
基于Xception和迁移学习的图像分类研究
2024-03-27 16:21谢生锋
现代计算机 2024年1期
谢生锋
(河南工学院计算机科学与技术学院,新乡 453003)
0 引言
迁移学习是一种机器学习方法,它是将已经学习过的知识迁移应用于新的问题中,用于提高解决新问题的速度和能力。卷积神经网络CNN使用卷积运算提取图像的特征,从而实现对图像的分类和识别,在CNN 的发展过程中出现了许多经典的网络模型,如AlexNet、GoogLeNet、VGGNet、ResNet 和Xception 等[1]。这些网络模型是在包含超过1400万张有标记图片的ImageNet数据集训练出来的,所以当需要训练一个新的图像分类任务时,使用这些网络模型作为预训练模型,然后在训练好的卷积基的基础上建立分类器。
1 Xception网络模型
Xception 是Google 继Inception 后提出的InceptionV3 的一种改进模型,主要采用深度可分离卷积替代InceptionV3 中的卷积操作,将通道维度和空间维度的处理分开,达到解耦的效果。Xception 模型先用1 × 1 卷积处理通道维度之间的信息,再用3 × 3 卷积处理每一个通道维度内的空间维度信息。Xception 网络结构是由36 个卷积层组成网络的特征提取基础,这些卷积层被分成14个模块,除了首尾模块,其余模块用线性残差连接[2],其网络结构如图1所示。
基于上述Xception 网络模型的特点,其在ImageNet 数据集上训练的准确率有明显提高,参数量有所下降,同时引入了残差连接机制也加快了Xception 的收敛过程。本文采用Xception网络模型作为预训练模型,对猫狗图像进行分类识别。
2 实验数据
2.1 数据集
数据来源于Kaggle竞赛平台上的dogs-vs-cats数据集,该数据集由标记为cat 和dog 的25000张图片和未标记的图片组成,其中有标记的猫和狗的图片各占12500张。本文从有标记的图片中随机抽取5000 张图片来构建数据集,将数据集划分为训练集、验证集和测试集三部分,图片数量分别是3000张、1000张和1000张,并且每一个数据集中的猫和狗的图片数量相等。划分后的训练集中的图片如图2所示。
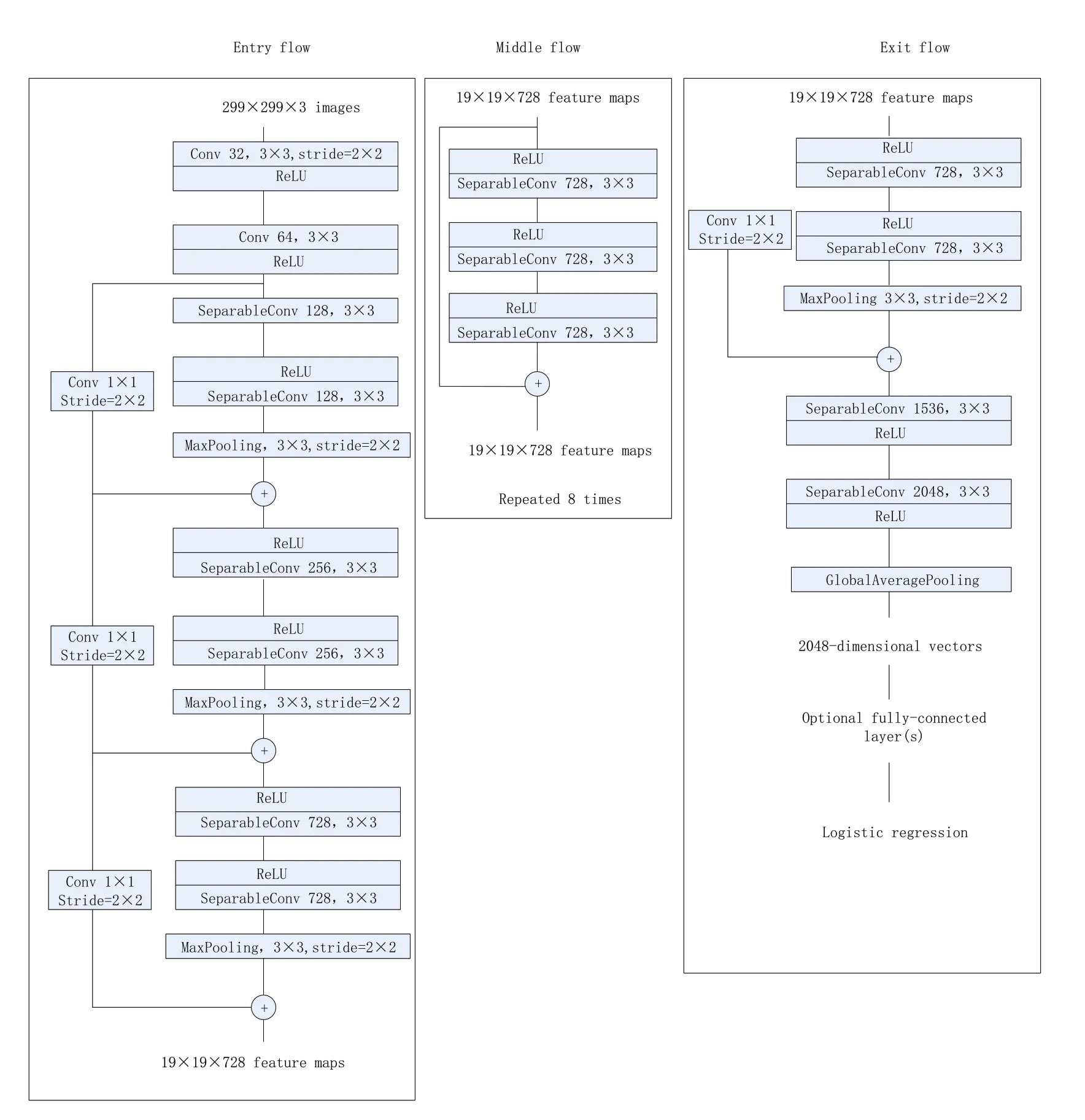
图1 Xception模型结构图

图2 训练集图片
2.2 数据处理
由于Xception 模型要求的图片大小是229像素×229像素,包含的三个通道分别是R、G、B。所以先把三个数据集中的图片维度处理为(229,229,3),使用Keras 框架中的图片生成器ImageDataGenerator 对训练集中的图片做数据增强,它是对图片进行旋转、平移、缩放、反转、剪切和归一化等操作,归一化是把像素值缩小到(0,1)范围内[3]。通过数据增强可以扩充数据集大小,增强模型的泛化能力,而对验证集和测试集中的图片只做归一化处理,训练集和验证集每个批次生成图片的数量分别设置成30 和20,同时把文本类标签cat 和dog 编码为数值,分别是0和1。
3 构建模型
采用Xception 模型作为预训练模型,首先删除Xception 模型的最后一个模块,即删除Dense 层和GlobalAveragePooling 两层,同时对Xception 模型进行微调,解冻block14 模块,包括两个SeparableConv2D 层、两个BatchNormalization 层,两个Activation 层,使这六层变为可训练状态,它们的权重在训练模型的每个周期中被更新[4],block14模块的结构如图3所示。
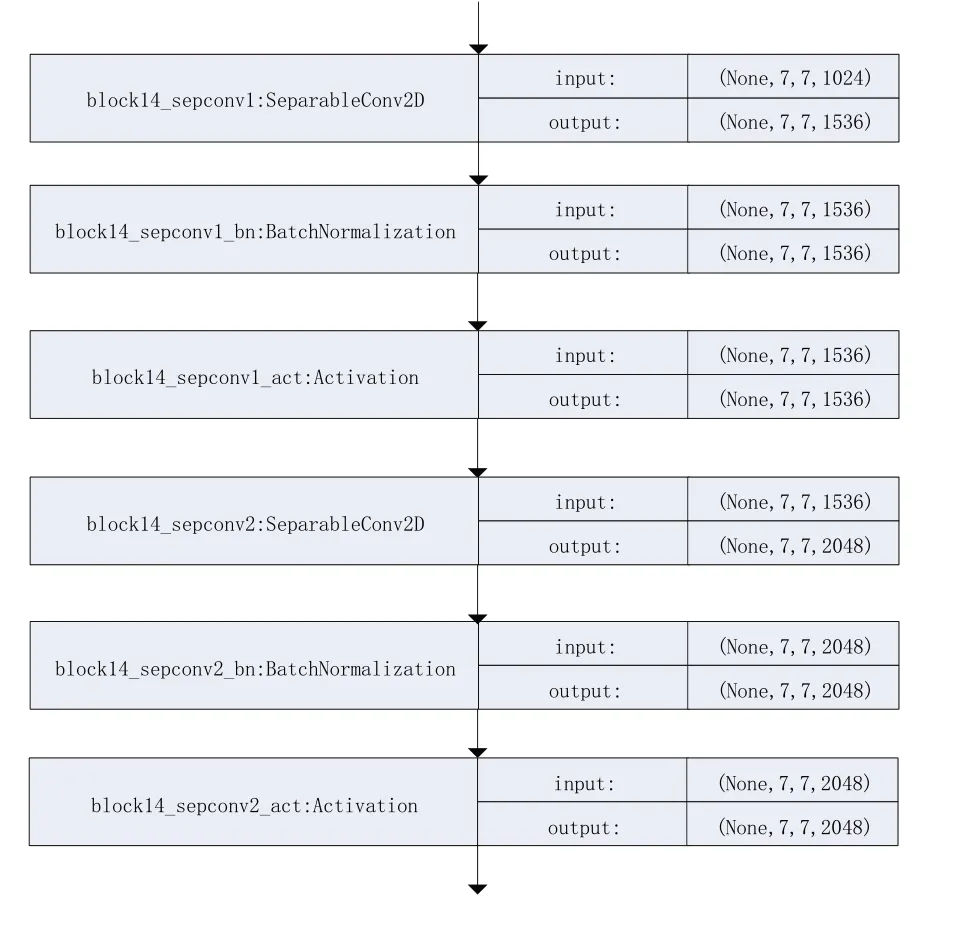
图3 block14模块的结构图
在block14 模块的基础上构建图像分类器,使用GlobalAveragePooling2D 对图像数据进行扁平化处理,得到的一维数据作为Dense层的输入数据,激活函数是ReLU;再使用Dropout层抑制过拟合;最后使用Dense 层进行二分类,激活函数是Sigmoid。图像分类器的结构如图4所示。

图4 图像分类器的结构图
4 实验结果分析
使用模型的fit_generator 函数在数据生成器上进行训练,分批次读取数据增强后的图片数据,模型迭代训练50 次。设置训练集的一次训练包含的步数是100,每一步生成30个图片数据参与训练,验证集的一次训练包含的步数是50,每一步生成20 个图片数据参与训练。模型的损失函数和准确率分别采用binary_crossentropy 和accuracy来评估[5]。
经过训练后模型的准确率如图5所示,可以看出,验证集的准确率为98.9%。模型的损失值如图6所示,验证集的损失曲线是逐渐下降并趋于收敛。
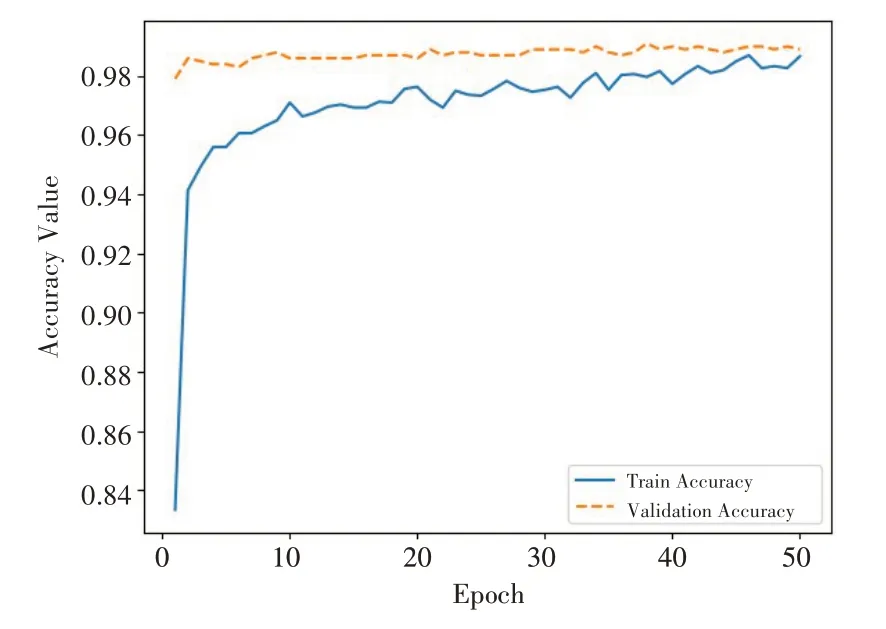
图5 模型准确率变化曲线
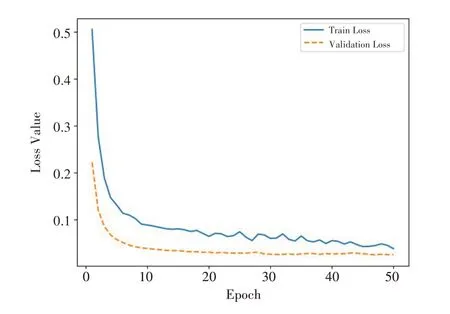
图6 模型损失变化曲线
训练后的模型以h5格式保存到硬盘中,并对测试集的1000张图片进行测试,调用evaluate()函数输出准确率以对模型进行评估,程序运行结果表明,测试集上的准确率达到99.2%,损失值是0.0219。最后调用roc_curve()函数生成ROC 曲线,如图7所示。从图7看出,曲线下方的面积接近于1,表明模型的分类效果好。
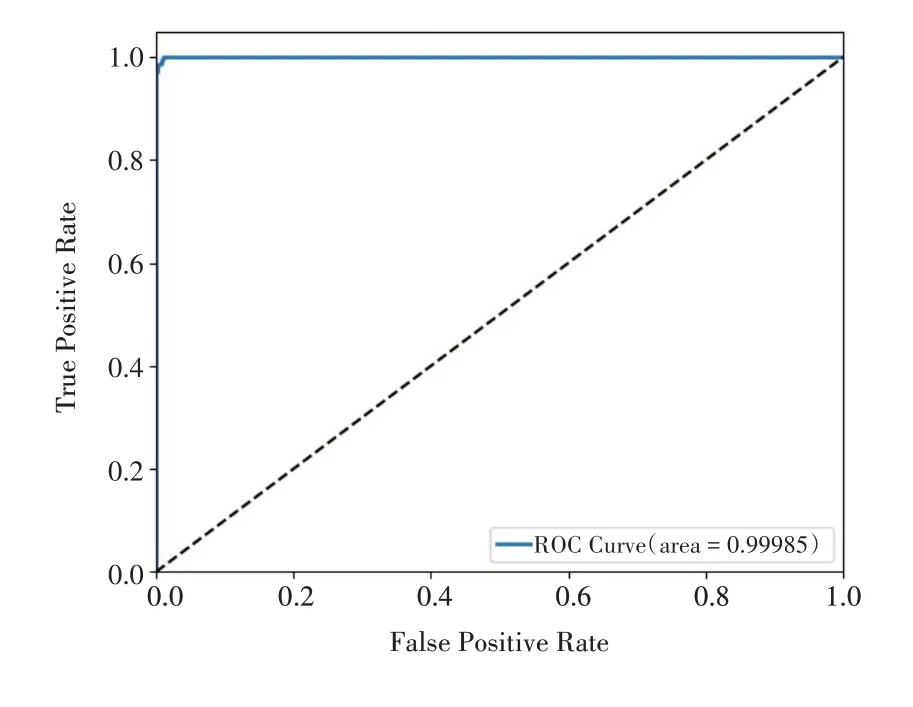
图7 ROC曲线图
5 结语
本文使用迁移学习将Xception 模型作为预训练模型,并对其中的block14 模块进行微调,使其中的六层处于可训练状态,在此基础上构建图像分类器,把5000 张猫狗图片分为训练集、验证集和测试集,通过训练集得到模型的权重,该模型在验证集和测试集上的准确率分别达到了98.9%和99.2%,证明了该模型对猫狗图片的分类效果好。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
