
基于强化学习的多雷达抗干扰算法研究
2024-04-11 01:36智永锋邱璐莹高红岗师浩博
现代雷达 2024年2期
智永锋,邱璐莹*,张 龙,高红岗,师浩博
(1. 西北工业大学 无人系统技术研究院, 陕西 西安 710072) (2. 西北工业大学 民航学院, 陕西 西安 710072)
0 引 言
随着科技发展,大量无线电设备使用,造成了频谱拥挤。2000年,文献[1]提出了认知无线电,把无线电赋予智能化,能够智能响应用户的感知需求。2002年,联邦通信委员会针对频谱效率问题对认知无线电做出定义。软件无线电技术的完善,为认知无线电研究打下了坚实基础。雷达在战争发挥着重要作用,而战场环境瞬息万变,有其他电子设备干扰,有敌方干扰机干扰,还存在着环境杂波。为解决此类问题,需要推进雷达智能化发展。2006年,文献[2]提出了认知雷达概念,让雷达根据探测的环境情况,调整自身参数,提高雷达检测跟踪能力。认知雷达的提出,为人工智能理论用于雷达抗干扰指明了方向。文献[3]提出了认知雷达的感知-行动循环,把感知数据作为记忆以预测未来环境进行决策。文献[4]把认知雷达用于汽车雷达的抗干扰,让波形在测量周期内自适应地调整以达到抗干扰的目的。文献[5]通过均衡契约的方式进行频谱共享,文献[6]提出了军用频谱共享的框架。
本文将环境划分为多个子频段,用马尔可夫模型对多雷达系统进行建模,对扫频干扰每一时刻占用频段进行建模。对双深度Q网络(Double DQN)强化学习算法进行改进,与门控循环神经网络相结合,使之能处理依赖于长时间序列的干扰问题。提出了基于门控循环单元的深度确定性策略强化学习算法,其针对Double DQN强化学习中的网络臃肿和行动集巨大问题进行了改进。最后,进行了两种网络对于单雷达系统和多雷达系统的对比仿真实验,证实了深度确定性策略梯度递归网络能达到与双深度递归Q网络同样的性能,但深度确定性策略梯度递归网络的输出维度更小,且两算法都实现了多雷达系统的抗干扰及不对己方其他雷达造成干扰。
1 雷达干扰系统模型
1.1 雷达扫频干扰
扫频干扰是一种随着时间变化而不断改变频率的干扰。扫频干扰可以是一次占用一个频带也可以是一次占用多个频带,可以是频带每一时刻左移或右移一位或多位。将干扰所在频带抽象为二进制符号,0代表此频带未被干扰占用,1则相反。例如,把300 MHz的频段分为6段,则每一频带占用50 MHz,假设扫频干扰每次占用100 MHz,每一时刻右移50 MHz,则其表示如图1所示。

图1 扫频干扰示意图
1.2 雷达系统
雷达包括有单雷达、多雷达系统。雷达系统中,雷达发射电磁波,电磁波碰到环境障碍物反射回来,形成回波信号,雷达接收回波信号。接收的信号不仅有反射的电磁波频移信号,还有干扰。雷达大脑根据过去的经验,对当前情况做出决策判断,动态地根据历史中不同情况下采取的决策而变化,使其能够自适应调整决策,应对未知环境。雷达框架如图2所示。

图2 雷达系统框架
上述过程可以看作是一个马尔可夫过程[7-8],雷达下一时刻做出的决策仅与当前的环境状态有关,而与过去环境状态无关,可以用一个五元组(S,A,F,R,γ)来描述,其中
Ftn|t1…tn-1(sn|sn-1,an-1,…,s1,a1)=
Ftn|tn-1(sn|sn-1,an-1)
(1)
式中:S为状态空间;A为动作空间;F为状态转移概率即环境变化函数;R为奖励函数;γ为折扣因子。
在多雷达系统不仅存在着环境的干扰,还存在着周围雷达的干扰。在本文中,将雷达作为智能体进行研究,智能体检测到环境状态包括了外界干扰和其他雷达干扰的总和,即
Sit=It+At-1
(2)
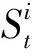
多雷达有两种方案,一种是多个系统共用一个大脑,还有一种是每个系统各有一个大脑。在实验部分将对这两种方案分别进行表述。
2 强化学习算法模型
强化学习主要是根据环境信息,智能体做出动作,环境对于智能体做出的动作进行评估,反馈给智能体一个奖励值。智能体根据环境反馈的奖励情况调整自身的策略,根据下一时刻环境状态做出动作,以此类推,如图3所示。

图3 强化学习基本模型
有学者提出了Q表格的方法,把环境状态和行动量化成一个表格,智能体得到一个环境状态,做出一次行动,都在表格上填上相应的奖励值,这里奖励值就相当于Q值,如表1所示。

表1 Q表格
环境状态数m的大小取决于环境状态维度和每一维度下的取值个数。如果环境维度和取值个数较大,将会导致上述表格十分巨大,在程序运行时,消耗巨大的内存资源,时间复杂度高。于是有学者就提出了将神经网络用于智能体决策。对于神经网络,输入的大小等于环境状态维度,输出的大小等于行动个数,智能体利用环境状态,经过一系列前向神经网络运算就可以得到每个行动的Q值,选择最大的Q值作为本次行动,再通过环境的奖励反馈给神经网络。
直接把奖励作为训练方向的判断会引起网络的震荡,使网络不易收敛。在奖励范围大,变化剧烈情况下,这种直接的方法对于长期任务来说并不适用,通常需要考虑下一时刻的奖励,对目标Q值进行软更新。
(3)
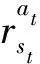
在雷达系统中,雷达仅仅根据当前的干扰环境状态,通常是无法判断干扰的下一刻走向的。长短时记忆网络即LSTM网络通常用于语音识别、语义识别,它具有一定的记忆,可以通过过去一段时间的状态推测现在的输出。扫频干扰与时间序列有关,有必要结合语言识别中常用的LSTM网络,作为雷达智能体抗干扰的一部分,门控循环单元有LSTM网络的优点,网络参数少,易于训练收敛,因此最终将门控循环单元加入了雷达智能体。针对雷达抗干扰方面,提出了下面两种方法进行对抗。
2.1 改进双深度递归值强化学习
双深度递归值网络(GRU-DDQN)由双深度强化学习(Double DQN)网络进化而来[9]。Double DQN采用神经网络取代Q值表格,防止了环境状态数过大;建立了两个网络,一个用于计算当前Q值,一个用于计算下一状态Q′值,两个网络不完全一样,Q值网络一种在更新,而Q′网络只有在运行一定步数后,把Q值网络复制过来,这样两个网络有延迟,可以防止估计的Q值过大而引起网络的不稳或网络估计的失真的问题。网络结构如图4所示。
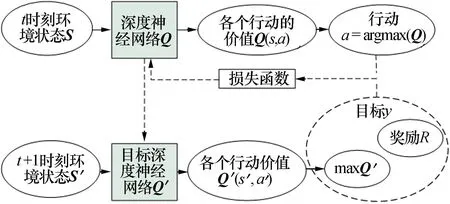
图4 Double DQN强化学习架构
由于Double DQN具有无后向性,无法学习与时序状态有关的行动策略,为了使智能体能处理依赖于长时间序列的干扰问题,提出了循环神经网络与深度强化学习相结合的方法。循环神经网络主要是用于序列数据的处理[10],在强化学习中加入循环神经网络可以使雷达做出抗干扰性能更好的决策。循环神经网络中的门控循环单元网络(GRU)有长短时记忆循环网络(LSTM)的优点[11-13],解决了长期依赖的梯度爆炸问题和梯度消失问题,又减少了网络参数,加快训练和收敛速度。
本文把频谱分割成五个频段,网络的输入是5×5大小的,网络的输出大小为1×15。根据行动、奖励和价值估算,计算出与神经网络输出值相对应的价值Q,通过最小化Q与目标y之间的差或者均方差,即最小化损失函数,来更新网络权重。网络结构如图5所示。

图5 GRU-DDQN强化学习架构
2.2 深度确定性策略门控循环强化学习
当行动的数目太多时,网络变得难以训练或收敛。为了解决这个问题,提出了基于深度确定性策略门控循环强化学习(GRU-DDPG),主要是将基于值学习的方法变为基于策略的方法,将门控循环单元网络与深度确定性策略梯度强化学习(DDPG)项结合。策略梯度更新公式为
(4)
式中:θ是神经网络模型参数;U(θ)是参数为θ下的期望奖励;θU(θ)则是对期望奖励函数中的参数θ进行求导;T为智能体完成一个序列的长度;m为训练数据的轮次大小;为在时刻t,第i轮中采取的动作;为在时刻t,第i轮中的环境状态;为策略函数;为在状态下的奖励;为时间t以后的折扣累计奖励,γ为折扣因子。
深度确定性策略门控循环强化学习[14]的网络输入层是GRU网络层,一共有四个神经网络,一个用于决定当前时刻下的环境状态做出的行动,一个是用于预测下一状态下的行动,一个用于评价当前状态和行动的价值,一个用于评价下一状态和预测的行动的价值。其算法结构如图6所示。

图6 GRU-DDPG网络结构
目标y的计算公式如下
y=Qtarget=R+γQ′
(5)
式中:Qtarget为目标值;R为环境奖励;γ为折扣因子;Q′估计下一时刻的评估值。
评估神经网络critic网络输入是当前状态和动作,输出对于当前状态动作的评估值,其更新是通过最小化目标评估值和评估值直接差距来梯度反向传播,更新网络。动作神经网络actor网络的更新是通过最大化评估值Q来实现。估计动作神经网络actor′网络和估计评分神经网络critic′网络分别由actor网络和critic网络更新而来,更新公式如下
(6)
(7)
3 结果分析
本次实验假设雷达能正确感知到环境并把感知情况化为一串0-1序列。假设雷达能发射占用连续频带的波形,只需要输出频段大小和位置即可,省略信号的发射部分。设置环境频谱大小为100 MHz,分为五个频带,每个频带占用25 MHz,干扰为扫频干扰。分别进行单雷达和多雷达的系统抗干扰[15]仿真,对每个系统采用两种方法进行仿真结果分析。
3.1 单雷达仿真
对于GRU_DDQN方法,即采用双深度递归Q网络的方法,使用奖励函数(8)作为环境反馈。
(8)
迭代20 000次后得到的曲线图如图7所示。

图7 GRU-DDQN方法用于单雷达
智能体的迭代奖励虽然能够快速升高,到5 000步之后基本可以达到奖励最大的情况出现,但智能体对于决策一直处于在较大范围震荡中,直到15 000步以后较为稳定。雷达智能体对于抗干扰的测试结果如表2所示。
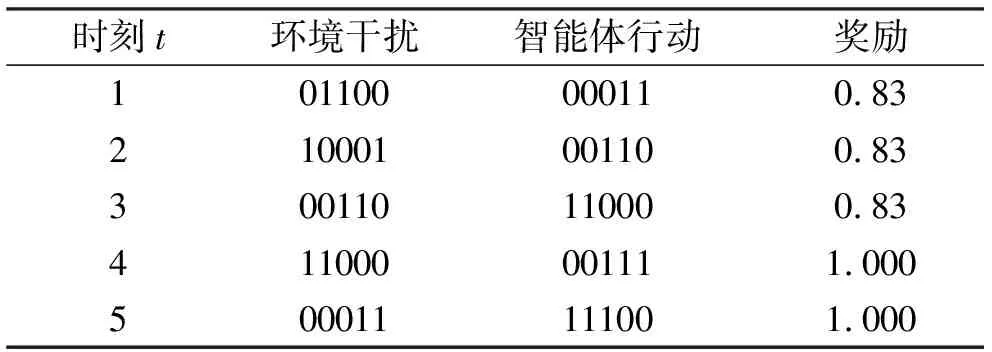
表2 GRU-DDQN测试结果
从表中可以看出雷达智能体做出的行动占用的频点不与干扰的频点相撞,智能体可以躲避干扰所在频点。智能体有时无法占满没有干扰的频点,使得奖励值未达到最大。
对于使用深度确定性策略梯度递归网络,若使用与GRU-DDQN方法一样的奖励函数,则经常有陷入局部最优的情况出现,智能体不对环境发射信号。为了能更好地指导智能体寻找到每一状态下的最优策略,需要运用奖励函数为式(9)~式(11)
(9)
(10)
R=R1+R2
(11)
智能体使用上述奖励函数,基本可以达到最优奖励的行动。考虑到神经网络的输出空间大于智能体行动空间,属于输出空间但不在行动空间里的某些动作,在奖励函数(9)~(11)下,奖励大于在行动空间里的所有动作,智能体根据尽量往奖励大的方向靠拢,采取了不符合行动空间的动作。为了减少此类状况发生,就需要修改为奖励函数(12)~(14),如下所示。
(12)
(13)
(14)
R=R1+R2+R3
(15)
通过上述优化,离最优解的差别还是挺大的,为此我们将限制直接加入到智能体输出中,即当智能体的输出有多个离散的频段时,只取最左边的离散频段,示意图如图8所示。

图8 网络输出调整
实验结果如图9和表3所示。

表3 GRU-DDPG方法单雷达实验测试结果
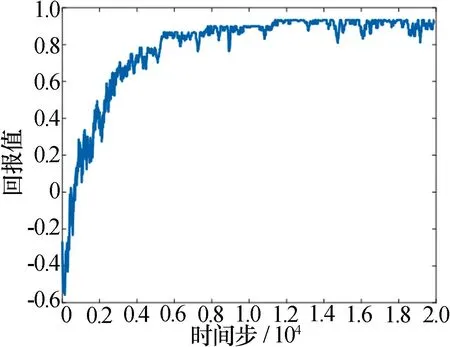
图9 GRU-DDPG方法用于单雷达
从表3中可以看到,雷达智能体的决策行动频点有效地避开了干扰,达到了抗干扰效果。智能体也会有错失可用频段的情况,但总体来说比未改进时的情况更好,迭代奖励值更高。
对两种方法的迭代曲线进行对比,如图10所示。

图10 GRU-DDPG和GRU-DDQN用于单雷达
从图10中可以看出两种方法都能达到相似的优化效果,但GRU-DDQN方法速度较快, GRU-DDPG方法变化平稳。
3.2 多雷达仿真
对于多个雷达来说,不仅要判断敌方的扫频干扰,还需要判断己方其他雷达造成的干扰。需要雷达具备更高智能性,对网络提出了更高的要求。多雷达当前有两种方案:一种所有雷达智能体共用一个大脑做出决策,另一种是每个雷达智能体都有各种的神经网络大脑。实验证明,只使用一个大脑的效果并不理想,它虽然能躲开外部的干扰,但对内部干扰无能为力,会让所有的智能体都趋向于使用同一频段,他们检测到的环境状态基本相同,同一输入状态、同一神经网络结构和参数,必然会输出相同的决策。当所有智能体都使用同样决策时,频谱冲突就无法避免,自然会引起相互干扰。其实验结果图和数据如图11和表4、表5所示。

表4 方案1的GRU-DDQN测试结果

表5 方案1的GRU-DDPG测试结果
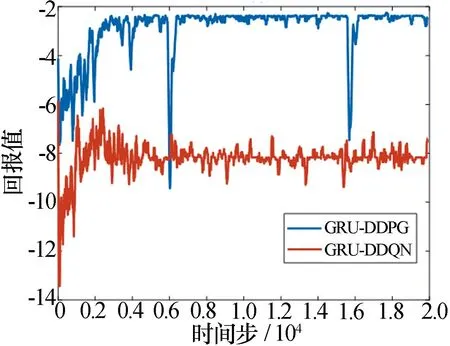
图11 方案1(多个雷达单大脑网络)迭代曲线
由图11、表4和表5可知,在方案1中,由于多个雷达智能体在每一时刻都采取同一动作,导致智能体之间的决策相互冲突,奖励一直为负。
为了解决智能体总是采取同一动作,我们采取了方案2。基于GRU-DDQN算法和基于GRU-DDPG算法的实验结果如图12和表6、表7所示。
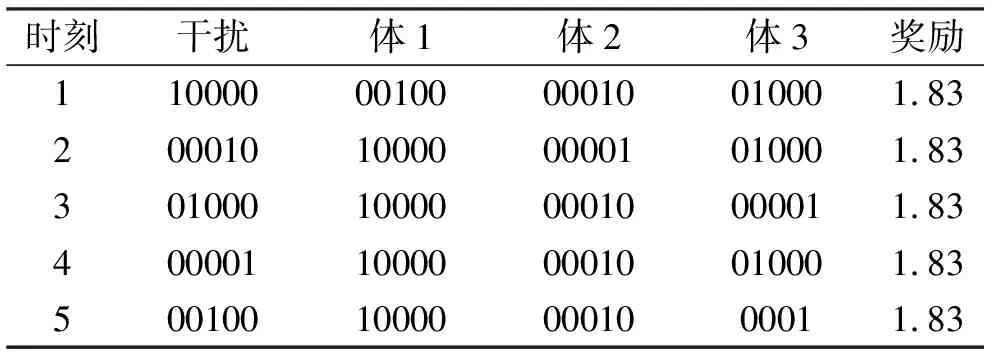
表6 方案2的GRU-DDQN多雷达结果

表7 方案2的GRU-DDPG多雷达结果
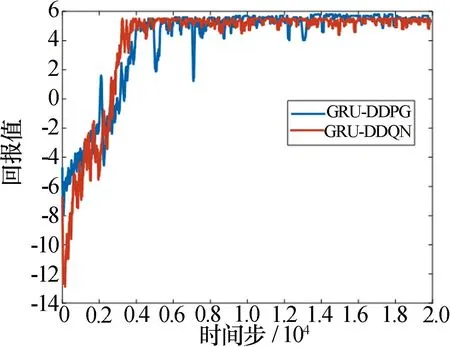
图12 方案2(多个雷达多大脑网络)迭代曲线
可以看到智能体基本上能避开环境干扰和其他智能体的干扰,获得较高的奖励。GRU-DDPG算法的效果稍好于GRU-DDQN算法。
4 结束语
本文针对雷达受到扫频信号的干扰的情况,提出了基于深度强化学习的多雷达共存抗干扰算法。对环境进行模型的建立和简化,采用双深度循环Q网络进行抗干扰解算,将其循环网络修改为门控循环单元,取得了良好的效果。提出了一种深度确定性策略梯度递归网络,该网络在频带数量多的时候,可以减小网络的神经元个数,大大节省网络的存储空间。实验结果表明,本文的算法可以使雷达系统避开存在干扰的频点,有效降低来自外界和己方雷达相互之间干扰。
猜你喜欢
大自然探索(2023年7期)2023-08-15
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
小学生学习指导(低年级)(2018年12期)2018-12-29
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
重型机械(2016年1期)2016-03-01
火控雷达技术(2016年3期)2016-02-06
大连工业大学学报(2015年4期)2015-12-11
