
基于CenterNet的多教师联合知识蒸馏
2024-03-27 12:58刘绍华佘春东
系统工程与电子技术 2024年4期
刘绍华, 杜 康, 佘春东, 杨 傲
(北京邮电大学电子工程学院, 北京 100080)
0 引 言
在过去几年的时间里,计算机视觉领域迅猛发展,目标检测作为计算机视觉的一个重要分支已经被运用于现实中的各种场景下,如智能手机相机中的人脸自动抓取功能,停车场中检测车位占用情况的摄像头,以及军事项目中无人机对于基地目标的检测任务等。
目前,一些主流的目标检测网络都采取残差神经网络(residual neural network, ResNet),如ResNet50[1]或者Hourglass[2]作为主干网络,同时多数实验中也将这两种网络作为参照。ResNet50是一种深度残差网络,可以有效地解决深度神经网络训练中的梯度消失和梯度爆炸问题,从而提高网络的准确率。Hourglass网络具有良好的特征提取以及多尺度建模的能力,同时在目标检测等任务中表现出色。但是在移动设备、嵌入式平台、物联网等资源受限的环境下,上述两种深度神经网络需要消耗大量的计算资源,同时其缓慢的训练推理速度以及庞大的空间占用,使得人们不得不将目光聚焦于轻量化目标检测网络。
轻量化目标检测网络可以降低计算复杂度和减少空间占用,在各种资源受限或对计算速度、能耗、存储等有要求的应用场景中具有广泛的应用前景。同时其也面临新的挑战,比如如何提出有效的模型训练方案,使轻量化目标检测模型仍然能够保持优异的性能。
本文介绍了一种基于轻量化CenterNet的多教师联合知识蒸馏方案。该方案能有效解决模型轻量化带来的性能恶化问题,可以大大缩小教师模型和学生模型之间的性能差距。将多个大规模复杂模型作为教师网络,以教导作为学生网络的轻量化模型进行训练。相比于使用传统训练方式的轻量化目标检测网络,使用该知识蒸馏方案可以在相同的训练轮数后达到更优的检测性能。
本文提出了针对CenterNet目标检测网络特有的知识蒸馏模块——多教师联合知识蒸馏。该知识蒸馏模块采用的蒸馏损失(knowledge distillation loss, LossKD)分为4部分:类别蒸馏损失LossCLSKD、长宽预测蒸馏损失LossWHKD、目标中心点偏移蒸馏损失LossOFFKD、主干网络蒸馏损失LossBACKBONEKD。在单教师知识蒸馏实验中,使用加入ImageNet[3]预训练权重的ResNet50作为教师网络,对比多种轻量化模型的训练效果,验证了该知识蒸馏模块的有效性。引入蒸馏损失权重参数W,对不同部分蒸馏损失设置不同的权重,通过调整不同蒸馏损失部分的权重,可以快速地优化蒸馏效果。在多教师联合蒸馏与单教师蒸馏的对比实验中,使用加入ImageNet预训练权重的ResNet50、Hourglass作为多教师网络,提出使用蒸馏注意力机制对不同教师网络自适应分配不同权重,验证了多教师联合蒸馏指导出的学生网络在泛化能力以及性能指标方面的提升。
在VOC2007数据集上,以MobileNetV2轻量化网络为例,相较于传统的CenterNet(主干网络为ResNet50),所提方案的参数大小压缩了74.7%,推理速度提升了70.5%,在平均精度(mean average Precision, mAP)上仅有1.99的降低,取得了更好的“性能-速度”平衡。同样经过100轮训练,使用多教师联合知识蒸馏的训练方式相较于普通训练方式,mAP提升了11.30。
1 相关工作
1.1 目标检测模型概述
在目标检测领域,最早出现的是双阶段目标检测,如基于区域的卷积神经网络(region-based convolutional neural network, R-CNN)[4]、空间金字塔池化网络(spatial pyramid pooling network, SPP-net)[5],第一个阶段首先产生候选区域,该区域包含目标大概的位置信息,第二个阶段的任务包含对候选区域进行分类和位置微调。由此可见,双阶段目标检测在产生候选区域时会消耗大量的内存空间,在训练速度和推理速度上也略显不足。随着人们对于目标检测模型性能要求的提升,单阶段目标检测应运而生。单阶段目标检测算法可以在同一个阶段直接产生物体的类别概率和位置坐标值。相比于双阶段目标检测算法,单阶段目标检测没有产生候选区域的阶段,整体流程更为简单。同时,单阶段目标检测算法又可以分为基于锚框和无锚框两类,以基于锚框为代表的模型有更快的R-CNN(Faster RCNN)[6]、YOLOv2[7]、YOLOv3[8];以无锚框为代表的模型有:CornerNet[9]、CenterNet[10]、ExtremeNet[11]。两者区别在于有没有利用锚框提取候选目标框。比如YOLOv3,其首先按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域,再对锚框是否包含目标物体进行预测,如果经预测判断包含目标物体,则还需要预测所包含物体的类别以及预测框相对于锚框位置需要调整的位移大小。CenterNet则采用关键点检测,通过特征提取后输出的热力图峰值来确定待检测目标物体的中心点和种类,再通过对每个中心点预测其对应的预测框来完成检测任务。
1.2 CenterNet原理及结构
CenterNet网络的组成包括主干网络特征提取模块、特征图解码模块以及分类头。CenterNet的解码器一般采用反卷积模块Deconv进行3次上采样,得到分辨率更高的特征图。解码器输出的特征图随后传入到CenterNet的分类头中,假设在目标检测任务中有C个待检测类,那么分类头将输出C+4个通道的特征图,其中预测的热力图占有C个通道的输出,每一个类别都有一张热力图与之对应。在每一张热力图上,若某个坐标处有物体目标的中心点,即在该坐标处产生一个关键点。预测框的长宽大小占2个通道的输出,预测框的中心点偏移占有2个通道的输出。CenterNet的损失包括3部分,热力图类别预测损失LossCLS、目标长宽预测损失LossWH、目标中心点偏移损失LossOFF。其中,LossCLS损失函数采用改进的Focal Loss, LossWH和LossOFF的损失函数均采用L1 Loss。 标准CenterNet的结构示意图如图1所示。

图1 标准CenterNet的结构Fig.1 Structure of standard CenterNet
1.3 轻量化神经网络
近年来,随着深度学习应用的不断拓展和移动设备的广泛普及,轻量化神经网络成为了深度学习领域的热门话题之一。轻量化神经网络是指在保持神经网络模型准确性的前提下,通过设计轻量化算法和结构,减小神经网络的参数数量和计算复杂度,以实现在较低硬件资源条件下的高效运行。
ShuffleNet[12]是由旷视科技提出的一种轻量级卷积神经网络模型。它通过使用逐通道的1×1卷积和通道重排来减少计算量。通道重排是指将输入的特征图进行分组,然后对每个分组内的通道进行混洗,从而将不同的通道分布到不同的分组中。该方法可以有效减少模型中的参数量和计算量。MobileNetV2[13]使用了瓶颈设计以及倒残差模块,满足了在移动设备等资源受限的环境下进行图像分类和目标检测的需求。EfficientNet[14]是一个多尺度卷积神经网络,该网络通过利用深度网络和多尺度特征提取,在保证准确性的情况下减小了神经网络参数量和计算复杂度。小型基于语义理解的深度双向预训练Transformer(tiny bidirectional encoder representation from Transformer, TinyBERT)[15]是一个轻量化的基于Transformer的双向编码器表示(bidirectional encoder representation from Transformer, BERT)模型,该模型通过蒸馏技术将原版BERT模型的知识迁移到较小的模型中,从而在保证准确性的情况下,减小了模型的参数数量和计算复杂度。2020年华为推出GhostNet[16],该网络通过Ghost模块,即一种基于低秩分解的特征重用技术,将参数量减小了50%,同时在ImageNet分类任务中超过了MobileNetV3。MobileBERT[17]相较于原版BERT模型减少了90%的计算量,同时在自然语言理解(natural language understanding, NLU)任务中取得了不错的性能。Bias Loss[18]是一种轻量化网络的新型损失函数,将注意力集中在一组有价值的数据点上,并防止特性差的样本误导优化过程。Mobile-Former[19]将MobileNet和Transformer进行并行设计,可以实现局部和全局特征的双向融合。在分类和目标检测任务中,性能远超其他轻量级网络。
1.4 知识蒸馏
知识蒸馏作为一种新兴的模型压缩训练方法,目前已成为深度学习领域的一个研究热点和重点[20]。Hinton等[21]认为,学生模型可以利用教师模型传递的“暗知识”更好地理解和掌握特征知识,从而增强其泛化能力。最早,知识蒸馏算法主要针对分类问题,分类问题的共同点是模型最后会有一个Softmax层,其输出值对应了相应类别的概率值。知识蒸馏使用软标签,能够提供高效的迁移泛化能力。软标签是指输入图像通过教师模型得到Softmax层的输出。软标签相比硬标签,有着更高的熵、更小的梯度变化,因此学生模型相比教师模型可以使用更少的数据和更大的学习率。在使用软标签时,一般会引入温度系数T:
(1)
式中:T为蒸馏温度,T=1时,即为普通的Softmax。蒸馏温度T的升高,可以使标签变得更软。通过使用软标签,可以获得比硬标签更丰富的泛化信息,从而避免学生模型过拟合。虽然知识蒸馏已经获得了广泛的应用,但是学生模型的性能通常接近于教师模型。特别地,若学生模型和教师模型使用相同的网络,学生模型的性能将超越教师模型[22],性能更差的教师模型反而教出了更好的学生模型[23]。一般的知识蒸馏可以统一抽象为如下形式:
L=αLsoft+βLhard
(2)
式中:α和β是超参数,β是学生网络在硬标签上的损失,α是学生网络在教师网络生成的软标签上的损失。为了更好地理解知识蒸馏的作用,一些研究工作从数学或实验上对知识蒸馏的作用机制进行了证明和解释,主要分为以下几类:
(1) 软标签为学生模型提供正则化约束。这一结论最早可以追溯到通过贝叶斯优化来控制网络超参数的对比试验[24],其表明了教师模型的软标签为学生模型提供了显著的正则化。软标签正则化的作用是双向的,因此能将知识从较弱的教师模型迁移到能力更强大的学生模型中[25-26]。软标签通过标签平滑训练提供了正则化[25-26],标签平滑通过避免过分相信训练样本的真实标签来防止训练的过拟合[25]。
(2) 软标签为学生模型提供了“特权信息”。“特权信息”可以被用于教师模型的解释和评估[27]。教师模型在训练的过程中,将软目标的“暗知识”迁移到学生模型中,而学生模型在测试的过程中并不能使用“暗知识”。从这个角度看,知识蒸馏通过软标签来为学生模型传递“特权信息”。
(3) 软标签引导了学生模型优化的方向。Phuong等[28]从模型训练的角度证明了软标签能够指导学生模型的优化方向。Cheng 等[29]从数学角度验证了使用软标签比使用原始数据进行的优化学习具有更高的学习速度和更好的性能。
同时,为了解决教师网络特征图与学生网络特征图对应不一致的问题,Lin等[30]提出了Target-aware模型Transformer模型,使得整个学生网络在蒸馏过程中能够分别模仿教师网络的每一个空间组件。通过这种方式,可以提高匹配能力,进而提高知识蒸馏的性能。针对前景和背景特征图之间的不均匀差异将对蒸馏产生负面影响的问题,Yang等[31]提出局部和全局知识蒸馏(focal and global knowledge distillation, FGD)。局部蒸馏分离了前景和背景,迫使学生将注意力集中在老师的关键像素和通道上。全局蒸馏重建了不同像素之间的关系,并将其从教师传递给学生,以补偿局部蒸馏中丢失的全局信息。
1.5 注意力机制
注意力机制是近几年深度学习中重要的方法之一,在不同领域得到了广泛的研究。在发展过程中,注意力机制首先被应用在自然语言处理任务之中。而如今,在人工智能领域,注意力机制作为神经网络体系结构的一个重要组成部分,在数据挖掘、时间序列预测、计算机视觉等领域都有着广泛的应用。顾名思义,注意力机制就是通过对人类阅读、听说中的注意力行为进行模拟操作。注意力机制可以做到重点关注有利于任务完成的信息,而抑制那些不重要的信息。这项技术也可以自然地应用在目标检测模型中:在执行检测任务时,网络会更重视特征更加重要的通道,因此正确利用注意力机制给通道分配不同的注意力分数有利于网络使用更加重要的特征图进行特征融合,从而提高目标检测的准确性。
Transformer[32]模型利用多头注意力机制加速了模型的训练,加强了不同位置信息的关联性,一定程度地解决了RNN系列模型的长距离依赖问题。Transformer模型仅利用注意力机制就实现了机器翻译等复杂的任务,并且取得了目前最好的效果,向相关研究人员展示了注意力机制的强大作用。
2 CenterNet多教师联合知识蒸馏
在本节中,首先介绍CenterNet单教师知识蒸馏模块,然后提出了多教师知识蒸馏模块的网络结构,并对在多教师联合知识蒸馏模块中加入的蒸馏注意力机制、损失权重参数W进行了描述,最后阐述了联合训练与冻结解冻训练的模型训练方式。
2.1 基于CenterNet的知识蒸馏框架
为了达到模型轻量化的目的,目前常用的方法是将模型的特征提取网络替换为轻量化网络。若在模型轻量化后依然采用常规的训练方式,即使用LossCLS、LossWH、LossOFF组成的损失函数,很难完成对于模型参数的有效更新,导致训练出的模型检测性能不佳。于是,为了兼顾模型轻量化以及模型检测的性能,提出了专门针对于CenterNet的知识蒸馏方案。
目前的知识蒸馏算法大多应用于分类任务,很难直接应用于目标检测模型。这其中的难点主要有两个方面:① 检测任务中大量的背景样本使得正负样本不均衡,导致模型的分类更加困难;② 目标检测的网络更加复杂,尤其对于双阶段网络而言,双阶段的网络由于RPN输出的不确定性,导致教师网络和学生网络的候选区不能精确对齐。而对于这两个难点,目标检测模型CenterNet均有良好的解决方案。针对难点①,根据CenterNet的范式,该网络没有复杂的正负样本采样,只有物体的中心点是正样本,其他都是负样本。针对于难点②,如第1节所介绍,CenterNet为单阶段目标检测网络,结构相对简单。基于CenterNet的知识蒸馏模块的结构如图2所示。

图2 基于CenterNet的知识蒸馏模块结构Fig.2 Knowledge distillation module structure based on CenterNet
所采用的总体蒸馏模块由两部分构成,分别为基于主干模块的蒸馏以及基于分类头的蒸馏。在模型端到端的训练过程中,总体网络参数更新由原来的分类头损失以及蒸馏损失共同决定,模型总体损失定义如下:
LossTOTAL=LossCLS+LossWH+LossOFF+LossKD
(3)
关于教师网络与学生网络的选择,在基于CenterNet多教师联合知识蒸馏任务中,选用ResNet50、Hourglass等作为教师网络,它们拥有更复杂的网络结构以及更多的参数运算量,但模型可以提供更高的检测性能。选用ResNet18、MobileNetV2等作为学生网络,模型简单并拥有较低的计算复杂度,足够轻量化,但是其检测性能也相对较低。综上所述,本文采取的教师网络与学生网络可以提供较好的平衡,以满足知识蒸馏的需求,契合教师带动学生、“先富带动后富”的思想,使作为学生网络的轻量化模型得到性能提升。
2.2 蒸馏损失函数及损失权重参数W
根据第2.1节图2所展示的知识蒸馏的框架,提出基于CenterNet的蒸馏损失函数。
在基于主干模块的蒸馏上,使用MSE损失作为该部分蒸馏损失:
LossBACKBONEKD=MSE(ReLU(FMt),ReLU(FMs))
(4)
式中:FMt为教师网络主干模块输出的特征图;FMs为学生网络主干模块输出的特征图。
根据第1.2节介绍的CenterNet分类头的特殊结构,拟采取的蒸馏损失也从分类头的这3类优化目标着手。对于输出的热力图,把教师网络和学生网络输出的特征图通过一个ReLU层将负数部分去掉,然后使用MSE损失生成LossCLSKD,如下所示:
LossCLSKD=MSE(ReLU(hmt),ReLU(hms))
(5)
式中:hmt为教师网络输出的热力图,hms为学生网络输出的热力图。
对于LossWH和LossOFF,根据CenterNet只学习正样本的原理,将教师网络输出热力图用非极大值抑制操作后,产生掩膜,再将掩膜与宽高和中心点偏移的对应特征图相乘作为新特征图。最后,将教师网络和学生网络所有对应的像素点使用L1 Loss作为该部分的蒸馏损失。具体操作过程如下:
LossWHKD=L1(wht·mask/T,whs·mask/T)
(6)
LossOFFKD=L1(offt·mask/T,offs·mask/T)
(7)
式中:wht与offt为教师网络输出的特征图,whs与offs为学生网络的特征图;T为温度系数;“·”为张量乘法符号。
根据CenterNet损失的定义,CenterNet损失主要分为主干模块损失、热力图损失、预测框宽高损失以及中心点偏移损失,这些损失对于目标检测性能的重要程度不尽相同。于是给予不同类别损失不同的权重W,将分类头部分总体蒸馏损失定义如下:
LossKD=w1*LossCLSKD+w2*LossWHKD+
w3*LossOFFKD+w4*LossBACKBONEKD
(8)
式中:w1、w2、w3、w4为模型训练前人工设置的损失权重的超参数,需根据训练效果进行调节。
2.3 多教师联合知识蒸馏及蒸馏注意力机制
为了进一步提升知识蒸馏的效果,可以借鉴Transformer模型中多头注意力机制的作用,融合多个教师网络生成的特征图以及软标签。对于同一张图片,不同的教师网络生成的软标签分布是不同的,如图3所示。

图3 不同网络对于同一张图片生成的软标签分布Fig.3 Soft label distribution generated for the same image by different networks

由于不同教师网络的性能效果存在差异(与标签之间的损失),若直接使用Softmax对损失进行权重分配,容易发生权重的极限偏移,使权重分布更加尖锐(极端情况为其中一个教师网络权重接近于1,其余教师网络权重接近于0),此时多教师蒸馏网络退化为单教师蒸馏网络。为避免上述情况发生,得到更加平缓的权重分布,需要先对不同教师网络的损失进行归一化,如下所示:
(9)

(10)

(11)

多教师联合知识蒸馏模块如图4所示,使用N个不同的教师网络对同一学生网络进行知识蒸馏。

图4 多教师联合知识蒸馏模型Fig.4 Multi-teacher joint knowledge distillation network
2.4 联合训练及冻结解冻训练
根据知识蒸馏的特性,使用教师网络与学生网络联合训练的方式。具体来说,教师网络在硬标签上单独训练N个轮次,学生网络在硬标签上单独训练N个轮次,然后使用教师网络指导学生网络,并保留原本的硬标签损失,再训练N个轮次。实验证明,这种训练方式得到的模型性能是最佳的。
借鉴迁移学习的思想,神经网络主干特征提取部分所提取到的特征是通用的,所以将主干模块冻结起来训练可以加快训练效率,也可以防止训练好的主干模块权值被破坏。在冻结训练阶段,模型主干模块的初始参数加载了其在ImageNet上预训练得到的模型参数,在新任务的训练过程中参数被冻结了,主干网络权重不发生改变,只改变解码模块以及分类头模块的权重,占用的显存较小,仅对网络进行微调。 在解冻训练阶段,模型的主干网络不被冻结,主干模块、解码模块以及分类头模块的参数都可以得到更新。在解冻训练阶段,模型训练占用的显存较大,冻结解冻训练方式如图5所示。

图5 解冻和冻结训练Fig.5 Unfreeze and freeze training
3 评估实验
在本节中,首先介绍了实验使用的数据集、硬件设备以及训练方法。其次,对比了多种轻量化主干网络是否使用知识蒸馏训练的检测效果,评价指标主要包括不同主干网络下CenterNet的目标检测性能mAP和模型参数大小。同时,通过消融实验对比单教师与多教师知识蒸馏,证明了多教师联合知识蒸馏带来的性能提升。基于CenterNet的知识蒸馏训练方案可以分为以下3步。
(1) 训练教师模型:使用硬标签,即正常的标签训练教师模型。
(2) 计算“软标签”:利用训练好的教师模型来计算“软标签”,也就是教师模型“软化后”的输出。
(3) 训练学生模型:在学生模型硬标签损失函数的基础上加入教师模型输出软标签的损失函数,共同指导学生模型的训练。
3.1 单教师知识蒸馏
采用VOC2007作为数据集。其中,训练集包括19 352张分辨率为500×375的图片和对应标签,验证集采用随机分割训练集的方式生成,每一轮训练中,训练集和验证集的比例为9∶1。测试集由3 870张分辨率为500×375的图片和对应标签组成。在将数据集导入模型时,需要对图片进行尺寸归一化和数据增强的预处理,将图片尺寸归一化为512×512。
使用2块GPU Tesla T4对不同模型进行ImageNet[22]预训练权重加载的训练。使用ResNet50作为教师网络,对学生网络ResNet18、ResNet34、MobileNetV2、EfficientNet-b0等都设置100轮训练。在训练过程中,采用第3节中的联合训练、冻结训练与解冻训练结合的方法,将100轮训练分为2步, 1~50轮采用学习率为1e-3、权重衰减为5e-5的Adam优化器,使用冻结训练方式;51~100轮采用学习率为1e-4、权重衰减为5e-5的Adam优化器,使用解冻训练方式。采用不同主干模块的CenterNet模型大小、参数大小、浮点运算次数(floating point operations per second,FLOPs)如表1所示。

表1 不同结构CenterNet的模型大小、参数大小、FLOPsTable 1 Model size, parameter size, FLOPs of different structures of CenterNet
经过100轮训练后,不同模型使用普通训练以及知识蒸馏训练,得到数据集中“汽车”类别的精度(average precision, AP)如图6所示。

图6 不同模型在两种训练方式下对汽车类别的APFig.6 AP of different models trained in two ways in car category
对同一轻量化网络模型,分别使用普通训练方式和基于CenterNet知识蒸馏的训练方式,在VOC2007数据集上得到的mAP的交并比(intersection over union, IoU)阈值取0.5,如表2所示。

表2 不同轻量化结构CenterNet的mAP、训练轮数以及预训练 模型加载情况(VOC数据集下)Table 2 mAP, number of training rounds, and loading of pre-trained models in different light-weight structures of CenterNet (with VOC dataset)
可以看出,在100轮训练后,使用知识蒸馏训练方式的轻量级特征提取网络相较于使用普通训练方式的轻量化特征提取网络可以得到更高的mAP,实验的4种轻量化模型的mAP平均提升了4.52。
3.2 多教师知识蒸馏
为了测试多教师知识蒸馏的效果,采用ResNet50和Hourglass组成多教师网络对轻量化网络进行知识蒸馏。在实验中主要采用了ResNet18、ResNet34、MobileNetV2、EfficientNet-b0作为BACKBONE的CenterNet目标检测模型进行消融实验。
使用4块GPU Tesla T4对不同模型在VOC2007数据集上进行ImageNet[22]预训练权重加载的解冻训练与冻结训练。训练轮数设置为100轮,其中1~50轮训练采用学习率为1e-3,权重衰减为5e-4的Adam优化器,使用冻结训练方式;51~100轮采用学习率为1e-4,权重衰减为5e-5的Adam优化器,使用解冻训练方式。经过训练后,不同模型对于VOC2007数据集中数据集中“摩托车”类别的AP如图7所示。

图7 不同模型在两种训练方式下对于摩托车类别的APFig.7 AP of different models trained in two ways in motorbike category
不同模型使用单教师知识蒸馏与多教师知识蒸馏,在VOC2007数据集训练得到的mAP如表3所示。
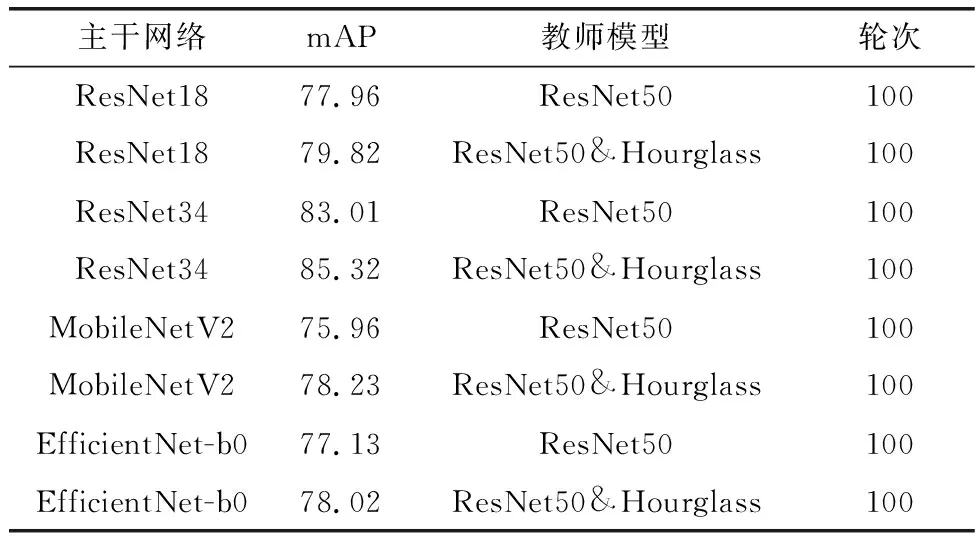
表3 单教师知识蒸馏和多教师知识蒸馏对比Table 3 Comparison of single teacher knowledge distillation and multi-teacher knowledge distillation
可以看出,在100轮训练后,使用多教师联合知识蒸馏训练方式相较于单教师知识蒸馏训练得到的轻量级特征提取网络可以得到更高的mAP。实验中4种轻量化模型的mAP平均提升了1.83。
3.3 损失权重参数W
根据第2节对于损失权重参数W的定义,W由w1、w2、w3、w4组合而成,其中w1、w2、w3、w4分别为LossCLSKD、LossWHKD、LossOFFKD、LossBACKBONEKD的权重。由式(8)可知损失权重参数W选择的不同会直接影响蒸馏损失的构成。在模型训练前,需要人工设置损失权重参数W的可选取值,W∈{0.1,1,10,100,1 000},采取网格搜索算法枚举多种蒸馏权重组合进行实验。在VOC2007数据集下,不同权重组合的模型性能如表4所示。

表4 由不同损失权重参数W蒸馏训练得到的CenterNet性能 对比(主干网络为ResNet18)Table 4 Comparison of CenterNet performance obtained by distillation training with different loss weight parameters W (withResNet18 as backbone)
根据表4中使用不同损失权重参数W训练出的模型的检测性能效果对比,对于VOC2007数据集而言,当w1,w2,w3,w4分别为1 000,1,0.1,100时,mAP相较w1,w2,w3,w4分别为0.1,10,1 000,1时提升了6.48,说明了W超参数对于模型调优的重要性,即如果找到更加适配模型的损失权重参数,可以使训练效果得到提升。其中,w1,w2,w3,w4分别为1 000,1,0.1,100时训练出的ResNet18-CenterNet模型的检测效果图如图8所示。

图8 ResNet18-CenterNet目标检测效果Fig.8 ResNet18-CenterNet object’s detection effect
综上所述,当训练条件发生变化时,可以选择更换损失权重参数W,以快速达到更好的训练效果以及检测效果。
3.4 目标检测效果展示
使用BACKBONE为MobileNetV2的CenterNet目标检测模型,使用普通训练与多教师联合知识蒸馏训练两种不同方式下得到的模型进行目标检测的测试,效果对比如图9所示,图9(a)、图9(b)、图9(c)左侧为普通训练方式检测效果图,图9(a)、图9(b)、图9(c)右侧为多教师蒸馏检测效果图。

图9 普通训练方式检测效果图(各分图左侧)及多教师蒸馏训练检测效果图(各分图右侧)Fig.9 Detection performance diagram of the regular training(left) and detection performance diagram of the multi-teacher distillation training (right)
由图9可见,使用了多教师知识蒸馏训练得到的模型,无论在检测的置信度还是检测出的目标的数量上,都更加优异。图9(c)图片存在多目标重叠的情况,使用多教师联合知识蒸馏后的模型也能很好地解决这一问题,可将多重叠目标进行准确分割。
4 结束语
本文回顾了目前国内外对于目标检测领域的研究现状,总结了一些轻量化目标检测模型的实现方法以及一些优秀的知识蒸馏方案。本文提出了基于CenterNet的多教师联合知识蒸馏训练方案,定义了基于CenterNet的蒸馏损失函数,提出了利用蒸馏注意力机制来有效融合多个教师网络的“暗知识”,可应用于多种轻量化主干网络CenterNet的训练过程。实验结果表明,本蒸馏训练方案在VOC2007数据集上表现出了比普通训练方案更加优异的性能。以使用了本文的多教师联合蒸馏训练后的MobileNet-CenterNet为例,相较于传统的CenterNet(主干网络为ResNet50),参数大小压缩了74.7%,推理速度提升了70.5%,而mAP只有1.99的降低,取得了更好的“性能-速度”平衡。同样经过100轮训练,多教师联合知识蒸馏训练方式相较于普通训练方式,mAP提升了11.30。未来,还将继续改进CenterNet多教师联合知识蒸馏损失函数,以更优的蒸馏结构训练得到更好的轻量化目标检测模型。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
数学小灵通·3-4年级(2021年5期)2021-07-16
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
今日农业(2019年15期)2019-01-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
专用汽车(2016年1期)2016-03-01
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
