
基于人物属性提取的行人重识别改进算法
2024-03-27 16:21梁冰锐李宏杰
现代计算机 2024年1期
梁冰锐,周 卫,王 奔,李宏杰,杨 静
(1. 广西民族大学电子信息学院,南宁 530006;2. 广西民族大学人工智能学院,南宁 530006;3. 广西民族大学数学与物理学院,南宁 530006)
0 引言
行人重识别(pedestrian re-identification,ReID)是使用计算机视觉技术来判断图像或视频队列中是否有特定行人,或识别可能源和非重复摄像机视图的现有视频序列中的目标行人的技术。行人重识别问题作为图像检索的子问题被广泛关注。在监控视频中,由于摄像机的分辨率和拍摄角度,通常无法使用高质量的面部照片,因此在人脸识别失败的情况下,行人重识别将成为非常重要的替代技术。
与传统的视频监控相比,ReID 在实际应用场景下的数据来源非常多样化,不同的摄像设备之间存在较大差异,行人外观易受穿着、遮挡、姿态和视角等因素影响,ReID 对算法也有较高的要求。
在行人属性识别中,获取了行人的高层语义信息,与低层特征不同,高层特征对视觉变换和成像条件的变化具有相对鲁棒性。虽然在实验室领域已经有很多研究成果,但在工程运用中依旧还颇具有挑战性,因为有很多因素,如视觉、光线和分辨率都会对实验结果造成影响。
目前行人属性识别的基本方法是将整个图片放进同一个CNN 网络,并输出多个代表属性的标签进行分类。基于这个最基本的方法,目前最新的工作主要集中在如何对不同粒度、不同规模的属性进行识别,如何通过提取场景中的上下文信息辅助属性的识别,以及如何提取不同属性间的相关性信息。不同粒度属性的提取通过建立不同网络层次的分支分别进行提取,再将不同分支提取的特征进行拼接作为最终特征。
1 相关工作
1.1 行人重识别现状
近年来,在行人重识别方面,已有一些研究成果。Chen等[1]提出用mAP(mean average precision)作为算法的评价标准,指出使用mAP 作为评价标准能更好地比较方法的优劣。而Zheng等[2]将CMC 曲线和mAP 结合作为评价标准。Yan 等[3]提出了RFA-Net,先提取图像的颜色特征,然后与LSTM(long short term memory)结合,获得基于序列的特征,充分利用序列数据集的信息,然后再进行匹配。Mclaughlin 等[4]提出将输入的信息分为外观特征和光流信息,将CNN 和RNN 网络相结合,在RNN 层上加入时域池化层使得该网络可以处理任意长度的视频,进行联合调参。Zhou等[5]提出利用深度神经网络将特征学习和度量学习统一在一个框架下,进行训练和推理。Liu等[6]提出基于累积运动上下文的视频人物重识别,采用了时间和空间分离的二路卷积网络结构,将获得的表观特征和运动特征融合,作为RNN的输入,和目前现有的方法相比,该方法的Rank-1 非常高。接下来,基于Transformer 的方法[7-8]也得到了越来越多的关注。和CNN 比较,TransReID[9]的Rank-1达到了明显的改善,Rank-1超过了87%。但是,由于训练CNN 和ViTs 的巨大差异,使用ViTs视觉的Transformer时,ViTs在Rank-1上获得了较差的性能。
1.2 行人属性提取研究现状
在行人属性提取方面,Li等[10]在基于深度层次内容信息的人体属性识别中训练CNN网络,从所有检测部位中选取最具描述属性的人体部分;并结合整体人体作为姿态深度表示。Liu 等[11]提出了一种基于注意力机制(attention-based)的深度神经网络, 提出多方向注意机制模块(multi-directional attention,MDA),提取多层特征,包含局部和全局特征,进行多层特征融合,进行细粒度的行人属性分析。
1.3 行人重识别和人物属性提取数据集研究现状
在基于视频的行人重识别研究中,VIPER作为使用最广泛的数据集,RANK-1的精确度从2008 年的12.0%[12]提升到2015 年的63.9%[13];与此同时,自2010—2016 年以来,CHUK 上的Rank-1获得了56.7%的增长。因为这些数据集的规模都不大,就算使用了深度学习,其特征和度量方法所得到的最好结果仍然是近似于手工计算出来的。然而,在Market-1501 上,深度学习的计算精确度得到了显著提升。2015—2016 年,Market-1501 数据集的Rank-1 的精确度从43.42%[14]提升至74.04%[15]。
基于视频的行人重识别数据集研究近几年来也引起了研究人员的重视。iLIDS-VIDRank-1准确率从2014 年的23.3%[16]提升至2016 年的58%[17],2017 年,有研究者提出基于上下文以及联合CNN、RNN 的AMOC 方法[18-20],Rank-1可以达到68.7%,同样,Zhou 等[21]通过将从数据集MARS 上获得的CNN 特征运用到PRID2011上,使得其Rank-1 准确率达到76.3%;而在MARS 上,Rank-1 准确率达到68.3%。2017 年,Zhao 等[22]在iLIDS-VID、PRID2011 以及MARS上的Rank-1 准确率分别达到了55.2%、79.4%以及70.6%,在MARS上的mAP也有所提高。2021年Fu 等[23]在LUPerson 上通过收集未标记的人物图像来构建大规模预训练数据集,结果表明在LUPerson 数据集上基于CNN 的SSL 预训练与ImageNet-1k预训练相比提高了ReID性能。
2 现有数据测试及说明
在针对现有行人重识别算法的测试中,目前公认的数据集为Market1501 数据集以及Duke数据集。以下是对两个数据集的大概介绍。
2.1 Market1501数据集
Market1501 的行人图片采集自清华大学校园的六个摄像头,一共标注了1501 个行人。其中751 个行人用于训练集,750 个行人用于测试集。其中gallery 集中含有标注的750 个行人的19732张图片,query集中含有标注的750个行人的3368张图片。
2.2 DukeMTMC-reID 数据集
DukeMTMC-reID 的行人图片采集自Duke 大学校园的八个静态摄像头,一共标注了1812 个行人。其中,1404 个行人被超过两个摄像头捕捉到,而408 个行人只被一个摄像头拍摄到。其中gallery 集中包含702 个行人和408 个干扰行人,共17661 张图片。query 集中包含了702 个行人,共2228张图片。
2.3 自制数据集
自制数据集采集于广西民族大学的四个静态摄像头,一共标注了54 个行人。其中,query中含有54 个行人的368 张图片,gallery 集中含有54个行人的4025张图片。
对目前国内外比较先进、泛化性强的几种行人重识别算法进行了调研、代码复现和测试。其中,选取了TorchReID、TransReID、TransReID-ssl三种有典型代表性的算法进行详细说明,见表1。

表1 几种行人重识别算法的交叉测试表
使用自制数据集进行测试后的数据见表2。
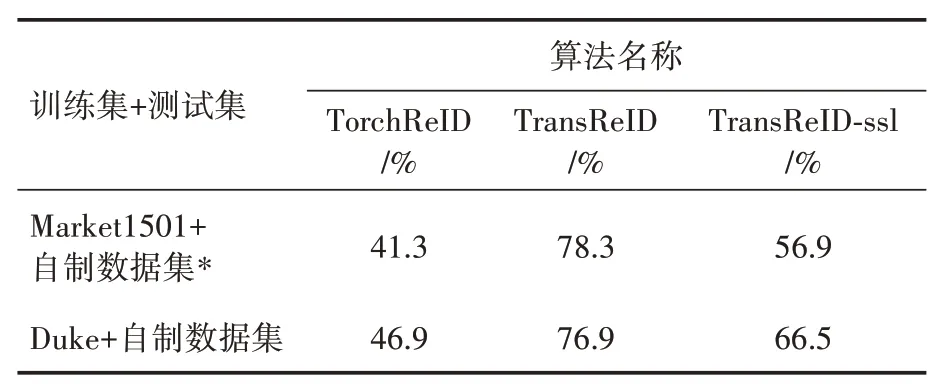
表2 使用自制数据集测试的详细情况表
从表2 可以看出,由于现有的ReID 方法大多是在同一数据集上进行训练和测试,使用交叉数据集进行测试的结果都不理想。从整体的测试结果来看,现有的ReID 算法都体现了很强的过拟合的风险。因此可以得出目前现有的ReID 算法并不能很好地适用于工程层面,还需要进行一系列改进的结论。
3 模型
3.1 整体架构
由现有算法测试结果可知,由于现有的行人重识别算法都是使用相同数据集进行训练和测试的,训练出来的模型均存在很强的过拟合问题,在跨域条件下的测试表现十分不理想,因此均不适用于工程条件下的行人重识别任务。
本文提出了一种改进的行人重识别方法,将传统基于Transformer 的行人重识别方法与行人属性提取方法结合,此方法可以增加ReID 算法识别的鲁棒性以及泛化性,在非同一来源的跨域行人重识别任务中有不错的表现。方法的整体结构如图1 所示,由ReID 模块、行人属性提取通路模块以及注意力机制模块三部分组成。
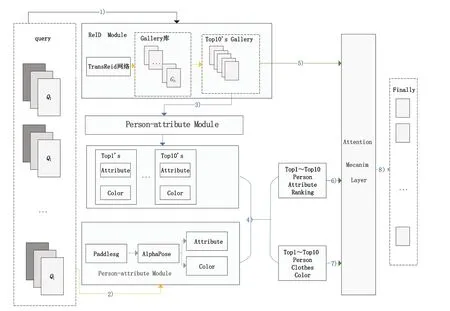
图1 模型层次图
算法的整体流程如下:
(1)将当前被查询的query 图片送入reid 通道提取特征值,并且匹配出gallery 库中相似度最高的Top10图片;
(2)同时将此query 图片使用paddleseg 算法去除背景得到query’,将去除背景的query’图片送入AlphaPose 中根据人体关键点分割上半身与下半身轮廓;通过HSV 色域空间比对query’的颜色信息,灰度共生矩阵分布计算所得的query’的纹理信息,其中上下衣颜色属性通过独热编码归为10 类10 种颜色,上下衣纹理属性以余弦相似度形式进行存储;
(4)将所得到的query 图片的人物属性值、query图片通过ReID算法得到的rank10的行人特征匹配值、query 图片通过ReID 算法得到的rank10 的10 张图片的人物属性值一同送入注意力机制模块进行结果整合,最后即可输出该query图片的匹配成功的rank图片结果。
3.2 ReID模块工作流程
ReID 模块选取了TransReid-ssl 算法作为baseline,将query 图片输入Transformer 网络(如图2 所示),提取特征,并根据阈值在gallery数据库中找到匹配阈值最高的Top10图片作为最后结果,并进行可视化输出,输出结果如图3所示。
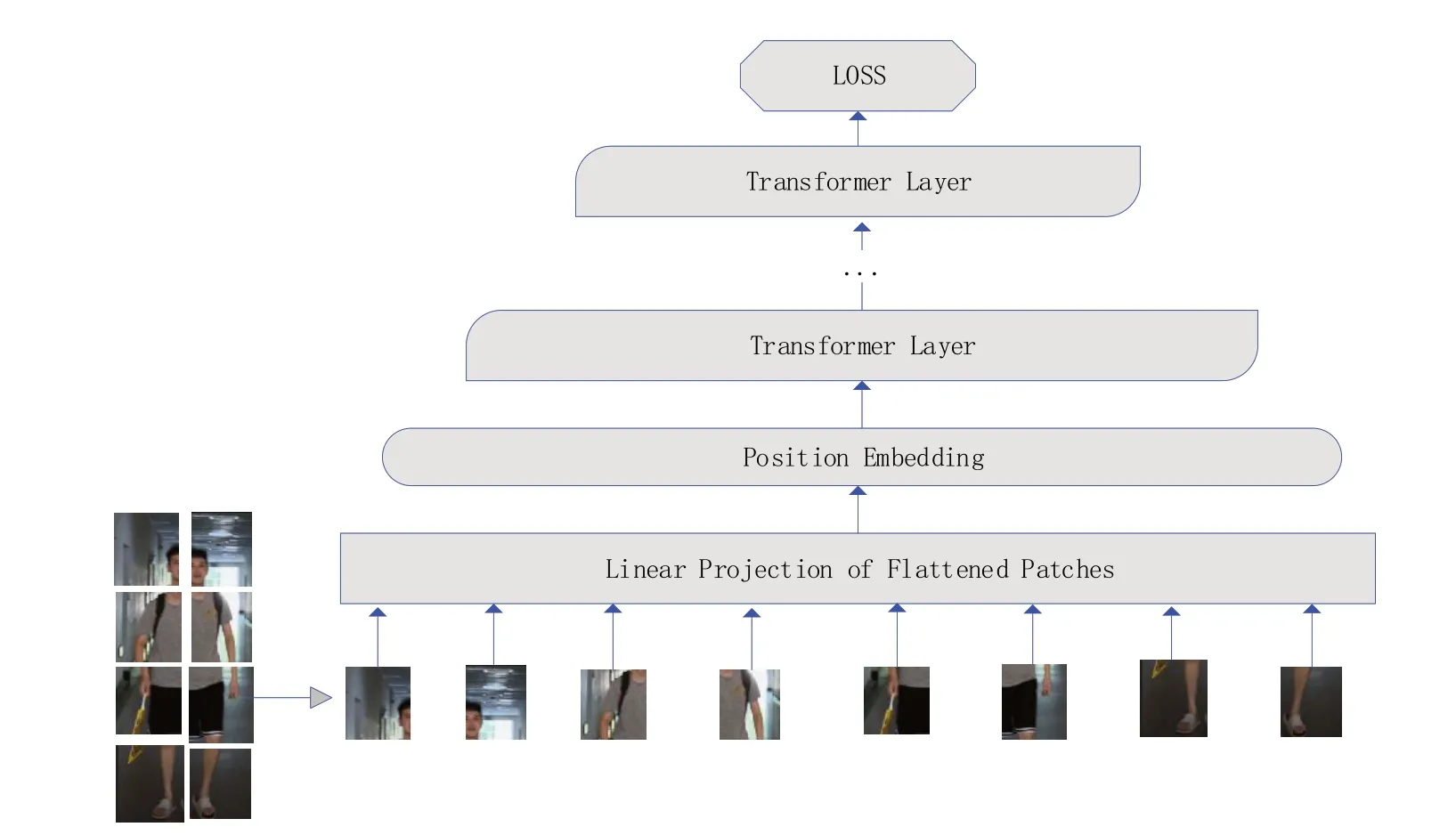
图2 ReID模块的Transformer网络模型

图3 分别使用market1501(a)与自制数据集(b)的ReID匹配结果
数据集中含有标注的750 个行人的3368 张图片。
图3(a)为使用Market1501 所训练的模型,测试数据集为Market1501 所测试出来的query 图片当前匹配阈值最高的Top10 的图片;图3(b)为使用Market1501 数据集所训练的模型,测试数据集为自制数据集所测试出来的当前匹配阈值最高的Top10的图片。
3.3 人物属性提取模块工作
人物属性提取算法可以在更加细微的层面提取出待检测行人图片的特征,例如:性别、头发长度、袖子长度、下身服装长度、下身服装类型、是否戴帽子、是否背背包、是否提手提包、上半身服装颜色、下半身服装颜色、年龄等属性。由于由人物属性提取算法提取到的人物属性是语义级别的特征,鲁棒性强,因此在跨镜条件下,部分人物属性特征可以起到辅助行人重识别判断的作用。
在辅助判断行人重识别的行人属性特征的属性选择上,以跨镜、鲁棒性强作为筛选条件,本文认为选择上身衣物颜色、上身衣物纹理、下身衣物颜色、下身衣物纹理这四种人物属性特征为辅助行人重识别的参数较为合理。
人物属性提取模块(person-attribute moudle)是对从query 库中抽取出来的待问询图片进行人物属性提取的算法模块。
本例患者肿块较大,呈分叶状,增强扫描病变实性部分与边缘明显强化,与文献报道相同[3][4][5],肿瘤内伴有较多点状、条状、块状钙化,与文献报道有所不同,提示EMC病灶内可伴有较多钙化,这为进一步认识EMC提供了依据。总之EMC临床及CT表现缺乏特征性,确诊主要依据病理组织学及免疫表型。
人物属性提取模块分为三步:
(1)通过PaddleSeg 将人物背景与人物主体进行分离,如图4 所示。PaddleSeg 是一个基于PaddlePaddle 深度学习框架的语义分割库,用于解决图像语义分割问题。在本文所述的人物属性提取的方法中,使用了PaddleSeg 提供的语义分割模型和数据增强方法,可以实现对图像中人物和背景的分割。

图4 运用PaddleSeg对人物进行背景与主体分离
(2)通过基于深度学习的人体姿态估计库AlphaPose 对分离背景的人物图像进行人物姿态关键点解析,并且根据人物的姿态关键点进行人物上下装的切分。结果如图5所示。

图5 AlphaPose切割分离的人物上下装衣物
(3)对上一步分离的人物上下装切分图片进行颜色与纹理的识别。主要流程如图6所示。

图6 颜色、纹理判定主要流程
首先输入当前帧切分出来的人物上装或下装图片,将图片从RGB 颜色空间转为HSV 色域空间,并遍历表3 所示的颜色列表生成掩码图像,然后对掩码图像进行二值化操作找出轮廓,更新主要颜色并且计算上下装的纹理的灰度共生矩阵。
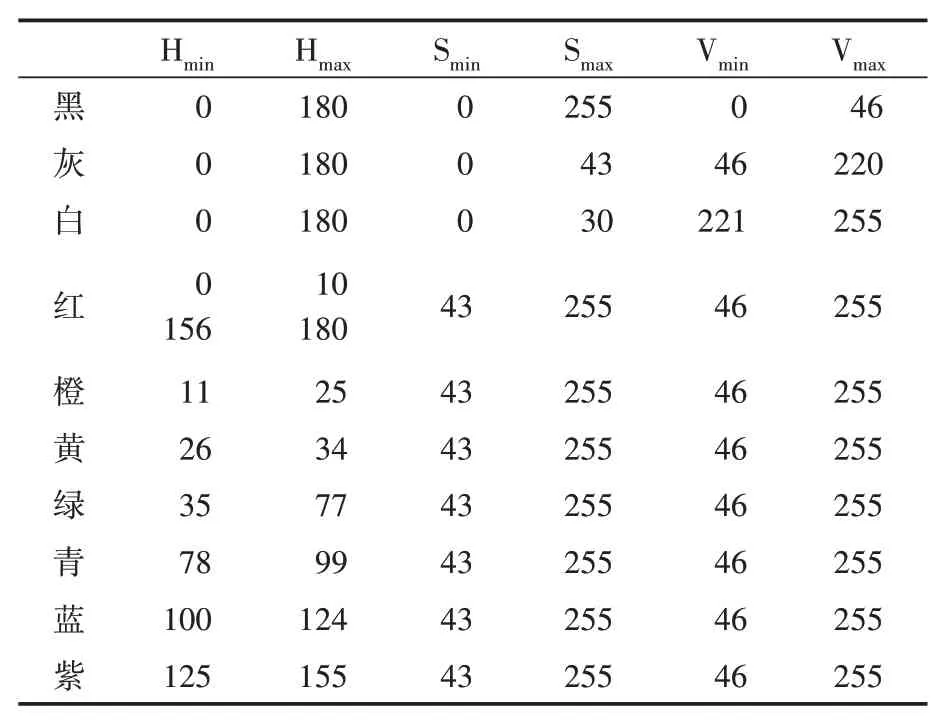
表3 10种HSV色域空间值
通过人物属性提取算法,进一步筛选出行人在摄像头内切片数据的语义级别的特征,如图7 所示,包括切片行人的上衣颜色、下装颜色、上衣的纹理灰度共生矩阵数据、下装的纹理灰度共生矩阵数据。

图7 行人的上下衣颜色属性以及纹理灰度共生矩阵属性
3.4 注意力机制模块设计方法
3.4.1 行人属性提取的参数选择
通过人物属性提取算法,进一步筛选出行人在摄像头内切片数据的语义级别的特征,包括切片行人的上衣颜色、下装颜色、上衣的纹理灰度共生矩阵数据、下装的纹理灰度共生矩阵数据。
3.4.2 激活函数的选择
选择Heaviside 函数作为激活函数。对人物衣物属性特征进行二分类。如果匹配则选择,不匹配则过滤删除掉Top10中的图片。
3.4.3 注意力机制模块的设计
如图8 所示,通过将当前query 图片的Top10 的mergin 值、当前query 图片的人物上下衣的纹理灰度共生矩阵的余弦距离、通过简单函数筛选过滤的人物上下衣颜色值作为参数输入,输入至注意力机制模块中,最后输出当前query图片的gallery库筛选结果。

图8 注意力机制的设计
4 实验与分析
4.1 实验数据
本文使用Market1501数据集与上文所提的自制数据集进行训练与测试。均使用Market1501数据集进行训练,测试集分别使用Market1501与自制数据集。具体数据见表4。

表4 实验数据详细信息表
本文使用Rank-1 准确率、精确率P、召回率R作为行人重识别的衡量指标,其定义如式(1)~式(2)其中TP是正确匹配的人物图片的数量,FP为错误匹配的人物图片的数量,FN为没有进行匹配的人物图片的数量。
Rank-1 准确率表示模型在给定一个查询图像后,将数据库中与查询图像最相似的正确匹配项排在第一位的准确率。
4.2 实验设置参数
为了验证本方法的可行性,本文与Trans-ReID 模型进行对比,验证本方法在跨域行人重识别方向上的改进效果。
本实验的环境配置见表5。

表5 环境配置表
4.3 实验数据
为了验证本方法的可行性,本文与Trans-ReID 模型进行对比,验证本方法在跨域行人重识别方向上的改进效果。本文提出的基于人物属性提取的行人重识别改进算法的效果见表6。

表6 改进算法与原算法比较情况
本文提出的改进算法的人物匹配结果如图9所示。

图9 TransReID-ssl+PA-A算法匹配人物图片输出结果
本文的TransReID-ssl+PA-A 改进算法在跨域条件下的Rank-1值达到81%,高于TransReID-ssl模型,说明通过基于人物属性提取的行人重识别改进算法能够很好地提高行人重识别算法在跨域条件下的准确率,在一定程度上加快了行人重识别算法在工程上应用的步伐。
5 结语
针对行人重识别算法在工程应用上对rank-1的命中率的高要求、对算法模型泛化性的高要求,本文提出了一种基于人物属性提取的行人重识别改进算法。本文的主要贡献有:①通过数据集之间的交叉测试以及使用自制数据集对现有行人重识别算法的泛化性做了详细的测试;②提出了基于人物属性提取的行人重识别方法,在行人重识别方法中引入了人物属性作为第二通道,通过注意力机制对行人重识别结果进行二次筛选,得到更为精确的rank-1 结果;③针对行人重识别,从工程运用的角度设计并制作了自制数据集,从是否打伞、更换衣物、跨镜等角度捕捉行人图片。
猜你喜欢
意林(2021年5期)2021-04-18
软件(2020年3期)2020-04-20
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
扬子江(2019年1期)2019-03-08
摄影之友(影像视觉)(2018年12期)2019-01-28
数学小灵通·3-4年级(2017年9期)2017-10-13
Coco薇(2017年8期)2017-08-03
小天使·一年级语数英综合(2017年6期)2017-06-07
Coco薇(2015年5期)2016-03-29
