
基于改进麻雀搜索算法的农田节水灌溉路径自动规划方法
2024-03-27 08:28田艳艳
水利技术监督 2024年3期
田艳艳
(敦煌市水务局,甘肃 敦煌 620982)
0 引言
随着农业产业链的发展,在互联网经济的加持下,农作物销售渠道增多,农业发展在需求推动下由传统的人力劳动改为半自动机械化或全自动机械化发展。农田作物培养中,最重要的就是根据作物需求进行水土灌溉。而在资源节约的号召下,农田的节水灌溉也成为了当前研究的热点,既要满足作物的生长需求,又要合理利用水资源,并且在大农田环境中,实现节水灌溉的自动规划,在众多需求前提下,本文通过算法设计,结合我国当前情况,大力开展节水灌溉技术的推广应用,并改进麻雀搜索算法,探寻农田节水灌溉路径自动规划方法。在有关农田节水灌溉的方向探究中,范美师通过理论上的发展编制,探寻了农田灌溉的思路与路径,并结合实际的农田区域,提出有针对性的发展策略;莫姣姣从灌溉排水工程技术的角度,基于生态扶贫区域,对农田节水灌溉提出一视同仁的要求,并为相应水平的提升规划了方向。而本文的研究通过搜索算法,在现代科技的运用下,实现农田节水灌溉路径的自动规划[1]。
1 农田节水灌溉路径自动规划方法
1.1 计算农田节水灌溉参数
在对农田节水灌溉的路径规划中,计算前提为分析植物的需水量,并根据植物在不同季节不同时段的生长规律以及需水要求,合理制定灌溉方案,并规划出相应路径,然后通过搜索算法,在模型训练中对路径自动寻优,实现灌溉路径的规划。
本文的研究首先分析农作物的需水量,通过经验公式以及相应理论,在热量平衡理论的辅助下,将作物的蒸发蒸腾量转化为农作物的需水量,进行对应的需水量的计算,这种参考以间接的形式求得所需结果,计算表达式为:
ET=Kc·Kθ·ET0
(1)
式中,ET—农作物的需水量;Kc—农作物的吸水系数;Kθ—土壤对作物吸水的修正系数;ET0—随着日照作物的蒸腾量。
结合半经验公式,将作物在节水灌溉中的灌溉状态分为三个阶段,分别为受旱之前,受旱期间和受旱之后。并结合不同参数指标的计算,对作物的灌水平均量以及节水量等数值指标,以趋向正相关的方式发展。对于土壤蒸腾量,水分流失率等负面灌溉信息,需要以负相关的趋向进行规划构建。因此为了方便计算,通过数据指标转换的方式,来对各项灌溉参数进行处理,转换公式为:
C00=Cmax+Cmin-C0
(2)
式中,C00—经过数据指标转换处理的数据;Cmax—转换中数据的峰值状态;Cmin—数据转换中数据的峰谷状态;C0—原始的数据值。
式中的C00数据即为之后构建模型所需要的主要数据,在农田需水量计算的同时,还需要另外一组数据值来对农田节水灌溉方案进行划分,数据集合的表达式为:
(3)
式中,β—方案规划约束的数据长度;l—数据的离散程度;(e,i)(e≥1)—约束程度的区间。并结合公式(4),进行分类区间的规划。
P(β)=Y0H0
(4)
式中,Y0—形成集合的数据的标准差;H0—上述式(3)中k(e)的分类值。比对局部范围值的相似度,则能够对分类数据进行划分,代入式(4)后能够得到k(e)的最终数据结果,并且具有循序性,按照从大到小、从优到劣的顺序进行排列[2]。
1.2 基于麻雀搜索算法初步规划路径
根据上述流程中农田节水灌溉方案的规划,能够获取农作物需水量等数据参数,本文根据上述数据,基于麻雀搜索算法初步探寻节水灌溉路径。在麻雀搜索算法中,依凭其中的发现者和搜索者等算法特性,找到本文所需要研究目标的最优解。为了更形象地体现出麻雀搜索算法的搜索方式,构建的麻雀搜索算法模型图如图1所示。

图1 麻雀搜索算法示意图
根据图1中麻雀搜索算法模型的构建,发现者的任务是为种群寻找食物,并将食物定位提交给追随者,那么麻雀搜索算法中发现者的功能描述如下:
(5)
式中,t—当前迭代次数,也就是搜索算法中搜索食物次数;α∈(0,1]的随机数;Xi,j—某个为i的麻雀在位置j的信息数据;R—搜素算法中的警戒者能够探测到的警戒值;ST—搜素环境的安全值;Q—随机系数,增加发现者搜寻食物的随机性;L—发现者搜索范围矩阵。L矩阵范围如下表示:
(6)
式中,d—发现者的横向搜寻范围;n—发现者的纵向搜寻范围。但是搜索算法中,一个发现者麻雀并不只有一个追寻者,所以一些追随者会去争夺发现者的食物,那么对追随者的位置进行更新,可以分析出追随者位置的动态情况[3]。
虽然收敛速度快是麻雀搜索算法的优势,但是该优势的形成也限制了搜索算法的发展,导致其出现稳定性差以及局部最优解等问题。对于上述问题的处理本文通过以下两点来分析:
(1)首先是稳定性问题,出现该问题的原因为在麻雀搜索算法中,麻雀个体在解空间的随机位置上生成,生成位置影响了算法的求解,当种群的初始位置处于空间的边缘地带时,需要花费更多的时间来完成空间中有效解的搜寻,因此麻雀搜索算法的稳定性较低。
(2)其次是局部最优问题,在开始搜索阶段种群中的个体就向群体中的最优位置靠近,导致算法过早收敛。并且追随者会根据食物位置而大量进行觅食行为,导致局部极值问题的产生,并且警戒者只考虑最优个体而忽略了其他个体,降低了算法的搜索能力,具有一定的片面性[4]。
1.3 优化改进麻雀搜索算法
因此,为了对上述两种问题进行优化,本文通过改进麻雀搜索算法,提高搜索算法的稳定性,并且解决局部最优的问题,以引入Tent混沌映射初始化种群的方式,提高解质量的同时调整各分工下的位置更新方式。
首先,混沌映射提高初始解的质量,也就是提高食物的质量,并初始化种群的位置,提高种群的解空间中心的可能性,其表达式如下:
(7)
式中,φn∈[0,1]并能够在范围内产生随机数,然后根据Tent混沌映射,可以获得相应的混沌序列,将其映射到解空间中,就能够得到处于稳定状态的麻雀种群。
为了解决搜索算法的局部最优问题,设置发现者在搜索模式时,在最优解附近精细搜索,提高算法的收敛精度。并结合一种周期性非线性的自适应a值产生方式,将参数a设置为收敛因子,通过收敛因子的限定,扩大算法的搜索范围,并在多次的迭代中对种群进行多项式变异扰动,以增加麻雀个体跳出当前所处区域的概率,以此来解决局部最优问题[5]。
1.4 构建农田节水灌溉模型
通过上述麻雀搜索算法的设计以及对搜索算法的优化改进,可以在节水灌溉自动规划的要求下,建立节水灌溉模型,该模型的构建是为了使农田的节水灌溉的自动规划,更加符合农作物的生长需求,并节约相应的资源。节水灌溉模型需要将计算的需水量等参数进行输入,然后预测出农作物的参数,将数据进行输出,再由麻雀搜索算法进行最优路径的规划[6]。
在数据输入中,除了上述对农作物参数的计算,还需要结合环境原因,计算出农作物灌溉的用水影响,在原有需水量的参数上,结合环境因素,分析灌溉用水需求,在式(1)的基础上,农作物的需水量为:
ET1=ET+Δ(Fx-ρ)
(8)
式(8)中,除了式(1)中的参数外,ET1—农作物的需水量;Fx—农田内净化后的辐射数量;ρ—农田土壤密度构成。除此之外,还需要考虑土壤能够渗入的水量,在正常降雨和灌溉的情况下,土壤中水量的渗入值计算公式如下表达:
(9)
式(9)中,WU—土壤可渗入的水含量;G—能够被农作物吸水的水量;Z0—土壤中原有的水分子含量;P—土壤的吸水量;D—能够渗入土壤的水的深度。结合历史降雨量数据,农田灌溉区降雨划分状态如图2所示。
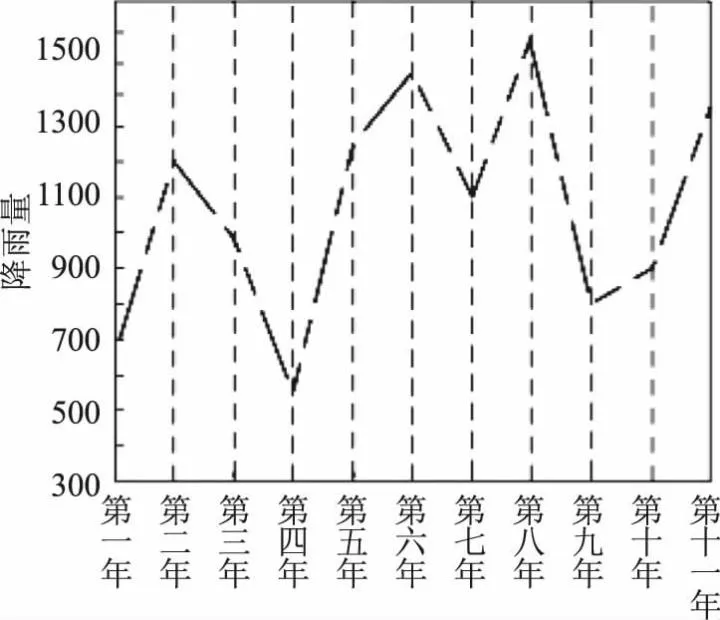
图2 农田灌溉区降雨划分状态
结合图2中的降雨数据输入至模型中进行计算,获取实际的降雨参数后及时将数据输入重新规划,以调整整体的农田节水灌溉路径[7]。
结合模型的构建,能够基于麻雀搜索算法自动规划灌溉路径。为了减小农田坐标的定位误差,以及实际环境参数的影响,将最优解进行分类,获得较为精确的数据范围[8-9]。并增加特殊的计算步骤,从而改善搜索算法对路径规划的误差。
2 实验论证
2.1 实验说明
本次为了验证基于麻雀搜索算法下的农田节水灌溉路径自动规划方法的有效性,结合一定的实际参数,通过仿真模型的构建,规划农田节水路径,以本文在麻雀搜索算法下的规划方法与传统的规划方法进行对比,将最后节约用水量作为对照参数进行比较,以此来获得本文所设计方法的优势性的体现。在实验结果的表格数据中,将本文的基于改进麻雀搜索算法的农田节水灌溉路径自动规划方法简称为实验组,传统方法为传统组。
2.2 实验准备
在本次的实验准备中,选择部分适宜状态的农田作为数据样本作为实验,并标定对应农田的地理坐标,通过仿真实验的方式,对农田中的节水灌溉路径规划进行规划。
首先收集农田中的气象数据,气象数据为影响农田灌溉量的一项重要因素,根据所选定的农田样本,选取其中最近15天的降雨量、平均气温、日照时数等参数,具体数据见表1。
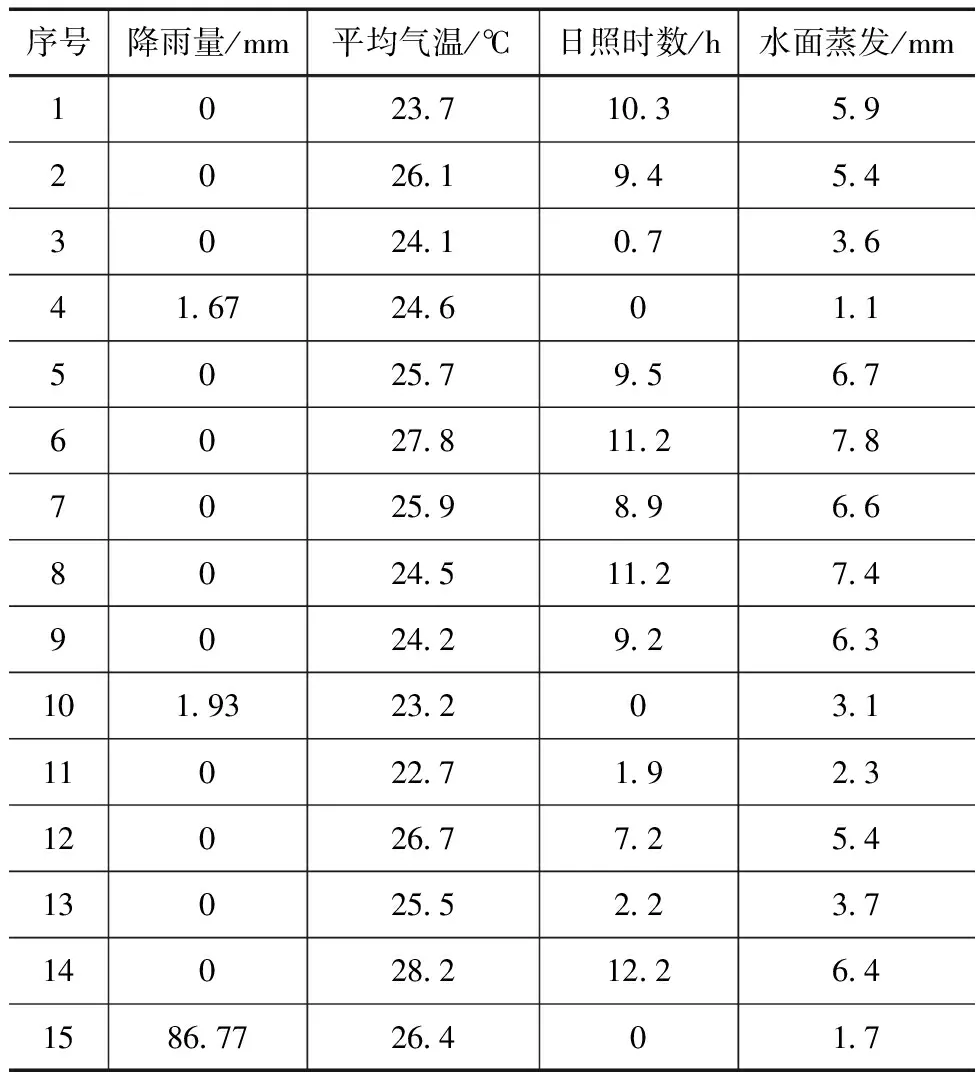
表1 实验农田气象资料参数
表1中的数据具有一定时限性,需要随着环境的变化重新输入数据并规划结果,本次实验为了测定算法的优势性,因此仅选取部分时间段内的数据。
农田地理坐标在仿真环境中的标定数据如下:(1.36,5.13),(3.67,1.78),(7.65,3.56),(4.34,3.82),(1.01,0.98),(719,6.12),(9.64.1.95),并以字母顺序进行排列。将排列完成的农田实验样本进行路径规划实验的比对。
2.3 实验结果
本文在模拟仿真中按照正常灌溉方式进行规划的路径排布如图3所示。

图3 模拟农田正常灌溉路径示意图
然后将实验数据输入至本文所设计的麻雀搜索算法下的自动规划路径中,获得的规划的路径排布如图4所示。

图4 模拟农田搜索算法下灌溉路径示意图
图4为本文算法下自动规划的农田灌溉路径,可以明显看出:
图3中的传统路径规划方式,仅能够按照排布顺序,根据农田坐标进行机械性作业,缺少对路径的优化,而图4中实验组的路径规划方式,能够自动固化出一条适合农田地理环境的节水灌溉路径,能够有效减少路径的重复性。该算法运用下的算法模型,能够降低农田坐标误差,且适合面积较大的区域算法模型。
3 结语
综上所述,本文所设计基于改进麻雀搜索算法的农田节水灌溉路径自动规划方法,通过农田需水量等参数计算,用麻雀搜索算法初步构建灌溉路径,然后基于农田参数构建相应的灌溉模型,实现农田节水灌溉路径自动规划,灌溉路径的自动规划,能够对传统灌溉路径进行改善,并节约灌溉用水量。实验对比证明:本文设计的方法在改机的麻雀算法运用中,不仅能够提高解的质量,也能够提升算法的稳定性,能够解决传统麻雀搜索算法中局部最优问题,具有一定的研究意义,然而,在实际应用中还存在一些不足,后续将继续研究进行完善。
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
环境影响评价(2020年2期)2020-12-02
作文小学中年级(2019年10期)2019-11-04
新世纪智能(高一语文)(2018年11期)2018-12-29
趣味(语文)(2018年2期)2018-05-26
水利科技与经济(2017年4期)2017-04-22
水利科技与经济(2016年3期)2016-04-22
水利规划与设计(2016年7期)2016-02-28
山东青年(2016年1期)2016-02-28
电测与仪表(2015年15期)2015-04-12
