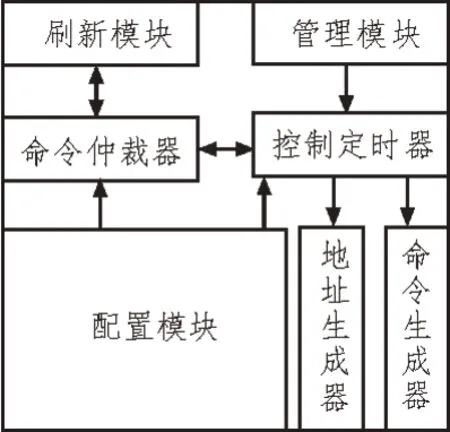
图3 分布式存储模块控制器结构
控制器内刷新模块用于设置及调整刷新时间;管理模块为管理芯片Bank 地址切换;命令仲裁器的作用是适时选择合适的执行命令;控制定时器用于为时序信号进行定时;配置模块主要配置存储芯片模式寄存器,设置各种可编程模式;地址生成器用于生成芯片行、列地址及选通信号;命令生成器为输出命令仲裁结果,生成芯片控制信号控制芯片。
1.3 检索系统软件设计
1.3.1 动态检索的分布式缓存方法
系统在数据层分布式存储模块设计动态检索的分布式缓存方法,通过用户使用系统所产生的最近访问时间及历史访问次数制定缓存替换策略,插入热数据至系统缓存数据中,替换温数据及冷数据,提升用户访问数据的缓存命中率,降低由系统缓存产生的计算开销及不必要的磁盘访问。动态检索的分布式缓存方法流程如图4 所示。

图4 动态检索的分布式缓存方法流程
用户通过登录检索系统进入用户端,系统依据用户对数据的最近访问时间及历史访问次数判断数据热度,并将热度最高的数据优先排列形成数据序列,数据序列中的数据按照从前到后的顺序依次为热数据、温数据、冷数据,当缓存占用率超出系统缓存阈值时剔除冷数据缓存。若用户发起读写请求,采用逻辑划分方式将原有数据序列划分为多个数据序列进行更新,可以降低锁粒度及I/O 时延。
考虑到系统发生网络拥塞或内存节点故障时会导致缓存信息丢失,动态检索的分布式缓存采用定期打包的方式整理缓存数据并写入逻辑,利用检查点将打包后的缓存数据持久化至数据库中[12]。针对已丢失的缓存信息,可以依据数据库日志信息进行重建。该方式可以确保检索系统在缓存信息丢失的状态下正常运行,增强检索系统的容错性。
动态检索的分布式缓存方法核心是缓存替换策略,缓存替换策略的作用是提升缓存命中率,当检索系统缓存已满时需及时剔除冷数据,选取用户最近未访问且访问次数最少的冷数据缓存作为剔除对象,以此类推获取更多内存空间缓存新数据[13]。该策略以用户最近及历史访问记录为基础,判断冷数据范围并替换用户需求数据,同时设计缓存完整数据与仅缓存元数据的两级缓存,既提升了数据缓存量,又确保了冷数据剔除的准确性。缓存替换策略链表结构如图5 所示。
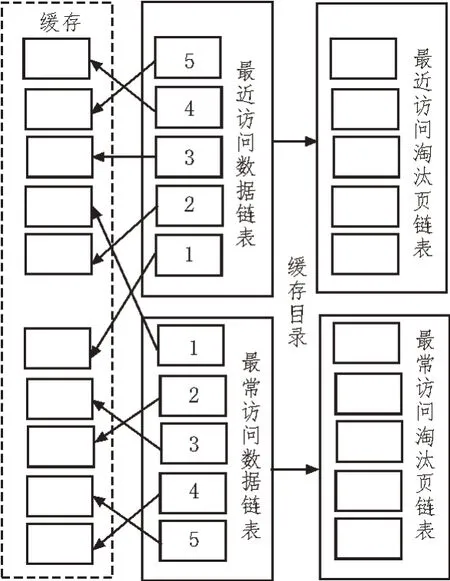
图5 缓存替换策略链表结构
最近访问数据链表与最常访问数据链表中的数据块均依据访问时间进行有限序列排列。若用户正在访问某数据,检索系统缓存该数据块时,将该数据块插入最近访问数据链表中,以此替换链表中最后一个数据块;若该链表中即将被替换的数据块被用户二次访问,则将该数据块插入最常访问数据链表1号数据块处,其余数据块后退一步,淘汰链表末尾数据块完成缓存替换。
若用户访问某数据时,缓存占用率超出系统缓存阈值,则删除链表内最近最少使用的数据元素,同时将与该数据对应的元数据信息存储至最近访问淘汰页链表与最常访问淘汰页链表中,淘汰页链表仅存储访问索引,不存储数据。在删除链表数据元素至淘汰页链表时,链表内数据元素均传输至与其相对应的淘汰页链表内,并释放被删除数据块在原链表内所占空间[14]。
若用户所访问的数据在淘汰页链表内,则需从数据库内读取用户所需数据元素,同时将该数据插入最近访问数据链表中。动态检索的分布式缓存方法能够通过各淘汰页链表内发生的伪命中次数,动态调整最近访问数据链表与最常访问数据链表应包含元素的数量。
动态检索的分布式缓存方法通过建立元数据缓存,迅速读取刚被淘汰的缓存数据,且依据用户最近访问时间及历史访问次数识别热数据,提升缓存内数据块被用户选择的潜力。
1.3.2 科技文献信息动态检索
检索系统处理层检索处理模块选取Lucene 项目设计完整科技文献信息动态检索引擎,该项目是一个以Java 为基础的可扩展开源搜索项目,具有全文检索及搜寻引擎架构。检索系统在Lucene 搜寻引擎架构的基础上,通过确定检索科技文献目标信息并重组相似类型科技文献索引信息,提升系统检索速度。为确定检索科技文献目标信息位置,分别从目标信息位于标题处及正文处两个方面进行优化确定,设置检索系统科技文献信息数据库中目标信息位于标题处的权重表达式为:
式中,a为检索科技文献目标信息;d为数据库内全部网络资源的索引信息;δ为目标信息出现于标题内的次数;ωa∈d,title为目标信息在查询标题处的位置权重;σa∈d,title为目标信息的关键词数量。
设置检索系统科技文献信息数据库中目标信息位于正文处的权重表达式为:
式中,ωa∈d,text与θ分别为目标信息出现于正文内的位置权重及次数;σa∈d,text为目标信息的关键词数量;|f|为数据库内待检索特征词的全部数量。确定检索科技文献目标信息位置后,设计科技文献信息动态检索流程,如图6 所示。用户在检索系统搜索引擎中输入检索信息,检索系统从科技文献信息数据库提取待索引信息数据为字符串型数据,分词处理字符串同时写入索引文件内,读取索引文件内索引并对热数据库中的索引信息进行分词处理,依据搜索索引判断两种信息是否为相似类型信息,若是相似类型信息,则将两种信息依据关联程度进行排序重组,获取检索结果;若不是相似类型信息,则将该信息返回至分布式存储模块内等待下次搜索。

图6 科技文献信息动态检索流程
采用动态检索的分布式缓存方法建立元数据缓存并获取热数据,利用目标信息在标题处及正文处的位置权重,设置检索系统的加载内容,通过Lucene搜寻引擎架构检测数据,获取子类元数据同时与热数据库内的数据进行关联排序重组,完成基于分布式缓存的科技文献信息动态检索系统软件设计。
2 实例分析
为验证所研究基于分布式缓存的科技文献信息动态检索系统整体性能,实验将系统应用于某科技大学图书馆内,该学校师生共计22 578人,图书馆建筑面积5 219 m2,馆内藏书25 万余册。实验选取自动化测试工具JMeter 模拟不同的工作负载,并设置负载工具测试参数为128;系统存储大小为256 GB;分布式存储模块大小为64 GB;分布式对象存储大小为1 MB。
IOPS(系统每秒读写次数)是衡量系统存储性能的关键指标。为验证系统在负载状态下的运行性能,通过JMeter 自动化测试工具为系统加载不同程度的请求数据,并对请求数据进行随机读写操作请求,获取测试系统IOPS 及读写宽带等数据。不同负载下设计系统运行性能测试结果如图7 所示。通常以4 kB 大小的数据块为基准测试系统IOPS,采用JMeter 测试工具对系统加载4~40 kB 的请求数据,并对系统进行随机读写的操作,IOPS 随机读取值为1 700~1 900,随机写入值为230~510,通过IOPS 随机读写值可知,设计系统存储数据不卡顿,随机读写速度较快;图7(b)中设置请求数据量为1~10 MB,随机读取带宽为820~870 MB/s,随机写入带宽为410~450 MB/s,由此可知,设计系统传输数据能力较强,系统响应时间较快。

图7 检索系统运行性能测试结果
全类平均正确率(MAP)是评价检索系统多次查询的平均准确率衡量指标,为验证设计系统的检索性能,实验选取500 位在校学生作为研究对象,分别操作文献[7]基于双向索引的高效连接关键字查询动态检索加密系统、文献[8]基于特征包的数字图书馆图像检索系统以及设计系统,每人检索10 条科技文献信息,通过MAP 指标对比三个系统的检索性能,对比结果如图8 所示。
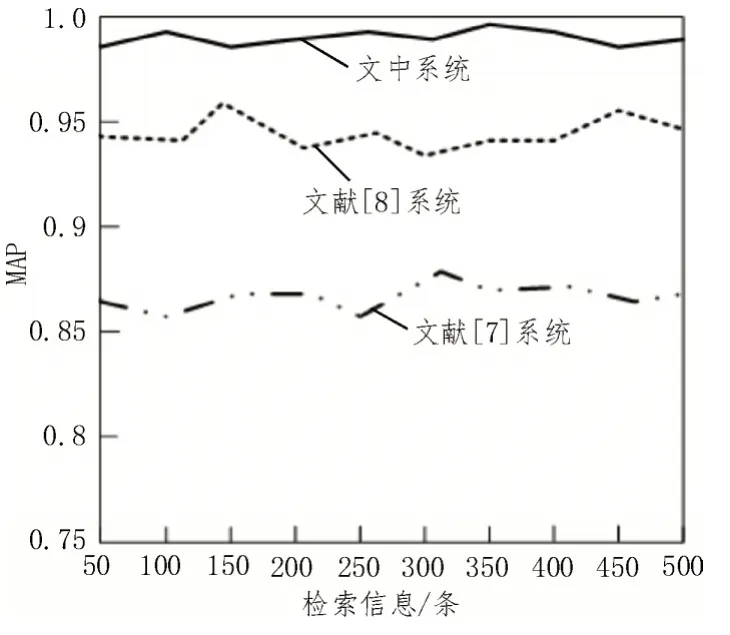
图8 三个系统检索性能对比结果
由图8 可知,通过50 位在校学生的多次查询对比结果可知,三个系统的MAP 值均在0.85 以上,总体检索性能都比较良好,其中系统的MAP 值始终位于0.95 以上,MAP 值明显高于文献[7]及文献[8]系统,用户输入的检索关键词与系统检索结果关联度越高,MAP 值越高,由此可知系统的检索性能较好。
3 结论
在传统检索系统中,文献信息内出现的检索字词都会作为检索结果展示出来,导致用户体验感较差。基于此,设计基于分布式缓存的科技文献信息动态检索系统,采用分布式缓存及动态检索的方式,同时考虑用户最近经常访问的文献信息与检索字词在标题处及正文处的位置权重,结合数据库内最新科技文献资料,为用户检索出最优质的检索结果,满足用户检索需求,提升用户的检索体验。
猜你喜欢
成都信息工程大学学报(2019年2期)2019-08-28
第二课堂(课外活动版)(2019年12期)2019-02-10
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
成都信息工程大学学报(2018年1期)2018-05-31
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
