
不同自然语言处理方法在土壤环境污染调查报告文本信息抽取中的对比研究
2024-04-01 08:09孙维维潘贤章郭观林
环境科学研究 2024年3期
孙维维,潘贤章,2,刘 杰*,郭观林,李 衍,王 娟,项 钰,王 睿
1. 中国科学院南京土壤研究所,土壤与农业可持续发展国家重点实验室,江苏 南京 210008
2. 中国科学院大学,北京 100049
3. 生态环境部土壤与农业农村生态环境监管技术中心,北京 100012
4. 讯飞智元信息科技有限公司,安徽 合肥 230088
随着我国工业化的快速发展,早期不合理和粗放式的管理遗留了大量污染场地[1]. 为防控污染地块环境风险,保护生态环境并保障人民的身体健康,对有关地块进行土壤环境污染调查是必不可少的步骤[2].我国于2016 年启动了《土壤污染防治行动计划》,明确深入开展以农用地和重点行业企业用地为重点的土壤环境质量调查,并建立土壤环境质量状况定期调查制度[3];同年,原环境保护部出台《污染地块土壤环境管理办法》,进一步规范了污染地块环境保护监督管理,土壤环境调查、风险评估、风险管控、治理与修复及其效果评估等相关文本数据爆发式增长,积累了丰富的地块土壤环境信息[4-6]. 土壤环境调查报告包含地块名称、位置、面积、利用历史、环境资料等基本信息,以及现场踏勘、采样分析、评估、结果分析等重要信息,因此对其文本要素信息进行结构化抽取可有效支持污染场地智能化管控[7]. 利用自然语言处理(natural language processing,NLP) 方法,研究者开展了许多环境文本信息抽取研究,如从环境科研文献中提取元数据信息[8],从在线新闻中提取环境事件信息[9],以及从调查报告提取土壤-环境关系[10]等. 然而,仍然缺乏从土壤环境污染调查报告中系统性抽取文本要素的研究,满足不了管理部门对场地状况快速精准掌控的数据需求[11-12].
近年来,随着NLP 技术的发展,计算机对人类语言的理解和处理能力日益提升[13-14]. NLP 技术涉及计算语言学、人工智能等多个领域,可用于文本分类、信息抽取及机器翻译等多个方面[15-19]. 其中,信息抽取是NLP 的一个重要分支,主要是指从文本数据中抽取特定信息的技术. 对于具有特定组合规则的文本,通过定义一定的语言组合规则,利用传统规则匹配方法可以实现相关要素信息的抽取. 利用基于规则的方法,研究者对科研文献中的方法文本要素进行了抽取[20-21],对Web 网页文本内容抽取也进行了探索[22].这种方法在解决一些简单任务时可有效抽取大量要素信息并提高效率,但随着任务复杂度的增加,规则编写难度会愈来愈大,且需要大量的人工干预,因而该方法可扩展性和泛化能力受到限制[23].
随着深度学习技术的兴起,基于卷积神经网络(convolutional neural networks,CNN)、循环神经网络(recurrent neural network,RNN)等进行文本信息抽取的研究不断涌现[24]. 2017 年,谷歌提出了具有里程碑意义的转换器(transformer)模型,此后基于该模型发展的生成式预训练转换器(generative pre-trained transformer,GPT)[25]、转换器的双向编码器表示模型(bidirectional encoder representations from transformers,BERT)[26],持续推动着人工智能方法处理文本能力的提升. 相对于传统规则匹配方法,BERT 预训练语言模型从单词的两边(左边和右边)来考虑上下文,且具有更好的泛化能力和扩展性,可以处理更加复杂的自然语言任务,如问答、文本分类及命名实体识别等. 基于BERT模型,谢腾等[27]对中文命名实体要素识别进行了研究,吴俊等[28]对中文专业术语的抽取进行了研究,景慎旗等[29]对中文电子病历中医学要素抽取进行了研究,都取得了较好的效果. 基于BERT 模型的方法依赖大规模领域标注数据进行训练,需要专家经验的支持及人工标注,而基于GPT 模型的ChatGPT 在一定程度上能够减轻对监督学习的依赖.
已发布的基于GPT-3 模型[30]的智能聊天语言生成器ChatGPT[31](https://chat.openai.com),因其高水平的文本交互能力而在短时间内吸引了全球关注. 作为一个自回归语言模型,GPT-3 延续了GPT 的单向语言模型训练方法,使用更多的参数来提高上下文学习能力,对45 TB 的数据进行训练,包含1 750 亿个参数. ChatGPT 作为一个通用助手,具有强大的自然语言理解和生成能力,可以处理多种开放的自然语言处理任务,极大地改变了人们处理文本信息的方式,在教育、搜索、医疗等行业产生了深远影响[32-37]. ChatGPT具有从非结构化文本中提取出(半)结构化信息的能力,且表现出了较好的效果[38],为从土壤环境污染调查报告中抽取关键文本信息提供了新思路. 本研究使用传统规则匹配、BERT 和GPT(ChatGPT)语言模型等NLP 方法,分别对土壤环境污染调查报告文本中的关键信息进行抽取,并对结果进行对比分析,探讨不同方法的适用性和局限性.
1 材料与方法
1.1 实验数据
针对土壤环境污染调查报告内容特征与应用需求,梳理出地块基本信息、污染源信息、迁移途径信息等8 个方面的关键文本要素,形成了包括“地块名称”“地块类别”“地块占地面积”等112 类需抽取的文本要素标签. 本研究中,共用到378 份PDF 格式的土壤环境污染调查报告(来自北京市、天津市、广东省、江苏省和安徽省5 个省市),首先按照章节目录将报告转换为文本格式. 其中,363 份作为BERT 模型的训练样本;同时,对另外15 份中涉及敏感信息的文本以其他随机字符进行替换,用以评估不同NLP 方法的抽取效果.
1.2 技术框架
根据《建设用地土壤污染状况调查技术导则》(HJ 25.1-2019),土壤污染状况调查报告相关内容具有一定的格式和要求,主要包括概述,地块概况,资料分析,现场踏勘和人员访谈,采样和分析,结果和评价,以及结论和建议等内容. 因此,基于调查报告内容特征和专家经验,制定了本研究的技术框架(见图1):首先,通过对文档报告目录的解析,按照章、节等进行拆分,转换为txt 文本;其次,结合文本要素标签,分别利用传统规则匹配方法、BERT 模型、GPT 模型方法,进行文本要素信息抽取;最后,对不同NLP 方法抽取效果进行评估,探讨不同方法的适用场景.
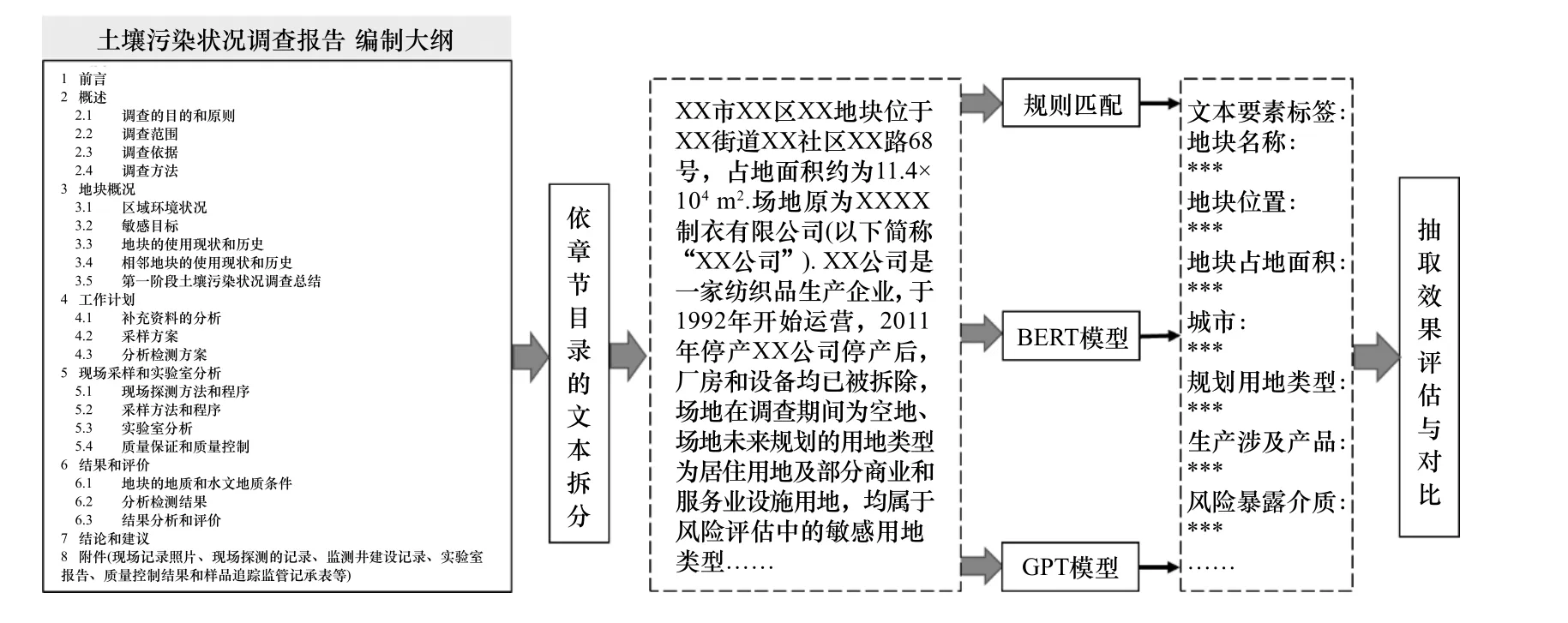
图1 研究的技术框架Fig.1 The technical framework of the study
1.3 传统规则匹配方法
传统规则匹配方法是指根据相关标准规范和专家知识,对特定领域的文本术语进行识别,通过归纳总结,自定义构建该领域的语言规则集合,并根据规则在文本中查找各要素标签对应的信息. 理论上来讲,只要制定足够多的语言规则并确定合适的优先级,就能得到较高的信息抽取准确率[23],但是相关规则的构建需要专家经验,且耗费大量的人力和时间. 根据调查报告中文本的共性特点,针对112 类文本要素标签,分别制定了信息抽取的匹配规则,进而识别包含特定关键词的句子. 例如,对于“四至范围”要素标签,将“四至”或“东至”“西至”“南至”“北至”等关键词加入匹配规则,包含这些关键词的句子都自动抽取到“四至范围”标签的内容. 最后,基于构建的匹配规则,对15 份报告进行了要素信息抽取,将返回的抽取结果存储在数据库或表格中,并进行模型抽取效果的评估.
1.4 BERT 模型
BERT 模 型 采 用BERT-BiLSTM-Attention-CRF模型结构(见图2),首先,基于调查报告文本要素标签和专家经验,在土壤环境污染调查报告中人工标注要素标签对应的文本内容;其次,对标注内容的单个字符进行编码,得到单个字符对应的词向量,接着利用BiLSTM 层对输入文本进行双向编码,在解码前使用注意力机制增加上下文相关的语义信息,并将包含上下文信息的语义向量输入条件随机场(conditional random field,CRF) 进行解码,CRF 层可以输出概率最大的标签序列,从而得到每个字符的类别,进而形成文本要素抽取模型;同时,对于抽取效果较差的要素标签,通过优化文本标注、模型参数等手段,进一步优化抽取结果.
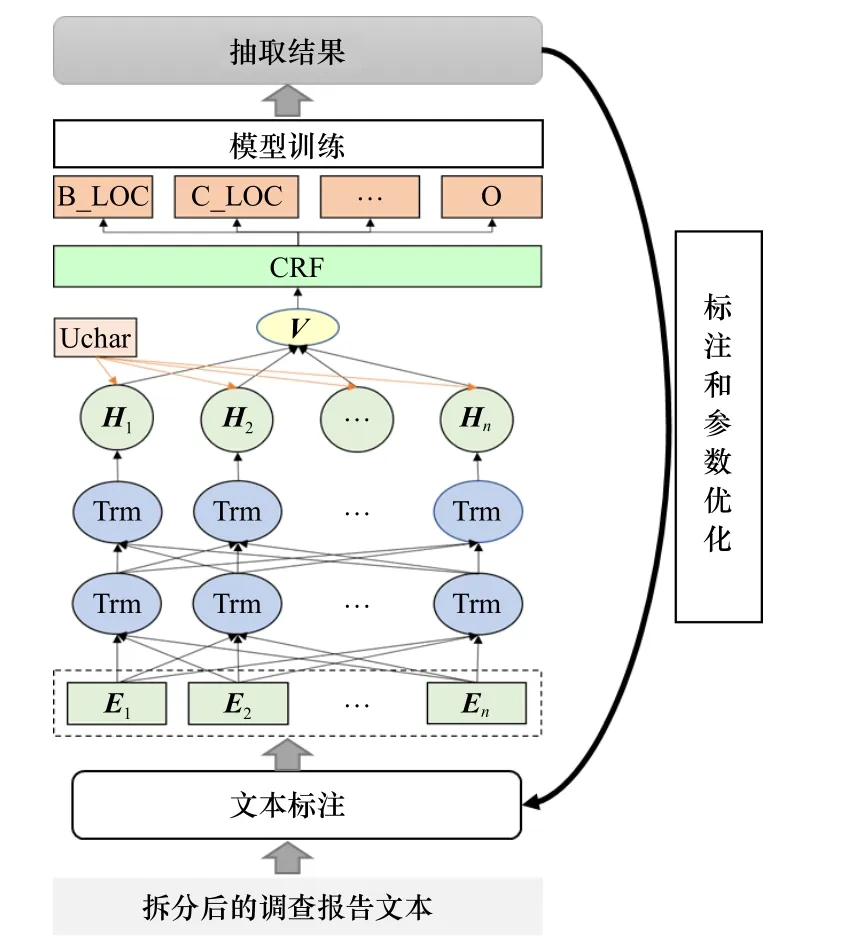
图2 基于BERT 模型的文本要素抽取流程Fig.2 The process of text element extraction based on BERT model
在本研究中,对363 份报告进行标注获取到81 122条要素标签对应的文本信息,将其按8∶2 的比例划分为训练集与测试集,经过多轮标注和参数迭代优化,获取到最优的BERT 文本要素抽取模型,将另外15份报告作为新鲜样本用于模型的效果评估.
1.5 GPT 模型
ChatGPT 3.5 是在GPT-3 的基础上,采用一系列的模型(GPT-3.5,包括3 个GPT-3 变体,每个变体有13 亿、60 亿和1 750 亿个参数) 进行更大规模的训练. 依托于大型GPT 模型结构[25],该模型使用了多层单向的Transformer 解码器,并采用随机梯度下降训练神经网络参数(见图3). GPT 针对下游任务采用统一框架,直接在Transformer 的最后一层连接softmax作为任务输出层,减少了计算复杂度. 模型采用多头自注意力机制对输入文本的上下文向量进行处理,然后由位置感知的前馈层对目标词向量产生输出分布,计算公式如下:

图3 基于GPT 模型的文本要素抽取流程Fig.3 The process of text element extraction based on GPT model
式中,U为标记的上下文向量,We为标记嵌入矩阵,Wp为位 置 嵌 入 矩阵,n为transformer 的 层 数,hm和hm-1分别为第m和m-1 层的输出,P(u)为输出分布.
首先,对于不同的要素标签,有针对性地制定了相应的提示词模板;其次,将隐藏了敏感信息的15 份报告进行文本拆分,之后输入ChatGPT 3.5 接口,利用提示词向GPT 模型提出要抽取的文本信息;再次,对于抽取效果较差的要素标签,通过优化提示词手段改进抽取结果;最后,将返回的标签信息存储在数据库或表格中,用于后续的效果评估(见图4).

图4 基于提示词的GPT 模型交互式文本要素抽取示例Fig.4 The example of interactive text element extraction with GPT model based on prompts
1.6 评价方法
采用准确率(Precision)、召回率(Recall)和F1 分数作为评价指标,对文本要素抽取效果进行评估. 准确率是指正确识别出的信息数占总识别出的信息数的比例;召回率是指正确识别出的信息数占所有存在信息数的比例;F1 分数是准确率和召回率的调和平均数. 各项指标的计算公式如下:
式中,P为准确率,R为召回率,TP 表示真正例(即正确抽取的信息个数),FP 表示假正例(即错误抽取的信息个数),FN 表示假负例(即存在但未抽取出的信息个数).
2 结果与讨论
2.1 总体结果和精度对比
利用3 种NLP 方法对15 份报告进行信息抽取,整体精度指标统计结果如表1 所示. 可以看出,传统规则匹配方法要素抽取精度较低,准确率、召回率和F1 分数分别为52.38%、21.15% 和30.14%;而BERT模型抽取效果优于传统规则匹配方法,其准确率、召回率和F1 分数分别为82.81%、33.21%和47.41%,相比于规则匹配方法分别提高了58.08%、57.00%、57.31%;GPT 模型的准确率、召回率和F1 分数分别达到97.80%、84.43%和90.62%,相比于规则匹配方法分别提高了86.70%、299.12%、200.70%,相比于BERT 模型分别提高了18.10%、154.21%、91.15%. 结果表明,在土壤环境污染调查报告的文本要素抽取任务中,GPT 模型具有较好的抽取效果,这是由于其上下文理解能力、预训练策略、模型规模等多种因素共同作用的结果. 因为GPT 对大规模文本数据进行了考虑上下文关系的无监督预训练,使其能够学到更丰富、更复杂的语言模式;同时,GPT 具有更大的参数量和深层的网络结构,这使得它能够更好地捕捉土壤环境污染调查报告中复杂和多样的文本信息,有助于抽取效果的提升.

表1 不同方法抽取效果对比Table 1 Comparison of extraction results of different methods
2.2 不同要素标签抽取效果
为了进一步分析3 种方法对不同要素标签的抽取效果,分别统计了每种方法对各标签信息的抽取精度. 在此仅展示24 个要素标签的抽取精度,因为其他标签要素在一种或多种方法下的TP+FP=0 或TP+FN=0,无法计算准确率或召回率,抽取准确度、召回率和F1 分数统计结果见图5、图6 和图7.
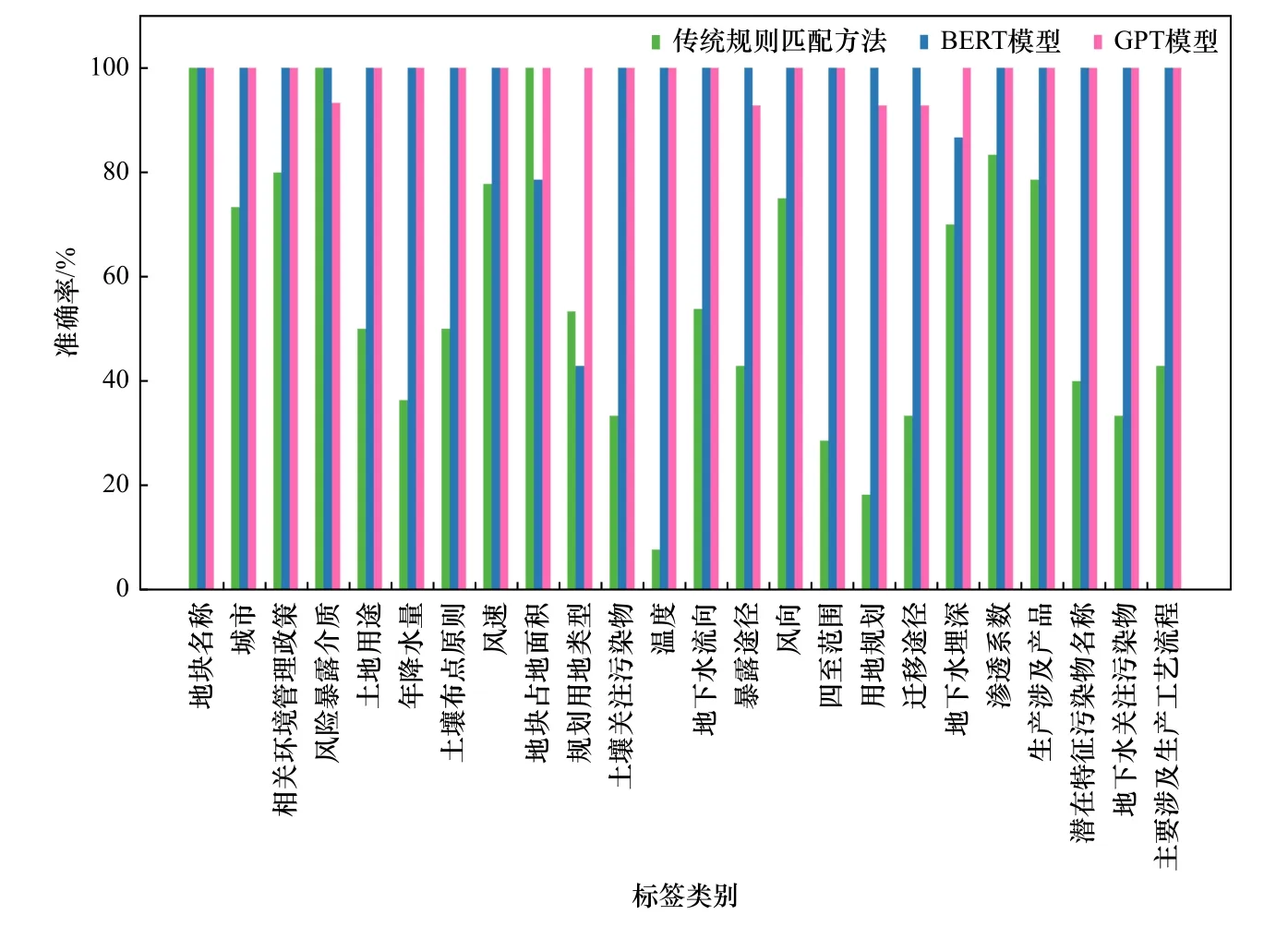
图5 不同标签要素的抽取准确率Fig.5 The accuracy for the extraction of each label element using three NLP methods
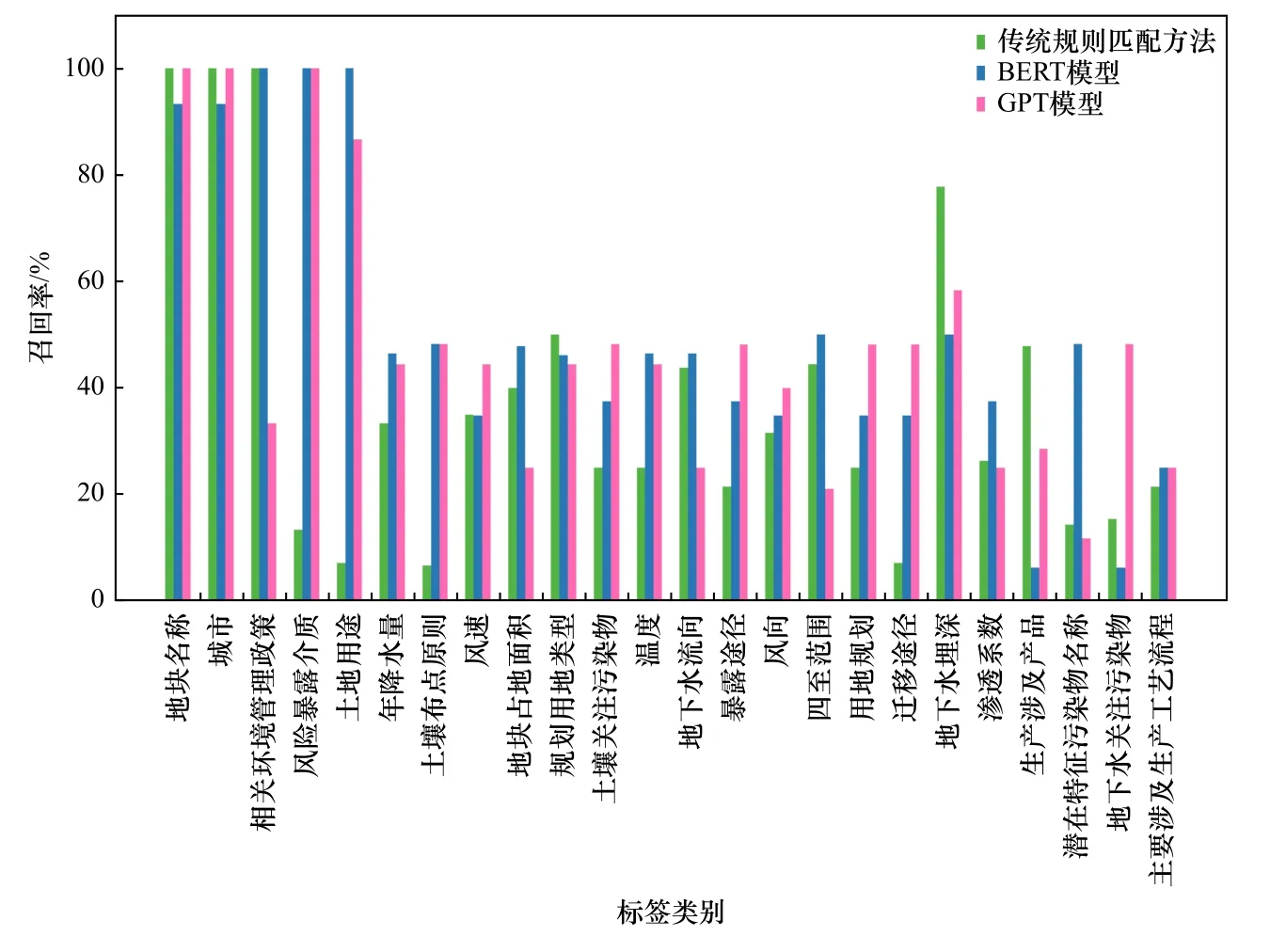
图6 不同标签要素的抽取召回率Fig.6 The recall for the extraction of each label element using threeNLP methods
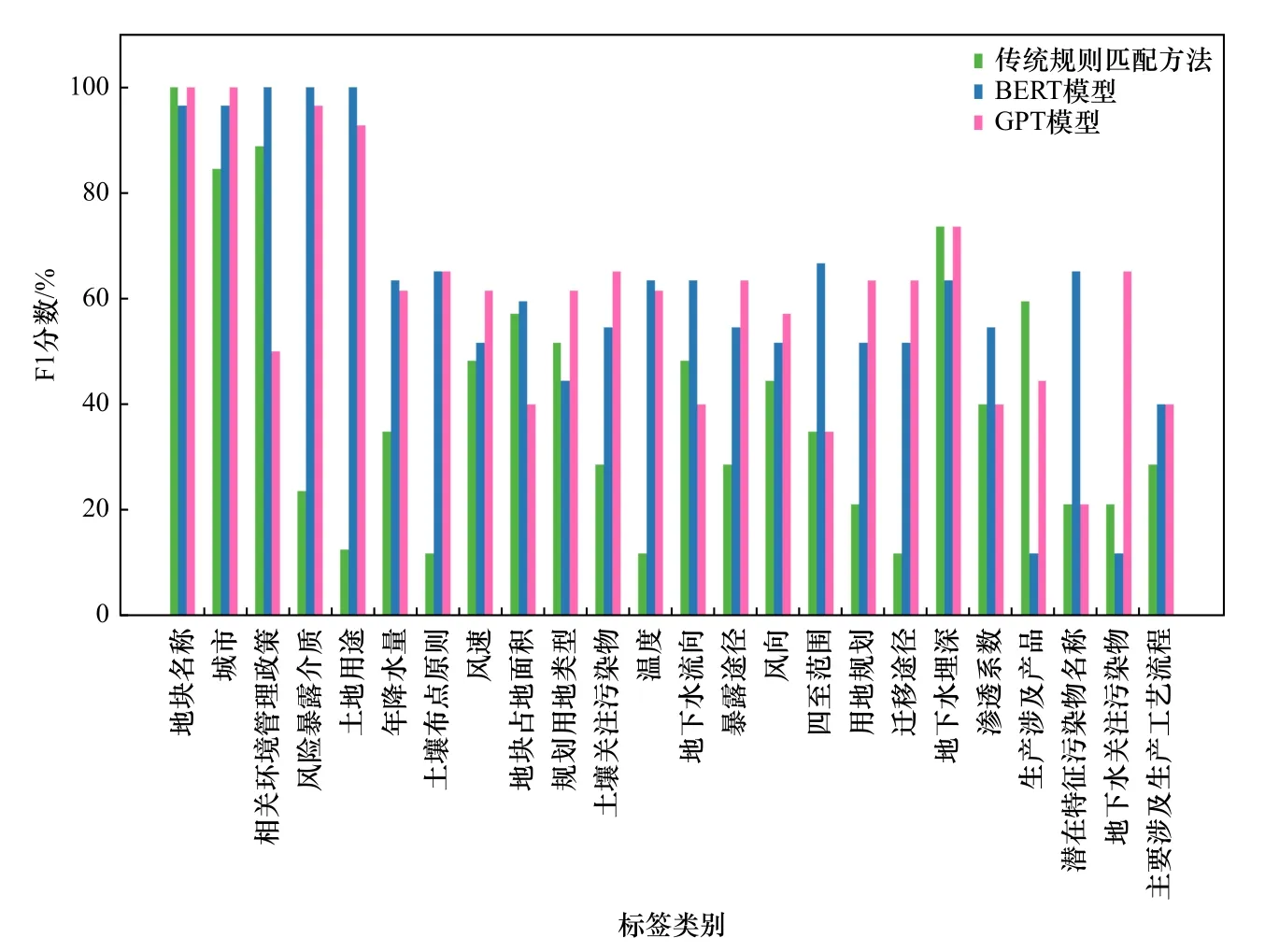
图7 不同标签要素的抽取F1 分数Fig.7 The F1-score for the extraction of each label element using three NLP methods
从准确率结果(见图5)可以看出,传统规则匹配方法对少数标签信息具有较高的抽取准确率,其中,“地块名称”“风险暴露介质”“地块占地面积”等5种标签信息抽取准确度在80%以上,而其他多种标签的信息抽取准确率较低,且“用地规划”“地下水关注污染物”等8 多种标签的信息抽取准确低于40%. BERT 语言模型对“地块名称”“城市”“相关环境管理政策”等22 种标签的信息抽取准确率大于80%,其中21 种标签的信息抽取准确率为100%,抽取效果比较稳定,而对“地块占地面积”的抽取准确率低于80%,对“规划用地类型”的抽取准确率低于50%. GPT 模型则对各项标签的信息抽取准确率相对较高,对24 种标签的信息抽取准确率都在90%以上,抽取性能比较平衡.
从召回率结果(见图6)可以看出,传统规则匹配方法、BERT 和GPT 模型的抽取召回率在80%以上的标签数分别为3、5 和4 个,而3 种方法对其余的大多数标签信息的召回率都在60% 以下,其中,在40%~60%之间的标签数分别为4、8 和11 个,在20%~40%之间的标签数分别为8、7 和5 个,并且,传统规则匹配方法对“风险暴露介质”“土地用途”“土壤布点原则”和“迁移途径”4 种标签信息的抽取召回率低于20%. GPT 模型的召回率相比准确率优势不明显,这可能是由于GPT 模型的生成能力较强,并且在抽取文本信息时存在一定的“冗余性”[37],有时甚至会生成与报告不相符的文本,比如只输出“详见第XX 节”,在精度评估时也将其归为错误抽取结果,从而影响了召回率.
从F1 分数结果(见图7)可以看出,传统规则匹配方法、BERT 和GPT 模型的抽取F1 分数在80%以上的标签数分别为3、5 和4 个,传统规则匹配方法仅对“地下水埋深”信息的抽取F1 分数在60%~80%之间,而BERT 和GPT 模型的F1 分数在60%~80%之间的标签数分别为7 和11 个,3 种方法的F1 分数在40%~60%之间的标签数分别为7、9 和7 个,在20%~40%之间的标签数分别为8、1 和2 个;同时,传统规则匹配方法对“土地用途”“土壤布点原则”“温度”和“迁移途径”4 种标签信息的抽取F1 分数低于20%,而BERT 对“生产涉及产品”和“地下水关注污染物”的抽取F1 分数低于20%.
2.3 讨论
从本研究的文本要素信息抽取效果可以看出,传统规则匹配方法对大多数标签信息的抽取精度较低,但对少数标签信息具有较高的抽取精度. 这是因为基于规则的方法需要手动编写规则,而这些规则可能无法覆盖所有情况,且难以处理复杂的语言结构和多义词等[39],因此,基于规则方法的信息抽取准确性受到限制,但此方法对大批量报告的提取具有效率优势,能适用于大量土壤环境污染调查报告中语言模式比较单一的要素标签(如“地块名称”“城市”等)的信息抽取任务. 相比之下,BERT 模型能够获得更好的抽取效果,特别是对于条目列举类要素标签(如“相关环境管理政策”等). 这是因为BERT 模型是基于大规模标注文本数据进行训练的,它能够自动地学习语言结构和上下文信息,从而更准确地抽取比较复杂的文本信息[40-42]. BERT 模型还可以解决多义词等语言难题,提高了抽取的准确性,但它有时会输出多个选项,而不是准确答案,如抽取“调查所处阶段”标签信息时,会将文本中出现的“初步调查”“详细调查”等字符都抽取出来. 此外,BERT 模型依赖大量有标注的文本数据,容易出现标签漏标、标签混淆、数据缺失等问题,需要在模型训练中反复采取优化标注标准、扩充标注数据和补充漏标标签等措施以优化模型[43].而GPT 模型具有更强的上下文理解能力,对多数标签的信息抽取综合表现较好,特别是对于总结判断类标签信息(如“厂区内是否有废水治理设施”等),具有较高的信息抽取精度和稳定性.
本研究中,BERT 和GPT 模型的训练方式不同,BERT 是基于有监督的方式进行的预训练,利用标注的土壤环境污染调查报告进行训练;而GPT 是基于无监督的方式进行的预训练,利用大量未标注的语料库进行训练,利用提示词进行文本要素抽取. 在预训练过程中,BERT 会学习到标注数据中的文本信息和规则,但这些规则可能并不适用于其他未标注的数据,因而对未标注或少量标注的要素标签信息进行抽取时,BERT 的效果可能会下降.虽然GPT 模型的预训练过程中没有受到标注数据的干扰,对新的标签信息抽取的泛化能力更强,但也有可能生成与实际不符的要素标签信息. 同时,在学习到一定量场地领域的知识后,BERT 模型对场地文本要素抽取效果更好.因此,在文本要素标签标注达到特定量的情况下,BERT 语言模型的信息抽取效果有可能会超过GPT模型[44].
综上所述,在本研究的土壤环境污染调查报告的文本要素抽取中,GPT 模型展现出了较好的抽取效果. 然而,ChatGPT 提示词构造存在主观性,不同提示词抽取效果也存在差异[45-46]. 已有研究发现,在标注训练数据集足够大时,GPT 模型在某些信息抽取任务中的表现不及BERT 等模型[26]. 因此,本研究中用于BERT 模型训练的标注数据量可能仍然是影响BERT 模型精度的主要因素. 虽然本研究中BERT 模型的整体抽取效果不及GPT 模型,但通过增加训练样本量、优化文本标注和模型参数等措施,其性能将会进一步提升. 考虑到标注样本数据需要大量的人力投入,因此,探索联合规则匹配、BERT 和GPT 模型等不同NLP 方法,利用各自方法的优势针对不同的文本要素标签制定相应的抽取策略,可能更适用于土壤环境污染调查报告信息抽取任务.
3 结论
a) 利用不同NLP 方法进行文本信息抽取时,GPT 模型在抽取准确率、召回率和F1 分数方面表现出色,分别达到97.80%、84.43%和90.62%,相比传统规则匹配方法,分别提高了86.70%、299.12%和200.70%;相比BERT 语言模型,分别提高了18.10%、154.21%和91.15%.
b) 不同的NLP 方法在土壤环境污染调查报告文本要素抽取中均有一定的适用性,GPT 模型准确率较高,但通过增加训练样本量、优化标注和模型参数等方法,BERT 模型可能会拥有更好的针对场地领域文本要素的抽取效果.
猜你喜欢
基层中医药(2022年4期)2022-07-22
现代畜牧科技(2021年9期)2021-10-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
车迷(2018年11期)2018-08-30
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2018年3期)2018-05-09
知识经济·中国直销(2017年11期)2017-11-28
公民与法治(2016年10期)2016-05-17
