
基于云平台输电变电设备故障率预测技术研究
2024-04-01 04:11万乐
电气技术与经济 2024年3期
万 乐
(烟台工程职业技术学院)
0 引言
电力系统是现代社会的重要组成部分,它们依赖于复杂的输电变电设备网络来保障能源的分配和传输[1]。因此,对输电变电设备的可靠性和稳定性提出了更高的要求。为了实现这一目标,电力行业正在积极探索基于云平台的故障率预测技术[2]。云平台提供了强大的计算和存储资源,可处理大规模数据,实现实时监测和预测。
1 云平台在电力行业中的应用
云平台在电力行业中的应用已取得显著进展[3]。它可用于数据存储、实时监测、分析和可视化。通过将传感器数据上传到云平台,操作人员可远程监控设备状态。云平台还可存储历史数据,用于故障率预测模型的训练和改进。
2 数据采集和处理
2.1 传感器观测变量
为了进行故障率预测,首先定义一组传感器观测变量,这些变量包括电流、电压、温度、湿度等。数据采集过程可表示为:
式中,N是采样点的数量;t是时间戳。这些采样的原始数据包含噪声和异常值,因此需要进行数据清洗和预处理。
2.2 数据清洗
数据清洗的目的是检测和修复异常值,以确保数据的质量和可用性[4]。异常值的检测和表示如下:
(1)计算观测变量Xi的均值μi和标准差σi,计算如下:
(2)设置异常值的阈值为α,随后定义异常值的界限。异常值可表示为以下条件:
若某个数据点Xi(t)k超过上述条件的阈值,则被视为异常值。这些异常值代表数据中的错误、干扰或设备故障等问题。一旦检测到异常值,可删除这些异常值,以确保数据的准确性和可信度。
2.3 数据预处理
在数据清洗之后,进行数据预处理,包括平滑、插值和特征工程。
2.3.1 数据平滑
在数据平滑中,本研究使用滑动窗口法进行平均滤波,其中M表示窗口的大小。平均滤波可以表示为:
式中,Xi(tk)是经过平滑后的观测值,Xi(tk-j)是原始观测值。经过平滑后的数据可减少数据的波动,使其更适合用于后续的分析。随后,进行数据插值以确保数据的连续性。
2.3.2 数据插值
数据插值用于填补缺失的数据点,以保持时间序列的完整性。本研究使用线性插值填补缺失的数据点。线性插值是一种常见的方法,它通过使用相邻时间点的观测值来估算缺失数据点,可用公式表示为:
2.3.3 特征工程
最后,进行特征工程,提取统计特征,以便用于故障率预测模型。统计特征包括平均值、方差、偏度和峰度。这些特征有助于模型捕捉数据的分布和趋势,同时也可用于检测异常情况。
特征工程为模型提供了有用的信息,帮助模型更好地理解数据。经过这些数据预处理步骤,得到经过平滑、插值和特征工程处理后的数据,这些数据可以用于训练故障率预测模型,提高预测的准确性和可信度。
3 基于深度前馈神经网络的故障率预测模型
深度前馈神经网络(FNN)可自动学习和捕捉数据中的复杂模式和关联,从而提供准确的设备故障率估计,以实现输电变电设备故障率预测[5]。因此本研究选择深度前馈神经网络建立输电变电设备故障率预测模型。输电变电设备故障率预测模型的建立过程如下:
(1)数据准备。首先,将经过数据预处理的数据集分为训练集和测试集。数据集中的大部分数据将用于训练模型,而剩余的数据将用于评估模型的性能。数据集包括多种特征作为输入,这些特征包括设备的操作数据(如电流、电压、温度等)以及环境条件(如湿度、温度、风速等)。将这些特征表示为一个输入向量X,X的表达式如下:
其中,Xi代表不同的特征。此输入向量将用于训练模型。
同时,设备的故障率作为输出标签也包括在数据集中。故障率可以表示为一个输出标签Y,Y的表达式如下:
其中,Yi代表对应的设备的故障率。此输出标签将用于监督模型的训练,使其学习如何根据输入特征来预测设备的故障率。
(2)神经网络架构设计。深度前馈神经网络包括输入层、隐藏层和输出层。输入层接受来自数据集的输入特征,隐藏层执行非线性变换,最终输出预测结果。本研究选择一个包括两个隐藏层的神经网络。每个隐藏层的神经元数量是一个可调整的超参数,用Nhidden表示。隐藏层的数量和每个隐藏层中神经元的数量取决于任务的复杂性和数据的特性。此神经网络的架构可表示为:
输入层:输入包含D个特征且每个元素都是实数的特征向量,的表达式如下:
其中,Xj表示每个特征,j是特征的索引。
第一个隐藏层:
1)神经元i的线性组合:
2)神经元i的激活函数(使用ReLU):
式中,表示第一个隐藏层中神经元i和输入层中特征j之间的连接权重,是第一个隐藏层中神经元i的偏置。
第二个隐藏层:
1)神经元i的线性组合:
2)神经元i的激活函数(使用ReLU):
式中,表示第二个隐藏层中神经元i和第一个隐藏层中神经元j之间的连接权重;是第二个隐藏层中神经元i的偏置。
输出层:
输出预测值Y′:
式中,表示输出层中神经元i和第二个隐藏层中神经元i之间的连接权重;b(3)是输出层中神经元i的偏置。
整个神经网络架构使用ReLU作为激活函数,通过前向传播计算输入特征X经过隐藏层传递到输出层,从而得到故障率的预测结果Y′。隐藏层的数量和每个隐藏层中神经元的数量都是可调整的超参数,可根据具体任务和数据集进行选择和优化。
神经网络架构案例:如图所示,本研究使用MATLAB创建一个包含10个特征的特征向量作为神经网络的输入,随后建立两层包含20个神经元的隐藏层,最后设置输出层大小,模拟输出值。
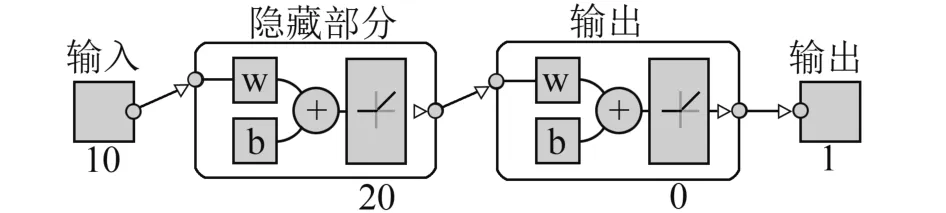
图 神经网络架构案例
(3)损失函数和优化器。在故障率预测问题中,本研究采用均方误差(MSE)作为损失函数,以量化模型的性能。均方误差计算模型的预测值与实际值之间的平方差的平均值,MSE的表达式如下:
式中,L(θ)表示损失函数;θ表示神经网络的参数,包括权重和偏差;N表示样本数量;Yi表示第i个样本的实际故障率;Y′表示第i个样本的神经网络预测的故障率。
MSE损失函数的目标是最小化这个平方差的平均值,使模型的预测尽可能接近实际值。
为了优化神经网络的参数(权重和偏差),本研究使用Adam优化器。Adam优化器结合了动量和自适应学习率的方法,可更有效地调整学习率,以加速训练过程并避免陷入局部极小值。Adam优化器的更新规则如下:
式中,mt和vt分别表示梯度的一阶矩估计和二阶矩估计;β1和β2是衰减率,通常设置为接近1的值;∇L(θt)表示损失函数关于参数θt的梯度;^mt和^vt是修正后的一阶和二阶矩估计;α是学习率,控制了参数更新的步长;˙o是一个极小的常数,防止除零错误。
通过使用MSE作为损失函数和Adam优化器,神经网络在训练过程中逐渐调整权重和偏差,以最小化损失函数,从而更好地拟合实际的故障率数据,有助于提高故障率预测模型的准确性和性能。
(4)模型训练。模型训练是深度前馈神经网络构建的重要阶段,其目标是通过使用训练集的数据和故障率标签来拟合模型参数,以使模型能够准确预测故障率。在每个训练周期中,神经网络根据损失函数的梯度对权重和偏差进行更新,以最小化损失。此过程经常需要多次迭代,直到模型收敛到一个满意的性能水平。训练过程如下:
1)训练数据集。训练数据集由输入特征数据Xtrain和相应的故障率标签Ytrain组成。其中,Xtrain是一个大小为Ntrain×D的矩阵,包含Ntrain个训练样本,每个样本有D个特征。Ytrain是一个大小为Ntrain×Noutput的矩阵,包含每个训练样本对应的故障率标签,其中Noutput是输出层的大小。
2)使用MSE损失函数训练模型。使用(3)中提到的均方误差(MSE)作为损失函数,对模型进行训练,可表示为:
其中,θ表示神经网络的参数 (权重和偏差),Yi,train表示第i个训练样本的实际故障率标签,Y′i表示神经网络对第i个训练样本的预测故障率。
3)权重和偏差更新。本研究使用(3)中提到的Adam优化器优化算法,在每个训练周期中,根据损失函数的梯度,对权重和偏差进行更新。
4)迭代训练。训练过程是一个迭代的过程,每个训练周期更新一次权重和偏差。需要多个训练周期,直到模型在训练数据上达到最优性能。在每个训练周期结束后,使用验证数据集来评估模型的性能,并根据需要进行超参数调整。
模型训练的目标是通过不断迭代调整神经网络参数,使其能够最小化损失函数,以更好地拟合故障率数据并提高预测准确性。一旦模型收敛,它将能够对新的未知数据进行准确的故障率预测。
4 将模型部署到云平台
云平台为模型提供了计算和存储资源,使得实时预测和数据处理成为可能。将已训练完成的深度前馈神经网络故障率预测模型部署到云平台以接收、处理和分析实时数据流,从而提供设备状态的实时监测和故障率预测。部署过程如下。
(1)云计算资源配置。在部署之前,在云平台中配置适当的计算资源,包括虚拟机、GPU等,以支持深度学习模型的推理和实时数据处理。
(2)模型上传。将已训练完成的深度前馈神经网络故障率预测模型上传至云平台的模型存储库,以供后续的推理使用。
(3)实时数据接收。在云平台中设置实时数据接收器,用于从设备传感器、监测系统或其他数据源接收实时数据流。这包括设备操作数据、环境条件等输入特征。
(4)数据处理和预测。云平台的计算资源对实时数据进行处理,将其输入到已部署的深度前馈神经网络故障率预测模型中进行预测。模型会生成实时设备故障率预测作为输出。
(5)实时监测。根据模型的输出,云平台实时监测设备状态,检测异常或高风险情况。
(6)警报生成。一旦检测到异常或高风险情况,云平台生成警报,通知相关维护人员或决策者采取措施。
5 结束语
本研究在电力系统领域取得了显著进展,通过融合云平台和深度前馈神经网络,实现了输电变电设备的故障率预测,为电力行业提供了更可靠和高效的解决方案。未来的工作将集中在进一步提高预测性能、扩展应用领域以及完善实时监测和警报系统,为智能电力系统的发展和可持续性做出贡献。
猜你喜欢
自然杂志(2021年6期)2021-12-23
电子制作(2019年19期)2019-11-23
现代装饰(2018年5期)2018-05-26
中国交通信息化(2017年4期)2017-06-06
电测与仪表(2016年20期)2016-04-11
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
机电信息(2015年3期)2015-02-27
